二分类问题之电影评论
import keras
keras.__version__
from keras.datasets import imdb
import numpy as np此处用到了imdb的数据
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)(num_words=10000)表示只用前1w个最常出现的单词。
train_data.shape
>>(25000,)
np.array(train_data[2]).shape
>>(141,)
train_data.shape[0]
>>25000
train_labels
>>array([1, 0, 0, ..., 0, 1, 0], dtype=int64)可以看出导入的train_data是25000行,各列不同的张量。且一千个单词分别用数字表示(1-1k)。
# word_index is a dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# We reverse it, mapping integer indices to words
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
#解码单词
# We decode the review; note that our indices were offset by 3
# because 0, 1 and 2 are reserved indices for "padding", "start of sequence", and "unknown".
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])把字典的键值颠倒来解码单词,不过这一步对于本神经网络没有什么帮助。
one-hot编码
把某个对象转化成0,1的向量。
例:
import numpy as np
a=np.zeros((3,3)).astype('int64')
a[2][1]=8.
a[0][1]=1.
a[0][2]=3.
a[1][0]=9.
b=np.zeros((3,10))
print(a)
print(b)
>>[[0 1 3]
[9 0 0]
[0 8 0]]
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]先随便构建矩阵a。
for i,c in enumerate(a):
print(i)
b[i, c] = 1.
print(b)
>>0
1
2
[[1. 1. 0. 1. 0. 0. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[1. 0. 0. 0. 0. 0. 0. 0. 1. 0.]]
#enu
merate索引与遍历
#one-hot编码利用python自带的索引遍历实现one-hot编码。这种编码着重于存在而忽略内在的位置关系和数量。
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
# Create an all-zero matrix of shape (len(sequences), dimension)
#创造一个25000乘10000的零矩阵
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1. # set specific indices of results[i] to 1s
return results
# Our vectorized training data
x_train = vectorize_sequences(train_data)
# Our vectorized test data
x_test = vectorize_sequences(test_data)
#它是如何把二维数组转化成0,1向量矩阵的?
#这种做法忽略了每个数字的相对位置和数量,追求存在
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')构建函数实现one-hot编码。
开始构建神经网络。
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))Sequential模型???
序贯模型。
序贯模型是函数式模型的简略版,为最简单的线性、从头到尾的结构顺序,不分叉。
小批量随机梯度下降法SGD???
激活函数
为什么使用激活函数:
使原来的线性函数转化成非线性的。

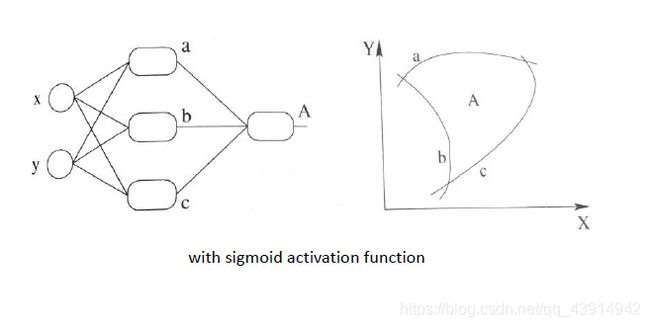
-
relu
线性整流函数
f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x) -
sigmoid
f ( x ) = 1 1 + e − x f(x)=\frac{1}{1+e^{-x}} f(x)=1+e−x1
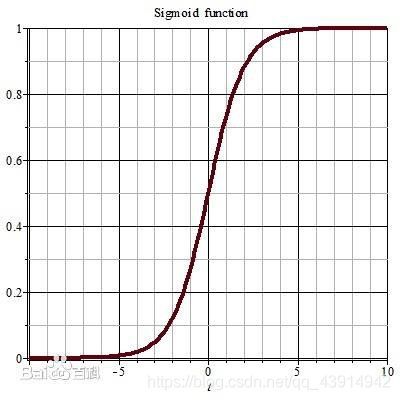
编辑模型
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])后面的’…'中的内容分别为优化器、损失函数、衡量指标的名字。
在以后的字典中会用到。
compile:编译
optimizer:优化器
loss:损失函数
metrics:衡量指标
优化器

https://keras.io/zh/optimizers/
损失函数
https://keras.io/zh/losses/#_1
衡量指标(评价函数)
https://keras.io/zh/metrics/
配置优化器
from keras import optimizers
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss='binary_crossentropy',
metrics=['accuracy'])使用自定义的损失和指标
from keras import losses
from keras import metrics
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss=losses.binary_crossentropy,
metrics=[metrics.binary_accuracy])验证方法
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
#x_val = x_train[:10000] 把前10k组给x_val
#partial_x_train = x_train[10000:] 把剩下的给partial_x_train留出训练集的一部分作为验证集。
训练模型
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))fit()用于使用给定输入训练模型.
epochs:训练多少轮
batch_size:当传递NumPy数据时,模型将数据分成较小的批次,并在训练期间迭代这些批次。 此整数指定每个批次的大小。 请注意,如果样本总数不能被批量大小整除,则最后一批可能会更小。
validation_data:验证集
显示history词典
history_dict=history.history
history_dict.keys()
>>dict_keys(['val_loss', 'val_binary_accuracy', 'loss', 'binary_accuracy'])绘制训练损失和验证损失
import matplotlib.pyplot as plt
history_dict=history.history
loss_values=history_dict['loss']
val_loss_values=history_dict['val_loss']
epochs = range(1, len(loss_values) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss_values, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss_values, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()绘制训练精度和验证精度
plt.clf() # clear figure
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()核心代码
防止过拟合,新建立一个网络只训练4次迭代。
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=4, batch_size=512)
results = model.evaluate(x_test, y_test)