训练自己数据集的YOLOX模型,手把手教学
1.数据集的制作
(1)VOC数据的格式为:

(2)数据集的划分:
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = r'D:\YOLOX-1027\datasets\VOCdevkit\VOC2007\Annotations'
txtsavepath = r'D:\YOLOX-1027\datasets\VOCdevkit\VOC2007\JPEGImages'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftest = open(r'D:\YOLOX-1027\datasets\VOCdevkit\VOC2007\ImageSets\Main\test.txt', 'w')
ftrain = open(r'D:\YOLOX-1027\datasets\VOCdevkit\VOC2007\ImageSets\Main\trainval.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftest.write(name)
else:
ftrain.write(name)
ftrain.close()
ftest.close()
2.模型部分的修改
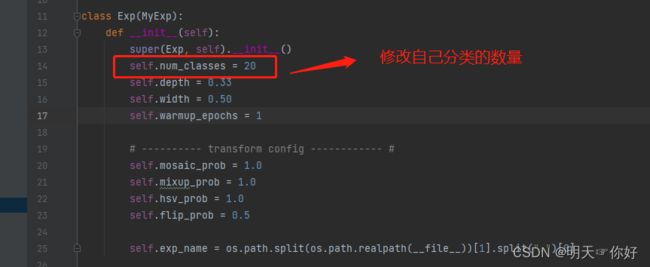
(1)在这个路径中,exps/example/yolox_voc/yolox_voc_s.py,修改自己分类的数量
 (2) 在这个路径中,yolox/data/datasets/voc_classes.py,修改自己的标签名
(2) 在这个路径中,yolox/data/datasets/voc_classes.py,修改自己的标签名

(3)将这三个文件复制到主目录中:
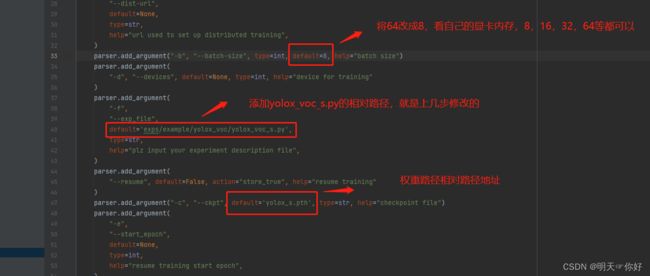
(4)在主目录中的train.py中进行以下修改:
3.错误解决
1.[Errno 2] No such file or directory: 'D:\\LZT\\YOLOX-1027\\datasets\\VOCdevkit\\VOC2012\\ImageSets\\Main\\trainval.txt'
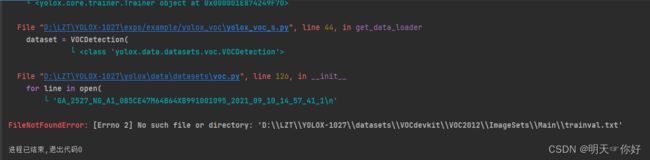
在这个文件中,exps/example/yolox_voc/yolox_voc_s.py ,删除('2012', 'trainval')
2.[Errno 2] No such file or directory: 'GA_0514_NG_A1_0B5CE47M64B64XB8O1000313_2021_09_02_10_25_32_0.xml'

修改为:
tree = ET.parse(os.path.join('datasets/VOCdevkit/VOC2007/Annotations', filename))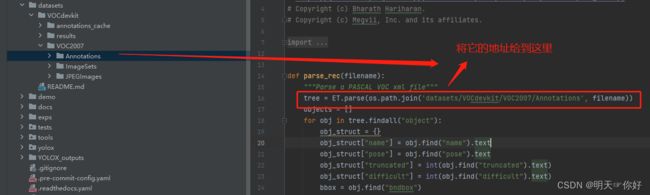
4.测试模型
(1)修改部分见下图
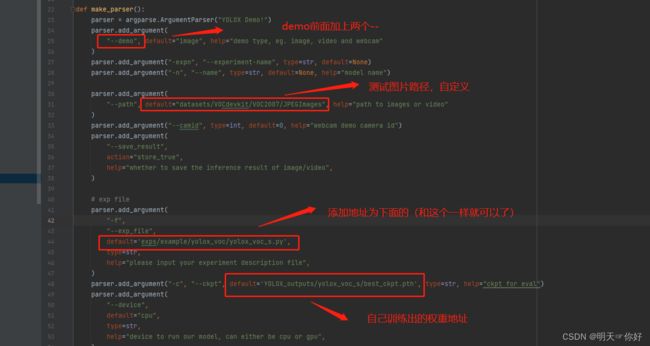
(2) 将demo.py中的三处 COCO_CLASSES 替换成 VOC_CLASSES
from yolox.data.datasets.voc_classes import VOC_CLASSES