ASR - OpenAI whisper
文章目录
-
- 关于 whisper
- Approach
- Setup
-
- 1、安装 whisper
- 2、安装依赖 ffmpeg
- 3、安装依赖 rust
- 可用的模型和语言
- 命令行用法
- Python usage
- 更多示例
- 参考
关于 whisper
Whisper is a general-purpose speech recognition model.
It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.
whisper 作者:Alec Radford、Jong Wook Kim
- github : https://github.com/openai/whisper
- Introducing Whisper : https://openai.com/blog/whisper/
- 论文:https://cdn.openai.com/papers/whisper.pdf
- huggingface spaces - whisper : https://huggingface.co/spaces/openai/whisper
其他资料/教程
- AI匠:来自OpenAI的Whisper语音识别模型
https://www.bilibili.com/video/BV1SN4y1K7m9
Approach

Whisper 使用 Transformer seq2seq 模型针对各种语音处理任务进行训练,包括多语言语音识别、语音翻译、口语识别和语音活动检测。
所有这些任务都被联合表示为解码器预测的令牌序列,允许使用单个模型替换传统语音处理管道的许多不同阶段。
多任务训练格式使用一组特殊标记作为任务说明符或分类目标。

Whisper是一个自动语音识别(ASR)系统,经过68万小时的多语言和多任务监控数据训练,这些数据是从网络上收集的。( 65%(438218小时)是英语音频和匹配的英语文本,大约18%(125739小时)是非英语音频和英语文本,而最后17%(117113小时)则是非英语音频和相应的文本。非英语部分共包含98种不同语言。)
我们表明,使用这样一个大而多样的数据集可以提高对口音、背景噪音和技术语言的鲁棒性。
此外,它还支持多种语言的转录,以及将这些语言翻译成英语。
Whisper 是开源模型和推理代码,为构建有用的应用程序和进一步研究健壮的语音处理奠定了基础。
Whisper架构是一种简单的端到端方法,实现为编码器-解码器 Transformer。
输入音频被分割成30秒的块,转换成对数梅尔谱图,然后传递给编码器。
解码器经过训练以预测相应的文本标题,并与特殊标记混合,这些标记指示单个模型执行诸如语言识别、短语级时间戳、多语言语音转录和英语语音翻译等任务。

其他现有方法经常使用更小、更紧密配对的音频文本训练数据集,或使用广泛但无监督的音频预训练。
因为Whisper是在一个大而多样的数据集上训练的,并且没有针对任何特定的数据集进行微调,所以它没有击败专门研究LibriSpeech性能的模型,这是语音识别领域一个著名的竞争基准。
然而,当我们在许多不同的数据集上测量Whisper的零启动性能时,我们发现它比那些模型更健壮,误差减少50%。
Whisper大约有三分之一的音频数据集是非英语的,它被交替地赋予用原语言转录或翻译成英语的任务。
我们发现这种方法在学习语音到文本翻译方面特别有效,并且在CoVoST2到英语翻译零炮上优于监督的SOTA。
Setup
whisper 官方使用 Python 3.9.9 和 PyTorch 1.10.1 训练和测试模型,但此代码库可兼容 Python 3.7 及以上的版本 和最近的 PyTorch 版本。
代码库也依赖于一些 Python 包,主要包括 HuggingFace Transformers 来使用他们快捷的tokenizer使用 和 ffmpeg-python 用来读取音频文件。
1、安装 whisper
方式一:下载源码本地安装
cd whisper
python setup.py install
方式二:拉取代码安装
这将拉取和安装最近的版本和他们的依赖。(个人觉得速度不太稳定)
pip install git+https://github.com/openai/whisper.git
2、安装依赖 ffmpeg
It also requires the command-line tool ffmpeg to be installed on your system, which is available from most package managers:
# on Ubuntu or Debian
sudo apt update && sudo apt install ffmpeg
# on Arch Linux
sudo pacman -S ffmpeg
# on MacOS using Homebrew (https://brew.sh/)
brew install ffmpeg
# on Windows using Chocolatey (https://chocolatey.org/)
choco install ffmpeg
# on Windows using Scoop (https://scoop.sh/)
scoop install ffmpeg
更多 ffmpeg 的安装使用可参考:https://blog.csdn.net/lovechris00/article/details/125921387
3、安装依赖 rust
参考文章:https://blog.csdn.net/lovechris00/article/details/124808034
$ brew install rustup
$ rustup-init
$ pip install setuptools-rust
可用的模型和语言
有一下五种大小尺寸的模型,四种支持英语,提供速度和准确性的权衡。
下面是可用模型的名称,和他们所需要的内存和相对速度。
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en |
tiny |
~1 GB | ~32x |
| base | 74 M | base.en |
base |
~1 GB | ~16x |
| small | 244 M | small.en |
small |
~2 GB | ~6x |
| medium | 769 M | medium.en |
medium |
~5 GB | ~2x |
| large | 1550 M | N/A | large |
~10 GB | 1x |
如果应用中只是使用英语,.en 模型效果更好,特别是 tiny.en 和 base.en 模型。
我们发现 small.en 和 medium.en 模型差异不太显著。
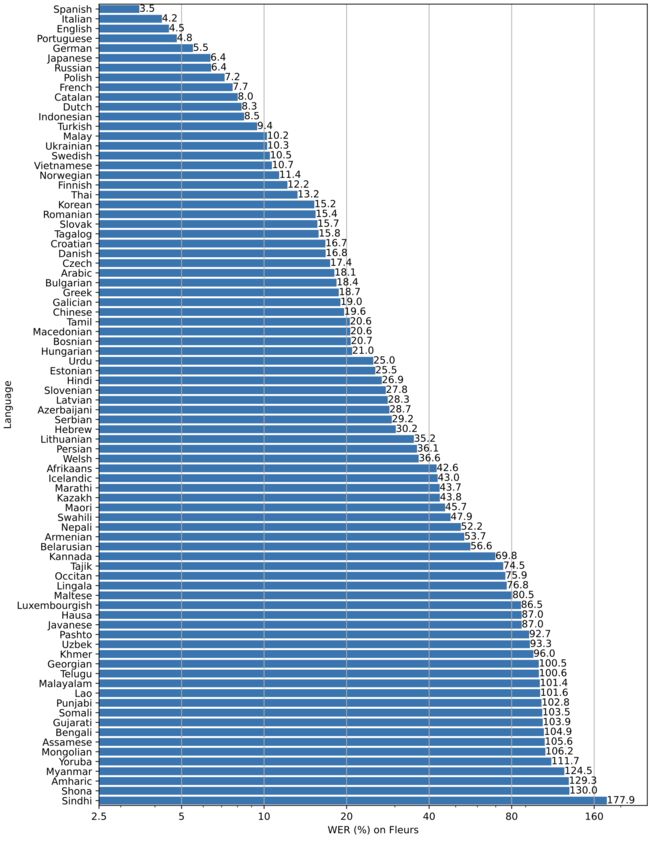
不同语种,Whisper的效果不同。
下图显示了使用“大型”模型,按Fleurs数据集语言划分的WER细分。
更多 WER 和 BLEU 与其他模型和数据集相对应的分数见论文中的附录D:
https://cdn.openai.com/papers/whisper.pdf。
命令行用法
下面命令将表述音频文件内容,使用 medium 模型:
whisper audio.flac audio.mp3 audio.wav --model medium
默认设置(将选择 small 模型 )将良好的表述为英语;
表述非英语语音,你可以通过 --language 选项指定语种;
whisper japanese.wav --language Japanese
添加 --task translate 可以将语音翻译为英语:
whisper japanese.wav --language Japanese --task translate
查看所有选项:
whisper --help
查阅支持语言的列表(whisper/tokenizer.py):
https://github.com/openai/whisper/blob/main/whisper/tokenizer.py
Python usage
还可以在Python中执行转录:
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])
在内部, transcribe() 方法读取整个文件,并将语音切分以 30s 为窗口进行切分,在每个窗口上执行自回归 seq2seq 预测。
下面是 whisper.detect_language() 和 whisper.decode() 的使用示例,提供对模型更底层的访问:
import whisper
model = whisper.load_model("base")
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio("audio.mp3")
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# print the recognized text
print(result.text)
更多示例
可以示例可访问 Show and tell : https://github.com/openai/whisper/discussions/categories/show-and-tell
讨论分享更多Whisper和第三方扩展的示例用法,如web演示、与其他工具的集成、不同平台的端口等。
参考
https://baijiahao.baidu.com/s?id=1744833871099962749
2022-10-19(二)清凉