openVION部署YOLOv5
前言
本人第一次接触openvion部署,因工作需要,需要一款CPU加速工具去部署我们的模型。在网上翻箱倒柜找到了这个openvion。本着对工作严谨认真的态度,我努力研究了一早上,下午开始准备干的时候,这个时候才发现噩梦才刚刚开始。
话不多说,咋们直接开始从头来搞一遍。
一、yolov5训练出的模型转换为onnx。
这里我就不去教大家如何训练了。大家可以根据 :
YoloV5实战:手把手教物体检测——YoloV5_AI浩-CSDN博客_yolov5目录摘要训练1、下载代码2、配置环境3、准备数据集4、生成数据集5、修改配置参数6、修改train.py的参数摘要YOLOV5严格意义上说并不是YOLO的第五个版本,因为它并没有得到YOLO之父Joe Redmon的认可,但是给出的测试数据总体表现还是不错。详细数据如下:YOLOv5并不是一个单独的模型,而是一个模型家族,包括了YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x、YOLOv5x+TTA,这点有点儿像EfficientDe..https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/109253329?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163663210516780357241654%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=163663210516780357241654&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-109253329.pc_search_result_cache&utm_term=yolov5%E6%89%8B%E6%8A%8A%E6%89%8B%E6%95%99&spm=1018.2226.3001.4187
最后生成的文件 (我这里使用的是第五版本的torch版本的yolov5m,大家也可以参照。)会在runs/train/exp/weights/best.pt 文件。因为openvion要使用IR模型,所以要先把pt模型转换为onnx模型中间值,以下为步骤。
yolo代码中有直接可以转,在models下面的export.py里面。需要注意要改一些东西。
# yolov5/models/export.py# Lines 51 to 52 in 5e0b90d
# torch.onnx.export(model, img, f, verbose=False, opset_version=12, input_names=['images'], torch.onnx.export(model, img, f, verbose=False, opset_version=10, input_names=['images'], output_names=['classes', 'boxes'] if y is None else ['output'])
这里要保证 opset_version=10。
运行代码:
python export.py --weights --img 640 --batch 1 最好去runs/train/exp/weights/下面去看一下是不是生成了。
二、安装openvion工具
OpenVINO是英特尔基于自身现有的硬件平台开发的一种可以加快高性能计算机视觉和深度学习视觉应用开发速度工具套件,支持各种英特尔平台的硬件加速器上进行深度学习,并且允许直接异构执行。 支持在Windows与Linux系统,Python/C++语言。
首先奉上Intel Openvino的官方安装教程链接:Install Intel® Distribution of OpenVINO™ toolkit for macOS* - OpenVINO™ Toolkit
【OpenCV+OPENVINO使用】openvino安装教程_tjj1998的博客-CSDN博客_openvino安装教程转载自文章:巨详细!使用OpenCV和OpenVINO轻松创建深度学习应用额外内容:修改openvino安装后自带的opencv,改为自己版本的opencv(为了使用opencv_contrib)第一步:安装OpenVINO从官网注册并下载OpenVINO开发包的Linux版本:官网下载地址:https://software.intel.com/content/www/us/en/develop/tools/openvino-toolkit/choose-download/linux.htmlhttps://blog.csdn.net/tjj1998/article/details/112372398?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163663441416780357215835%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=163663441416780357215835&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-7-112372398.pc_search_result_cache&utm_term=openvion%E5%AE%89%E8%A3%85&spm=1018.2226.3001.4187
我是在ubuntu下安装的,大家可以参照一下。一定要验证一下。
环境安装好后咋们进入正题,我这里使用的是c++去部署openvion,具体的代码我上传到 许凌瑞/yolov5-openvion
下面就开始我的踩坑之旅了:
刚开始的代码是别人给我的,他是直接使用官方5s的模型去部署的一个视频。而我的项目寻求是使用自己的模型去部署图片。刚开始我抱着试一试的心态去改了模型的路径,改了导入图片的路径。果不其然,各种各样的报错。本在对工作认真负责的态度为我一个一个解决,终于代码运行了,可是结果让我直接哭出来了,一张图片上面居然有1000多个预测框,这不仅仅让为怀疑人生,也让我们组长对我刮目相看。我也不怕被大家笑话直接给大家上图。
所以我就一直在思考一个问题,为什么一模一样的代码,别人运行就什么事情都没有,到我这里将会有各种各样的问题。然后我就将代码整整齐齐滤了一遍,我没有发现任何问题,然后我就尝试着将官方模型运行了一遍。得出结论是我模型转换的问题,还有就是我的推理速度,每张图片在300多ms。我一气之下把openvion卸载了重新装载了一边(这里因为没有删除干净,又浪费了我2天的时间)。不过黄天不负有❤人,我发现我第一次安装时根本没有安装好,所以我让大家根据教程好好去安装,最后还一定要去验证一次。
三、onnx模型转换为IR模型
这里给大家着重强调一下,这一步至关重要,直接关系到这个模型的使用。
安装验证完成openvion可以使用后,使用下面的命令,进入这个文件。
cd /opt/intel/openvino_2021/deployment_tools/model_optimizer
这个文件下面有,我们要使用的是 mo_onnx.py这个文件.
这里我们要先进入conda的虚拟环境,然后使用下面这个命令,安装所需要的包。
pip install -r requirements_onnx.txt -i https://pypi.douban.com/simple/
onnx模型转换成功后一定要去 Netron这里去看自己的模型。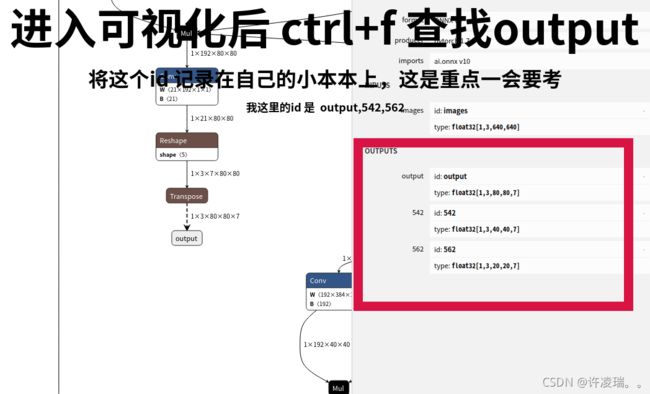
重点中的重点来了 下面这个命令直接关乎是否能成功。
在 /opt/intel/openvino_2021/deployment_tools/model_optimizer/这个路径下,conda环境下使用命令
python mo_onnx.py --input_model 《你模型存放的地址》 --input_shape [1,3,640,640] --output_dir 《保存生成模型的地址》--output 《可视化onnx模型得到的output的id名》这就生成模型了,然后将这个模型放入代码中去运行使用一下。
如果还是不对的话,可以去调整一下nms的值,设置的大一点。还有排版,20,40,80的那里,可以把顺序反转一下。
总结
如果大家还有什么问题,欢迎提问 ,我的微信:18834206636。本人也是一名小白,如果有不对的地方希望大家指正一下,谢谢大家。