股票量化交易策略之选股、模拟交易过程
一、多因子策略-回测阶段介绍
1、回测内容确定
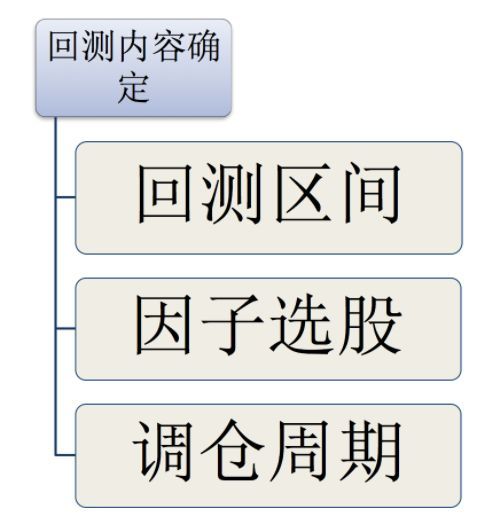
在多因子策略当中,选股通过因子选择,那么怎么结合筛选出来的多个因子来去选择某些股票
2、回测选股方法
多因子选股最常用的方法就是打分法和回归法,但是至于这两种哪个效果更好需要进行实际的模拟交易或者实盘交易之后才能确定。通常模拟交易测试结果来说,打分法效果更好。
- 打分法选股
- 回归法选股
这两种方法都是在确定因子的权重来选择固定的股票。什么是确定权重再去选股呢?
二、多因子打分法选股
1、经过筛选的因子
| 因子方向 | 因子说明 |
|---|---|
| 因子升序 | 因子值越小越好,市值、市盈率、市净率 |
| 因子降序 | 因子值越大越好,ROIC、inc_revenue营业总收入 和inc_profit_before_tax利润增长率 |
2、 打分法选股流程确定
2.1 分析
- 1、回测区间:
- 2010-01-01 ~ 2018-01-01
- 2、选股:
- 选股因子:6个已知方向的因子
- 选股权重:
- 因子升序从小到大分10组,第几组为所在组得分
- 因子降序从大到小分10组,第几组为所在组得分
- 数据处理:处理缺失值
- 3、调仓周期:
- 调仓:每月进行一次调仓
- 交易规则:卖出已持有的股票
- 买入新的股票池当中的股票
2.2 代码
# 可以自己import我们平台支持的第三方python模块,比如pandas、numpy等。
# 打分法选股
# 回测:2010-01-01~2018-01-01
# 调仓:按月
# 选股因子:市值、市盈率、市净率、ROIC、inc_revenue营业总收入
# 和inc_profit_before_tax利润增长率
# 选股的指数、模块:全A股
import pandas as pd
# 在这个方法中编写任何的初始化逻辑。context对象将会在你的算法策略的任何方法之间做传递。
def init(context):
context.group_number = 10
context.stocknum = 20
# 定义调仓频率函数
scheduler.run_monthly(score_select, tradingday=1)
def score_select(context, bar_dict):
"""调仓函数
"""
# 选股逻辑,获取数据、数据处理、选股方法
# 1、获取选股的因子数据
q = query(fundamentals.eod_derivative_indicator.market_cap,
fundamentals.eod_derivative_indicator.pe_ratio,
fundamentals.eod_derivative_indicator.pb_ratio,
fundamentals.financial_indicator.return_on_invested_capital,
fundamentals.financial_indicator.inc_revenue,
fundamentals.financial_indicator.inc_profit_before_tax
)
fund = get_fundamentals(q)
# 通过转置将股票索引变成行索引、指标变成列索引
factors_data = fund.T
# 数据处理
factors_data = factors_data.dropna()
# 对每个因子进行打分估计,得出综合评分
get_score(context, factors_data)
# # 进行调仓逻辑,买卖
rebalance(context)
def get_score(context, factors_data):
"""
对因子选股数据打分
因子升序:市值、市盈率、市净率
因子降序:ROIC、inc_revenue营业总收入和inc_profit_before_tax利润增长率
"""
# logger.info(factors_data)
for factorname in factors_data.columns:
if factorname in ['pe_ratio', 'pb_ratio', 'market_cap']:
# 单独取出每一个因子去进行处理分组打分
factor = factors_data.sort_values(by=factorname)[factorname]
else:
factor = factors_data.sort_values(by=factorname, ascending=False)[factorname]
# logger.info(factor)
# 对于每个因子去进行分组打分
# 求出所有的股票个数
single_groupnum = len(factor) // 10
# 对于factor转换成dataframe,为了新增列分数
factor = pd.DataFrame(factor)
factor[factorname + "score"] = 0
# logger.info(factor)
for i in range(10):
if i == 9:
factor[factorname + "score"][i * single_groupnum:] = i + 1
factor[factorname + "score"][i * single_groupnum:(i + 1) * single_groupnum] = i + 1
# 打印分数
# logger.info(factor)
# 拼接每个因子的分数到原始的factors_data数据当中
factors_data = pd.concat([factors_data, factor[factorname + "score"]], axis=1)
# logger.info(factors_data)
# 求出总分
# 先取出这几列分数
# 求和分数
sum_score = factors_data[
["market_capscore", "pe_ratioscore", "pb_ratioscore", "return_on_invested_capitalscore", "inc_revenuescore",
"inc_profit_before_taxscore"]].sum(1).sort_values()
# 拼接到factors_data
# logger.info(sum_score)
context.stocklist = sum_score[:context.stocknum].index
def rebalance(context):
# 卖出
for stock in context.portfolio.positions.keys():
if context.portfolio.positions[stock].quantity > 0:
if stock not in context.stocklist:
order_target_percent(stock, 0)
# 买入
for stock in context.stocklist:
order_target_percent(stock, 1.0 / 20)
# before_trading此函数会在每天策略交易开始前被调用,当天只会被调用一次
def before_trading(context):
pass
# 你选择的证券的数据更新将会触发此段逻辑,例如日或分钟历史数据切片或者是实时数据切片更新
def handle_bar(context, bar_dict):
# 开始编写你的主要的算法逻辑
pass
# after_trading函数会在每天交易结束后被调用,当天只会被调用一次
def after_trading(context):
pass三、多因子回归法选股
1、回归法选股步骤
- 选股因子回归系数确定
- 利用回归系数计算结果选股
2、选股因子回归系数确定
2.1 步骤分析
- 1、回归训练区间
2012-01-01 ~ 2014-01-01
- 2、回归股票池
股票池(HS300指数)
- 3、回归因子数据准备、收益率计算
因子数据:横截面数据拼接,添加日期数据、去除空值 收益率计算: 所有样本的收益率计算
- 4、目标值特征值提取进行回归估计
数据处理:去除收益为0(价格数据不存在)、去极值、标准化处理
2.2 代码
- 因子数据准备
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, Ridge
# 获取股票列表数据、训练时间
stocks = index_components("000300.XSHG")
date = get_trading_dates(start_date="2012-01-01", end_date="2013-01-01")
all_data = pd.DataFrame()
for i in range(len(date)):
q = query(fundamentals.eod_derivative_indicator.pe_ratio,
fundamentals.eod_derivative_indicator.pb_ratio,
fundamentals.eod_derivative_indicator.market_cap,
fundamentals.financial_indicator.ev,
fundamentals.financial_indicator.return_on_asset_net_profit,
fundamentals.financial_indicator.du_return_on_equity,
fundamentals.financial_indicator.earnings_per_share,
fundamentals.income_statement.revenue,
fundamentals.income_statement.total_expense).filter(fundamentals.stockcode.in_(stocks))
fund = get_fundamentals(q, entry_date=date[i])[:, 0, :]
# 添加日期
fund['date'] = date[i]
all_data = pd.concat([all_data, fund])
# 为了回归计算,先去除空值
all_data = all_data.dropna()
# 计算收益率,需要用到索引的股票代码
all_data = all_data.reset_index()- 计算每个样本的收益率
# 增加return收益率列
all_data['return'] = 0.0
for i in range(20):
# 取出每个样本的股票代号和当天的日期
stock_code = all_data.ix[i, 'index']
# 取出当天日期
now_day = all_data.ix[i, 'date']
# 得到下一天的日期,一定要从交易日里面找到下一期
for time in range(len(date)):
if date[time] == now_day:
next_day = date[time + 1]
# 根据日期,取的当天的价格和下一天的价格计算收益率
price_now = get_price(stock_code, start_date=now_day, end_date=now_day, fields='close')
price_next = get_price(stock_code, start_date=next_day, end_date=next_day, fields='close')
# 做出价格为空的判断
if price_now.values.size == 0 or price_next.values.size == 0:
continue
# 计算收益率
return_price = price_next.values/price_now.values - 1
all_data['return'][i] = return_price- 利用回归确定系数
# 取出特征值
x = all_data[["pe_ratio","pb_ratio","market_cap","return_on_asset_net_profit","du_return_on_equity","ev","earnings_per_share","revenue","total_expense"]]
# 取出目标值
y = all_data[['return']]
def mad(factor):
"""3倍中位数去极值
"""
# 求出因子值的中位数
med = np.median(factor)
# 求出因子值与中位数的差值,进行绝对值
mad = np.median(np.abs(factor - med))
# 定义几倍的中位数上下限
high = med + (3 * 1.4826 * mad)
low = med - (3 * 1.4826 * mad)
# 替换上下限以外的值
factor = np.where(factor > high, high, factor)
factor = np.where(factor < low, low, factor)
return factor
# 对特征值进行处理
for name in x.columns:
x[name] = mad(x[name])
# 特征值标准化操作
std = StandardScaler()
x = std.fit_transform(x)
std_y = StandardScaler()
y = std_y.fit_transform(y)
# 通过线性回归得出系数
lr = LinearRegression()
lr.fit(x, y)
print(lr.coef_)
rd = Ridge()
rd.fit(x, y)
print(rd.coef_)我们可以得出线性回归的系数,如下
array([[-0.12496874, 0.03845575, -0.99038983, -0.39055527, 0.68191808,
0.85971852, 0.14719819, 0.18936681, 0.11412645]])3、利用回归系数计算结果选股
# 可以自己import我们平台支持的第三方python模块,比如pandas、numpy等。
# 回测区间:2014-01-01~2018-01-01
# 选股:
# 范围:沪深300
# 因子:
# 方法:回归法,利用系数相乘(矩阵相乘运算)得出结果排序
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, Ridge
# 在这个方法中编写任何的初始化逻辑。context对象将会在你的算法策略的任何方法之间做传递。
def init(context):
context.stock_num = 20
# 定义沪深300指数股
context.hs300 = index_components("000300.XSHG")
scheduler.run_monthly(regression_select, tradingday=1)
def regression_select(context, bar_dict):
"""回归法进行选择股票
准备因子数据、数据处理(缺失值、去极值、标准化、中性化)
预测每个股票对应这一天的结果,然后排序选出前20只股票
"""
# 1、准备因子数据
q = query(fundamentals.eod_derivative_indicator.pe_ratio,
fundamentals.eod_derivative_indicator.pb_ratio,
fundamentals.eod_derivative_indicator.market_cap,
fundamentals.financial_indicator.ev,
fundamentals.financial_indicator.return_on_asset_net_profit,
fundamentals.financial_indicator.du_return_on_equity,
fundamentals.financial_indicator.earnings_per_share,
fundamentals.income_statement.revenue,
fundamentals.income_statement.total_expense).filter(fundamentals.stockcode.in_(context.hs300))
fund = get_fundamentals(q)
factors_data = fund.T
# 2、处理数据
# 缺失值
factors_data = factors_data.dropna()
# 保留原来的数据,后续处理
factors1 = pd.DataFrame()
# 去极值
for name in factors_data.columns:
factors1[name] = mad(factors_data[name])
# logger.info(factors1)
# 标准化
std = StandardScaler()
# factors1 dataframe --->
factors1 = std.fit_transform(factors1)
# 将factors1还原成dataframe,方便后面取数据处理
factors1 = pd.DataFrame(factors1, index=factors_data.index, columns=factors_data.columns)
# 给中心化处理
# 确定中性化:特征值:原始的市值,目标值:处理过后的因子数据
x = factors_data['market_cap']
for name in factors1.columns:
# 跳过market_cap
if name == "market_cap":
continue
# 取出因子作为目标值
y = factors1[name]
# 建立回归方程,得出预测结果
# 用真是结果-预测结果得到残差,即为新的因子值
lr = LinearRegression()
lr.fit(x.values.reshape(-1, 1), y.values)
# 预测结果
y_predict = lr.predict(x.values.reshape(-1, 1))
# 得出没有相关性的残差部分
res = y - y_predict
# 将残差部分作为新的因子值
factors1[name] = res
# 处理结束,factors1即为我们最终需要的数据结果
# 3、选股
# 建立回归方程,得出预测结果,然后排序选出30个股票
# 特征值:factors1:9个因子特征值
# 训练的权重系数为:9个权重
# 假如5月1日,
# 得出的结果:相当于预测接下来的5月份收益率,哪个收益率高选谁
weights = np.array(
[-0.01864979, -0.04537212, -0.18487143, -0.06092573, 0.18599453, -0.02088234, 0.03341527, 0.91743347,
-0.8066782])
# 进行特征值与权重之间的矩阵运算
# (m行,n列) *(n行,l列) = (m行,l列)
# (300, 9) * (9, 1) = (300, 1)
return_ = np.matmul(factors1, weights.reshape(-1, 1))
# logger.info(stock_return)
# 根据收益率的大小排序去选股
# 将股票的代码和收益率绑定一起排序
stock_return = dict(zip(factors1.index, return_.reshape(-1)))
# logger.info(stock_return)
# 对字典进行排序
score = sorted(stock_return.items(), key=lambda x: x[1], reverse=True)[:20]
# 取出score的股票代码
context.stocklist = [x[0] for x in score]
# logger.info(context.stocklist)
rebalance(context)
def rebalance(context):
# 卖出
for stock in context.portfolio.positions.keys():
if context.portfolio.positions[stock].quantity > 0:
if stock not in context.stocklist:
order_target_percent(stock, 0)
weight = 1.0 / len(context.stocklist)
# 买入
for stock in context.stocklist:
order_target_percent(stock, weight)
# before_trading此函数会在每天策略交易开始前被调用,当天只会被调用一次
def before_trading(context):
pass
# 你选择的证券的数据更新将会触发此段逻辑,例如日或分钟历史数据切片或者是实时数据切片更新
def handle_bar(context, bar_dict):
pass
# after_trading函数会在每天交易结束后被调用,当天只会被调用一次
def after_trading(context):
pass
def mad(factor):
"""3倍中位数去极值
"""
# 求出因子值的中位数
med = np.median(factor)
# 求出因子值与中位数的差值,进行绝对值
mad = np.median(np.abs(factor - med))
# 定义几倍的中位数上下限
high = med + (3 * 1.4826 * mad)
low = med - (3 * 1.4826 * mad)
# 替换上下限以外的值
factor = np.where(factor > high, high, factor)
factor = np.where(factor < low, low, factor)
return factor四、技术分析策略
1、MACD策略交易信号分析
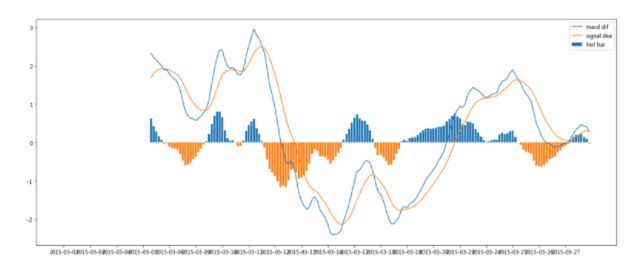
- 差离值(DIF值)与讯号线(DEA值,又称MACD值)相交
2、MACD策略实现
# 可以自己import我们平台支持的第三方python模块,比如pandas、numpy等。
import talib
# 在这个方法中编写任何的初始化逻辑。context对象将会在你的算法策略的任何方法之间做传递。
def init(context):
# 选择我们感兴趣的股票
context.s1 = "000001.XSHE"
context.s2 = "601988.XSHG"
context.s3 = "000068.XSHE"
context.stocks = index_components("000300.XSHG")
# 使用MACD需要设置长短均线和macd平均线的参数
context.SHORTPERIOD = 12
context.LONGPERIOD = 26
context.SMOOTHPERIOD = 9
context.OBSERVATION = 100
# 你选择的证券的数据更新将会触发此段逻辑,例如日或分钟历史数据切片或者是实时数据切片更新
def handle_bar(context, bar_dict):
# 开始编写你的主要的算法逻辑
# bar_dict[order_book_id] 可以拿到某个证券的bar信息
# context.portfolio 可以拿到现在的投资组合状态信息
# 使用order_shares(id_or_ins, amount)方法进行落单
# TODO: 开始编写你的算法吧!
for stock_code in context.stocks:
# 读取历史数据,使用sma方式计算均线准确度和数据长度无关,但是在使用ema方式计算均线时建议将历史数据窗口适当放大,结果会更加准确
prices = history_bars(stock_code, context.OBSERVATION, '1d', 'close')
# 用Talib计算MACD取值,得到三个时间序列数组,分别为macd, signal 和 hist
macd, signal, hist = talib.MACD(prices, context.SHORTPERIOD,
context.LONGPERIOD, context.SMOOTHPERIOD)
# macd 是长短均线的差值,signal是macd的均线,使用macd策略有几种不同的方法,我们这里采用macd线突破signal线的判断方法
# 如果macd从上往下跌破macd_signal
if macd[-1] - signal[-1] < 0 and macd[-2] - signal[-2] > 0:
# 计算现在portfolio中股票的仓位
curPosition = context.portfolio.positions[stock_code].quantity
# 进行清仓
if curPosition > 0:
order_target_value(context.s1, 0)
# 如果短均线从下往上突破长均线,为入场信号
if macd[-1] - signal[-1] > 0 and macd[-2] - signal[-2] < 0:
# 满仓入股
order_target_percent(stock_code, 0.1)五、模拟交易
1、为什么需要模拟交易
- 检查策略的有效性以及策略的bug
- 减少真实资金的风险
2、RQ的模拟交易介绍
一键部署、云端永久运行,微信号通知,支持一键跟单。
3、模拟交易过程
3.1 策略进行分钟测试
这步的目的就是检查策略的bug,如果在每日回测的时候,策略表现较好。但是分钟测试效果不好,就需要去检查策略。
- 策略是否用到了未来函数
- 策略的逻辑判断是否存在问题
原因:
- 策略周期性
- 使用未来函数
- 真实交易环境(滑点)
3.2 RiceQuant使用
- 分钟测试
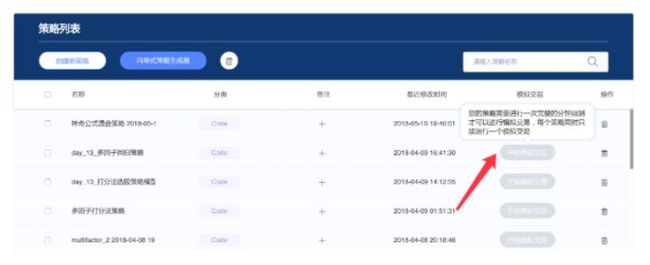
分钟测试没有问题之后,模拟交易按钮就可以使用了
- 模拟交易
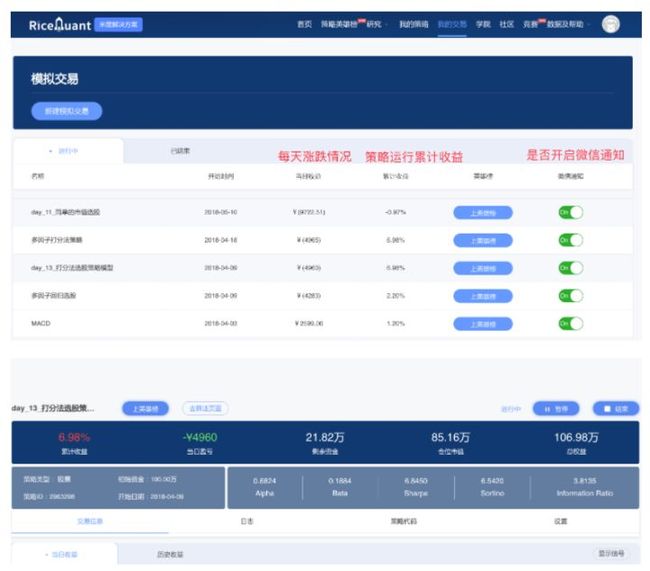
当然我们可以看到成交记录,以及最新的持仓,这里我们演示的是一个月调一次仓,所以会在每月月初进行一次买卖交易
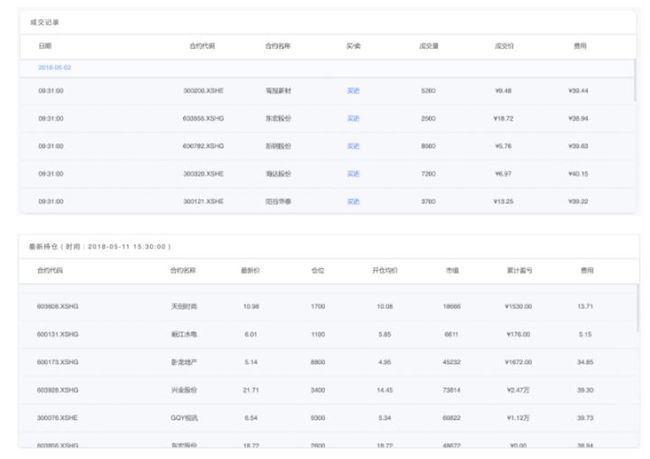
从上面可以看出我们这个策略表现还可以,所持仓的每只股票基本都是收益当中。
- 微信通知与跟单
我们进行策略编写完或者进行因子挖掘之后,那么交易的话一般不是我们进行或者可以有专门的人进行手动交易。因为多因子策略的调仓周期比较长,所以可以手动根据策略的交易结果来去手动下单