【YOLOV5】记录一次自己在yolo训练模型上的全过程(附上多次解决Bug记录以及心得体会)
一.yolov5的版本选择
本人一开始跟着教程选择了yoloV5-5.0的版本,5.0的版本和6.0已经有部分差距而且源码部分文件被修改,导致我们训练的过程中老是需要缝缝补补,我这里建议要么下最新的版本要么去下6.0。
github地址:https://github.com/ultralytics/yolov5/tree/v6.0
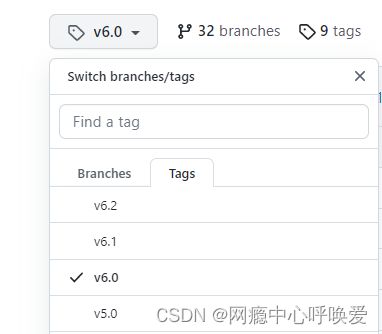
通过github上的标签(Tags)来选择你想要下载的yolov5版本
下面开始我们的第一次yolo之旅
二.训练数据集的准备
这边也是出差错的重灾区,一般大部分问题出在了文件夹或文件命名错误上。在这里我用我自己第一次尝试所使用的吸烟检测作为实例帮助大家更好理解训练过程。
-
Conda与PyTorch环境的配置
– 如果你先前已经装过PyTorch环境的话如果版本和requirements一致则仅需补齐所需的其他包。这里非常不建议一键更新PyTorch,有极大可能会升级成cpu版本,导致后续很麻烦,
– 建议可以conda新创一个环境,再根据一键安装requirements文件里的包。 -
训练集格式的规范化
以我自己创建的SmokingDetect文件夹为例,分为:
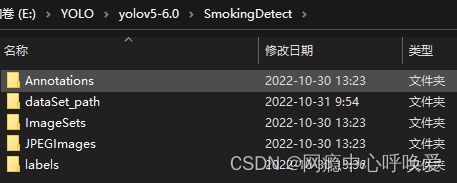
Annotations:存放图像的xml标注文件
dataSet_Path:存放test,train,val三个txt文件,里面是图像的绝对路径,通过编程自动生成

ImageSets/Main:里面还有一个子文件夹Main,在Main里面存放test,train,val三个txt文件,里面是图像的id,通过编程自动生成
JPEGImages:也可以写成Images(建议),此处我写成JPEGImages是因为和yolo以前的版本可以匹配起来,如果像我一样需要在源码的dataset.py里修改路径。
labels:存放通过代码自动生成的文本文档,名称为图片id,内容为该图片的类别与标注框数据。 -
如何生成训练集、测试集、验证集(ImageSet/Main里的文件)
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='E:\YOLO\datasets\car_head/Annotations', type=str, help='input xml label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='E:\YOLO\datasets\car_head/ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0 # 训练集和验证集所占比例。 这里没有划分测试集
train_percent = 0.9 # 训练集所占比例,可自己进行调整
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
- 如何生成labels的yolo格式文件和dataSet_path里的路径
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["smoke"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
if(size[0] == 0 or size[1] == 0):
dw = size[0] # size[0]为图片的宽
dh = size[1] # size[1]为图片的高
else:
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('E:/YOLO/datasets/SmokingDetect/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('E:/YOLO/datasets/SmokingDetect/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
# difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('E:/YOLO/datasets/SmokingDetect/labels/'):
os.makedirs('E:/YOLO/datasets/SmokingDetect/labels/')
image_ids = open('E:/YOLO/datasets/SmokingDetect/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
if not os.path.exists('E:/YOLO/datasets/SmokingDetect/dataSet_path/'):
os.makedirs('E:/YOLO/datasets/SmokingDetect/dataSet_path/')
list_file = open('E:/YOLO/datasets/SmokingDetect/dataSet_path/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('E:/YOLO/datasets/SmokingDetect/JPEGImages/%s.jpg\n' % (image_id))
# print(image_id)
convert_annotation(image_id)
list_file.close()
- 编写.yaml文件放置进源码的data文件夹里
path: E:/YOLO/yolov5-6.0/SmokingDetect/ # dataset root dir
train: dataSet_path/train.txt
val: dataSet_path/val.txt
test: # test images (optional)
# number of classes
nc: 1
# class names
names: ["smoke"]
- 修改超参数:在data/hyps/hyp.scratch.yaml中,主要是调整不同优化器的学习率

- 修改models文件夹的yolo5s.yaml,主要修改其中的类别个数(改为自己数据集的类别个数)

- 修改train.py
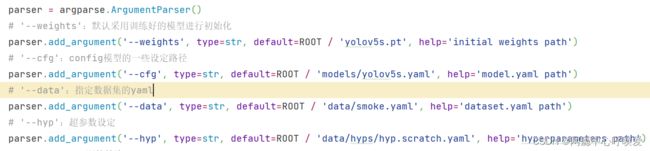
权重文件改为自己想用的(小型数据集推荐使用yolo5s)(yolo5s/m/l分别代表小中大)
设定路径改为刚刚我们修改的yolo5s.yaml
–data改为我们自己数据集的smoke.yaml
–hyp为我们修改的超参数设定
其次可以修改一些epoch或batch-size或dataloader workers的数量,这里如果电脑不是太好建议dataloader workers设置为0
三.开始训练!
对修改好的train.py直接右键运行,或者在终端中输入python train.py运行
如果想使用adam优化器,即输入python train.py --adam(别忘了重新设置adam优化器的学习率)
其他的命令可以在train文件里有详细解释
训练结果保存至runs/train文件夹中
四.开始预测!
在detect,py中最主要修改的是预测文件的地址,预测文件可以是图片或视频,放置在相应路径下即可

训练结果可视化工具的选择
yolo文件中给大家推荐这两款可视化训练过程的工具,我觉得两个都很好用,并推荐装一个wandb库可以对自己的项目有很好的管理
1.TensorBoard
TensorBoard是最常用的
在终端中输入tensorboard --logdir runs\train即可在本地的http://localhost:6006/中打开。如果发现PyCharm的终端打不开,可以查阅我的这篇博客 解决终端打不开

2.Wandb
Wandb需要大家一开始初始化注册一下,这里附上一个wandb注册的博客,大家在终端里登陆一下就可以记录每一次的训练过程
wandb注册这边注意一下那个输入秘钥是隐藏密码的,如果不能复制需要自己对照输入进去。
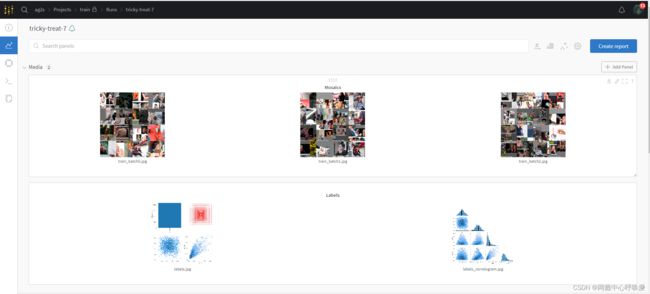
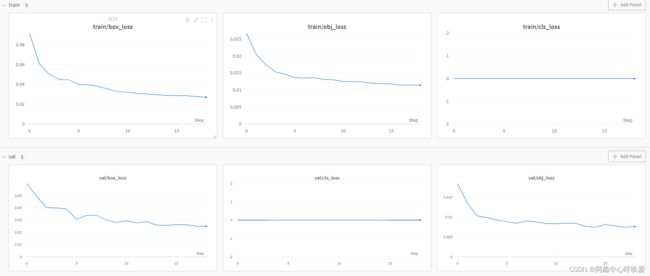
Wandb会详细记录你的每一次训练,无论失败/中断/成功,并自动上传云端,可以在云端上对你的模型进行操作(比如中断它)
Wandb还提供了log日志记录,方便大家查找每次训练的超参数设置,以及丰富的可视化图例,如下图所示,非常推荐大家使用