地心的PyTorch学习(一)
目录
一. 背景
二. PyTorch的基础语法
1. 数据类型
2. 判断数据类型
3. 将数据张量Tensor从CPU移到GPU上
4. 创建标量
5. 看一个数据的大小和形状
6. 随机的初始化函数
7. 对tensor赋值
8. 改变tensor的形状
9. 运算操作
10. 将2个张量合并
11. 逻辑语句(==、>、<) 编辑
12. 求和
13. 广播机制
14. 索引和切片
15. numpy数组和pytorch张量间的转换
三. 总结
一. 背景
PyTorch是Facebook开发的深度学习的框架之一,它是Facebook在Torch的基础上开发的,主要用于训练神经网络,可以用CPU和GPU进行训练网络。PyTorch可以用于人工智能的各个应用领域,如自然语言处理,计算机视觉,语音处理等方向,是一个功能很全面的深度学习框架。
除了Facebook开发的Pytorch框架之外,还有许多热门的深度学习框架,比如:
(1)TensorFlow:TensorFlow框架是Google公司开发的框架,其中TensorFlow又分为TensorFlow1.0和TensorFlow2.0,TensorFlow1.0和2.0的差别很大,可以说是两种不同的框架了。同时在TensorFlow中可以调用Keras的功能。
(2)MindSpore:MindSpore是国产的深度学习框架,是华为公司所开发开源AI框架,与与华为研发的昇腾芯片最佳匹配。有兴趣的小伙伴可以去华为云官网或华为ICT学院免费学习了解。
(3)PaddlePaddle(飞桨):是百度开发的中国首个自主研发的深度学习框架。
除此之外还有许多的框架,大家感兴趣可以自行了解。
二. PyTorch的基础语法
1. 数据类型

由图中可以看出,PyTorch的数据类型,在CPU和GPU上是不一样的,在GPU上较比CPU,它在torch后多了cuda。
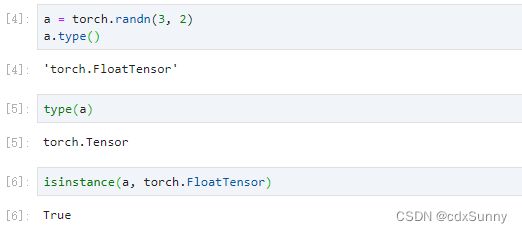
2. 判断数据类型
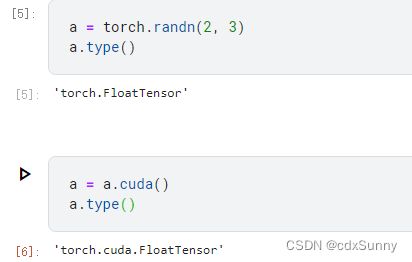
3. 将数据张量Tensor从CPU移到GPU上
(1)变量.cuda()
(2)变量.to(device)
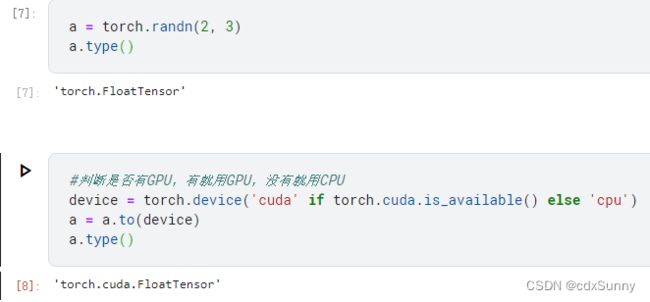
以上的两种方法是常用的用GPU加速的方法,除了张量Tensor可以放到GPU上,我们构建的模型也可以放到GPU上训练。
4. 创建标量
标量是dimension为0的数据,是一个数值,比如经常用于表示loss的大小


5. 看一个数据的大小和形状
(1)形状:
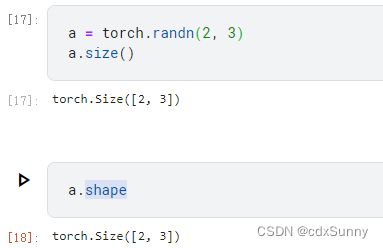
(2)大小:

6. 随机的初始化函数
(1)rand
在[0,1]之间随机分布

rand(x, y)在[0,1]之间随机分布,其中x,y表示a的形状,比如rand(3,3)表示在一个3*3的在[0,1]之间分布的矩阵
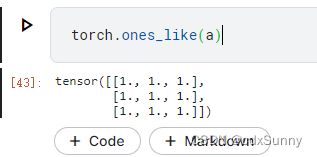
(2)rand_like

rand_like相当于一个函数,即将随机出来的值直接赋值给a。
(3)randint
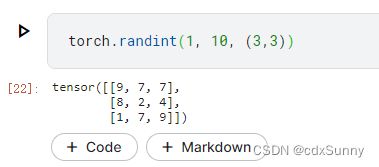
表示从最小值1开始不包括最大值10,随机生成3*3的矩阵 。
(4)randn(正态分布)
均值为0,方差为1的正态分布。

7. 对tensor赋值
(1)将tensor赋值为相同的值

(2)arange

这里的arange和python里的一样的用法
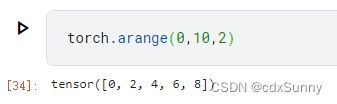
第三个参数是步长
(3)linspace
linspace(x,y,z)中,x,y和上面的arange一样的意思,z是表示分多少份,比如下面0-10分成11分就是0,1,2,.....,10,而arange的第三个参数表示步长,即各多少取一个数。

(4)全部赋值为1

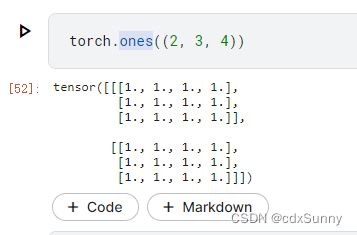
(5)全部赋值为0



(6)对角矩阵

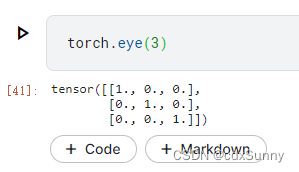
如果参数eye(x)只有1个,则构建x*x的对角矩阵。
(7)randperm不重复的随机打散

注意不包括10,如果参数为11,则不包括11。
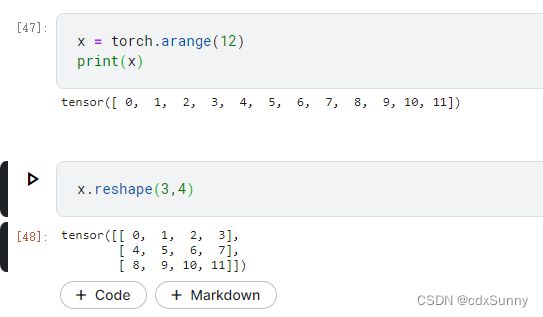
8. 改变tensor的形状
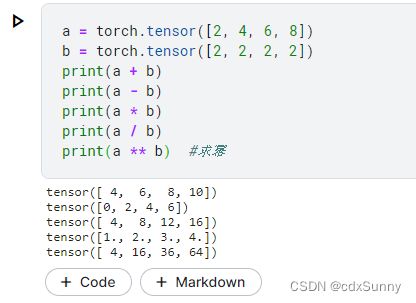
9. 运算操作
10. 将2个张量合并
dim=0代表竖直方向,dim=1代表水平方向

11. 逻辑语句(==、>、<) 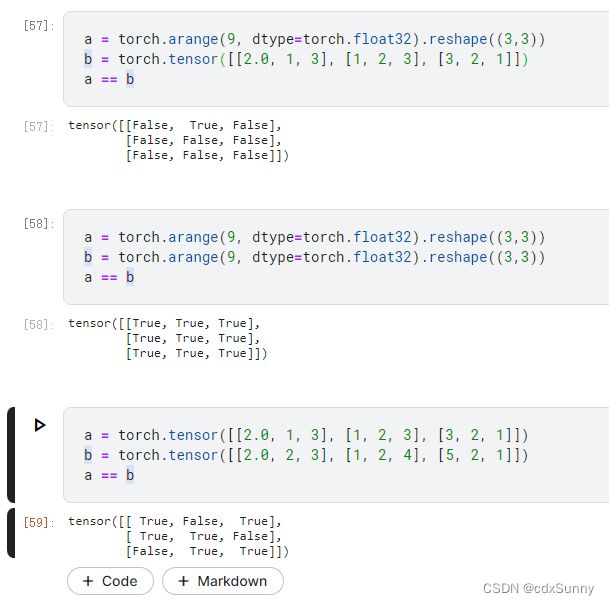


12. 求和
对张量内的所有元素求和

13. 广播机制

由于a和b的形状不一样,所有把它们的形状扩展到相同,即a赋值一列,b赋值一行,再相加。
14. 索引和切片
pytorch中的索引和切片和python中的是一样的。
15. numpy数组和pytorch张量间的转换

三. 总结
以上是对Pytorch数据的一个简单的操作,包括赋值、生成随机数和有规律数、查看张量大小和形状、改变形状、加减乘除、广播机制、索引切片等操作,算是简单的入了门。