2022-kaggle-nlp赛事:Feedback Prize - English Language Learning
文章目录
-
- 零、背景介绍
-
- 0.1 比赛目标
- 0.2 数据集
- 0.3 注意事项
- 一、设置
-
- 1.1 导入相关库
- 1.2 设置超参数和随机种子
- 1.3 启动wandb
- 二、 数据预处理
-
- 2.1 定义前处理函数,tokenizer文本
- 2.2 定义Dataset,并将数据装入DataLoader
- 三、辅助函数
- 四、池化
- 五、模型
- 六、定义训练和验证函数
-
- 6.1 定义优化器调度器和损失函数
- 6.2 定义训练函数和评估函数
- 七、训练
-
- 7.1 定义训练函数
- 7.2 开始训练
- 八、推理
- 九、改进
-
- 9.1 设置
- 9.2 数据预处理
-
- 9.2.1 加载测试集
- 9.2.2 4折交叉
- 9.3 模型
- 9.4 定义优化器
- 9.5 训练
-
- 9.5.1 定义训练函数
- 9.5.2 开始训练
- 9.6 推理
- 十、Utilizing Transformer Representations Efficiently
-
- 10.1 池化
本文第九章改进后的代码已公开,直接fork下来跑就行,地址:《FB3 English Language Learning》,看完觉得不错的vote一下,谢各位了。
零、背景介绍
0.1 比赛目标
写作是一项基本技能。可惜很少学生能够磨练,因为学校很少布置写作任务。学习英语作为第二语言的学生,即英语语言学习者(ELL, English Language Learners),尤其受到缺乏实践的影响。现有的工具无法根据学生的语言能力提供反馈,导致最终评估可能对学习者产生偏差。数据科学可够改进自动反馈工具,以更好地支持这些学习者的独特需求。
本次比赛的目标是评估8-12年级英语学习者(ELL,)的语言水平。利用ELLs写的文章作为数据集,开发更好地支持所有学生写作能力的模型。
0.2 数据集
本次比赛数据集(ELLIPSE语料库)包括8-12年级英语学习者(ELL)撰写的议论文。论文根据六个分析指标进行评分:cohesion, syntax, vocabulary, phraseology, grammar, and conventions.(衔接、语法、词汇、短语、语法和惯例)。分数范围从1.0到5.0,增量为0.5。得分越高,表示该能力越熟练。您的任务是预测测试集论文的六个指标分数。其中一些文章出现在 Feedback Prize - Evaluating Student Writing 和 Feedback Prize - Predicting Effective Arguments 的数据集中,欢迎您在本次比赛中使用这些早期数据集。
文件和字段:
- train.csv:由唯一的
text_id标识,full_text字段表示文章全文,还有另外6个写作评分指标 - test.csv:只有text_id和full_text字段,且只有三个测试样本。
- sample_submission.csv :提交文件范例
训练集格式如下:
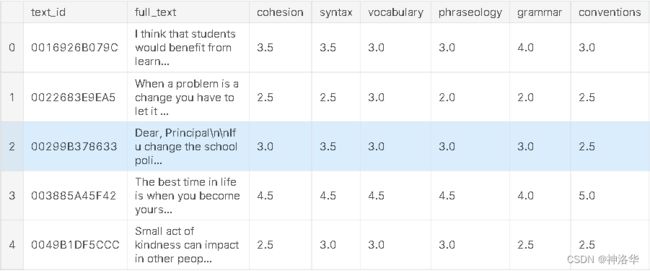
评测指标:

也就是所有测试样本6项指标的平均MSE
0.3 注意事项
请注意,这是一场 Code Competition,即需要最终提交kaggle notebook而不是submission.csv。
- test.csv只有三个测试样本。当提交kaggle notebook时系统会自动进行评分,测试集的三个样本将被完整的测试集替换(大约2700篇论文);
- save version之后提交,其中提交的csv文件必须命名为Submission.csv
- notebook运行时间不能大于9小时,且不能联网(也就是不能直接下载预训练模型,安装别的库或者新的版本等等),但是允许使用免费公开的外部数据,包括预训练模型(从kaggle 上的dataset加载Bert model,后面会提到)
一、设置
- 《ICLR 2021 | 微软DeBERTa:SuperGLUE上的新王者》、《DeBERTa》
- 《Utilizing Transformer Representations Efficiently》讲了很多模型训练问题,在代码区投票最高
- 导入相关库,设置超参数和随机种子
- 本次使用的模型是DeBERTaV3,主要参考了比赛区代码《FB3 single pytorch model [train]》(此人参考的是《FB3 / Deberta-v3-base baseline [train]》)
- 因为这次比较提交的notebook不能联网,不能下载预训练模型,所以input加入了BERT models的预训练数据

1.1 导入相关库
import os,gc,re,ast,sys,copy,json,time,datetime,math,string,pickle,random,joblib,itertools
from distutils.util import strtobool
import warnings
warnings.filterwarnings('ignore')
import scipy as sp
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tqdm.auto import tqdm
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import StratifiedKFold, GroupKFold, KFold,train_test_split
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Parameter
from torch.optim import Adam, SGD, AdamW
from torch.utils.data import DataLoader, Dataset
from torch.utils.checkpoint import checkpoint
import transformers,tokenizers
print(f'transformers.__version__: {transformers.__version__}')
print(f'tokenizers.__version__: {tokenizers.__version__}')
from transformers import AutoTokenizer, AutoModel, AutoConfig
from transformers import get_linear_schedule_with_warmup, get_cosine_schedule_with_warmup
os.environ['TOKENIZERS_PARALLELISM']='true'
transformers.__version__: 4.20.1
tokenizers.__version__: 0.12.1
1.2 设置超参数和随机种子
class CFG:
str_now = datetime.datetime.now().strftime('%Y%m%d-%H%M')
model = 'microsoft/deberta-v3-base' #Iv3-large 会超时
model_path='../input/microsoftdebertav3large/deberta-v3-base' # 不能联网,只能使用本地模型
batch_size ,n_targets,num_workers = 8,6,4
target_cols = ['cohesion', 'syntax', 'vocabulary', 'phraseology', 'grammar', 'conventions']
epochs,print_freq = 5,20 # 训练时每隔20step打印一次
loss_func = 'RMSE' # 'SmoothL1', 'RMSE'
pooling = 'attention' # mean, max, min, attention, weightedlayer
gradient_checkpointing = True
gradient_accumulation_steps = 1 # 是否使用梯度累积更新
max_grad_norm = 1000 #梯度裁剪
apex = True # 是否进行自动混合精度训练
scheduler = 'cosine'
num_cycles ,num_warmup_steps= 0.5,0
encoder_lr,decoder_lr,min_lr = 2e-5,2e-5 ,1e-6
max_len = 512
weight_decay = 0.01
fgm = True # 是否使用fgm对抗网络攻击
wandb=True # 是否启用wandb
adv_lr,adv_eps,eps,betas = 1,0.2,1e-6,(0.9, 0.999)
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
save_all_models=False # 是否每个epoch都保存数据
OUTPUT_DIR = f"./{model.replace('/', '-')}/"
train_file = '../input/feedback-prize-english-language-learning/train.csv'
test_file = '../input/feedback-prize-english-language-learning/test.csv'
submission_file = '../input/feedback-prize-english-language-learning/sample_submission.csv'
if not os.path.exists(CFG.OUTPUT_DIR):
os.makedirs(CFG.OUTPUT_DIR)
CFG.OUTPUT_DIR
'./microsoft-deberta-v3-base/'
设置随机种子 固定结果
def set_seeds(seed):
random.seed(seed)
np.random.seed(seed) # 保证后续使用random函数时,产生固定的随机数
torch.manual_seed(seed) # 固定随机种子(CPU)
if torch.cuda.is_available(): # 固定随机种子(GPU)
torch.cuda.manual_seed(seed) # 为当前GPU设置
torch.cuda.manual_seed_all(seed) # 为所有GPU设置
torch.backends.cudnn.deterministic = True # 固定网络结构
set_seeds(1111)
1.3 启动wandb
我的方式是预先在kaggle notebook的Add-ons secrets下面写入了wandb个人的key,没有这样写入的,直接在下面
wandb.login(key=api_key)部分将api_key改为自己的wandb key就行。
线下训练时可以启动wandb提交时不能联网,需设置CFG.wandb=False
if CFG.wandb:
import wandb
try:
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
api_key = user_secrets.get_secret("WANDB")
wandb.login(key=api_key)
except:
wandb.login(anonymous='must')
print('To use your W&B account,\nGo to Add-ons -> Secrets and provide your W&B access token. Use the Label name as WANDB. \nGet your W&B access token from here: https://wandb.ai/authorize')
def class2dict(f):
return dict((name, getattr(f, name)) for name in dir(f) if not name.startswith('__'))
run = wandb.init(project='FB3-Public',
name=CFG.model,
config=class2dict(CFG),
group=CFG.model,
job_type="train")
二、 数据预处理
2.1 定义前处理函数,tokenizer文本
为了将训练测试集都统一处理,测试集添加
label=[0,0,0,0,0,0]
from datasets import Dataset
def preprocess(df,tokenizer,types=True):
if types:
labels = np.array(df[["cohesion", "syntax", "vocabulary", "phraseology", "grammar", "conventions"]])
else:
labels=df["labels"]
text=list(df['full_text'].iloc[:])
encoding=tokenizer(text,truncation=True,padding="max_length",
max_length=CFG.max_len,return_tensors="np")#训练集中划分的训练集
return encoding,labels
df=pd.read_csv(CFG.train_file)
train_df, val_df = train_test_split(df[:100], test_size=0.2, random_state=1111, shuffle=True)
test_df = pd.read_csv(CFG.test_file)
test_df['labels']=None
test_df['labels']=test_df['labels'].apply(lambda x:[0,0,0,0,0,0])
tokenizer = AutoTokenizer.from_pretrained(CFG.model_path)
train_encoding,train_label=preprocess(train_df,tokenizer,True)
val_encoding,val_label=preprocess(val_df,tokenizer,True)
test_encoding,test_label=preprocess(test_df,tokenizer,False)
test_encoding
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
{'input_ids': array([[ 1, 335, 266, ..., 265, 262, 2],
[ 1, 771, 274, ..., 0, 0, 0],
[ 1, 2651, 9805, ..., 0, 0, 0]]), 'token_type_ids': array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]]), 'attention_mask': array([[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0]])}
2.2 定义Dataset,并将数据装入DataLoader
from torch.utils.data import Dataset, DataLoader,TensorDataset
class MyDataset(Dataset):
def __init__(self,encoding,label):
self.inputs=encoding
self.label=label
# 读取单个样本
def __getitem__(self,idx):
item={key:torch.tensor(val[idx],dtype = torch.long) for key,val in self.inputs.items()}
label=torch.tensor(self.label[idx],dtype=torch.float)
return item,label
def __len__(self):
return len(self.label)
def collate(inputs): # 貌似是每个批次选这个批次的最大长度,去掉也没事吧
mask_len = int(inputs["attention_mask"].sum(axis=1).max())
for k, v in inputs.items():
inputs[k] = inputs[k][:,:mask_len]
return inputs
train_dataset=MyDataset(train_encoding,train_label)
val_dataset=MyDataset(val_encoding,val_label)
test_dataset=MyDataset(test_encoding,test_label)
#validation_dataset=MyDataset(validation_econding,list(validation_label))
train_loader=DataLoader(train_dataset,batch_size=CFG.batch_size,num_workers=CFG.num_workers,shuffle=True)
val_loader=DataLoader(val_dataset,batch_size=CFG.batch_size,num_workers=CFG.num_workers,shuffle=True)
test_loader=DataLoader(test_dataset,batch_size=CFG.batch_size,num_workers=CFG.num_workers,shuffle=False)#test数据不能shuffle啊,真坑死我了
#validation_loader=DataLoader(validation_dataset,batch_size=batch_size,shuffle=False)#test数据不能shuffle啊,真坑死我了
for i in test_loader:
print(i)
break
[{'input_ids': tensor([[ 1, 335, 266, ..., 265, 262, 2],
[ 1, 771, 274, ..., 0, 0, 0],
[ 1, 2651, 9805, ..., 0, 0, 0]]), 'token_type_ids': tensor([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0]])}, tensor([[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]])]
三、辅助函数
定义RMSELoss、评价指标MCRMSE分数、logger、FGM等。
class RMSELoss(nn.Module):
def __init__(self, reduction = 'mean', eps = 1e-9):
super().__init__()
self.mse = nn.MSELoss(reduction = 'none')
self.reduction = reduction
self.eps = eps
def forward(self, y_pred, y_true):
loss = torch.sqrt(self.mse(y_pred, y_true) + self.eps)
if self.reduction == 'none':
loss = loss
elif self.reduction == 'sum':
loss = loss.sum()
elif self.reduction == 'mean':
loss = loss.mean()
return loss
def MCRMSE(y_trues, y_preds):
scores = []
idxes = y_trues.shape[1]
for i in range(idxes):
y_true = y_trues[:, i]
y_pred = y_preds[:, i]
score = mean_squared_error(y_true, y_pred, squared = False)
scores.append(score)
mcrmse_score = np.mean(scores)
return mcrmse_score, scores
class AverageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n = 1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def asMinutes(s):
m = math.floor(s / 60)
s -= m * 60
return f'{int(m)}m {int(s)}s'
def timeSince(since, percent):
now = time.time()
s = now - since
es = s / (percent)
rs = es - s
return f'{str(asMinutes(s))} (remain {str(asMinutes(rs))})'
def get_logger(filename=CFG.OUTPUT_DIR+'train'):
from logging import getLogger, INFO, StreamHandler, FileHandler, Formatter
logger = getLogger(__name__)
logger.setLevel(INFO)
handler1 = StreamHandler()
handler1.setFormatter(Formatter("%(message)s"))
handler2 = FileHandler(filename=f"{filename}.log")
handler2.setFormatter(Formatter("%(message)s"))
logger.addHandler(handler1)
logger.addHandler(handler2)
return logger
logger= get_logger()
logger
<_Logger __main__ (INFO)>
Fast Gradient Method (FGM)
FGM有关介绍可参考Reference、《功守道:NLP中的对抗训练 + PyTorch实现》
class FGM():
def __init__(self, model):
self.model = model
self.backup = {}
def attack(self, epsilon = 1., emb_name = 'word_embeddings'):
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
self.backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0:
r_at = epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self, emb_name = 'word_embeddings'):
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}
四、池化
- 池化教程可参考《Utilizing Transformer Representations Efficiently》、WeightedLayerPooling
- 有个小哥在 Attention pooling中做了比较:AttentionPooling (0.4509) > MultiLayerCLSPooling (0.4511) > MeanPooling(0.4512),并发现发现池化性能在很大程度上取决于数据集的拆分。使用
n_fold=4,seed=42能取得0.43的成绩(排行榜前1000名都是0.43分)。
class MeanPooling(nn.Module):
def __init__(self):
super(MeanPooling, self).__init__()
def forward(self, last_hidden_state, attention_mask):
input_mask_expanded = attention_mask.unsqueeze(-1).expand(last_hidden_state.size()).float()
sum_embeddings = torch.sum(last_hidden_state * input_mask_expanded, 1)
sum_mask = input_mask_expanded.sum(1)
sum_mask = torch.clamp(sum_mask, min = 1e-9)
mean_embeddings = sum_embeddings/sum_mask
return mean_embeddings
class MaxPooling(nn.Module):
def __init__(self):
super(MaxPooling, self).__init__()
def forward(self, last_hidden_state, attention_mask):
input_mask_expanded = attention_mask.unsqueeze(-1).expand(last_hidden_state.size()).float()
embeddings = last_hidden_state.clone()
embeddings[input_mask_expanded == 0] = -1e4
max_embeddings, _ = torch.max(embeddings, dim = 1)
return max_embeddings
class MinPooling(nn.Module):
def __init__(self):
super(MinPooling, self).__init__()
def forward(self, last_hidden_state, attention_mask):
input_mask_expanded = attention_mask.unsqueeze(-1).expand(last_hidden_state.size()).float()
embeddings = last_hidden_state.clone()
embeddings[input_mask_expanded == 0] = 1e-4
min_embeddings, _ = torch.min(embeddings, dim = 1)
return min_embeddings
#Attention pooling
class AttentionPooling(nn.Module):
def __init__(self, in_dim):
super().__init__()
self.attention = nn.Sequential(
nn.Linear(in_dim, in_dim),
nn.LayerNorm(in_dim),
nn.GELU(),
nn.Linear(in_dim, 1),
)
def forward(self, last_hidden_state, attention_mask):
w = self.attention(last_hidden_state).float()
w[attention_mask==0]=float('-inf')
w = torch.softmax(w,1)
attention_embeddings = torch.sum(w * last_hidden_state, dim=1)
return attention_embeddings
#There may be a bug in my implementation because it does not work well.
class WeightedLayerPooling(nn.Module):
def __init__(self, num_hidden_layers, layer_start: int = 4, layer_weights = None):
super(WeightedLayerPooling, self).__init__()
self.layer_start = layer_start
self.num_hidden_layers = num_hidden_layers
self.layer_weights = layer_weights if layer_weights is not None \
else nn.Parameter(
torch.tensor([1] * (num_hidden_layers+1 - layer_start), dtype=torch.float)
)
def forward(self, ft_all_layers):
all_layer_embedding = torch.stack(ft_all_layers)
all_layer_embedding = all_layer_embedding[self.layer_start:, :, :, :]
weight_factor = self.layer_weights.unsqueeze(-1).unsqueeze(-1).unsqueeze(-1).expand(all_layer_embedding.size())
weighted_average = (weight_factor*all_layer_embedding).sum(dim=0) / self.layer_weights.sum()
return weighted_average
五、模型
FB3作者试了10个bert模型10折的效果,然后集成,参考《FB3 Deberta Family Inference [9/28 UPDATED]》
CFG1 : 10 fold deberta-v3-base CV/LB: 0.4595/0.44
CFG2 : 10 fold deberta-v3-large CV/LB: 0.4553/0.44
CFG3 : 10 fold deberta-v2-xlarge CV/LB: 0.4604/0.44
CFG4 : 10 fold deberta-v3-base FGM CV/LB: 0.4590/0.44
CFG5 : 10 fold deberta-v3-large FGM CV/LB: 0.4564/0.44
CFG6 : 10 fold deberta-v2-xlarge CV/LB: 0.4666/0.44
CFG7 : 10 fold deberta-v2-xlarge-mnli CV/LB: 0.4675/0.44
CFG8 : 10 fold deberta-v3-large unscale CV/LB: 0.4616/0.43
CFG9 : 10 fold deberta-v3-large unscale CV/LB: 0.4548/0.43
CFG10 :10 fold deberta-v3-large unscale CV/LB: 0.4569/0.43
- 使用太大的模型需要冻结低层 (v2-xlarge, funnnel, etc.)
if 'deberta-v2-xxlarge' in CFG.model:
self.model.embeddings.requires_grad_(False)
self.model.encoder.layer[:24].requires_grad_(False)
if 'deberta-v2-xlarge' in CFG.model:
self.model.embeddings.requires_grad_(False)
self.model.encoder.layer[:12].requires_grad_(False)
if 'funnel-transformer-xlarge' in CFG.model:
self.model.embeddings.requires_grad_(False)
self.model.encoder.blocks[:1].requires_grad_(False)
if 'funnel-transformer-large' in CFG.model:
self.model.embeddings.requires_grad_(False)
self.model.encoder.blocks[:1].requires_grad_(False)
if 'deberta-large' in CFG.model:
self.model.embeddings.requires_grad_(False)
self.model.encoder.layer[:16].requires_grad_(False)
if 'deberta-xlarge' in CFG.model:
self.model.embeddings.requires_grad_(False)
self.model.encoder.layer[:36].requires_grad_(False)
- FB3作者使用了Layer-Wise Learning Rate Dacay(LLRD),我这里没用
LLRD是一种对顶层应用较高的学习率而对底层应用较低的学习率的方法,通过设置顶层的学习速率并使用乘法衰减速率从上到下逐层降低学习速率来实现。
class FB3Model(nn.Module):
def __init__(self, CFG, config_path = None,pretrained=False):
super().__init__()
self.CFG = CFG
# 设置模型的config文件,根据此配置文件读取预训练模型
if config_path is None:
self.config = AutoConfig.from_pretrained(CFG.model_path, ouput_hidden_states = True)
self.config.save_pretrained(CFG.OUTPUT_DIR + 'config')
self.config.hidden_dropout = 0.
self.config.hidden_dropout_prob = 0.
self.config.attention_dropout = 0.
self.config.attention_probs_dropout_prob = 0.
logger.info(self.config)
else:
self.config = torch.load(config_path)
if pretrained:
self.model = AutoModel.from_pretrained(CFG.model_path, config=self.config)
else:
self.model = AutoModel.from_config(self.config)
if CFG.pooling == 'mean':
self.pool = MeanPooling()
elif CFG.pooling == 'max':
self.pool = MaxPooling()
elif CFG.pooling == 'min':
self.pool = MinPooling()
elif CFG.pooling == 'attention':
self.pool = AttentionPooling(self.config.hidden_size)
elif CFG.pooling == 'weightedlayer':
self.pool = WeightedLayerPooling(self.config.num_hidden_layers, layer_start = CFG.layer_start, layer_weights = None)
# 用一个全连接层得到预测的6类输出
self.fc = nn.Linear(self.config.hidden_size, self.CFG.n_targets)
# 根据池化方法选择输出
def feature(self,inputs):
outputs = self.model(**inputs)
if CFG.pooling != 'weightedlayer':
last_hidden_states = outputs[0]
feature = self.pool(last_hidden_states,inputs['attention_mask'])
else:
all_layer_embeddings = outputs[1]
feature = self.pool(all_layer_embeddings)
return feature
def forward(self,inputs):
feature = self.feature(inputs)
outout = self.fc(feature)
return outout
model = FB3Model(CFG, config_path = None,pretrained=True)
torch.save(model.config, './config.pth')
model.to(CFG.device)
六、定义训练和验证函数
- gradient_accumulation_steps:梯度累加。如果只有单卡,且可以加载模型,但batch受限的话可以使用梯度累加,进行N次前向后反向更新一次参数,相当于扩大了N倍的batch size。
- clip_grad_norm:梯度裁剪
- torch.cuda.amp:自动混合精度训练 —— 节省显存并加快推理速度( 《一文详解Transformers的性能优化的8种方法》)
6.1 定义优化器调度器和损失函数
def get_optimizer_params(model,encoder_lr,decoder_lr,weight_decay=0.0):
param_optimizer = list(model.named_parameters())
no_decay = ["bias", "LayerNorm.bias", "LayerNorm.weight"]
optimizer_parameters = [
{'params': [p for n, p in model.model.named_parameters() if not any(nd in n for nd in no_decay)],
'lr': encoder_lr,
'weight_decay': weight_decay},
{'params': [p for n, p in model.model.named_parameters() if any(nd in n for nd in no_decay)],
'lr': encoder_lr,
'weight_decay': 0.0},
{'params': [p for n, p in model.named_parameters() if "model" not in n],
'lr': decoder_lr,
'weight_decay': 0.0}
]
return optimizer_parameters
# 选择使用线性学习率衰减或者cos学习率衰减
def get_scheduler(cfg, optimizer, num_train_steps):
if cfg.scheduler == 'linear':
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps = cfg.num_warmup_steps,
num_training_steps = num_train_steps
)
elif cfg.scheduler == 'cosine':
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps = cfg.num_warmup_steps,
num_training_steps = num_train_steps,
num_cycles = cfg.num_cycles
)
return scheduler
from torch.optim import AdamW
optimizer_parameters = get_optimizer_params(model,CFG.encoder_lr, CFG.decoder_lr,CFG.weight_decay)
optimizer = AdamW(optimizer_parameters, lr=CFG.encoder_lr, eps=CFG.eps,betas=CFG.betas)
num_train_steps = len(train_loader) * CFG.epochs
scheduler = get_scheduler(CFG, optimizer, num_train_steps)
if CFG.loss_func == 'SmoothL1':
criterion = nn.SmoothL1Loss(reduction='mean')
elif CFG.loss_func == 'RMSE':
criterion = RMSELoss(reduction='mean')
6.2 定义训练函数和评估函数
def train_fn(train_loader, model, criterion, optimizer, epoch, scheduler, device):
losses = AverageMeter()
model.train()
scaler = torch.cuda.amp.GradScaler(enabled = CFG.apex) # 自动混合精度训练
start = end = time.time()
global_step = 0
if CFG.fgm:
fgm = FGM(model) # 对抗训练
for step, (inputs, labels) in enumerate(train_loader):
#attention_mask = inputs['attention_mask'].to(device)
inputs = collate(inputs)
for k, v in inputs.items():
inputs[k] = v.to(device)
labels = labels.to(device)
batch_size = labels.size(0)
with torch.cuda.amp.autocast(enabled = CFG.apex):
y_preds = model(inputs)
loss = criterion(y_preds, labels)
if CFG.gradient_accumulation_steps > 1:
loss = loss / CFG.gradient_accumulation_steps
losses.update(loss.item(), batch_size)
scaler.scale(loss).backward()
grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), CFG.max_grad_norm)
#Fast Gradient Method (FGM)
if CFG.fgm:
fgm.attack()
with torch.cuda.amp.autocast(enabled = CFG.apex):
y_preds = model(inputs)
loss_adv = criterion(y_preds, labels)
loss_adv.backward()
fgm.restore()
if (step + 1) % CFG.gradient_accumulation_steps == 0:
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
global_step += 1
scheduler.step()
end = time.time()
if step % CFG.print_freq == 0 or step == (len(train_loader) - 1):
print('Epoch: [{0}][{1}/{2}] '
'Elapsed {remain:s} '
'Loss: {loss.val:.4f}({loss.avg:.4f}) '
'Grad: {grad_norm:.4f} '
'LR: {lr:.8f} '
.format(epoch + 1, step, len(train_loader), remain = timeSince(start, float(step + 1)/len(train_loader)),
loss = losses,
grad_norm = grad_norm,
lr = scheduler.get_lr()[0]))
if CFG.wandb:
wandb.log({" loss": losses.val,
" lr": scheduler.get_lr()[0]})
return losses.avg
def valid_fn(valid_loader, model, criterion, device):
losses = AverageMeter()
model.eval()
preds ,targets= [],[]
start = end = time.time()
for step, (inputs, labels) in enumerate(valid_loader):
inputs = collate(inputs)
for k, v in inputs.items():
inputs[k] = v.to(device)
labels = labels.to(device)
batch_size = labels.size(0)
with torch.no_grad():
y_preds = model(inputs)
loss = criterion(y_preds, labels)
if CFG.gradient_accumulation_steps > 1:
loss = loss / CFG.gradient_accumulation_steps
losses.update(loss.item(), batch_size)
preds.append(y_preds.to('cpu').numpy())
targets.append(labels.to('cpu').numpy())
end = time.time()
if step % CFG.print_freq == 0 or step == (len(valid_loader)-1):
print('EVAL: [{0}/{1}] '
'Elapsed {remain:s} '
'Loss: {loss.val:.4f}({loss.avg:.4f}) '
.format(step, len(valid_loader),
loss=losses,
remain=timeSince(start, float(step+1)/len(valid_loader))))
predictions = np.concatenate(preds)
targets=np.concatenate(targets)
return losses.avg, predictions,targets
七、训练
7.1 定义训练函数
def train_loop():
best_score = np.inf
for epoch in range(CFG.epochs):
start_time = time.time()
logger.info(f"========== epoch: {epoch} training ==========")
avg_loss = train_fn(train_loader, model, criterion, optimizer, epoch, scheduler, CFG.device)
avg_val_loss, predictions,valid_labels = valid_fn(val_loader, model, criterion, CFG.device)
score, scores = MCRMSE(valid_labels, predictions)
elapsed = time.time() - start_time
logger.info(f'Epoch {epoch+1} - avg_train_loss: {avg_loss:.4f} avg_val_loss: {avg_val_loss:.4f} time: {elapsed:.0f}s')
logger.info(f'Epoch {epoch+1} - Score: {score:.4f} Scores: {scores}')
if CFG.wandb:
wandb.log({" epoch": epoch+1,
" avg_train_loss": avg_loss,
" avg_val_loss": avg_val_loss,
" score": score})
if best_score > score:
best_score = score
logger.info(f'Epoch {epoch+1} - Save Best Score: {best_score:.4f} Model')
torch.save({'model': model.state_dict(),
'predictions': predictions},
CFG.OUTPUT_DIR + "_best.pth")
if CFG.save_all_models:
torch.save({'model': model.state_dict(),
'predictions': predictions},
CFG.OUTPUT_DIR + "_epoch{epoch + 1}.pth")
7.2 开始训练
使用以上CFG超参数及microsoft/deberta-v3-base模型,不使用unscale和多折交叉验证,Best Score: 0.4648
train_loop()
if CFG.wandb:
wandb.finish()
========== epoch: 0 training ==========
Epoch: [1][0/391] Elapsed 0m 2s (remain 17m 13s) Loss: 2.8918(2.8918) Grad: inf LR: 0.00002000
Epoch: [1][390/391] Elapsed 8m 15s (remain 0m 0s) Loss: 0.3362(0.4871) Grad: 78659.0469 LR: 0.00001809
Epoch 1 - avg_train_loss: 0.4871 avg_val_loss: 0.3924 time: 519s
Epoch 1 - Score: 0.4909 Scores: [0.5139552, 0.5028605, 0.47576296, 0.47781754, 0.5014925, 0.47371823]
Epoch 1 - Save Best Score: 0.4909 Model
========== epoch: 1 training ==========
Epoch: [2][0/391] Elapsed 0m 1s (remain 9m 44s) Loss: 0.3781(0.3781) Grad: inf LR: 0.00001808
Epoch: [2][390/391] Elapsed 8m 14s (remain 0m 0s) Loss: 0.4184(0.3743) Grad: 156550.7969 LR: 0.00001309
Epoch 2 - avg_train_loss: 0.3743 avg_val_loss: 0.3731 time: 518s
Epoch 2 - Score: 0.4670 Scores: [0.49295992, 0.4471803, 0.42642388, 0.48949784, 0.49806547, 0.44805652]
Epoch 2 - Save Best Score: 0.4670 Model
========== epoch: 2 training ==========
Epoch: [3][0/391] Elapsed 0m 1s (remain 9m 22s) Loss: 0.3422(0.3422) Grad: inf LR: 0.00001307
Epoch: [3][390/391] Elapsed 8m 14s (remain 0m 0s) Loss: 0.4264(0.3477) Grad: 30027.1875 LR: 0.00000691
Epoch 3 - avg_train_loss: 0.3477 avg_val_loss: 0.3763 time: 517s
Epoch 3 - Score: 0.4715 Scores: [0.49935433, 0.4698818, 0.4369744, 0.49417937, 0.48269835, 0.44603842]
========== epoch: 3 training ==========
Epoch: [4][0/391] Elapsed 0m 1s (remain 9m 22s) Loss: 0.3345(0.3345) Grad: inf LR: 0.00000689
Epoch: [4][390/391] Elapsed 8m 15s (remain 0m 0s) Loss: 0.3789(0.3222) Grad: 113970.0625 LR: 0.00000191
Epoch 4 - avg_train_loss: 0.3222 avg_val_loss: 0.3712 time: 519s
Epoch 4 - Score: 0.4648 Scores: [0.4883219, 0.46181184, 0.4202939, 0.4787844, 0.48889253, 0.45086348]
Epoch 4 - Save Best Score: 0.4648 Model
========== epoch: 4 training ==========
Epoch: [5][0/391] Elapsed 0m 1s (remain 9m 18s) Loss: 0.3411(0.3411) Grad: inf LR: 0.00000190
Epoch: [5][390/391] Elapsed 8m 15s (remain 0m 0s) Loss: 0.2929(0.3068) Grad: 96642.0938 LR: 0.00000000
Epoch 5 - avg_train_loss: 0.3068 avg_val_loss: 0.3716 time: 518s
Epoch 5 - Score: 0.4651 Scores: [0.48936367, 0.4577376, 0.4213956, 0.48060682, 0.4890098, 0.4524079]
八、推理
def inference_fn(test_loader, model, device):
preds = []
model.eval()
model.to(device)
tk0 = tqdm(test_loader, total=len(test_loader))
for inputs,label in tk0:
for k, v in inputs.items():
inputs[k] = v.to(device)
with torch.no_grad():
y_preds = model(inputs)
preds.append(y_preds.to('cpu').numpy())
predictions = np.concatenate(preds)
return predictions
submission = pd.read_csv('../input/feedback-prize-english-language-learning/sample_submission.csv')
predictions = []
model = FB3Model(CFG, config_path = './config.pth',pretrained=False)
model.load_state_dict(torch.load(CFG.OUTPUT_DIR + "_best.pth",map_location=torch.device('cpu'))['model'])
prediction = inference_fn(test_loader, model, CFG.device)
prediction
array([[2.8611162, 2.5578291, 2.8050532, 2.8501422, 3.04253 , 2.9622886],
[2.7477272, 2.5338695, 2.79264 , 2.8682678, 3.024685 , 3.0156944],
[2.8779552, 2.6166203, 2.817436 , 2.8398242, 2.977949 , 2.9761167]],
dtype=float32)
test_df[CFG.target_cols] = prediction
submission = submission.drop(columns=CFG.target_cols).merge(test_df[['text_id'] + CFG.target_cols], on='text_id', how='left')
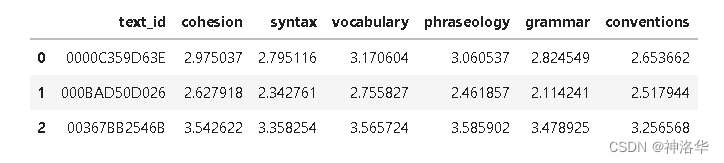
display(submission.head())
submission[['text_id'] + CFG.target_cols].to_csv('submission.csv', index=False)
九、改进
本来不想刷分的,不过还是稍微改进一下。deberta-v3-large会爆显存,貌似可以冻结浅层或者使用使用梯度累积更新等等。不过目前比较忙,没有实验,所以这部分还是base模型,不过用了4折交叉验证和LLRD。最终提交的notebook我已经公开了,直接跑就行,地址:《Fork of English Language Learning 157754》。
9.1 设置
启用LLRD(Layer-Wise Learning Rate Dacay),加入denug设置。
class CFG:
model_name = "microsoft/deberta-v3-base"
model_path = "../input/microsoftdebertav3large/deberta-v3-base"
batch_size ,n_targets,num_workers = 8,6,4
target_cols = ['cohesion', 'syntax', 'vocabulary', 'phraseology', 'grammar', 'conventions']
epochs,print_freq = 5,20 # 训练时每隔20step打印一次
save_all_models=False # 是否每个epoch都保存数据
gradient_checkpointing = True
loss_func = 'SmoothL1' # 'SmoothL1', 'RMSE'
pooling = 'attention' # mean, max, min, attention, weightedlayer
gradient_checkpointing = True
gradient_accumulation_steps = 1 # 是否使用梯度累积更新
max_grad_norm = 1000 #梯度裁剪
apex = True # 是否进行自动混合精度训练
# 启用llrd
layerwise_lr,layerwise_lr_decay = 5e-5,0.9
layerwise_weight_decay = 0.01
layerwise_adam_epsilon = 1e-6
layerwise_use_bertadam = False
scheduler = 'cosine'
num_cycles ,num_warmup_steps= 0.5,0
encoder_lr,decoder_lr,min_lr = 2e-5,2e-5 ,1e-6
max_len = 512
weight_decay = 0.01
fgm = True # 是否使用fgm对抗网络攻击
wandb=False
adv_lr,adv_eps,eps,betas = 1,0.2,1e-6,(0.9, 0.999)
unscale =True
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
seed=42
n_fold=4
trn_fold=list(range(n_fold))
debug=False # debug表示只使用少量样本跑代码,且n_fold=2,epoch=2
OUTPUT_DIR = f"./{model_name.replace('/', '-')}/"
train_file = '../input/feedback-prize-english-language-learning/train.csv'
test_file = '../input/feedback-prize-english-language-learning/test.csv'
submission_file = '../input/feedback-prize-english-language-learning/sample_submission.csv'
if not os.path.exists(CFG.OUTPUT_DIR):
os.makedirs(CFG.OUTPUT_DIR)
set_seeds(CFG.seed)
CFG.OUTPUT_DIR
9.2 数据预处理
9.2.1 加载测试集
df=pd.read_csv(CFG.train_file)
test_df = pd.read_csv(CFG.test_file)
test_df['labels']=None
test_df['labels']=test_df['labels'].apply(lambda x:[0,0,0,0,0,0])
tokenizer = AutoTokenizer.from_pretrained(CFG.model_path)
test_encoding,test_label=preprocess(test_df,tokenizer,False)
test_dataset=MyDataset(test_encoding,test_label)
test_loader=DataLoader(test_dataset,batch_size=CFG.batch_size,
num_workers=CFG.num_workers,shuffle=False)#test数据不能shuffle啊,真坑死我了
9.2.2 4折交叉
使用kaggle dataset搜索到的iterativestratification。另外denug模式启用
sys.path.append('../input/iterativestratification')
from iterstrat.ml_stratifiers import MultilabelStratifiedKFold
Fold = MultilabelStratifiedKFold(n_splits = CFG.n_fold, shuffle = True, random_state = CFG.seed)
for n, (train_index, val_index) in enumerate(Fold.split(df, df[CFG.target_cols])):
df.loc[val_index, 'fold'] = int(n)
df['fold'] = df['fold'].astype(int)
if CFG.debug:
CFG.epochs = 2
CFG.trn_fold = [0,1]
df = df.sample(n = 100, random_state = CFG.seed).reset_index(drop=True)
df.head(3)

9.3 模型
class FB3Model(nn.Module):
def __init__(self, CFG, config_path = None,pretrained=False):
super().__init__()
self.CFG = CFG
# 设置模型的config文件,根据此配置文件读取预训练模型
if config_path is None:
self.config = AutoConfig.from_pretrained(CFG.model_path, ouput_hidden_states = True)
self.config.hidden_dropout = 0.
self.config.hidden_dropout_prob = 0.
self.config.attention_dropout = 0.
self.config.attention_probs_dropout_prob = 0.
else:
self.config = torch.load(config_path)
#logger.info(self.config)
if pretrained:
self.model = AutoModel.from_pretrained(CFG.model_path, config=self.config)
else:
self.model = AutoModel.from_config(self.config)
if CFG.pooling == 'mean':
self.pool = MeanPooling()
elif CFG.pooling == 'max':
self.pool = MaxPooling()
elif CFG.pooling == 'min':
self.pool = MinPooling()
elif CFG.pooling == 'attention':
self.pool = AttentionPooling(self.config.hidden_size)
elif CFG.pooling == 'weightedlayer':
self.pool = WeightedLayerPooling(self.config.num_hidden_layers, layer_start = CFG.layer_start, layer_weights = None)
# 用一个全连接层得到预测的6类输出
self.fc = nn.Linear(self.config.hidden_size, self.CFG.n_targets)
# 根据池化方法选择输出
def feature(self,inputs):
outputs = self.model(**inputs)
if CFG.pooling != 'weightedlayer':
last_hidden_states = outputs[0]
feature = self.pool(last_hidden_states,inputs['attention_mask'])
else:
all_layer_embeddings = outputs[1]
feature = self.pool(all_layer_embeddings)
return feature
def forward(self,inputs):
feature = self.feature(inputs)
outout = self.fc(feature)
return outout
9.4 定义优化器
#LLDR
def get_optimizer_grouped_parameters(model, layerwise_lr,layerwise_weight_decay,layerwise_lr_decay):
no_decay = ["bias", "LayerNorm.weight"]
# initialize lr for task specific layer
optimizer_grouped_parameters = [{"params": [p for n, p in model.named_parameters() if "model" not in n],
"weight_decay": 0.0,"lr": layerwise_lr,},]
# initialize lrs for every layer
layers = [model.model.embeddings] + list(model.model.encoder.layer)
layers.reverse()
lr = layerwise_lr
for layer in layers:
optimizer_grouped_parameters += [{"params": [p for n, p in layer.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": layerwise_weight_decay,"lr": lr,},
{"params": [p for n, p in layer.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,"lr": lr,},]
lr *= layerwise_lr_decay
return optimizer_grouped_parameters
9.5 训练
9.5.1 定义训练函数
def train_loop(df, fold):
logger.info(f"========== fold: {fold} training ==========")
# 加载数据集
train_folds = df[df['fold'] != fold].reset_index(drop = True)
valid_folds = df[df['fold'] == fold].reset_index(drop = True)
valid_labels = valid_folds[CFG.target_cols].values
train_encoding,train_label=preprocess(train_folds,tokenizer,True)
val_encoding,val_label=preprocess(valid_folds,tokenizer,True)
train_dataset = MyDataset(train_encoding,train_label)
valid_dataset = MyDataset(val_encoding,val_label)
train_loader = DataLoader(train_dataset,batch_size = CFG.batch_size,shuffle = True,
num_workers = CFG.num_workers,pin_memory = True)
valid_loader = DataLoader(valid_dataset,batch_size = CFG.batch_size * 2,
shuffle=False,num_workers=CFG.num_workers,pin_memory=True, )
model = FB3Model(CFG, config_path = None,pretrained=True)
torch.save(model.config, CFG.OUTPUT_DIR +'./config.pth')
model.to(CFG.device)
# 加载优化器和调度器
from torch.optim import AdamW
grouped_optimizer_params = get_optimizer_grouped_parameters(model,
CFG.layerwise_lr,CFG.layerwise_weight_decay,CFG.layerwise_lr_decay)
optimizer = AdamW(grouped_optimizer_params,lr = CFG.layerwise_lr,eps = CFG.layerwise_adam_epsilon)
num_train_steps = len(train_loader) * CFG.epochs
scheduler = get_scheduler(CFG, optimizer, num_train_steps)
best_score = np.inf
for epoch in range(CFG.epochs): # 开始训练
start_time = time.time()
avg_loss = train_fn( train_loader, model, criterion, optimizer, epoch, scheduler, CFG.device)
avg_val_loss, predictions = valid_fn(valid_loader, model, criterion, CFG.device)
# scoring
score, scores = MCRMSE(valid_labels, predictions)
elapsed = time.time() - start_time
logger.info(f'Epoch {epoch+1} - avg_train_loss: {avg_loss:.4f} avg_val_loss: {avg_val_loss:.4f} time: {elapsed:.0f}s')
logger.info(f'Epoch {epoch+1} - Score: {score:.4f} Scores: {scores}')
if CFG.wandb:
wandb.log({f"[fold{fold}] epoch": epoch+1,
f"[fold{fold}] avg_train_loss": avg_loss,
f"[fold{fold}] avg_val_loss": avg_val_loss,
f"[fold{fold}] score": score})
if best_score > score:
best_score = score
logger.info(f'Epoch {epoch+1} - Save Best Score: {best_score:.4f} Model')
torch.save({'model': model.state_dict(),
'predictions': predictions},
CFG.OUTPUT_DIR+f"_fold{fold}_best.pth")
predictions = torch.load(CFG.OUTPUT_DIR+f"_fold{fold}_best.pth",
map_location=torch.device('cpu'))['predictions']
valid_folds[[f"pred_{c}" for c in CFG.target_cols]] = predictions
torch.cuda.empty_cache()
gc.collect()
return valid_folds # 返回验证集,方便后续看4折的验证结果
9.5.2 开始训练
if __name__ == '__main__':
def get_result(oof_df):
labels = oof_df[CFG.target_cols].values
preds = oof_df[[f"pred_{c}" for c in CFG.target_cols]].values
score, scores = MCRMSE(labels, preds)
logger.info(f'Score: {score:<.4f} Scores: {scores}')
oof_df = pd.DataFrame()
for fold in range(CFG.n_fold):
if fold in CFG.trn_fold:
_oof_df = train_loop(df, fold)
oof_df = pd.concat([oof_df, _oof_df])
get_result(_oof_df)
oof_df = oof_df.reset_index(drop=True)
logger.info(f"========== CV ==========")
get_result(oof_df)
oof_df.to_pickle(CFG.OUTPUT_DIR+'oof_df.pkl')
if CFG.wandb:
wandb.finish()
总共耗时9891s,具体输出日志和输出文件可以看我的kaggle notebook:FB3 English Language Learning(已公开)
Successfully ran in 9891.7s
========== fold: 0 training ==========
Epoch 3 - Save Best Score: 0.4484 Model
Score: 0.4484 Scores: [0.47639982021778765, 0.44438544047031964, 0.411117580524018, 0.4569625026301624, 0.464023683765807, 0.4375083818812937]
========== fold: 1 training ==========
Epoch 5 - Save Best Score: 0.4589 Model
Score: 0.4589 Scores: [0.4893536652962534, 0.4516149562135857, 0.42116027137885914, 0.4559525101568498, 0.48145626304991035, 0.4536839864791965]
========== fold: 2 training ==========
Epoch 5 - Save Best Score: 0.4627 Model
Score: 0.4627 Scores: [0.4877636587908424, 0.45136349987020213, 0.4240382780997242, 0.4713320188777592, 0.4850065780075501, 0.4567415286553652]
========== fold: 3 training ==========
Epoch 5 - Save Best Score: 0.4481 Model
Score: 0.4481 Scores: [0.4869053142647347, 0.44166370456940907, 0.41296169651420267, 0.44225207596395494, 0.47042158620227514, 0.43460859072352703]
========== CV ==========
Score: 0.4546 Scores: [0.4851313644810512, 0.4472768544548916, 0.41735362690386074, 0.45674088025058435, 0.47529988932109074, 0.44573896179506994]
9.6 推理
predictions = []
for fold in CFG.trn_fold:
model = FB3Model(CFG, config_path=CFG.OUTPUT_DIR+'/config.pth', pretrained=False)
state = torch.load(CFG.OUTPUT_DIR +f"_fold{fold}_best.pth")
model.load_state_dict(state['model'])
prediction = inference_fn(test_loader, model, CFG.device)
predictions.append(prediction)
del model, state, prediction
gc.collect()
torch.cuda.empty_cache()
print(predictions)
predictions = np.mean(predictions, axis=0)
运行这一步会报错,也没找出来啥原因,不过结果是ok的,简单说就是可以跑。最终得分是0.44,排名1002!!!
submission = pd.read_csv('../input/feedback-prize-english-language-learning/sample_submission.csv')
test_df[CFG.target_cols] = predictions.clip(1, 5)
submission = submission.drop(columns=CFG.target_cols).merge(test_df[['text_id'] + CFG.target_cols], on='text_id', how='left')
display(submission.head())
submission[['text_id'] + CFG.target_cols].to_csv('submission.csv', index=False)
十、Utilizing Transformer Representations Efficiently
参考《《Utilizing Transformer Representations Efficiently》》
10.1 池化
一般的Transformer微调都是将模型最后一层的输出接一个额外的输出层(比如FC层),来解决下游任务。但是Transformer不同层可以捕获不同级别的语义信息,即表层特征在下层,句法特征在中层,语义特征在高层(surface features in lower layers, syntactic features in middle layers, and semantic features in higher layers.)。
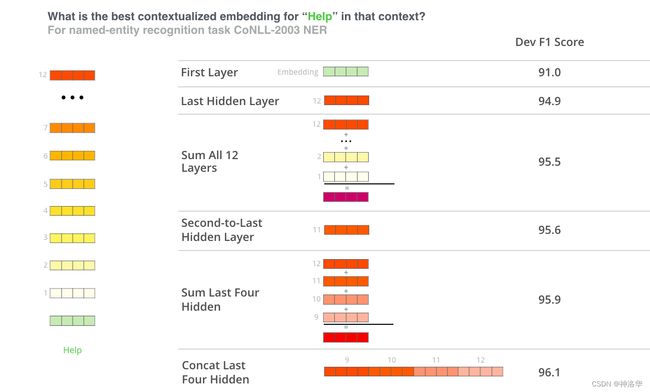
上图是使用BERT不同层的输出作为BiLSTM的特征输入以进行NER任务,可以看到串联BERT最后四层输出作为特征输入,效果最好(Concatenation of the last four layers)。所以针对不同的下游任务应该选择不同的池化策略。
在HuggingFace中 Transformers默认有两个输出(也可指定输出第三个):
- pooler output (batch size, hidden size) -最后一层CLS token的输出
- last hidden state (batch size, seq Len, hidden size) :最后一层所有token的输出(隐向量)
- hidden states (n layers, batch size, seq Len, hidden size) - 所有层的所有token输出
下面将显示不同的利用Transformer输出的方式,而不仅仅只是接一个额外输出层。
-
SWA, Apex AMP & Interpreting Transformers in Torch介绍了在Pytorch中实现transformers的Weight Averaging,同时也实现了LIT(Language Interpretability Tool,语言可解释性工具)
- SWA
- Apex AMP
- Weighted Layer Pooling
- MADGRAD Optimizer
- Grouped LLRD
- Language Interpretibility Tool
- Attention Visualization
- Saliency Maps
- Integrated Gradients
- LIME
- Embedding Space (UMAP & PCA)
- Counterfactual generation
- And many more …
-
On Stability of Few-Sample Transformer Fine-Tuning :使用各种技术来提升样本少时的微调性能。
- Debiasing Omission In BertADAM
- Re-Initializing Transformer Layers
- Utilizing Intermediate Layers
- Layer-wise Learning Rate Decay (LLRD)
- Mixout Regularization
- Pre-trained Weight Decay
- Stochastic Weight Averaging.
-
Speeding up Transformer w/ Optimization Strategies :深入解释了5种优化策略
- Dynamic Padding and Uniform Length Batching
- Gradient Accumulation
- Freeze Embedding
- Numeric Precision Reduction
- Gradient Checkpointing
其它有空再补吧,大家可以直接看原文。
文本参考资源
-
Papers:
- Deepening Hidden Representations from Pre-trained Language Models
- Linguistic Knowledge and Transferability of Contextual Representations
- What does BERT learn about the structure of language?
- Dissecting Contextual Word Embeddings: Architecture and Representation
- SDNET: CONTEXTUALIZED ATTENTION-BASED DEEP NETWORK FOR CONVERSATIONAL QUESTION ANSWERING
- Utilizing BERT Intermediate Layers for Aspect Based Sentiment Analysis
and Natural Language Inference - WHAT DO YOU LEARN FROM CONTEXT? PROBING FOR SENTENCE STRUCTURE IN CONTEXTUALIZED WORD REPRESENTATIONS
- SBERT-WK: A Sentence Embedding Method by Dissecting BERT-based Word Models
-
Blogs
- BERT Word Embeddings Tutorial
- Visualize BERT sequence embeddings: An unseen way
- Deconstructing BERT, Part 2: Visualizing the Inner Workings of Attention
- Writing Math Equations in Jupyter Notebook: A Naive Introduction
-
GitHub
- Sentence Transformers: Multilingual Sentence, Paragraph, and Image Embeddings using BERT & Co.
- FLAIR
- BERT Fine-tuning for Aspect Based Sentiment Analysis
- Interpreting Bidirectional Encoder Representations from Transformers
- BertViz
-
Kaggle Kernels and Discussion
- Jigsaw Unintended Bias in Toxicity - 1st Place
- Jigsaw Unintended Bias in Toxicity - 4th Place
- Jigsaw Unintended Bias in Toxicity - 8th Place
- Twitter Sentiment Extraction - 2nd Place
- Twitter Sentiment Extraction - 3rd Place
- Twitter Sentiment Extraction - 7th Place
- Twitter Sentiment Extraction - TensorFlow roBERTa - [0.712]
- Jigsaw Multilingual Toxic Comment Classification - 4th Place
- CommonLit Readability Prize - Step 1: Create Folds
还有很多其他的策略我还没有涉及到:
- Dense Pooling
- Word Weight (TF-IDF) Pooling
- Async Pooling
- Parallel / Heirarchical Aggregation