tensorrt安装_Nvidia Jetson Xavier NX与TensorRT
Nvidia Jetson Xavier NX
Nvidia Xavier NX开发模块在2020年5月14日正式发布,下面是官网的介绍

可以看到作为边缘服务器,Xavier NX以低功耗提供了较大的算力,下面提供经过trt加速的速度对比:

从上面可以看到,在608*608的图片输入下,经过trt加速的yolo可以跑到50帧左右,忍不住诱惑的我摩拳擦掌,然后得到了下面测评过程与感受:



首先jetson xavier nx的使用与其他jetson系列没有很大区别,和树莓派使用方式也基本一致,不过Nvidia自己定制的ubuntu18.04使用体验要比原生的ubuntu好用许多。下面给一些截图,

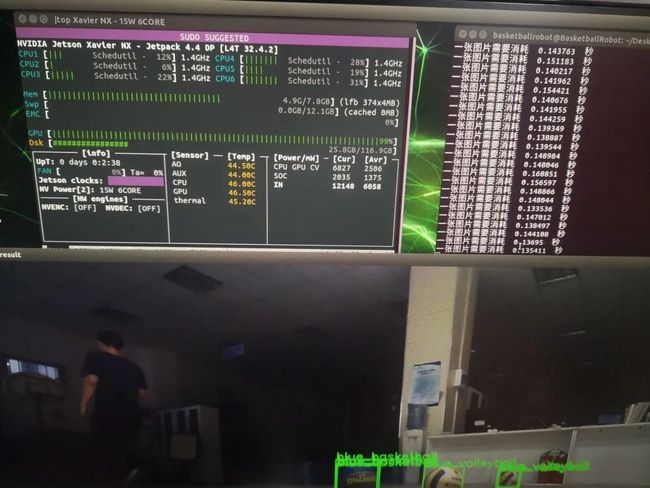
上图是我安装完系统后的实际测试结果。在1920*1080的视频流,AB官方版YoloV3在网络输入为608 * 608,四分类的情况下一帧照大概是0.15秒,也就是每秒6-7帧,和官方所说的50帧相差甚远。所以Tensorrt加速的Yolo急需测试,目前由于时间原因,尚未测试,不过根据客服说明,感觉在损失部分精度的情况下是可以实现50帧的。下面简单介绍一下TensorRT
TensorRT
1. 什么是TensorRT?
1.1TensorRT简介
TensorRT是一个高性能的深度学习推理(Inference)优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。TensorRT现已能支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。
TensorRT 是一个C++库,从 TensorRT 3 开始提供C++ API和Python API,主要用来针对 NVIDIA GPU进行 高性能推理(Inference)加速。现在最新版TensorRT是7.1版本。
1.2训练(training)和 推理(inference)的区别:
训练(training)包含了前向传播和后向传播两个阶段,针对的是训练集。训练时通过误差反向传播来不断修改网络权值(weights)。
推理(inference)只包含前向传播一个阶段,针对的是除了训练集之外的新数据。可以是测试集,但不完全是,更多的是整个数据集之外的数据。其实就是针对新数据进行预测,预测时,速度是一个很重要的因素。
1.3TensorRT
一般的深度学习项目,训练时为了加快速度,会使用多GPU分布式训练。但在部署推理时,为了降低成本,往往使用单个GPU机器甚至嵌入式平台(比如 NVIDIA Jetson)进行部署,部署端也要有与训练时相同的深度学习环境,如caffe,TensorFlow等。
由于训练的网络模型可能会很大(比如,inception,resnet等),参数很多,而且部署端的机器性能存在差异,就会导致推理速度慢,延迟高。这对于那些高实时性的应用场合是致命的,比如自动驾驶要求实时目标检测,目标追踪等。所以为了提高部署推理的速度,出现了很多轻量级神经网络,比如squeezenet,mobilenet,shufflenet等。基本做法都是基于现有的经典模型提出一种新的模型结构,然后用这些改造过的模型重新训练,再重新部署。
而tensorRT 则是对训练好的模型进行优化。tensorRT就只是推理优化器。当你的网络训练完之后,可以将训练模型文件直接丢进tensorRT中,而不再需要依赖深度学习框架(Caffe,TensorFlow等)。可以认为tensorRT是一个只有前向传播的深度学习框架,这个框架可以将 Caffe,TensorFlow的网络模型解析,然后与tensorRT中对应的层进行一一映射,把其他框架的模型统一全部 转换到tensorRT中,然后在tensorRT中可以针对NVIDIA自家GPU实施优化策略,并进行部署加速。
目前TensorRT几乎可以支持所有常用的深度学习框架,对于caffe和TensorFlow来说,tensorRT可以直接解析他们的网络模型;对于caffe2,pytorch,mxnet,chainer,CNTK等框架则是首先要将模型转为 ONNX 的通用深度学习模型,然后对ONNX模型做解析。而tensorflow和MATLAB已经将TensorRT集成到框架中去了。
1.4ONNX简介
ONNX(Open Neural Network Exchange )是微软和Facebook携手开发的开放式神经网络交换工具,也就是说不管用什么框架训练,只要转换为ONNX模型,就可以放在其他框架上面去inference。这是一种统一的神经网络模型定义和保存方式,上面提到的除了tensorflow之外的其他框架官方应该都对onnx做了支持,而ONNX自己开发了对tensorflow的支持。从深度学习框架方面来说,这是各大厂商对抗谷歌tensorflow垄断地位的一种有效方式;从研究人员和开发者方面来说,这可以使开发者轻易地在不同机器学习工具之间进行转换,并为项目选择最好的组合方式,加快从研究到生产的速度。
2.TensorRT 做了哪些优化?
相对于训练过程,网络推断时模型结构及参数都已经固定,batchsize一般较小,对于精度的要求相较于训练过程也较低,这就给了很大的优化空间。具体到TensorRT,主要在一下几个方面进行了优化:
2.1. 合并某些层
有时制约计算速度的并不仅仅是计算量,而是网络对于内存的读写花费太大,TensorRT中将多个层的操作合并为同一个层,这样就可以一定程度的减少kernel launches和内存读写。例如conv和relu等操作一次做完。
另外,对于相同输入及相同filtersize的层会合并为同一层,利用preallocating buffers等消除了concat层
2.2. 支持FP16 或者INT8的数据类型
训练时由于梯度等对于计算精度要求较高,但是inference阶段可以利用精度较低的数据类型加速运算,降低模型的大小
2.3. Kernel Auto-Tuning
TensorRT针对不同的超参数有一写算法层面的优化,比如会根据卷积核的大小、输入大小等超参数确定使用哪种算法进行卷积运算
2.4. Dynamic Tensor Memory
TensorRT经过优化减少内存开销,提高内存的reuse
2.5. 多支并行运算
对于同一输入的多个分支可以进行并行运算