One PUNCH Man——深度学习入门
文章目录
- 人类视觉原理
- 从神经网络到卷积神经网络(CNN)
- 数据输入层
- 卷积计算层
-
- 卷积的计算
- 参数共享机制
- 激励层
- 池化层
- 全连接层
- CNN优缺点
- 卷积神经网络的常用框架
人类视觉原理
深度学习的许多研究成果,离不开对大脑认知原理的研究,尤其是视觉原理的研究。
1981 年的诺贝尔医学奖,颁发给了 David Hubel(出生于加拿大的美国神经生物学家) 和TorstenWiesel,以及 Roger Sperry。前两位的主要贡献,是“发现了视觉系统的信息处理”,可视皮层是分级的。
人类的视觉原理如下:从原始信号摄入开始(瞳孔摄入像素 Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球)。下面是人脑进行人脸识别的一个示例:

我们可以看到,在最底层特征基本上是类似的,就是各种边缘,越往上,越能提取出此类物体的一些特征(轮子、眼睛、躯干等),到最上层,不同的高级特征最终组合成相应的图像,从而能够让人类准确的区分不同的物体。
那么我们可以很自然的想到:可以不可以模仿人类大脑的这个特点,构造多层的神经网络,较低层的识别初级的图像特征,若干底层特征组成更上一层特征,最终通过多个层级的组合,最终在顶层做出分类呢?答案是肯定的,这也是许多深度学习算法(包括CNN)的灵感来源。
从神经网络到卷积神经网络(CNN)
我们知道神经网络的结构是这样的:
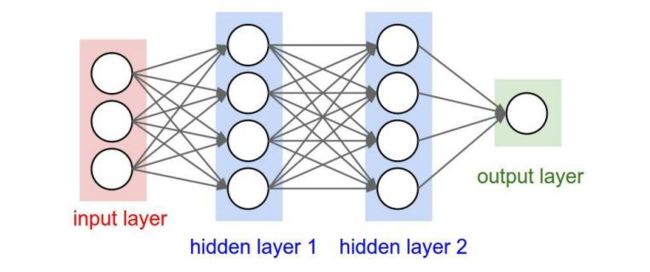
那卷积神经网络跟它是什么关系呢?
其实卷积神经网络依旧是层级网络,只是层的功能和形式做了变化,可以说是传统神经网络的一个改进。比如下图中就多了许多传统神经网络没有的层次。
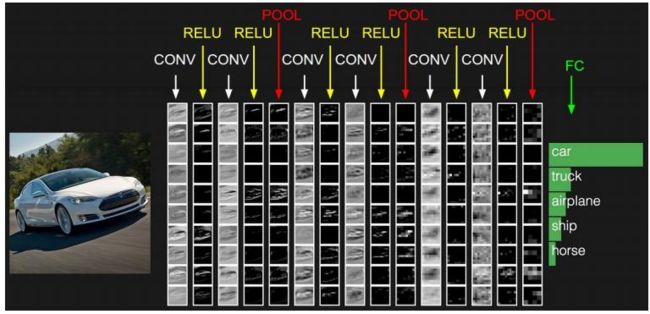
卷积神经网络的层级结构
• 数据输入层/ Input layer
• 卷积计算层/ CONV layer
• ReLU激励层 / ReLU layer
• 池化层 / Pooling layer
• 全连接层 / FC layer
注意看,上图,卷积层(CONV)和激励层(RELU)以及池化层(POOL)是反复交错的。
降低参数量级
综合起来说,CNN通过卷积来模拟特征区分,并且通过卷积的权值共享及池化,来降低网络参数的数量级,最后通过传统神经网络完成分类等任务。
如果我们使用传统神经网络方式,对一张图片进行分类,那么,我们把图片的每个像素都连接到隐藏层节点上,那么对于一张1000x1000像素的图片,如果我们有1M隐藏层单元,那么一共有10^12个参数,这显然是不能接受的。(如下图所示)
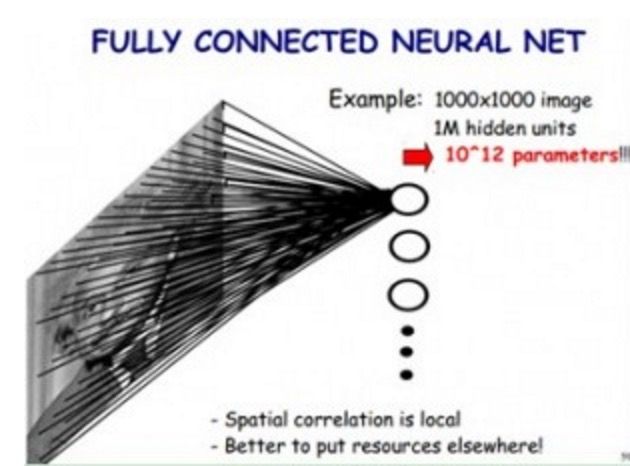
但是我们在CNN里,可以大大减少参数个数,我们基于以下两个假设:
1)最底层特征都是局部性的,也就是说,我们用10x10这样大小的过滤器就能表示边缘等底层特征。
2)图像上不同小片段,以及不同图像上的小片段的特征是类似的,也就是说,我们能用**同样的一组分类器(filter)**来描述各种各样不同的图像。
基于以上两个,假设,我们就能把第一层网络结构简化如下:
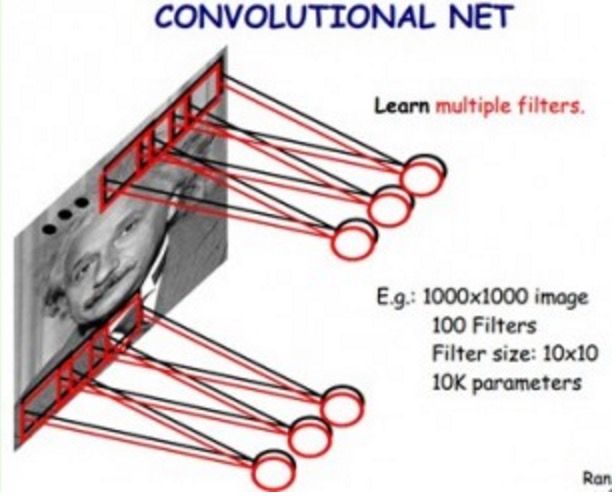
我们用100个10x10的小过滤器,就能够描述整幅图片上的底层特征。
数据输入层
该层要做的处理主要是对原始图像数据进行预处理,其中包括:
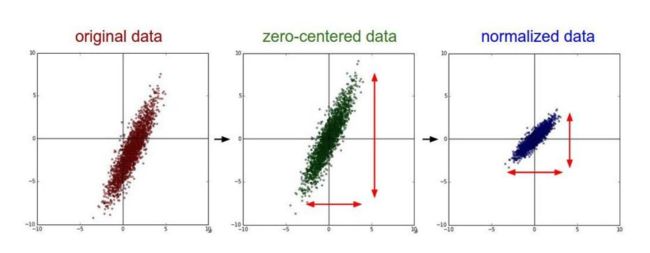
• 去均值:把输入数据各个维度都中心化为0,如下图所示,其目的就是把样本的中心拉回到坐标系原点上。
• 归一化:幅度归一化到同样的范围,如下所示,即减少各维度数据取值范围的差异而带来的干扰,比如,我们有两个维度的特征A和B,A范围是0到10,而B范围是0到10000,如果直接使用这两个特征是有问题的,好的做法就是归一化,即A和B的数据都变为0到1的范围。
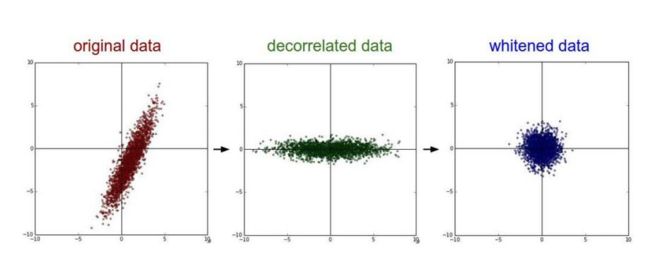
• PCA/白化:用PCA降维;白化是对数据各个特征轴上的幅度归一化
去均值与归一化效果图:
去相关与白化效果图:
数据输入层的内容我们点到为止,具体方法和理论以后有机会再深入了解。
卷积计算层
这一层就是卷积神经网络最重要的一个层次,也是“卷积神经网络”的名字来源。
在这个卷积层,有两个关键操作:
• 局部关联。每个神经元看做一个滤波器(filter)
• 窗口(receptive field)滑动, filter对局部数据计算
先介绍卷积层遇到的几个名词:
• 深度/depth
• 步长/stride (窗口一次滑动的长度)
• 填充值/zero-padding
填充值是什么呢?以下图为例子,比如有这么一个55的图片(一个格子一个像素),我们滑动窗口取22,步长取2,那么我们发现还剩下1个像素没法滑完,那怎么办呢?
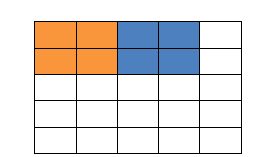
那我们在原先的矩阵加了一层填充值,使得变成6*6的矩阵,那么窗口就可以刚好把所有像素遍历完。这就是填充值的作用。

卷积的计算
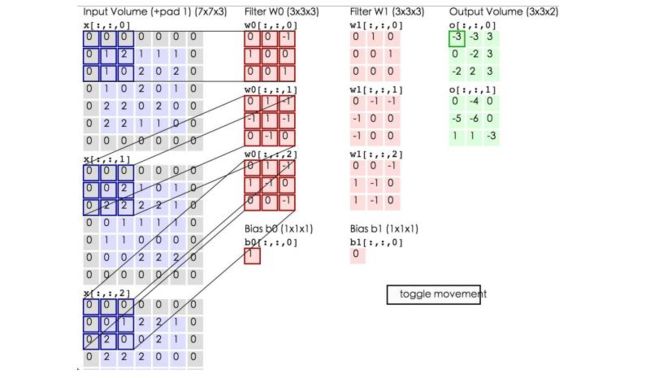
这里的蓝色矩阵就是输入的图像,粉色矩阵就是卷积层的神经元,这里表示了有两个神经元(w0,w1)。绿色矩阵就是经过卷积运算后的输出矩阵,这里的步长设置为2。

蓝色的矩阵(输入图像)对粉色的矩阵(filter)进行矩阵内积计算并将三个内积运算的结果与偏置值b相加(比如上面图的计算:2+(-2+1-2)+(1-2-2) + 1= 2 - 3 - 3 + 1 = -3),计算后的值就是绿框矩阵的一个元素。
下面是计算的动态图:
https://img2018.cnblogs.com/blog/1093303/201901/1093303-20190120113539659-455066516.gif
参数共享机制
在卷积层中每个神经元连接数据窗的权重是固定的,每个神经元只关注一个特性。神经元就是图像处理中的滤波器,比如边缘检测专用的Sobel滤波器,即卷积层的每个滤波器都会有自己所关注一个图像特征,比如垂直边缘,水平边缘,颜色,纹理等等,这些所有神经元加起来就好比就是整张图像的特征提取器集合。
上面说到,对图像的滤波处理就是对图像应用一个小小的卷积核,那这个小小的卷积核到底有哪些魔法,能让一个图像从惨不忍睹变得秀色可餐。下面我们一起来领略下一些简单但不简单的卷积核的魔法。
- 啥也不做

- 图像锐化滤波器Sharpness Filter
图像的锐化和边缘检测很像,首先找到边缘,然后把边缘加到原来的图像上面,这样就强化了图像的边缘,使图像看起来更加锐利了。这两者操作统一起来就是锐化滤波器了,也就是在边缘检测滤波器的基础上,再在中心的位置加1,这样滤波后的图像就会和原始的图像具有同样的亮度了,但是会更加锐利。
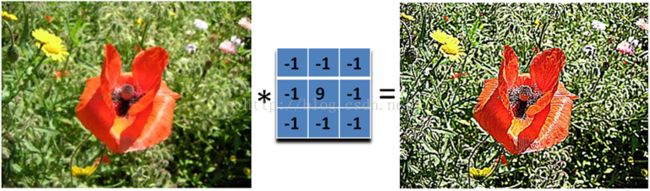
我们把核加大,就可以得到更加精细的锐化效果

另外,下面的滤波器会更强调边缘:
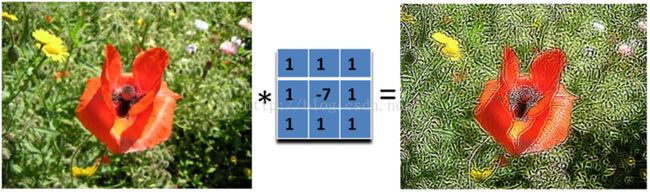
- 边缘检测
我们要找水平的边缘:需要注意的是,这里矩阵的元素和是0,所以滤波后的图像会很暗,只有边缘的地方是有亮度的。

为什么这个滤波器可以寻找到水平边缘呢?因为用这个滤波器卷积相当于求导的离散版本:你将当前的像素值减去前一个像素值,这样你就可以得到这个函数在这两个位置的差别或者斜率。下面的滤波器可以找到垂直方向的边缘,这里像素上和下的像素值都使用:
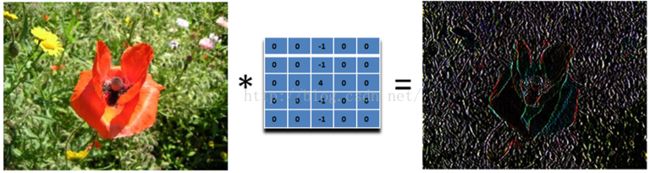
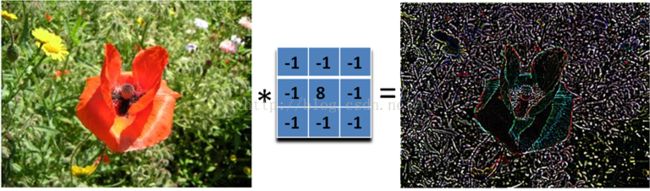
下面这个滤波器就可以检测所有方向的边缘:
激励层
把卷积层输出结果做非线性映射。
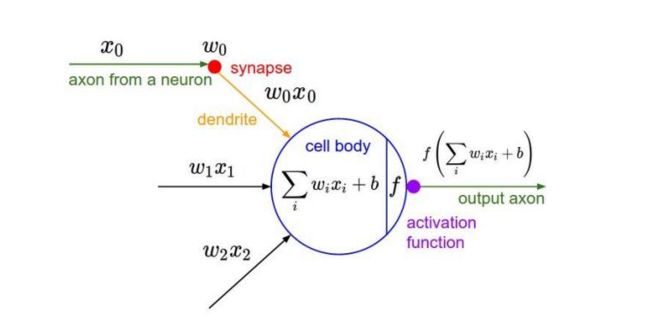
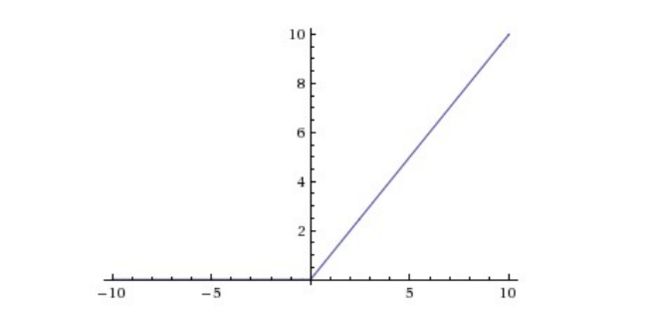
CNN采用的激励函数一般为ReLU(The Rectified Linear Unit/修正线性单元),它的特点是收敛快,求梯度简单,但较脆弱,图像如下。
池化层
池化层夹在连续的卷积层中间, 用于压缩数据和参数的量,减小过拟合。
简而言之,如果输入是图像的话,那么池化层的最主要作用就是压缩图像。
-
特征不变性,也就是我们在图像处理中经常提到的特征的尺度不变性,池化操作就是图像的resize,平时一张狗的图像被缩小了一倍我们还能认出这是一张狗的照片,这说明这张图像中仍保留着狗最重要的特征,我们一看就能判断图像中画的是一只狗,图像压缩时去掉的信息只是一些无关紧要的信息,而留下的信息则是具有尺度不变性的特征,是最能表达图像的特征。
-
特征降维,我们知道一幅图像含有的信息是很大的,特征也很多,但是有些信息对于我们做图像任务时没有太多用途或者有重复,我们可以把这类冗余信息去除,把最重要的特征抽取出来,这也是池化操作的一大作用。
-
在一定程度上防止过拟合,更方便优化。
池化层用的方法有Max pooling 和 average pooling,而实际用的较多的是Max pooling。
这里就说一下Max pooling,其实思想非常简单。
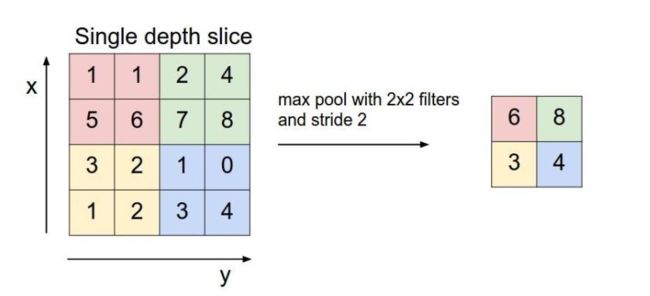
对于每个22的窗口选出最大的数作为输出矩阵的相应元素的值,比如输入矩阵第一个22窗口中最大的数是6,那么输出矩阵的第一个元素就是6,如此类推。
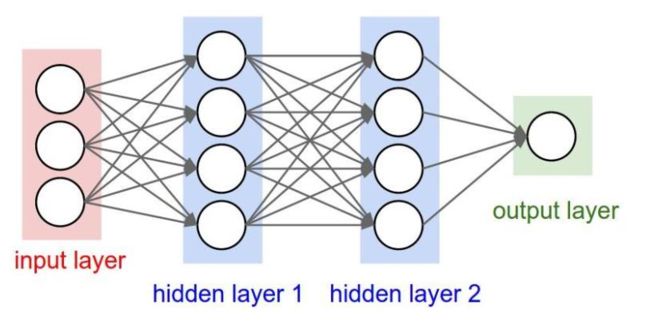
全连接层
两层之间所有神经元都有权重连接,通常全连接层在卷积神经网络尾部。也就是跟传统的神经网络神经元的连接方式是一样的:
一般CNN结构依次为
1. INPUT
2. [[CONV -> RELU]*N -> POOL?]*M
3. [FC -> RELU]*K
4. FC
CNN优缺点
卷积神经网络之优缺点
优点
• 共享卷积核,对高维数据处理无压力
• 无需手动选取特征,训练好权重,即得特征分类效果好
缺点
• 需要调参,需要大样本量,训练最好要GPU
• 物理含义不明确(也就说,我们并不知道没个卷积层到底提取到的是什么特征,而且神经网络本身就是一种难以解释的“黑箱模型”)
卷积神经网络的常用框架
Caffe
• 源于Berkeley的主流CV工具包,支持C++,python,matlab
• Model Zoo中有大量预训练好的模型供使用
Torch
• Facebook用的卷积神经网络工具包
• 通过时域卷积的本地接口,使用非常直观
• 定义新网络层简单
TensorFlow
• Google的深度学习框架
• TensorBoard可视化很方便
• 数据和模型并行化好,速度快
参考资料:
https://www.cnblogs.com/alexcai/p/5506806.html
https://www.cnblogs.com/skyfsm/p/6790245.html
http://www.cnblogs.com/Ponys/p/3428270.html
https://blog.csdn.net/linlang1536/article/details/78925115