【机器学习】详解 LSTM
相关文章
【机器学习】详解 RNN
【机器学习】详解 LSTM
【机器学习】详解 GRU
目录
一、概述
二、长短期记忆网络的原理
三、长短期记忆网络的运算
四、长短期记忆网络的训练
五、长短期记忆网络的实现
5.1 从头实现
5.1.1 初始化模型参数
5.1.2 定义模型
5.1.3 训练模型并创作歌词
5.2 简洁实现
一、概述
在【机器学习】详解 RNN 一文中介绍了 RNN,其易产生 梯度消失/弥散、梯度爆炸,难处理长距离的依赖问题,故使用时存在较大局限性。在本文中,将介绍一种经改进的 RNN:长短期记忆网络 (Long Short Term Memory Network, LSTM),它成功地解决了原 RNN 的不足,成为最广泛使用的 RNN 变体之一,成功应用于语音识别、图片描述、自然语言处理等多个领域。以下将详细介绍 LSTM 的原理与特点,并大致阐述 LSTM 最成功的变体之一 —— GRU。
二、长短期记忆网络的原理
在【机器学习】详解 RNN 一文中提到 RNN 的缺陷描述为:
RNN 使用 随时间反向传播算法 (Back Propagation Through Time, BPFT) 训练,误差不仅依赖于当前时刻
,也依赖于先前时刻。对于基本 RNN,根据反向传播公式,第 1 个时刻得到第
的
尽管后来的研究者试图使用多种技术应对 (如权重初始化、归一化),但效果仍十分有限。终于,LSTM 被发明并解决了 RNN 的上述问题。
其实,LSTM 的思路较简单。RNN 的隐藏层只有一个 隐藏状态 ![]() ,其对 短期输入 非常敏感。那么,若再增加一个状态
,其对 短期输入 非常敏感。那么,若再增加一个状态 ![]() 来保存 长期状态 不就可以了吗?如下图所示:
来保存 长期状态 不就可以了吗?如下图所示:

新增的长期状态 ![]() ,称为 单元状态 (cell state)。将 LSTM 按时间维度展开:
,称为 单元状态 (cell state)。将 LSTM 按时间维度展开:
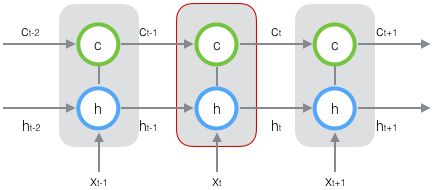
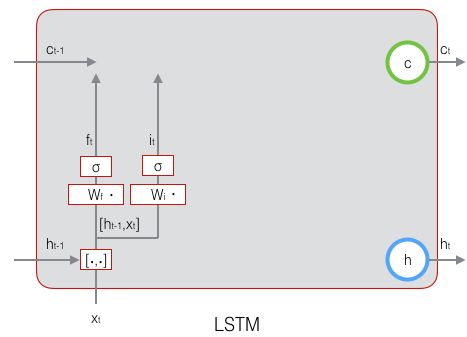
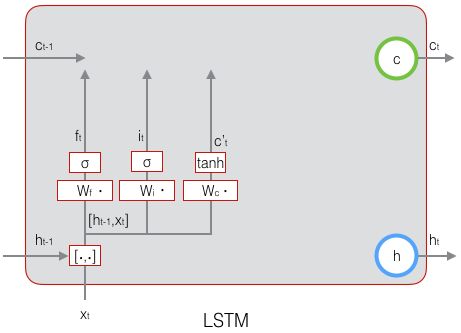
易知,在 时刻 LSTM 有三个 输入,分别为:
- 当前时刻
- 上一时刻
的 LSTM 隐藏状态输出
- 上一时刻
同时,在 时刻 LSTM 有两个 输出,分别为:
- 当前时刻
- 当前时刻
注意,这些输入、输出和单元状态都是 向量。
如何控制长期状态 ![]() 是关键之处。LSTM 的思路是使用三个控制开关,即:
是关键之处。LSTM 的思路是使用三个控制开关,即:
- 开关一:负责控制 继续保存上一时刻的长期状态
- 开关二:负责控制 把当前时刻的即时状态加入长期状态
- 开关三:负责控制 是否把当前时刻的长期状态
作为当前时刻的 LSTM 输出
三个开关的作用 如下图所示:

三、长短期记忆网络的运算
要实现上一节的开关,需要用到一个 全连接层 作为 门 (gate) ,其输入是一个向量,输出是一个 0~1 之间的实向量。设 ![]() 为门的权重,
为门的权重,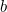 是偏置,那么门可表示为:
是偏置,那么门可表示为:
![]()
使用的门控制向量,即将门的输出向量按元素乘以该向量。因为门输出 0~1 之间的实向量,那么,当 门输出为 0 时,任何向量与之相乘都会得到 0,相当于 关门 —— 此路不通;当 门输出为 1 时,任何向量与之相乘都不会变化,相当于 开门 —— 畅通无阻。门(即 sigmoid )的值域是 (0, 1),门的状态可视为 半开半闭 的。
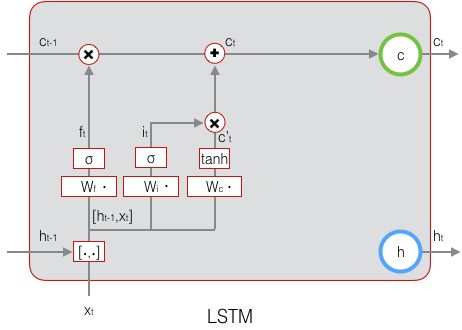
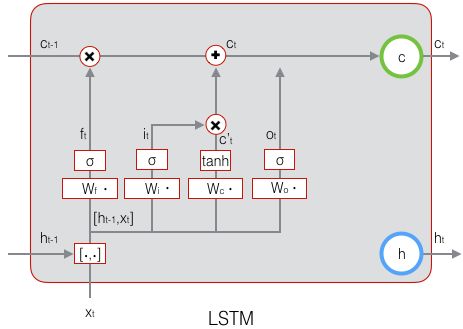
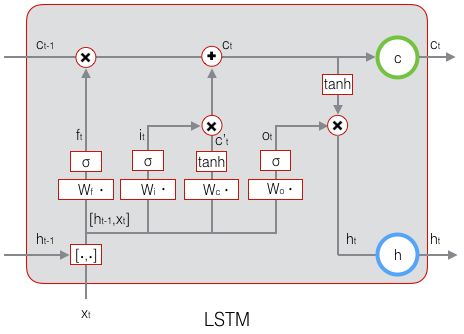
LSTM 中引入了 3 个门,即 输入门 (input gate)、遗忘门 (forget gate) 和 输出门 (output gate),以及与隐藏状态形状相同的记忆细胞(某些文献把记忆细胞当成一种特殊的隐藏状态),从而记录额外的信息。通常,输入门 控制当前时间步计算的新状态以多大程度更新到记忆单元中;遗忘门 控制前一时间步记忆单元中的信息有多大程度被遗忘掉;输出门 控制当前时间步的输出有多大程度上取决于当前的记忆单元。更具体地,LSTM 用
输出门 控制 当前时刻 的 LSTM 隐藏状态输出 ![]() :
:
- 输出门:决定当前时刻的单元状态
有多少作为当前时刻的隐藏状态输出
(或者说输出有多少取决于记忆单元)
遗忘门 和 输入门 控制 当前时刻 的 LSTM 单元状态 ![]() :
:
- 遗忘门:决定上一时刻的单元状态
有多少保留到当前时刻的单元状态
- 输入门:决定当前时刻的隐藏状态输入
和上一时刻的隐藏状态输出
有多少保存到当前时刻的单元状态
以下分别详细阐述计算过程。
设:上一时刻的隐藏状态输出为 ![]() ,当前时刻的隐藏状态输入为
,当前时刻的隐藏状态输入为 ![]() ,二者构成当前时刻输入;权重参数矩阵为
,二者构成当前时刻输入;权重参数矩阵为 ![]() ,偏置向量为 ,激活函数 sigmoid 为
,偏置向量为 ,激活函数 sigmoid 为 ![]() (值域 (0, 1)),激活函数 tanh 为
(值域 (0, 1)),激活函数 tanh 为 ![]() (值域 (-1, 1));则当前时刻的计算分别为:
(值域 (-1, 1));则当前时刻的计算分别为:
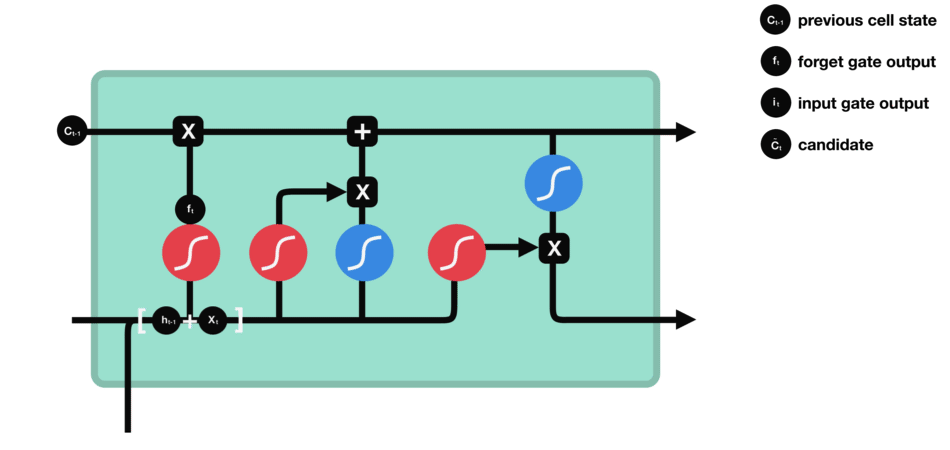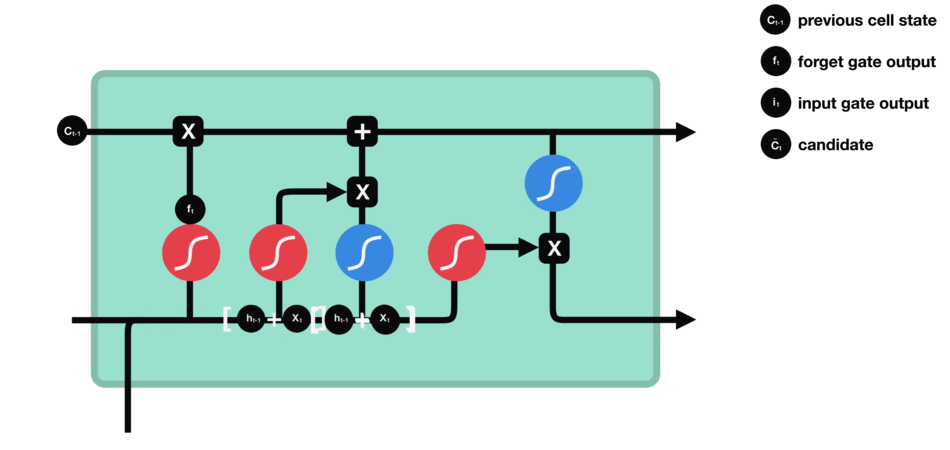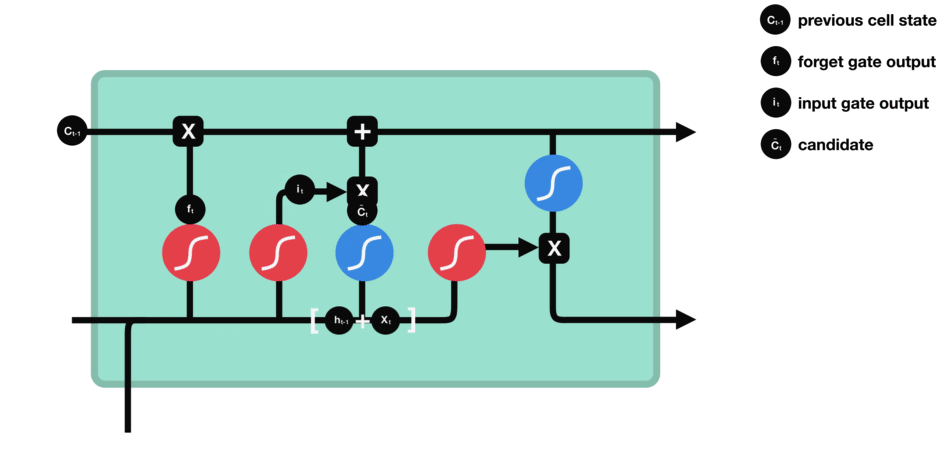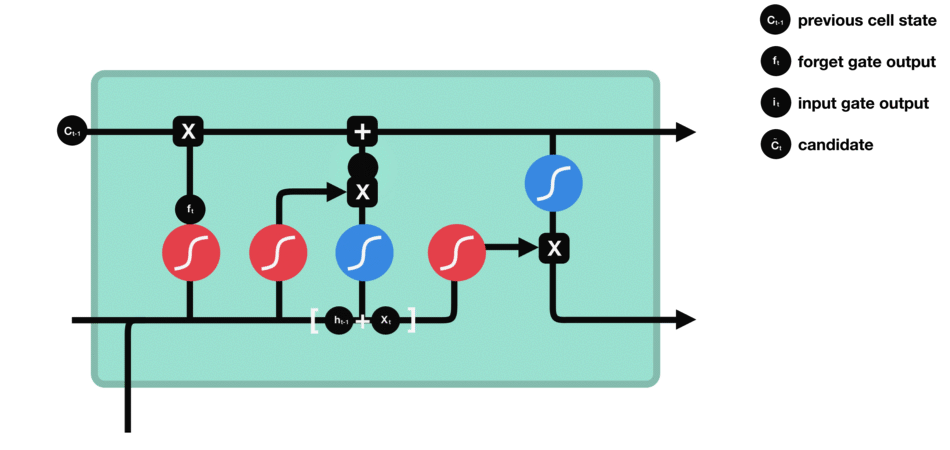
1. 遗忘门 ![]() :
:
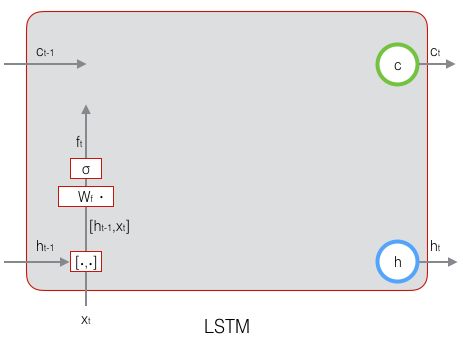 当前时刻的遗忘门计算
当前时刻的遗忘门计算
 遗忘门
遗忘门
2. 输入门 ![]() :
:
 当前时刻的输入门计算
当前时刻的输入门计算
 输入门 & 候选单元状态
输入门 & 候选单元状态
3. 候选单元状态 ![]() :
:
 当前时刻的候选单元状态计算
当前时刻的候选单元状态计算
 输入门 & 候选单元状态
输入门 & 候选单元状态
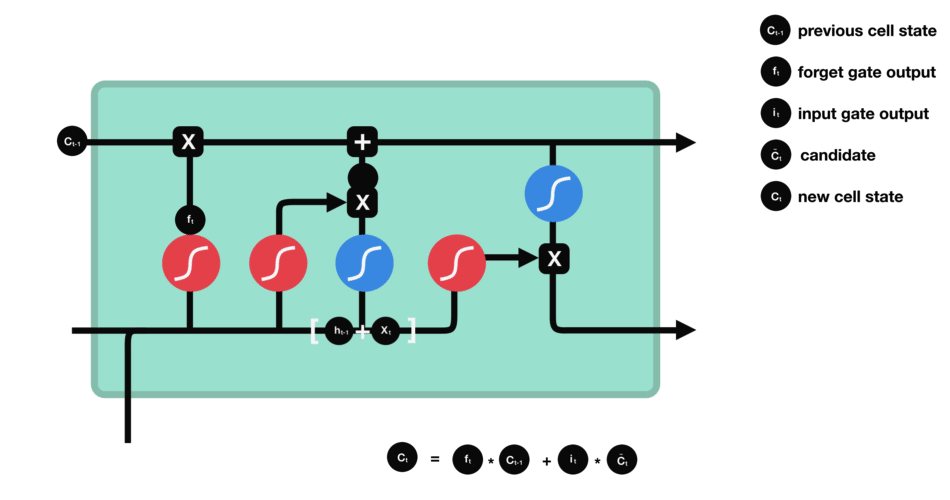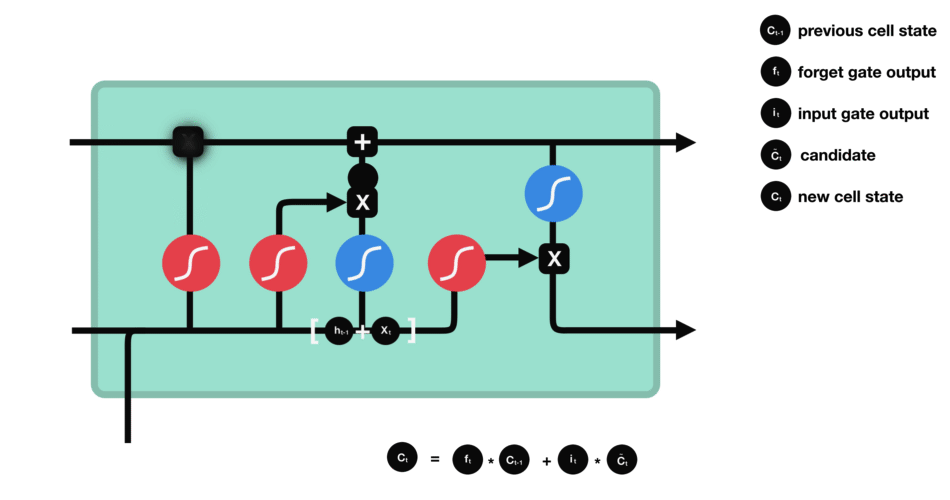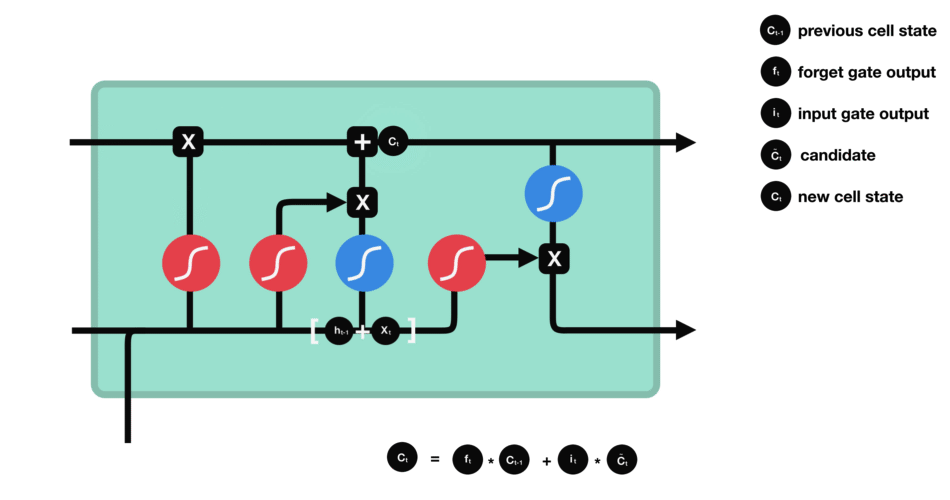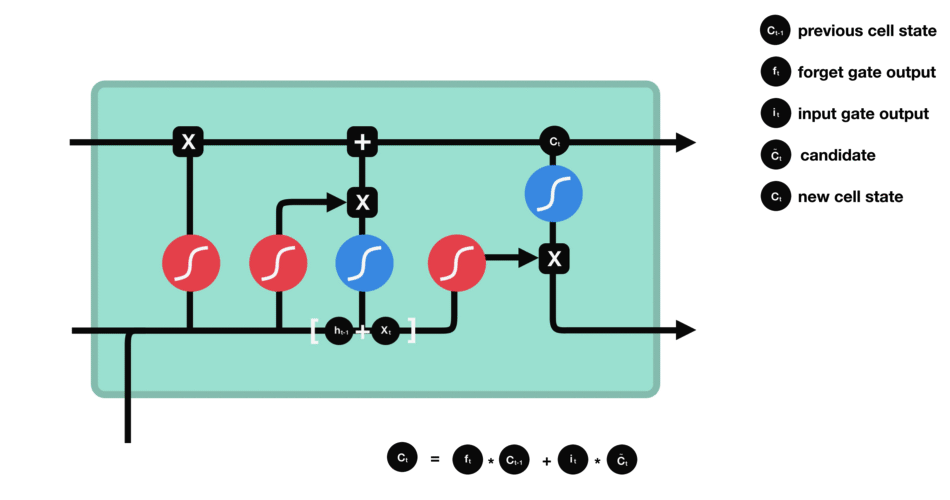
4. 单元状态 ![]() :
:
先由 当前时刻的 遗忘门 ![]() 按元素乘以 上一时刻的单元状态
按元素乘以 上一时刻的单元状态 ![]() (遗忘门调控),再用 当前时刻的 输入门
(遗忘门调控),再用 当前时刻的 输入门 ![]() 按元素乘以 当前时刻的 候选单元状态
按元素乘以 当前时刻的 候选单元状态 ![]() (输入门调控),再将 两积求和 得到:
(输入门调控),再将 两积求和 得到:
其中,符号 ![]() 表示 按元素相乘,其通过元素值域为 [0, 1] 的输入门、遗忘门和输出门来控制隐藏状态中的信息流动。
表示 按元素相乘,其通过元素值域为 [0, 1] 的输入门、遗忘门和输出门来控制隐藏状态中的信息流动。
 当前时刻的单元状态计算
当前时刻的单元状态计算
从而,LSTM 关于 当前的记忆和长期的记忆就被组合 在一起了,形成了新的单元状态。由于 遗忘门 ![]() 的控制,它可以保存很久很久之前的信息,由于 输入门
的控制,它可以保存很久很久之前的信息,由于 输入门 ![]() 的控制,它又可以避免当前无关紧要的内容进入记忆。
的控制,它又可以避免当前无关紧要的内容进入记忆。
 单元状态
单元状态
5. 输出门 ![]() :
:
 当前时刻的输出门计算
当前时刻的输出门计算
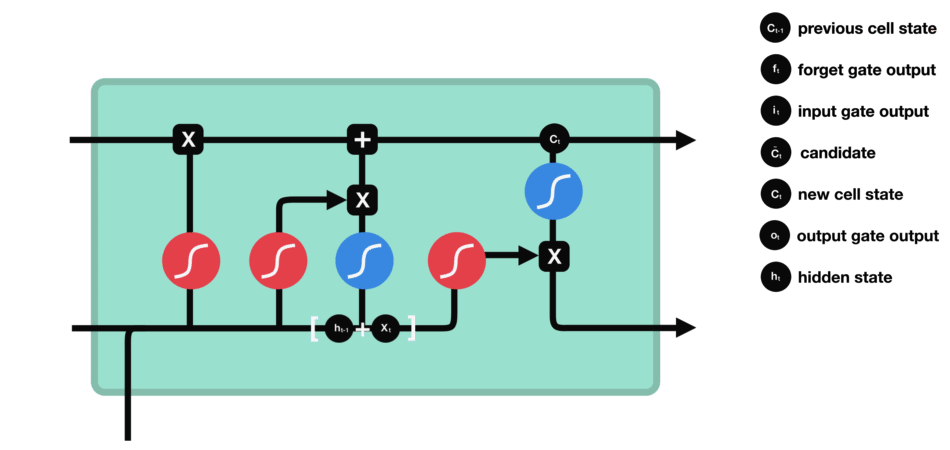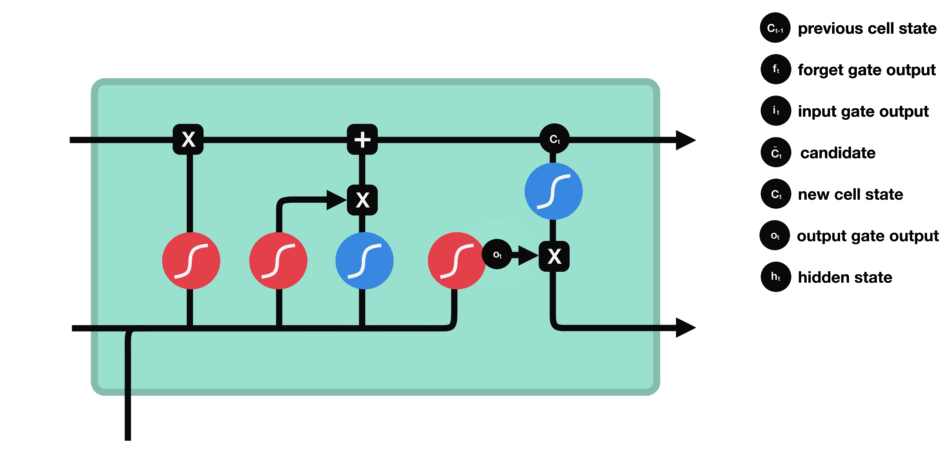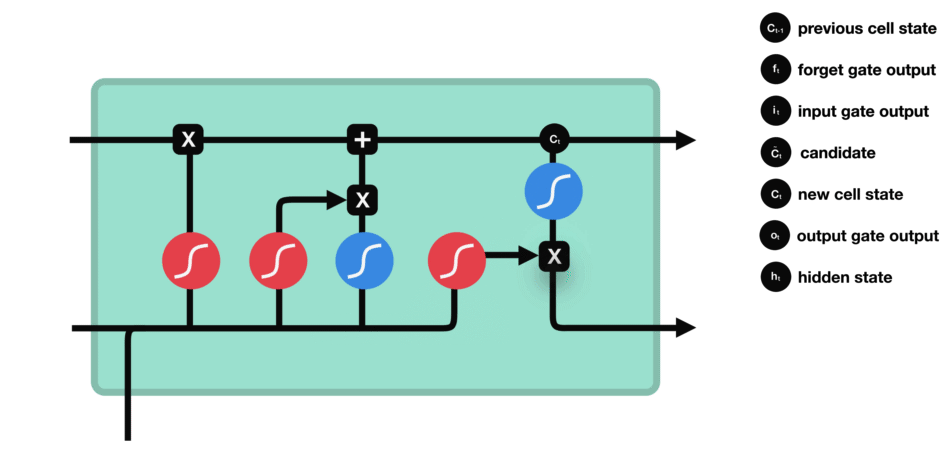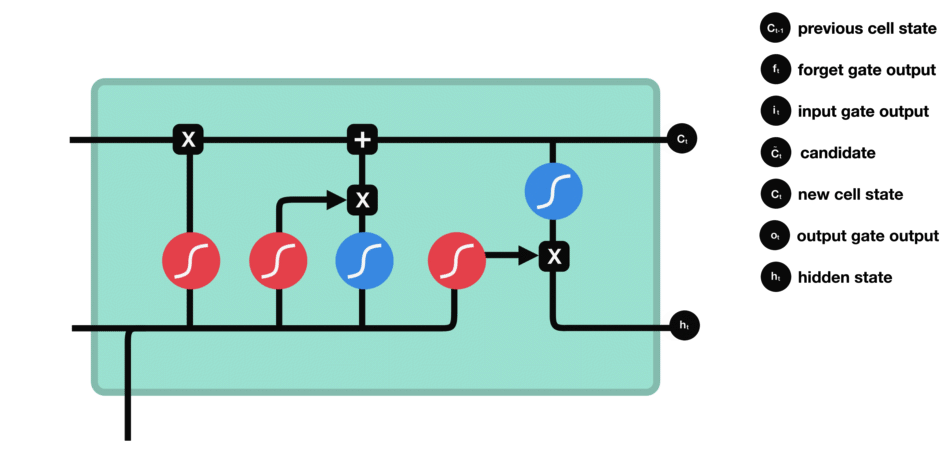 输出门
输出门
6. 隐藏状态 / 最终输出 ![]() :
:
由 当前时刻的 输出门 ![]() 和 当前时刻的 记忆单元状态
和 当前时刻的 记忆单元状态 ![]() 共同决定:
共同决定:
 当前时刻的隐藏状态/最终输出计算
当前时刻的隐藏状态/最终输出计算
7. 输出层 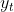 ,
,
即将 隐藏状态 / 最终输出 ![]() 馈入一个 全连接层 输出:
馈入一个 全连接层 输出:
当然,严格来说,这已经是 LSTM 之外的运算了,故此处仅简要提及。
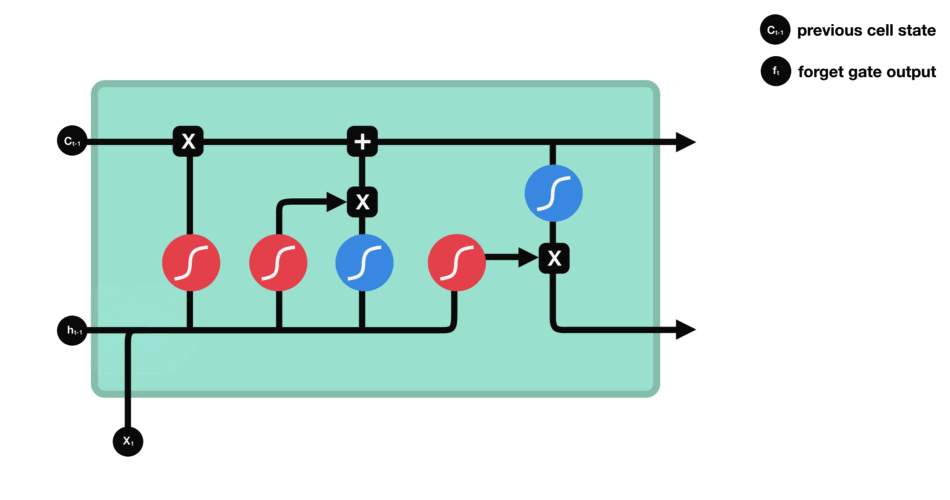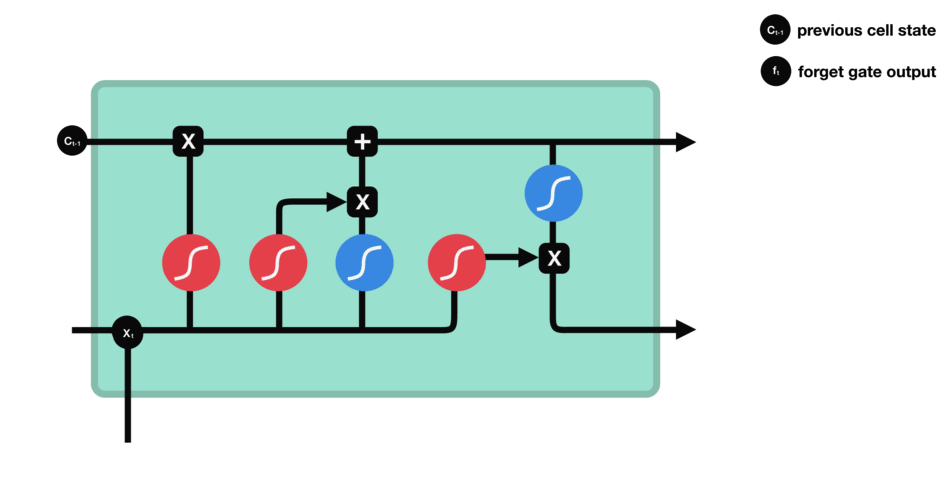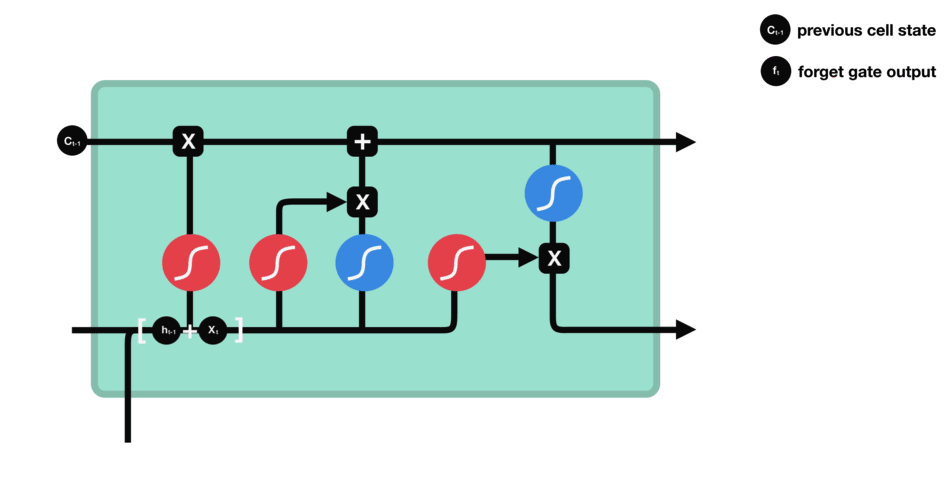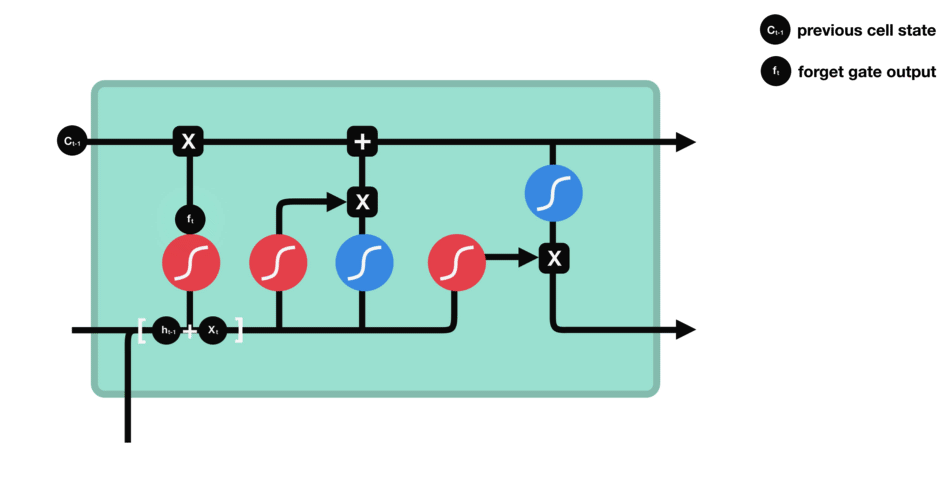
上述 LSTM 计算过程的完整回顾:
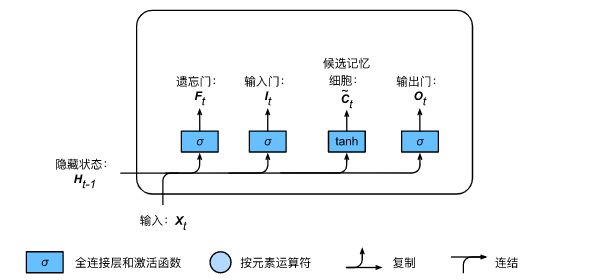
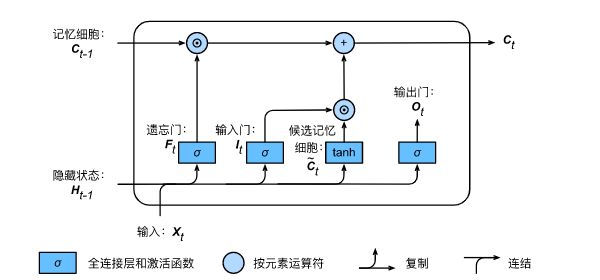
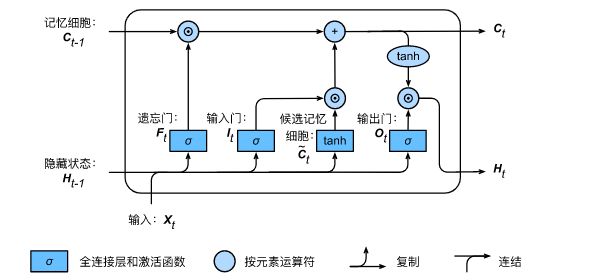 复制 (Copy)、连结 (Concatenate)
复制 (Copy)、连结 (Concatenate)
四、长短期记忆网络的训练
一方面,在一个训练好的 LSTM 中:
- 当输入序列中没有重要的新信息时,LSTM 的遗忘门的值接近于 1,输入门的值接近于 0,此时当前的信息会被大部分舍弃,而过去的记忆会被大部分保存,从而实现了长期记忆功能;
- 当输入序列中出现了重要的新信息时,LSTM 应将其存入记忆中,此时其输入门的值会接近于 1;
- 当输入的序列中出现了重要信息,且该信息意味着之前的记忆不再重要时,输入门的值接近 1,而遗忘门的值接近于0,从而旧的记忆被遗忘,新的重要信息被记忆。
经过如此设计,整个 LSTM 网络更容易学习到序列之间的长期依赖。
另一方面,关于 激活函数,LSTM 的遗忘门、输入门和输出门使用了 Sigmoid;在生成候选记忆时,使用了双曲正切函数 Tanh。值得注意的是,这两个激活函数都是 饱和的,也就是说在输入达到一定值的情况下,输出就不会发生明显变化了。若用 非饱和 的激活函数,例如 ReLU,那么将难以实现门控的效果。Sigmoid 函数的输出在 0~1 之间,符合 门控的物理定义。且当输入较大或较小时, 其输出会非常接近 1 或 0,从而 保证该门的开或关。在生成候选记忆时,使用 Tanh 函数,是因为其输出在 −1~1 之间,这与大多数场景下特征分布是 0 中心 的规律吻合。此外,Tanh 函数在输入为 0 附近相比 Sigmoid 函数 有更大的梯度,通常 使模型收敛更快。
当然,激活函数的选择也不是一成不变的。例如在原始 LSTM 中,使用的激活函数是 Sigmoid 函数的变 种,h(x) = 2Sigmoid(x)−1,g(x)=4Sigmoid(x)−2,这两个函数的范围分别是 [−1,1] 和 [−2,2]。并且在原始 LSTM 中,只有输入门和输出门,没有遗忘门,其中输入经过输入门后是直接与记忆相加的,所以输入门控 g(x) 的值是 0 中心的。后来经过大量的研究和实验,人们发现 增加遗忘门对 LSTM 的性能有很大的提升,并且 h(x) 使用 Tanh 比 2Sigmoid(x)−1 要好,所以现代 LSTM 采用 Sigmoid 和 Tanh 作为激活函数。事实上,在门控中,使用 Sigmoid 是几乎所有现代神经网络模块的共同选择。例如在 GRU 和 各种注意力机制 中,也广泛使用 Sigmoid 作为门控的激活函数。
此外,在一些对计算能力首先的设备,诸如可穿戴设备中,由于 Sigmoid 函数求指数需要一定的计算量,此时会使用 0/1门 (Hard Gate) 让门控输出为 0 或 1 的离散值,即当输入小于阈值时,门控输出为 0;当输入大于阈值时,输出为 1。从而在性能下降不显著的情况下,减小计算 量。经典的 LSTM 在计算各门控时,通常使用输入 ![]() 和隐层输出
和隐层输出 ![]() 参与门控计算。例如对于输入门的更新:
参与门控计算。例如对于输入门的更新:
![]()
其最常见的变种是加入了 窥孔连接,让记忆 ![]() 也参与到了门控的计算中,此时输入门的更新方式变为
也参与到了门控的计算中,此时输入门的更新方式变为
![]()
最后,训练过程的相关数学推导 详见:长短时记忆网络的训练
五、长短期记忆网络的实现
仍使用周杰伦歌词数据集来训练模型作词,首先读取数据集:
import numpy as np
import torch
from torch import nn, optim
import torch.nn.functional as F
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
(corpus_indices, char_to_idx, idx_to_char, vocab_size) = d2l.load_data_jay_lyrics()5.1 从头实现
5.1.1 初始化模型参数
对模型参数进行初始化,其中,超参数 num_hiddens 定义了隐藏单元的个数。
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
print('will use', device)
def get_params():
def _one(shape):
ts = torch.tensor(np.random.normal(0, 0.01, size=shape), device=device, dtype=torch.float32)
return torch.nn.Parameter(ts, requires_grad=True)
def _three():
return (_one((num_inputs, num_hiddens)),
_one((num_hiddens, num_hiddens)),
torch.nn.Parameter(torch.zeros(num_hiddens, device=device, dtype=torch.float32), requires_grad=True))
W_xf, W_hf, b_f = _three() # 遗忘门参数
W_xi, W_hi, b_i = _three() # 输入门参数
W_xc, W_hc, b_c = _three() # 候选单元状态参数
W_xo, W_ho, b_o = _three() # 输出门参数
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = torch.nn.Parameter(torch.zeros(num_outputs, device=device, dtype=torch.float32), requires_grad=True)
return nn.ParameterList([W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q])
5.1.2 定义模型
在初始化函数中,长短期记忆的隐藏状态需要返回额外的形状为(批量大小, 隐藏单元个数) 的值为 0 的记忆单元状态。
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
以下根据长短期记忆的计算表达式定义 LSTM 模型。注意,只有当前时刻的隐藏状态 ![]() 会传递到输出层,而当前时刻的单元状态
会传递到输出层,而当前时刻的单元状态 ![]() 不参与输出层计算 (注意,指的是最后最后的输出 层,不是输出 门 !!!)。
不参与输出层计算 (注意,指的是最后最后的输出 层,不是输出 门 !!!)。
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
# 1. 遗忘门
F = torch.sigmoid(torch.matmul(X, W_xf) + torch.matmul(H, W_hf) + b_f)
# 2. 输入门
I = torch.sigmoid(torch.matmul(X, W_xi) + torch.matmul(H, W_hi) + b_i)
# 3. 候选单元状态
C_tilda = torch.tanh(torch.matmul(X, W_xc) + torch.matmul(H, W_hc) + b_c)
# 4. 单元状态
C = F * C + I * C_tilda
# 5. 输出门
O = torch.sigmoid(torch.matmul(X, W_xo) + torch.matmul(H, W_ho) + b_o)
# 6. 隐藏状态 / 最终输出
H = O * C.tanh()
# 输出层 (不要和输出门混淆了)
Y = torch.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H, C)
5.1.3 训练模型并创作歌词
在训练模型时只使用相邻采样。设置好超参数后,将训练模型并根据前缀“分开”和“不分开”分别创作长度为50个字符的一段歌词。
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
每过 40 个迭代周期便根据当前训练的模型创作一段歌词。
d2l.train_and_predict_rnn(lstm, get_params, init_lstm_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, False, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
输出:
epoch 40, perplexity 211.416571, time 1.37 sec
- 分开 我不的我 我不的我 我不的我 我不的我 我不的我 我不的我 我不的我 我不的我 我不的我 我不的我
- 不分开 我不的我 我不的我 我不的我 我不的我 我不的我 我不的我 我不的我 我不的我 我不的我 我不的我
epoch 80, perplexity 67.048346, time 1.35 sec
- 分开 我想你你 我不要再想 我不要这我 我不要这我 我不要这我 我不要这我 我不要这我 我不要这我 我不
- 不分开 我想你你想你 我不要这不样 我不要这我 我不要这我 我不要这我 我不要这我 我不要这我 我不要这我
epoch 120, perplexity 15.552743, time 1.36 sec
- 分开 我想带你的微笑 像这在 你想我 我想你 说你我 说你了 说给怎么么 有你在空 你在在空 在你的空
- 不分开 我想要你已经堡 一样样 说你了 我想就这样着你 不知不觉 你已了离开活 后知后觉 我该了这生活 我
epoch 160, perplexity 4.274031, time 1.35 sec
- 分开 我想带你 你不一外在半空 我只能够远远著她 这些我 你想我难难头 一话看人对落我一望望我 我不那这
- 不分开 我想你这生堡 我知好烦 你不的节我 后知后觉 我该了这节奏 后知后觉 又过了一个秋 后知后觉 我该
5.2 简洁实现
在Gluon 中可以直接调用 rnn 模块中的 LSTM 类。
lr = 1e-2 # 注意调整学习率
lstm_layer = nn.LSTM(input_size=vocab_size, hidden_size=num_hiddens)
model = d2l.RNNModel(lstm_layer, vocab_size)
d2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
当然,Pytorch 等大部分框架都要直接封装好的 API 可供调用。
输出:
epoch 40, perplexity 1.020401, time 1.54 sec
- 分开始想担 妈跟我 一定是我妈在 因为分手前那句抱歉 在感动 穿梭时间的画面的钟 从反方向开始移动 回到
- 不分开始想像 妈跟我 我将我的寂寞封闭 然后在这里 不限日期 然后将过去 慢慢温习 让我爱上你 那场悲剧
epoch 80, perplexity 1.011164, time 1.34 sec
- 分开始想担 你的 从前的可爱女人 温柔的让我心疼的可爱女人 透明的让我感动的可爱女人 坏坏的让我疯狂的可
- 不分开 我满了 让我疯狂的可爱女人 漂亮的让我面红的可爱女人 温柔的让我心疼的可爱女人 透明的让我感动的可
epoch 120, perplexity 1.025348, time 1.39 sec
- 分开始共渡每一天 手牵手 一步两步三步四步望著天 看星星 一颗两颗三颗四颗 连成线背著背默默许下心愿 看
- 不分开 我不懂 说了没用 他的笑容 有何不同 在你心中 我不再受宠 我的天空 是雨是风 还是彩虹 你在操纵
epoch 160, perplexity 1.017492, time 1.42 sec
- 分开始乡相信命运 感谢地心引力 让我碰到你 漂亮的让我面红的可爱女人 温柔的让我心疼的可爱女人 透明的让
- 不分开 我不能再想 我不 我不 我不能 爱情走的太快就像龙卷风 不能承受我已无处可躲 我不要再想 我不要再
参考资料:
《百面机器学习》
一份详细的LSTM和GRU图解 -ATYUN
零基础入门深度学习(6) - 长短时记忆网络(LSTM) - 作业部落 Cmd Markdown 编辑阅读器
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Dive-into-DL-PyTorch