【文献翻译】What is Event Knowledge Graph: A Survey
【文献翻译】What is Event Knowledge Graph: A Survey
- 【文献翻译】什么是事件图谱?
- 摘要
- 1.概述
- 2.什么是EKG: 历史视角
-
- 2.1 EKG简史
- 2.2 定义
- 3.什么是EKG,本体视角
-
- 3.1事件模式归纳
- 3.2脚本归纳
- 3.3 EKG模式归纳
- 4. 什么是EKG:实例视角
-
- 4.1 事件获取
-
- 4.1.1 事件抽取
- 4.1.2 事件关系提取
- 4.1.3 事件共指消解
- 4.1.4 事件论元补全
- 4.2 EKG相关的代表性的图/系统
- 5. 什么是EKG:应用视角
-
- 5.1 基本应用
-
- 5.1.1 脚本事件预测
- 5.1.2 时序KG预测
- 5.1.3 其他基本应用
- 5.2 深入应用
- 6.未来的发展方向
-
- 6.1 高性能的事件获取
- 6.2 多模态知识处理
- 6.3 可解释EKG研究
- 6.4 实践中的EKG研究
- 总结
【文献翻译】什么是事件图谱?
一篇来自中科院计算所的事件图谱综述,文献地址。本文主要是机翻,然后通过个人理解进行校验、修改。如有不当之处,敬请谅解,且欢迎随时批评指正。

摘要
除了以实体为中心的知识(通常以知识图谱(knowledge Graph, KG)的形式组织起来),事件也是世界上必不可少的一种知识,它引发了以事件为中心的知识表示形式(Event KG, EKG)的兴起。它在许多机器学习和人工智能应用中发挥着越来越重要的作用,如智能搜索、问题回答、推荐和文本生成。本文从历史、本体、实例和应用的角度对EKG进行了全面的调研。具体地说,为了全面地描述EKG的特征,我们将重点关注EKG的历史、定义、模式归纳、获取、相关的代表性的图/系统和应用。研究了其发展过程和趋势后。我们进一步总结了未来EKG研究的发展方向。
关键词——事件知识图谱,模式,事件获取,脚本事件预测,时序知识图谱预测。
1.概述
知识图谱(KG)是谷歌在2012年发布的一种流行的知识表示形式。它关注名词性的实体及其关系,因此代表静态知识。然而,世界上存在着大量的事件信息,传递着动态的程序性知识。因此,以事件为中心的知识表示形式(如Event KG (EKG))也很重要,它将实体和事件结合在一起。它促进了许多下游应用,如智能搜索、问答、推荐和文本生成[1]、[2]、[3]、[4]、[5]。
本文就EKG的概念及其发展进行了深入的探讨。关于EKG你想知道什么?你可能会对它的产生感兴趣,什么是所谓的EKG?如何构建它?以及它的进一步应用。因此,要全面介绍EKG,我们可以从历史视角、本体视角、实例视角和应用视角四个方面来了解EKG。从历史的观点,我们介绍了EKG的简史和我们从中得到的EKG的定义。从本体的角度,提出了与EKG相关的基本概念,以及EKG相关的任务和方法,包括事件模式归纳、脚本归纳和EKG模式归纳。从实例视角,我们详细阐述了事件获取和与EKG相关的代表性的图/系统。具体来说,事件获取的重点是如何构建一个基本的EKG,并获得一个更好的EKG。前者包括事件抽取和事件关系抽取,是最基本的任务。后者包括事件相互引用解析和事件参数补全。从应用的角度,介绍了一些基本的应用,包括脚本事件预测和时序KG预测,以及一些深层次的应用,如搜索、问答、推荐和文本生成。并对相关任务的发展过程和趋势进行了深入的研究和分析。然后指出未来的方向。
也有一些关于部分EKG的研究(surveys),主要集中在事件提取[6],[7],[8],[9],事件建模和挖掘[10],事件提取和事件关系提取[11],事件共指解析[12]。然而,目前还缺乏对EKG的全面调研。事实上,事件是世界上不可忽视的重要因素。每天都有许多事件发生,反映了世界的状况。因此,有必要深入研究事件。因此,对EKG进行全面的调查是非常重要的。本文的其余部分组织如下。我们首先在第2-5节从不同的角度介绍什么是EKG,然后在第6节介绍未来的方向,然后在第7节总结。
2.什么是EKG: 历史视角
在本节中,我们将从历史的观点,简要介绍EKG的历史。然后我们根据历史上与EKG相关的概念推导出EKG的定义。
2.1 EKG简史
EKG并不是突然涌现出来的。它是自然语言处理(NLP)和人工智能发展的结果。如图1所示,按照日期可以分为四个阶段,分别为事件、事件提取、事件关系提取等阶段。
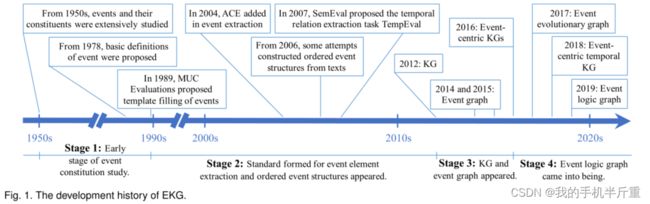
阶段1:事件构成研究的早期阶段。 自20世纪50年代以来,人们对事件及其组成成分(EKG的基本元素)进行了广泛的研究[13],[14],[15],[16]。例如,Davidson[14]试图得到关于行为的句子的逻辑形式。他对特定论元或词在这样的句子中的逻辑或语法作用进行了说明,这与这些句子之间的蕴涵关系是一致的,与这些相同的特定论元或词在其他(非动作)句子中的作用是一致的。Mourelatos[15]和Pustejovsky[16]对事件进行了研究,提出了事件的基本定义。1978年,Mourelatos[15]将事件定义为那些本质上是可计数的事件。而在1991年,Pustejovsky[16]认为一个事件可以为语言学分析提供一个独特而有用的表征,包括动词的体性、状语的范围、论元的作用以及从词汇到句法的映射。
阶段2:事件元素提取标准形成,事件结构有序出现。 然后,在1989年,MUC(Message Understanding Conference)评估提出了事件模板填充任务,由海军海洋系统中心发起,以评估和促进对军事文本消息[17]的自动分析研究。给定要在文本中识别的一类事件的描述,参与者被要求为页面上的每个事件填写一个模板。更实际的是,由于Web具有无限的信息承载潜力,ACE(Automatic Content Extraction)程序的目标是开发从其中提取意图的能力。从2004年开始,它增加了事件提取,这个任务被定义为提取事件触发词和参数,更符合现实[18]。事件触发词是最清楚地表达事件的词或跨度,即主要表示事件的类型,而参数是在事件中扮演特定角色的实体或跨度。由于意识到识别文本中描述的事件并及时定位它们的重要性,SemEval (Semantic Evaluation)在2007年提出了时序关系抽取任务TempEval[19]。它的目的是提取文本中事件之间的时间关系。此后,事件提取和事件关系提取的研究通常分别遵循ACE和TempEval的任务定义。由于文本时间流的理解是文本理解的一个重要方面,从2006年开始,人们开始尝试从文本中构建有序的事件结构,如时序图谱[20]和事件时间表[21],[22]。
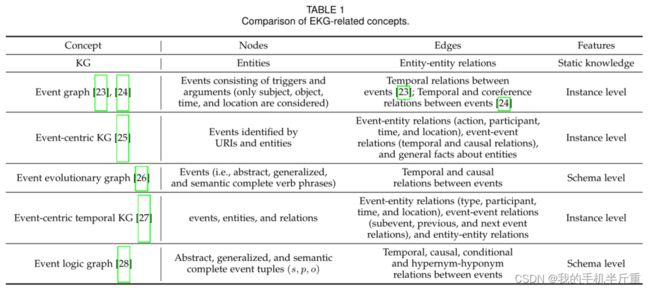
阶段3:KG和事件图谱出现。 值得注意的是,在2012年,为了显著增强谷歌搜索返回的结果,谷歌提出了KG的概念,它集合了语义网络中所有的实体和关系知识。此后,KG在各个领域引起了广泛的关注。然而,它是关于实体及其关系的,即静态知识,不能优雅地处理事件。它在某种程度上引发了对事件及其关系的知识表示形式的出现。2014年,Glavas和Snajder[23]提出了一种新颖的基于事件的文档表示模型——事件图谱,该模型对文本中描述的事件信息进行过滤和结构,以满足对事件相关信息的高效检索和简洁表示的需求。在这个事件图谱中,节点表示由触发词和参数组成的事件(只考虑主语、宾语、时间和位置),而边表示事件之间的时序关系。2015年,Glavas和Snajder[24]进一步增加了事件之间的共引用关系。具体来说,为了通过新闻文章报道的事件来描述世界的变化,Rospocher et al.[25]在2016年提出了以事件为中心的KGs,节点是由URIs和实体标识的事件,边为事件-实体关系、事件-事件关系和关于实体的一般事实。事件-实体关系考虑了动作、参与者、时间和位置,捕获了事件的动态信息(什么、谁、时间和地点)。事件-事件关系包括时间关系和因果关系。
阶段4:事件逻辑图产生。 近年来,随着事件预测、决策和对话系统场景设计等许多现实世界应用的发展,对事件的演化和发展有很大的需求。因此,Li et al.[26]在2017年提出了事件演化图谱。它类似于[23]中定义的事件图,但其中的事件节点由抽象、一般化和语义完整的动词短语表示。它进一步考虑了事件之间的因果关系,揭示了现实世界事件的演化模式和发展逻辑。然后,在2018年,Gottschalk和Demidova[27]提出了以事件为中心的时序知识图谱,其中事件、实体和关系被表示为节点,以促进对网络、新闻和社交媒体上的当代和历史事件信息的语义分析。其中的事件具有主题、时间和地理信息,并与参与事件的实体相关联。他们还考虑了实体关系,以及事件之间的子事件、前事件和下事件关系。2019年,事件演化图被发展为事件逻辑图[28],节点是抽象的,广义,和语义完整事件元组(s p o), p是行动/谓词(也就是说,事件触发),s是行动者/主语,o是执行操作的对象。此外,我们还考虑了另外两种事件之间的关系:条件关系和上义词和下义词(is-a)。
一般来说, EKG相关的概念有很多。如表1所示,事件演化图[26]和事件逻辑图[28]只关注模式级(schema-level)的事件知识。事件图谱[23]、[24]和事件逻辑图中的节点是组合结构,难于处理。此外,这些与EKG相关的概念都考虑了特定的和有限的论证角色,以及事件之间的特定的和有限的关系。实际上,一个事件有它的组成部分,每个组成部分由一个参数和参数在事件[29]中扮演的角色组成。此外,事件之间有许多不同的关系。
2.2 定义
如2.1节所述,有一些EKG相关的概念存在不足。我们遵循这个思路,但引入更丰富的内容,如下所示。
我们认为EKG以事件为中心,有两种节点,事件和实体,三种有向边,即事件-事件关系、事件-实体关系、实体-实体关系。第一种关系包括事件之间的各种关系,如时序关系、因果关系、条件关系、主位关系等。第二种类型的关系表示事件的论元,即,边是链接事件的实体的论元角色。不同的事件类型有不同的论元角色。第三种描述实体之间的关系,如place of birth、located in、has part等。形式定义如下:
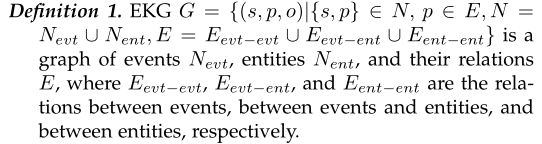 通过这种方式,事件可以很容易地被公共论元实体连接起来,反之亦然。因此,KG是EKG的一个特例,只有实体节点和实体-实体关系。
通过这种方式,事件可以很容易地被公共论元实体连接起来,反之亦然。因此,KG是EKG的一个特例,只有实体节点和实体-实体关系。
3.什么是EKG,本体视角
从本体的角度来看,我们研究了模式(schema)和相关的任务。EKG的模式描述了构成它的基本概念,比如事件类型、事件论元的角色以及事件之间的关系。事件类型和事件论元的角色构成了事件的框架,即事件模式。对于事件之间的关系,典型的脚本[30]根据一些事件关系组织一组事件,这些事件关系共同描述了常见的场景。在本节中,在介绍EKG模式归纳之前,让我们先从事件模式归纳和脚本归纳开始。
3.1事件模式归纳
事件模式可以手工设计,也可以自动提取。例如,ACE事件模式[18]、[29]和FrameNet框架[31]是典型的手工设计的事件模式。由于手工设计的事件模式具有较低的覆盖范围和较难适应领域的特点,因此事件模式的自动抽取即事件模式归纳受到了研究人员的广泛关注。它会自动从文本中提取事件类型及其对应的参数角色。现有的该任务的方法可以分为监督、半监督和无监督方法。其中,最后一个更受欢迎。
早期的研究采用有监督学习的方法。 他们从带注释的数据中学习,然后从新的文档[32]、[33]、[34]、[35]中归纳出事件模式。例如,第三次MUC评估中的方法使用了模式匹配(如正则表达式)、语法驱动技术(将语法分析与语义和后续处理结合起来),或者将语法驱动技术集成到事件模式归纳[33]的模式匹配中。Chieu等人的[35]采用语义和篇章特征,为每个论证角色构建一个分类器,如最大熵、支持向量机(SVM)、朴素贝叶斯或决策树。
半监督学习方法半监督方法首先使用一些带注释的种子(seed)来导出事件模式[36]、[37]、[38]、[39]。例如,Patwardhan和Riloff[38]创建了一个自训练的SVM分类器来识别感兴趣领域的相关句子,然后使用语义亲和度度量自动提取与领域相关的事件模式。自训练过程从一些种子模式和一组相关和不相关的文档开始。下面的事件模式抽取是基于启发式规则的句法分析。然后根据频率对提取的结果进行语义亲和度排序,以保持最优结果。Huang和Ji[39]通过利用对一些可见类型可用的注释,从给定的语料库中自动发现一组不可见的事件类型。他们设计了一个矢量量化变分自动编码器框架来自动学习每个可见或不可见事件类型的类型嵌入,并使用可见事件类型注释优化了框架。进一步引入一种变分自动编码器,根据事件类型的分布要求对每个事件触发词进行重构。
无监督方法消除了标注数据的要求, 广泛应用于[40]、[41]、[42]、[43]、[44]、[45]、[46]、[47]、[48]、[49]、[50]。例如,Chambers和Jurafsky[42]将事件模式归纳视为一项旨在从无标记语料库中发现不受限制关系的任务。他们使用点态互信息(PMI)来测量事件和根据距离聚集的事件之间的距离。Balasubramanian et al.[43]利用(主语、谓语、宾语)对的共现统计量来构建一个图,将这些三元组作为节点,并根据所涉及的三元组对的对称条件概率加权。其中的三元组使用词根和语义类型进行规范化。他们以图中的高连通性节点作为种子开始。然后,他们使用图分析来找到与种子密切相关的三元组,并合并它们的论元角色来创建事件模式。Chambers[44]提出了第一个类似于LDA[51]的模式归纳生成模型。Nguyen等人[45]进一步介绍了实体消歧。
最近的研究引入表示学习来导出无监督的事件模式[46],[47],[48],[49],[50]。如Yuan et al.[47]提出了一个两步框架。他们首先通过对新闻文章进行聚类从新闻语料库中检测事件类型。然后,他们提出了一个基于图(graph-based)的模型,该模型利用实体共现信息来学习实体嵌入,然后将这些嵌入聚为论元角色。2019国际语义评估研讨会(International Workshop on Semantic Evaluation)的方法通常采用预训练的语言模型,如BERT[52],来获得语境化的词嵌入[48]。然后,他们将这些嵌入与手工制作的特性聚集在一起,并将它们与现有事件模式的事件类型和论元角色对齐(例如,FrameNet)。Yamada et al.[49]认为以往的研究过于关注言语事件触发的表层信息,提出利用BERT中的掩模词嵌入来获得深层语境化的词嵌入。然后,他们应用了两步聚类方法,首先根据嵌入情况聚类同一个动词的实例,然后再跨动词进行聚类。最后,将每一个生成的聚类视为一个导出模式。
总之, 对于监督方法,它们很难应用于新的事件类型,这限制了它们的使用。对于半监督和非监督方法,自动生成的事件模式具有噪声和难于对齐的特点。到目前为止,这些技术还不太适用于为EKG构建事件模式。
3.2脚本归纳
脚本可以被看作是表示特定场景的事件模式的典型结构。具体来说,它将一系列事件组织成特定的结构(通常根据它们的时间关系)。图2显示了一个典型的脚本示例,即餐厅脚本,它模拟了客户在餐厅吃食物的场景。脚本有一个主要的特性,即脚本中的“事件”,通常称为脚本事件,是事件模式而不是事件实例。
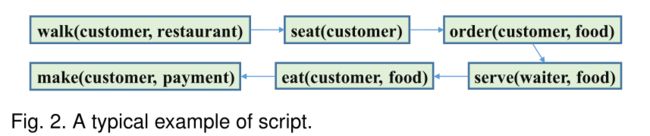
在早期的研究中,脚本是手工设计的[30],[53]。在最近的研究中,研究人员试图从文本中自动提取脚本,即脚本归纳。其中的一个挑战是自动学习特定场景的论元角色。因此,Chambers和Jurafsky[54]提出了一种启发式方法,该方法使用实体共引用链中出现频率最高的首词作为该实体的参数角色。Regneri et al.[55]通过互联网从志愿者那里收集了脚本特定事件序列的自然语言描述。然后,他们使用多序列对齐算法计算出脚本时间结构的图(graph)表示。这张图说明了哪些短语可以描述场景中的事件,以及这些事件发生的顺序。Cheung等人提出了一种概率方法,该方法定义了文档中单词的联合分布及其脚本分配。具体来说,他们将一个脚本隐马尔可夫模型(HMM)[57]与一个事件HMM结合在一起,其中第一个HMM建模脚本转换和触发事件,第二个HMM在脚本中建模事件转换触发论元角色。Orr等人[58]也基于HMM从文档中学习脚本。不同的是,HMM的状态对应于脚本中的事件类型,而观察结果对应于描述故事中发生的事件实例的句子。利用聚类算法获取状态和观测值。然后,他们开始对事件序列进行完全枚举的HMM表示,并增量合并状态和删除边(状态转换),以提高给定数据的结构和参数的后验概率。Weber等人[59]认为纯粹的基于相关性的方法是不够的,并提出了一种基于事件间因果效应的脚本归纳方法,该方法通过使用贝叶斯网络方法的干预进行正式定义。Weber等人[60]和Ciosici等[61]进一步通过人机协作方式导出脚本。例如,假设一个共引用链包含“Jobs”、“Steve Jobs”和“CEO Jobs”。在这种情况下,上述方法将使用“Jobs”而不是“CEO”作为论证角色,这种方法过于具体,缺乏泛化。如何有效、高效地学习高质量的情景化论元角色,仍然是一个有待解决的问题。
脚本可以被看作是关于事件的规则,在某些场景中形成事件的演化模式。脚本的一个基本应用是通过脚本事件预测来预测将来会发生什么。具体来说,首先将已知的现实世界事件一般化为脚本事件。然后,使用这些脚本事件派生出后续的脚本事件,称为脚本事件预测。最后,预测的后续脚本事件可以实例化为真实世界的事件。我们将在第5.1.1节中描述脚本事件预测的更多细节。
3.3 EKG模式归纳
对EKG模式的直接归纳已有研究。由于长期以来EKG相关研究未被提出,对EKG模式归纳的研究相对较少且较新。2020年,Li等[65]首先研究了事件图谱模式归纳,关注的是丰富的事件组件和事件-事件连接。提出了一种路径语言模型来构造一个事件图谱模式存储库,其中两种事件类型通过多个事件-事件路径连接,这些路径涉及填充重要论元角色的实体。在事件图谱模式中,这些实体被它们的类型所替换。然而,这个工作只关注一对事件之间的联系。2021年,Li等[66]进一步对事件-事件、事件-实体、实体-实体关系三种类型的关系进行了研究。他们把schema看作是隐藏的知识,指导事件图的生成,通过最大化这些实例图的概率来学习。然而,对于事件关系,只考虑时间关系。
一般来说, 现有的关于EKG模式归纳的研究很少考虑到有限的关系类型。因此,从EKG模式归纳的角度来归纳EKG的整体模式,还有很长的路要走。
4. 什么是EKG:实例视角
从实例视角来看,本节介绍如何构建EKG,即事件获取和EKG相关的代表性的图/系统。
4.1 事件获取
事件获取是构建EKG的关键。它主要包括事件提取、事件关系提取、事件共指解析和事件论元补全。前两项工作是基础工作,后两项工作对构建更好的EKG至关重要。在本部分中,我们回顾了它们的发展过程和未来的趋势。
4.1.1 事件抽取
作为构建EKG的主要步骤,事件抽取的目的是从文本中提取结构化的事件信息,包括具有类型的事件触发词和扮演角色的论元。因此,有两个主要的子任务,触发词检测和论元抽取。每一阶段包括识别和分类两个阶段。触发检测标识事件触发词,并使用适当的预定义类型或群集类给它们赋值,而论元提取标识论元,并使用触发事件的适当论元角色给它们赋值。
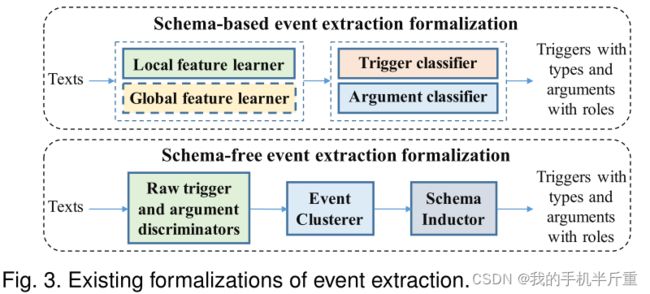
根据是否存在预定义的模式,事件抽取可以分为基于模式的事件抽取和无模式的事件抽取。如图3上半部分所示,现有的基于模式的方法以文本为输入,将文本传递给特征学习器,获得局部(和全局)特征。在此基础上,触发词和论元的分类器输出预定义模式上的总体概率分布,并根据峰值得到答案。对于无模式(schema-free)事件提取形式化(图3底部),将文本传递给鉴别器,得到原始触发词和论元,然后将这些原始触发词和论元聚为事件组,归纳出事件模式。其中通常使用简单的无监督事件模式归纳方法(见3.1节)。最后,它获取具有类型的触发词和扮演角色的论元。具体来说,考虑到输入数据的规模,基于模式的事件抽取可以进一步分为句子级和文档级事件抽取,无模式的事件抽取也称为开放域事件抽取。相对于文档级和开放域事件抽取,句子级事件抽取的研究更为广泛。
句子级别事件抽取 的目的是在一个句子中提取事件的触发词和论元。早期的方法设计了详细的特征,如词特征和句法特征,通过统计学习方法来解决这一任务[67],[68],[69]。例如,Liao和Grishman[69]利用文档级事件和角色特征来改进句子级事件提取。具体来说,他们在许多构造的模式下应用基于最大熵的分类器来提取句子级别的事件。然后采用跨事件信息,如事件共现、不同事件的论元之间的关系,训练额外的基于最大熵的分类器。这些分类器用于推断新的事件和事件论元。近年来,随着大规模数据集的构建(如ACE[29]、TACKBP[70]、RAMS[71])和深度学习的发展,研究人员开始利用神经网络自动提取特征。根据特征类型,这些方法可分为三大类。第一类只使用子任务内的特性,包括词法和句法特性。这些方法通常遵循一个管道框架(pipeline framework),在不同的阶段依次执行每个事件提取子任务。第二类探索子任务间的特性,比如各种触发词类型和论元角色的共现。这些方法可以受益于事件触发词和相应论元角色之间的相互依赖关系。最后,利用多任务学习框架,探讨了实体抽取、实体关系抽取、事件抽取等相关IE任务之间的交互特性。
探索子任务内的特性 这类方法大多采用卷积神经网络(Convolutional Neural Network, CNN)或循环神经网络(Recurrent Neural Network, RNN)来提取子任务的特征。Chen等[72]提出了动态多池化CNN,以流水线的方式解决事件提取的两个子任务。他们使用CNN提取单词特征,并在触发词检测和论元提取中采用动态池方法提取不同候选单词的各种句子级特征。但是,作为一种基于cnn的方法,该工作不能很好地处理句子中单词之间的顺序关系和长时间依赖关系。因此,Chen等[73]采用了两个双向动态多池长短期记忆网络(Long - term Memory network, LSTMs)来依次解决触发检测和参数提取问题。此外,他们设计了一个张量层来探索候选论点之间的相互作用,并同时预测所有候选论点。随着BERT和ELMo等预训练语言模型的发展[74],近年来研究者将这些模型引入事件抽取中。如Yang等[75]在BERT上增加了多分类器用于触发检测,在BERT上增加了多组二值分类器用于论元提取。他们根据论元角色来区分论元预测,以解决角色重叠的问题,即一个论元在同一事件中可能有不同的论元角色。通过调整损失函数的权重来解决变元角色的长尾频率分布问题。Deng等[76]利用事件-事件关系(如时间关系、因果关系和层次关系)丰富了事件模式,以改进基于BERT嵌入的触发检测。最近,Du和Cardie[77]和Liu等人[78]提出了基于BERT的机器阅读理解框架,该框架采用问答过程从句子中提取事件元素。
探索子任务间的特性 这类方法探索了触发词检测和论元提取的子任务间特性,通常遵循联合架构,从而缓解了第一类管道框架的错误传播问题。Nguyen等[79]提出了一种基于双向LSTM (Bidirectional LSTM, BiLSTM)的联合模型。在事件提取过程中引入记忆向量来存储关节特征,作为序列标记。联合特性包括触发词子类型之间、论元角色之间、以及触发词子类型和论元角色之间的依赖关系。为了进一步利用句法特征,Sha等[80]提出了用于事件提取的依赖桥RNN。他们在RNN中添加了依赖桥来连接语法相关的单词,并在每对候选论元上构建了一个张量层,以捕获密集的论元级信息交互。为了更有效地捕获远程依赖关系,Liu等[81]提出了联合多事件提取方法。他们引入了一种基于注意的图卷积网络(GCN),通过句子的句法树路径来聚合单词信息。通过引入这些句法结构和自注意机制,该方法可以捕获更多的候选触发器和参数之间的交互特征。
探索IE间的特性 为了更好地对事件元素的语义信息进行建模,近年来研究人员通过引入其他相关的IE任务,包括实体抽取、实体关系抽取和共指消解,探索句子中词汇的全局特征。使用多任务学习框架,这些IE任务可以相互受益。Nguyen和Nguyen[82]使用双向RNN (BiRNN)学习句子中单词的嵌入,然后使用基于全连接网络(Fully Connected Network, FCN)和softmax的分类器进行实体提取和事件提取。Wadden等人[83]进一步处理了实体提取、实体关系提取、事件提取和共指消解。在通过BERT对句子进行编码后,他们列举了候选文本span,并基于span之间关系的当前最佳猜测构建了一个span图,其中事件触发器与它们的参数相链接,实体通过它们的关系相链接。然后,通过聚合邻近的嵌入来更新每个span嵌入。这些更新后的嵌入被传递给所有任务的基于fcn的分类器。然而,这些研究分别处理任务,而没有深入的互动。为了更好地探究IE间的特征,Lin等[84]同时提取实体、实体关系和事件。他们使用BERT来学习上下文形式的单词嵌入,并通过基于fcn的局部分类器计算所有候选触发词、实体和它们的配对链接的局部分数。然后,他们设计了一系列全局特征来描述候选触发词和实体之间的相互依赖性。之后,他们通过整合这些全局特征来捕获任务间和实例间的交互,用基于波束搜索(beam-search-based)的解码器搜索全局最优结果。
文档级事件抽取 句子级事件提取假设事件触发词及其论元在同一个句子中。然而,在真实的场景中,它们通常分散在文档中的多个句子中。因此,文档级事件提取是可行的。在文档级别的事件提取中存在几个新问题。例如,论元可能存在于不同的句子中,而一个文档通常包含多个事件。
早期的方法使用一系列明确定义的特征来建模事件和所涉及的实体。然后采用统计学习的方法提取整个文档中的事件[85]、[86]、[87]。例如,Ji和Grishman[85]获得了关于触发词和论元与特定类型的事件相关联的频率的文档范围和文档集群范围的统计信息。然后,他们使用这些信息来修正基于最大熵的分类器在许多构造的事件模式下的事件提取结果。这些手工制作的特征和注释的数据通常获取的代价高昂。为了解决这一问题,Yang等[88]采用远程监督的方法,对整个文档中的事件触发器和论元进行自动标注。利用标注的数据,他们训练了一个带有BiLSTM层和条件随机场(CRF)层的句子级事件提取模型。然后,他们使用一种论元补全策略,根据句子级别的事件抽取结果,自动填充周围句子中缺失的论元。该框架能够以流水线的方式利用补全策略处理论元分散问题。为了使用端到端方法处理文档级的事件提取,Zheng等人[89]将事件转换为基于实体的有向无环图。然后,他们将传统的事件提取任务转换为几个更简单的顺序路径扩展子任务,并使用内存机制处理它们。Xu等人[90]也做了这种转换,但进一步探讨了文档中不同句子之间的更多互动以及不同事件之间的相互依赖性。具体来说,他们在句子和实体上设计了四种边类型来构建一个图。然后,他们使用图神经网络(GNN)对交互进行建模,并获得实体和句子的文档感知嵌入。为了整合不同事件之间的相互依赖性,他们跟踪提取的事件,并将信息存储到全局内存中,以方便及时提取。Lou等人[91]则提出了一种多层双向网络,可以同时捕获文档级语义和事件间的相互依赖关系,用于触发检测。具体来说,在解码事件标签向量序列时,使用BiLSTM、BiRNN和FCN对句子内的事件相互依赖性进行建模。通过LSTM对这些句子级语义信息和事件标签信息进行聚合。然后Lou等[91]基于BiRNN和FCN将多个双向标注层叠加,实现句子间信息的迭代传播。最后的事件标签向量是来自不同层的加权和。
开放域事件抽取 与句子级和文档级事件提取任务不同,开放域事件提取通常没有任何预定义的事件类型或特定的论元角色。它的目标是主要从新闻专线这样的长文本和社交媒体流这样的短文本中提取事件。
对于长文本,Rusu等[92]提出了一种基于依赖解析器的方法。他们认为动词是事件触发词,然后分析动词和其他语法元素(实体、时间表达式、主语和宾语)之间的依赖路径,以识别论元。但是,与预定义的事件模式相比,语法关系过于简单,难以描述复杂的事件。为了同时提取事件和归纳模式,Huang等人[46]首先识别出所有能够匹配现有模式(如FrameNet)的名词和动词概念作为候选事件触发词,然后通过人工选择语义关系识别出它们的候选论元。然后,他们根据基于张量模型的嵌入情况对候选触发词和论元进行聚类,并对它们进行命名,从而获得模式和通过映射到现有模式的提取结果。与之不同的是,Liu等人[93]通过从不同分布中抽样,学习了带有标题、上下文特征和潜在事件类型的新闻聚类的联合概率分布。此外,他们还使用了一个预先训练的语言模型来改进嵌入。然后采用学习到的联合分布对新闻进行聚类,并运用一系列规则对新闻进行组合,得到最终结果。
随着社交网络的发展,社交媒体流每天都能产生大量的信息。这些短文对于探索事件也很有价值。这些短文对于探索事件也很有价值。不像从长文本中提取的开放域事件需要诱导复杂的模式,社交媒体流中事件的主要组成部分是实体、时间、地点和关键字。Abdelhaq等人[94]从推特流中检测出在一个小地理区域内重要的事件。对于时间轴上的每一帧,他们根据频率提取出所有候选事件关键字。然后,他们计算出候选关键字在特定位置的使用率的空间密度分布。选取熵值小(仅发生在少数地点)的事件,根据其空间密度分布对其进行聚类,得到事件。为了提取更多的信息,Wang等[95]将Twitter和相关网页的信息融合,分别通过基于Twitter的CRF和基于页面的CRF来识别事件,并提取事件的时间、地点和标题。但是,多个提及可能会指向同一个实体,并且它们会被上面的方法错误地分配给不同的事件。因此,Zhou等人[96]提出了一种非参数贝叶斯混合模型,用于从Twitter中提取事件,该模型结合单词嵌入来解决这一问题。Xu等[97]进一步应用BiLSTM层、控制门层和CRF层从Twitter中提取事件。
总之, 虽然对事件提取的研究由来已久,但目前的方法仍不能满足高质量构建EKG的需要。现在的性能是不够的,特别是对于困难的论元提取。从而将噪声信息引入EKG构建中。此外,部分由于论元提取的性能较低,一些关于EKG应用的研究,如脚本事件预测和时间KG预测(见章节5.1.1和5.1.2),只考虑了较为简单的固定论元角色、主语、宾语和间接宾语或时间,而没有考虑明确定义的复杂模式。因此,提高这个主要事件抽取任务的性能是非常重要的。
4.1.2 事件关系提取
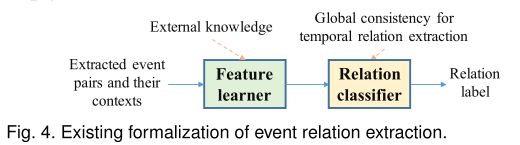
除事件提取外,事件关系提取是构建EKG的基本步骤。它从文本中提取事件之间的关系,从而将事件连接起来得到EKG。事件关系的主要类型有时间关系和因果关系。事件时间关系描述事件之间的时间顺序。事件因果关系描述事件之间的因果关系,是事件时间关系的一个子集。简而言之,我们分别使用时间关系和因果关系这两个术语。这两种类型的关系提取具有相似的研究方向。它们通常被形式化为给定事件对和上下文的简单文本分类任务。 如图4所示,将提取的事件对及其上下文传递给特征学习器,捕捉有用信息,进行事件关系提取。基于这些特征,关系分类器输出关系标签。有些方法还引入了外部知识。对于时间关系的提取,也有考虑全局一致性问题的方法。例如,如果分类器得到的结果是:A在B之前(A before B),B在C之前,C在A之前,那么就存在冲突。实际上,前两者暗示A在C之前。
早期的方法严重依赖于人工设计的句法和语义特征[98]、[99]、[100]、[101]、[102]、[102]、[103]。 然后他们使用机器学习模型,如朴素贝叶斯、最大熵或支持向量机作为分类器来识别关系。如Chambers等[100]提出了一种两阶段时间关系提取方法。第一阶段学习单个事件的时间属性,如时态、事件类型、情态和极性。第二阶段,结合其他语言特征,利用支持向量机对事件间的时间关系进行分类。Rink等[102]使用图模式作为特征来训练SVM分类器。具体来说,他们首先为一个句子构建了一个图表示,这个句子编码了词汇、句法和语义信息。然后,他们通过频繁的子图挖掘算法,从这些图表示中自动提取多个图模式,根据它们在确定同一句中事件之间的因果关系时的相关性进行排序。这些图模式特征被传递给SVM分类器。Zhao等[103]提出了一种受限隐朴素贝叶斯模型来处理特征之间的交互作用,用于因果关系提取。除了语境特征、句法特征和位置特征外,他们还利用了因果连接词的一种新的类别特征,这一特征是由表示因果关系的句子的句法依赖结构的相似性得到的。
上述的时间关系提取方法通常侧重于两两决策,而忽略了全局一致性。因此,许多方法进一步考虑了全局一致性[20],[22],[104],[105],[106],[107],[108]。Bramsen等人[20],Chambers和Jurafsky [104], Do等人[22]在上述局部分类器的基础上应用了整数线性规划(ILP)。Chambers等人[106]提出了一种级联结构,根据分类器的精度排序。分类器按顺序运行,从最精确的开始。全局一致性是通过在将结果传递给下一个分类器之前从早期分类器的结果推断所有传递关系来实现的。Mirza和Tonelli[107]进一步应用了类似的方法,如时间关系提取器和因果关系提取器。其中,时间关系提取器中的标签作为因果关系提取器的特征,因果关系提取器中的标签用于修正时间关系提取器标注错误的事件对。与这些管道(pipeline)方法的全局一致性不同,Yoshikawa等[105]和Ning等[108]在学习阶段考虑全局一致性。Yoshikawa等人[105]提出了一种马尔可夫逻辑模型,并通过添加加权一阶逻辑公式来捕获全局一致性。而Ning等人[108]提出了一种结构化学习方法,通过在每一轮学习过程中进行全局推理,用反映其他关系的反馈来训练局部分类器。除了上述的句内因果关系提取,Gao等[109]还设计了词汇特征、潜在因果特征(两个事件在一句话中共现)和句法特征,用于文档层面的句内因果关系和跨句因果关系提取。因果结构的这些全局和细粒度方面是通过ILP学习的。
更近期的方法是利用神经网络,如CNN和LSTM,学习有用的特征来自动提取[110]、[111]、[112]、[113]、[114]、[115]。 他们使用CNN或LSTM对事件句进行编码,然后使用基于FCN和softmax的关系分类器。为了在时间关系提取中做出更好的全局一致性决策,Han等[113]进一步采用了一种基于svm的结合传递性约束的算法,Ning等[114]进一步采用了ILP算法。与此不同的是,Cheng和Miyao[116]采用BiLSTM沿着事件句的依赖路径提取时间关系。
为了进一步利用外部知识,Ning等[114]将Siamese网络应用于时间常识知识库,将其输出与事件句的LSTM输出连接起来,提取时间关系。而Li和Mao[115]提出了一种面向知识的CNN用于因果关系提取,从词汇知识库中自动生成卷积过滤器来表示因果关系的关键字和线索短语。他们还结合传统的CNN,从训练数据中学习因果关系的其他特征。
为了进一步引入其他相关任务,Han等[117]将事件和时间关系联合提取,以避免传统流水线方式的误差传播,然后再将其提取出来。具体来说,在通过BiLSTM对句子进行编码后,他们使用输出来计算成为事件的概率,以及所有可能的时间关系标签上的softmax分布。最后一层结合传递性约束、对称性约束等考虑全局一致性。Wang等[118]提出了一种类似的时间和子关系提取方法,但将上述基于svm的层替换为可微分的约束学习层。将逻辑约束转化为可微函数,并纳入关系提取的学习目标中。与这些硬性约束不同,Han等[119]将语料库统计量作为软约束,利用拉格朗日松弛法解决约束推理问题,以保证全局一致性,改进了事件提取和时间关系提取的相似网络。
值得注意的是,由于预训练语言模型在各种各样的NLP任务中表现良好,研究人员已经将其引入到事件关系提取中,如BERT。 许多基于神经网络的研究简单地使用BERT作为预训练模型[113]、[114]、[117]、[118]、[119]。与他们不同的是,Liu等[120]和Zhou等[121]采用BERT方法直接对事件句进行编码。例如,Liu等人[120]提出了基于提及掩蔽概化的知识增强事件因果关系提取方法。具体来说,该模型由感知推理机、提及掩蔽推理机和注意哨(attentive sentinel)在两个模块之间的权衡组成。第一个模块使用BERT来建模句子,其中事件被外部知识的定义所取代,学习更具表达性的事件嵌入。第二种方法采用另一种BERT模型,将提及的事件替换为一个占位符[MASK],挖掘事件无关和上下文特定的模式进行推理。
近年来,一些基于bert的研究主要是通过引入外部知识来解决因果关系抽取中的数据缺失问题[122]、[123]、[124]、[125]。Zuo等[122]提出了一种知识增强的远程数据增强框架。他们根据词汇知识提取因果关系概率高的事件对,并利用提取的事件对通过远程监督自动标注句子。然后,他们在因果常识知识的帮助下,对标注远程的句子进行精炼。在这之后,他们采用了重新标记和退火策略,利用远程标记的句子进行训练。其中的因果关系抽取模型是基于事件句的BERT编码器和基于fcn的分类器。Zuo等[123]进一步提出了一个知识引导和可学习的数据增强框架。他们将目标任务、因果关系提取和增强任务、句子生成等视为双重任务,并通过双重学习对它们之间的相互关系进行建模。具体来说,他们从外部知识中引入不同的因果事件对来初始化二元生成,确保生成的因果句具有因果性。基于BERT算法实现了因果关系抽取和句子生成。与之不同的是,Zuo等人[124]设计了一个自我监督框架,从外部因果陈述中学习语境特定的因果模式。然后,他们采用对比迁移策略,将学习到的语境特定因果模式纳入基于BERT的目标因果关系抽取模型。而Cao等人[125]将事件句BERT的上下文化后的嵌入连接起来,将来自外部知识的事件单跳邻居的GCN嵌入,以及来自外部知识的事件对之间最短多跳路径的GCN密连嵌入。然后,他们将串联的嵌入信息传递给基于FCN和软max的分类器。
以上基于bert的因果关系提取方法仅限于句内提取的背景。对于文档级别的设置,Phu和Nguyen[126]提出了一个基于图的模型。他们应用BERT对文档中的单词进行编码,这些单词用于为考虑到基于话语、基于语法和基于语义的信息的文档生成交互图。然后GCN使用这张图学习文档上下文增强嵌入,基于FCN和softmax提取事件之间的因果关系。
一般来说, 现有的事件关系提取方法不能完全满足EKG构建的要求。例如,目前的事件关系提取通常只关注作为事件的动词,而不考虑作为事件的名词。事实上,除了动词,事件触发器也可以是名词。另一个限制是现有的研究忽略了论元。未来的事件关系抽取研究应注意这些基本问题。
4.1.3 事件共指消解
通常有很多文本描述相同的事件。因此,为了更好地构建EKG,有必要在提取事件后,将现实世界中相同事件的事件分组到同一个簇中。这个任务称为事件共指消解。研究者通常根据事件是来自同一文档还是不同文档,将其分为文档内背景环境和跨文档背景环境。后者更复杂,因为它很难处理来自不同文档的事件上下文。例如,来自不同文档的语义相似的事件上下文可能描述不同的事件。
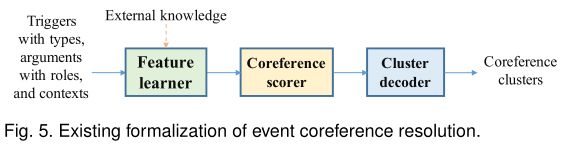
如图5所示,现有的事件共指解析方法将事件抽取的结果及其上下文作为输入,传递给特征学习者和共指评分者,得到事件之间的共指结果。然后,利用类似的聚类解码器对局部结果进行合并,得到全局结果,并采用一定的规则或聚类算法。一些方法额外引入外部知识来提高特征学习。具体来说,现有的事件共指消解方法可以分为无监督方法、半监督方法和监督方法。
无监督方法 构建基于特征模板的事件表示,然后进行模式匹配或采用无监督概率模型来识别事件之间的共指关系[127]、[128]、[129]、[130]、[131]、[132]、[133]、[134]。
早期的研究采用简单的基于规则的方法来处理事件共指消解[127],[128]。他们应用事件触发器和事件之间论元的一致性来确定事件是否为共指。随后,一些研究[129]、[130]、[134]利用事件触发器的词汇相关特征(如编辑距离)、论元相关特征(如共指论元)、语义相关特征(如词嵌入相似度)和其他手工特征来构建事件表示。然后,采用最大熵、非参数贝叶斯估计、余弦相似度等方法确定事件对在文档内或跨文档背景下的共指得分。此外,Chen和Ng[132]提出了一种无监督概率模型用于文档内事件共参照解析,并进一步引入了照应判定。利用触发器和参数的词汇和语义特征,采用期望最大化算法估计模型参数。
这些无监督的共参考解析方法直观而高效。它们通常可以处理文档内部和跨文档背景下的任务。然而,它们需要精心设计的规则或匹配策略,而且它们的可伸缩性受到严格限制的特性模板的限制。
半监督方法 注重现有标注语料库的稀缺性[135]、[136]、[137]、[138]。它们使用少量标记数据和大量未标记数据进行事件共指消解。
例如,Sachan等人[136]提出了一种基于主动学习的内部和跨文档事件共指消解框架。采用最大不确定性策略、最大期望判断错误策略和探索利用策略等启发式样本选择策略选择事件对进行人工标注。因此,在较低的人工成本下,可获得可接受的共指消解性能。此外,Peng等[137]在一个监督程度最小的统一的框架内进行了触发检测和事件共指消解。他们将事件共指消解转化为事件嵌入之间的相似度计算问题。事件嵌入是通过将从外部文本中训练出来的元素的嵌入拼接而得到的。触发器检测采用候选触发器与事件类型之间的相似性,其中事件类型嵌入是事件样本嵌入的平均值。根据给定的少量标记样本,分别调整触发器检测和事件共指消解的相似阈值。
这些方法针对语料库资源的不足,充分利用了现有的数据,甚至外部资源。它们通常可以应用于文档内部和跨文档环境。它们有效地扩展了事件共指消解的应用,特别是在资源匮乏的情况下。但是,它们的作用是有限的,外部资源可能会引入噪声。
监督方法。 随着MUC[17]、ACE[29]和ECB/ECB+[131]、[139]等数据集的构建,以及TAC KBP事件Nugget检测评价任务的开发[70],研究人员开发了许多事件共指消解的监督方法。根据共同引用评分者处理的事件共指消解示例的形式,有两种类型的模型:事件对模型和事件排名模型。
事件对模型 是最常见但最有影响力的监督方法。他们对事件对进行处理,采用二分类器作为共指评分器,为每个事件对分配一个共指概率[140]、[141]、[142]、[143]、[144]、[145]、[146]。
如Krause等[142]采用CNN作为特征学习器,将事件的整个句子作为输入,将其输出与事件触发器及其左右邻域的嵌入拼接起来,得到事件嵌入。将两个事件的嵌入与它们的成对特征(如论元重叠)进行连接和扩充。然后,将拼接的向量传递给FCN,然后使用逻辑回归分类器作为共指评分器。此方法只关注文档内的事件对。为了处理文档内部和跨文档的设置,Choubey和Huang[143]分别为文档内部和跨文档的事件对训练了两个基于神经网络的特征学习器和基于fcn的共指评分器。在此之后,他们交替地执行文档内集群合并和跨文档集群合并,以建模事件之间的二级相互依赖关系。这些方法都是先对每个事件进行嵌入,然后融合两个事件的嵌入,得到事件对的嵌入。为了进一步捕获两个事件上下文之间的语义交互,Zeng等人[146]提出了一种基于交互的文档内部和跨文档协同引用模型。具体来说,将事件对中的两个句子串联起来,并基于BERT将其输入特征学习器。同时,以语义角色标签嵌入的形式注入事件的内部结构信息。FCN和softmax作为共指评分器。Lee等人[140]和Barhom等人[145]进一步引入实体共指消解,通过两个任务的交互来提高性能。其中使用了词汇资源或预先训练的单词嵌入。
事件排名模型 同时处理给定事件之前提到的所有事件,即先行事件。模型通过训练为每个拥有最高排名的给定事件指派第一个共指先行词[147]、[148]、[149]、[150]、[151]、[152]、[153]。
例如,Lu和Ng[148]训练了一个概率模型来为文档中的每个事件共同选择共指先行词。他们首先定义了先行向量,其中第i个元素是给定文档中第i个事件的共引用先行索引。他们假设给定事件的特征,先验向量的概率服从指数分布。然后,采用对数线性模型将最高分数赋给前因式向量。然而,由于共指关系可能是长距离的,文档级别的信息可能有助于事件共指消解。因此,Tran等[152]对每个文档构造结构图,并使用GCN进行表示学习。结构图中的节点是文档中的事件、实体和单词。这些节点通过不同的信息进行连接,如连接共指实体、连接事件及其参数、连接相似的词/事件等。将来自GCN的事件嵌入信息反馈给基于fcn的共指评分器。此外,首先利用黄金(g)事件簇和预测事件簇之间的簇内和簇间一致性来正则化事件嵌入。为了利用跨任务交互或一致性约束来获得更好的共指性能,许多方法进一步将触发检测、实体共指消解、指代确定、实相检测或论元提取纳入联合学习框架[147]、[149]、[150]、[151]、[153]。
值得注意的是,由于提及排序方法通常需要使用更多的上下文信息,所以它更适合于文档内事件的共指消解,并且可能会为跨文档环境引入噪声。
一般来说, 现有的事件共指消解研究在实践中还存在一些不足,不能满足现实场景的需要。例如,大多数方法指定所有事件都有固定的论元。然而,在实际应用中,论元通常因事件而异。此外,一些方法只考虑文档内事件的共指消解,不能同时处理跨文档的环境,而这两种方法对于更好地构建EKG都很重要。此外,现有方法对计算效率的重视程度较低。高复杂度的事件共指解析模型将成为一个瓶颈。因此,未来的研究应侧重于开发实用、有效、高效的事件共指解析方法。
4.1.4 事件论元补全
由于原始文本中的信息是不完整的,而事件提取不可避免地会有一些缺失,所以被提取的事件往往会缺少一些元素。因此,事件论元补全的目的是补全已有的事件,通常将其形式化为推断和填补事件中缺失的论元或论元角色。
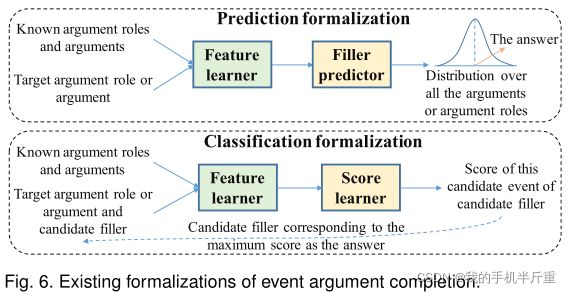
现有的方法进一步将此任务形式化为预测或分类任务。如图6所示,预测形式化将已知的论元角色和论元,以及目标论元角色或论元作为输入,传递给特征学习器和填充预测器,得到目标论元角色或论元的预测参数或论元角色。然后,与所有的论元或论元角色进行比较,得到总体分布。选择与峰值相对应的论元或论元角色作为要填写的答案。分类形式化另外以候选填充为输入,学习形成的候选事件的得分。候选填充词对应的最大分数,然后选择作为答案。现有的研究方法在特征型学习器、填充型学习器和分数型学习器方面存在差异。
一些较早的研究借鉴了句子理解的主题匹配任务, 它决定了实体与动词的施动者和受者角色之间的匹配是否良好[154]。如Tilk等[155]提出了一种神经网络模型,将论元角色的嵌入与论证的嵌入相结合,得到论元角色-论元对的嵌入。他们将这些嵌入加在一起,以进一步结合目标论元角色,然后预测缺失的论元。Hong等[156]用加权和替换了论元-论元对的嵌入和,并预测了目标论元缺失的论元角色。
随时间变化的EKG可以按时间重新排列成一系列的图。然后,基于时间感知分数学习器对图序列中事件元素的时间特异性嵌入进行事件论元补全。 Garc´ıa-Durán等[157]和Leblay and Chekol[158]通过串联事件类型的嵌入,将事件发生的时间整合到事件类型的嵌入中。然后,将这些时间感知的事件类型嵌入和其他论元嵌入设计为分数学习器的组合操作,如TransE[159]。Dasgupta等人[160]将每个时间戳与超平面相关联。在特定时间有效的事件被投影到相应的超平面上,在超平面上,通过事件类型[159]计算论元的平移分数以完成任务。Xu等人[161]进一步试图通过最小化相邻时间步长的欧氏距离来保持相邻时间步的超平面之间的时间平滑。与之不同的是,Lacroix等人[162]将EKG表示为一个张量,其顺序对应于事件类型、时间和其他论元。然后进行张量分解,用重构后的张量进行事件论元补全。除了具有确切发生时间的事件外,TeRo[163]还处理了涉及时间间隔的事件,即具有开始时间和结束时间,并将每种事件类型表示为一对二元复嵌入。然后他们将其他论元分别映射到这两种事件类型的嵌入,并结合基于平移的分数[159]。
事件是典型的n元关系事实。因此,n元关系事实的补全方法也可以应用于事件论元补全。 早期的研究采用了基于平移的方法。Wen等[164]将候选填充物的每个候选事件的得分学习器定义为其参数到其事件类型超平面的投影结果的加权和,其中权值为其论元角色投影的实数。然后,Zhang等人[165]又通过FCN引入了两个论元共同参与一个共同事件的可能性。Liu等[166]进一步考虑了论元角色之间的关联性,以及各论元角色与所涉及的所有论元之间的相容性。随后,应用了基于张量的方法。Liu等[167]将事件表示为高阶张量,并对张量进行重构补全。Di等[168]进一步通过部分共享嵌入解决了数据稀疏性问题,并通过对张量进行稀疏化解决了过参数化问题。最近,基于神经网络的方法如雨后春笋般涌现。他们使用CNN[169]、[170]、[171]、[172]、FCN[169]、[172]、[173]、GNN[174]、[175]、Transformer[174]、[176]来学习特征,并获得数十个候选事件或预测填充词。如Guan等[169]采用CNN得到了论元-论元对的嵌入。然后,利用FCN计算出的论元-论元对之间的相关性来估计候选事件的得分。不同的是,Galkin等[174]将事件组织成一个图,并应用GCN作为特征学习器来获得事件元素的嵌入。然后,将特征学习器的已知事件元素的嵌入信息传递给基于Transformer的分数学习器,得到答案分布。
总的来说, 现有的事件论元补全研究多集中在事件本身,而忽略了事件之间的关系。引入事件关系可以增强事件论元补全的性能。这是未来一个有趣的研究方向。此外,研究者还将事件论元补全简化为推断一个缺失的论元或论元在事件中的角色。然而,在现实世界中,情况通常并非如此。更常见的是,论元角色和相应的论元都缺失了。因此,未来的研究应注重更加现实的形式化和方法。
4.2 EKG相关的代表性的图/系统
随着事件获取技术的发展,出现了一些与EKG相关的代表性图/系统,它们针对特定的或一般的领域。
特定领域的图/系统。 2016年,Rospocher等[25]构建了4个以事件为中心的KGs,即由不同种类的新闻生成的WikiNews英语版、FIFA世界杯英语版、Cars英语版和Airbus语料库英语版、荷兰语版和西班牙语版。这些以事件为中心的KGs分别有超过62.4万个、930万个、2500万个和2500个事件。一些特定的事件-实体关系(例如,论元角色)和事件-事件关系将在2.1节中介绍。2017年,Li et al.[26]从大规模的非结构化Web语料库构建了中文旅游领域事件演化图。它是一个有向顺序关系图,节点是事件(简化为动词短语),边是事件之间用转移概率标记的顺序关系。2019年,Ding et al.[28]从大量新闻中构建了中国金融领域事件逻辑图。它关注事件之间的因果关系,由150多万个事件节点(即(主语、谓语、宾语)元组)和180万个事件节点之间的有向边组成。2020年,Wu等[4]基于海南旅游数据构建了以事件为中心的旅游KG模型,对游客出行的时空动态进行了建模。它的节点包含超过7千次旅行,约8.7万个事件,约14.1万个实体,而它的近22.8万个边表示事件的论元和事件之间约8万个时间关系。每个事件都包含三个组成部分:活动、时间和地点,并通过包含的关系与旅程联系在一起。2021年,Ma等人[177]提出了第一个事件管道系统EventPlus,该系统具有全面的事件理解能力,可以提取事件触发器、论元、持续时间以及事件之间的时序关系。该算法通过多领域训练实现多领域支持。而在其中的时间关系图中,节点代表事件触发器,边代表事件触发器的时间关系。事件的论元信息是独立的。
通用领域图/系统。 2018年,Gottschalk和Demidova[27]利用结构化和半结构化数据构建了一个以事件为中心的多语言时态KG EventKG,并考虑了一些事件-实体、实体-实体和事件-事件关系(见2.1节)。它有超过69万的活动。它进一步扩展到EventKG+Click[178],通过引入用户与事件、实体及其关系的交互,源自维基百科的点击流。此外,Gottschalk等人[179]在EventKG的基础上,进一步整合问答、实体推荐、命名实体识别等多个应用领域与事件相关的数据集,构建了超过4.36亿三元组的OEKG (Open EKG)。同样在2018年,Ning等[180]提出了一种时序理解系统,用于提取时序表示、事件触发以及事件触发之间的时序关系。其中没有考虑论元信息。2020年,Zhang等人[181]开发了ASER (Activities, States, Events, and their Relations),这是一种大规模的英语事件KG,提取自评论、新闻、论坛、社交媒体、电影字幕和电子书。在ASER中,每个节点是一个概率,它是一个依存图,而每条边是概率之间的关系。在依存图中,节点是对应句子中的词,边是这些词之间的依存关系。该系统考虑了五类事件之间可能的关系,即时序关系、偶发关系、比较关系、扩展关系和共现关系。完整版的ASER有超过1.94亿个事件和6400万个关系。
因此, 近年来开发了一些EKG相关的代表性图/系统。然而,它们都考虑了特定和有限的论元角色或事件-事件关系。实际上,不同的事件通常不会共享论元角色。此外,在现实场景中存在各种事件-事件关系。有必要开发实用的EKG,以促进未来的下游应用。
5. 什么是EKG:应用视角
通过引入事件、事件-事件关系、事件-实体关系,EKG掌握了事件的整体发展,具有很大的应用价值。本节将介绍其基本和深入的应用。
5.1 基本应用
EKG的基本应用在EKG上进行预测,它根据当前的EKG预测未来的事件。有两种方法可以预测EKG。第一种方法将事件实例泛化为脚本事件,然后根据给定的历史脚本事件在脚本级别预测后续的脚本事件,称为脚本事件预测[182]。预测的脚本事件最终可以实例化为真实事件。第二个直接在实例级别预测未来的事件。具体来说,现有方法将EKG简化为时序KG,形式化为带有时间戳的(s, p, o)的KG序列。然后,未来预测是对给定历史时间KG的未来时间戳预测未来事件,称为时序KG预测[183]、[184]、[185]、[186]。
5.1.1 脚本事件预测
由Chambers和Jurafsky[182]提出的脚本事件预测被形式化为脚本一致性评价,选择最大一致性得分对应的脚本事件作为答案。具体来说,Chambers和Jurafsky[182]将每个脚本事件表示为(主语、谓语)或(谓语、宾语)对。给定一个脚本事件,他们通过将脚本事件的一致性分数与脚本中所有脚本事件的一致性分数相加来计算它与脚本的一致性分数。他们使用基于计数的点状互信息(PMI)函数来衡量这一过程中的一致性得分。最后,采用叙事完形填空测试对该方法进行评价。在这个测试中,脚本中的一个脚本事件被屏蔽,并给出其他的脚本事件。要求模型预测被屏蔽的脚本事件(在下面,为了方便起见,将脚本事件表示为事件)。以下研究主要从三个方面对该模型进行了改进:
事件表示。 [182]中的事件表示可能会丢失主体与客体之间的共现信息。因此,Balasubramanian等人[43]将一个事件表示为一个(主语、谓语、宾语)三元体。Pichotta和Mooney[187]以及Granroth-Wilding和Clark[62]进一步将间接宾语引入事件表示法,即(主语、谓语、宾语、间接宾语),在以后的研究中得到广泛应用。然后,在最近的研究中,采用了分布式事件表示,即将事件表示为嵌入,以解决上述符号表示中的稀疏性问题。事件嵌入通常是通过组合组件来学习的。较早的研究采用的是加法组合方法[63]、[188]、[189]。具体来说,他们对线性变换的谓词和论元嵌入求和。Bai等[189]进一步将抽取的事件嵌入到原句中。然后,Weber等[190]和Ding等[191]提出了基于张量的事件嵌入模型,该模型利用神经张量网络来捕获事件元素之间的乘法交互作用。为了使基于张量的组合模型具有可扩展性,Weber等人[190]学会了基于共享的基张量生成交互张量,其元素由依赖于谓词嵌入的线性变换的值缩放。为了引入外部知识,Ding等人[191]引入了对事件意图和情绪的学习,并将其损失与基于张量的组合模型的损失相结合。最近,其他方法被采用为合成方法。Lee和Goldwasser[192]应用概率模型来学习事件嵌入。它们将每个事件表示为一系列基本事件标记、谓词、参数和事件属性,如事件情感和事件生命度(event animacy)。然后,在给定基本事件符号的情况下,他们学习了这个序列中其他事件的概率。他们还通过一个类似的概率模型捕获了后续事件之间的依赖关系。Granroth-Wilding和Clark[62]以及Lee和Goldwasser[193]采用FCN作为组合方法,将事件和参数一起进行编码。Lee和Goldwasser[193]进一步通过事件间的组合操作引入事件间的话语关系,学习关系感知的事件嵌入。Li等[64]除了通过组合方法获得事件嵌入外,还将事件组织成叙事事件演化图,并应用门控GNN更新事件嵌入。
脚本建模。 早期的方法主要是在脚本中对事件对进行建模,这些方法忽略了事件顺序,或者只考虑事件对之间有限的事件顺序。与[182]使用的PMI不同,有研究采用Bigram[187]、[194]、FCN[62]、余弦相似度[190]、[192]或基于平移的合成操作[193]对事件对的一致性得分进行建模。其他方法对脚本中的整个事件链进行建模。这些方法采用语言模型[195]、[196]、基于神经网络的概率模型[188]或LSTM[63]、[197]、[198]对整个事件链的顺序信息进行建模,从而获得较强的时间顺序信息。此外,Wang等[63]和Li等[64]在整合时间顺序信息后,也利用了基于事件对的模型。与这些单链模型不同,Chambers和Jurafsky[54]和Bai等[189]进一步聚合了来自多个事件链的结果。Li等[64]和Ding等[191]将脚本中的事件组织成叙事事件演化图,并采用GNN模型对该图进行建模。然后,他们通过聚合事件对的一致性得分来预测随后的事件,这是通过它们的嵌入在GNN中的相似性来计算的。
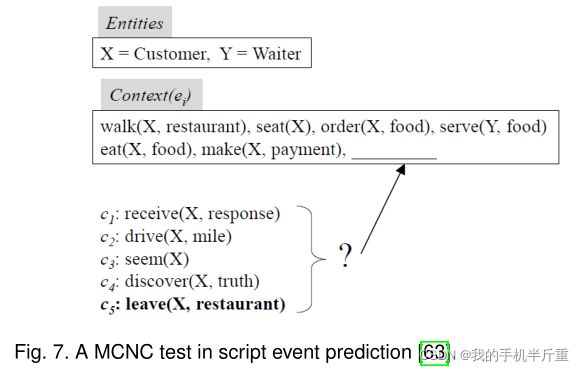
评估。 [182]提出的叙事完形填空测验的一个缺点是它不能识别多个似是而非的事件,因为只有最初的后续事件被视为正确答案。因此,莫迪[188]引入了对抗性叙事完形填空测试。这个测试要求模型区分正确链和负链,负链是正确链的副本,其后续事件被一个随机事件取代。Granroth-Wilding和Clark[62]进一步提出了多重选择叙事完形测验(Multiple Choice Narrative Cloze, MCNC)。如图7所示,本测试将答案事件限制为几个选项,要求模型从这些候选事件中选择正确的后续事件。在MCNC的基础上,后续的研究提出了两种变体,多重选择叙事序列(Multiple Choice Narrative Sequences, MCNS)和多重选择叙事解释(Multiple Choice Narrative Explanation, MCNE),以评估模型推断较长的事件序列的能力[192]。MCNS为每个步骤创建多个候选,除了初始事件。而MCNE则额外要求提供的结束事件,并推断其间发生了什么。在这些评估任务中,MCNC被广泛用于评估脚本事件预测的性能。
总之, 如上所述,有两种表示脚本的方法。第一种方法是以实体为中心的表示方法,它根据不同的参与者将脚本事件组织成事件链。对事件对或事件链建模的研究通常遵循这种方法。另一种方法是以事件为中心的表示方法,它将文档中的所有脚本事件组织到一个图中,这是一种新兴的表示方法。一般来说,以实体为中心的方法更擅长于对参与者及其脚本事件之间的关系进行建模,而以事件为中心的方法更擅长于对不同实体参与的脚本事件之间的交互进行建模。如何将两种方法的优点结合起来,还有待研究。在脚本事件预测中还有其他一些挑战。例如,如何真正预测随后的脚本事件,而不是从几个给定的候选人中选择答案?如何结合来自事件实例和脚本事件的信息?
5.1.2 时序KG预测
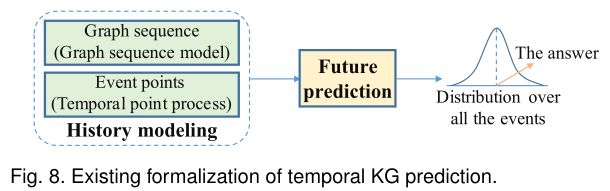
在实例级别预测未来事件需要模型理解历史事件。因此,如图8所示,现有的KG时序预测方法将该任务形式化为历史建模和未来预测两个步骤。在第一步,现有的方法集中于理解历史事件和建模它们的演变。在此基础上,现有方法预测未来事件,并在第二步输出对所有事件的分布。选择得分最高的事件作为答案。根据历史事件的组织和相应的建模方法,KG时间预测方法可分为基于图序列模型的方法和基于时间点过程的方法。由于时序KG是KG的序列,前者将历史事件组织为图的序列,其中每个图包含在相应时间戳发生的事件。后者将历史事件视为事件点,通常忽略同一时间戳下的并发事件。
基于图序列的方法。 在历史建模中,现有的这类方法通常首先提取相关的历史,它是一个子图序列。之后,他们将图序列表示为一个隐向量,或者直接学习主语、谓语和宾语的进化嵌入。在未来预测过程中,基于图序列的隐藏历史向量或事件元素的进化嵌入,计算所有候选论元(或谓词)的分布,进行论元预测,即主语/宾语预测(和谓词预测)。
现有的方法主要在相关历史提取过程上存在差异。一些方法通过启发式的方式提取与所关注的主语和谓词相关的部分历史事件。Jin等[185]提取给定主语和谓词的重复历史事件来预测对象,而Jin等[186]提取给定主语的历史事件。虽然可以设计许多启发式方法来提取相关历史,但这些方法依赖于人类知识,可能会忽略重要的历史事件。与上述启发式提取方法不同的是,Han等[199]从给定的主语出发,对子图中包含的论元的相关边进行迭代采样,并将给定的主语和谓词沿采样的边传播注意力分数。对于子图中的每个论元,它们只允许从前面的邻居(即论元发生时间之前的邻居)传递消息,以保持时态数据的因果性质。根据注意力得分,他们计算出作为目标的实体的得分。Li等人[200]和Sun等人[201]认为历史提取是一个顺序决策问题,并通过基于强化学习的方法从历史中搜索。与上述基于子图序列的方法不同,Li等人[202]在最后几个时间戳直接使用整图序列。通过叠加一个关系感知的GCN,他们获得了主体、谓词和对象在最终时间戳的进化嵌入。他们还引入了一个外部KG来规范这些嵌入。这些研究在离散时间域内模拟了时间KG。他们对按规则间隔的时间戳采样的时间KG进行快照,不能对不规律的时间间隔建模。为了对时间KG的连续动力学进行编码,Ding等人[203]将神经常微分方程(ODE)[204]的思想扩展到GCN,提出了一个连续模型。在ODE求解器之前,他们应用了一个GCN,根据当前时间的观察捕捉图的结构信息。进一步采用图的过渡层来明确地捕捉边的形成和删除信息。
基于时间点过程的方法。 在这里,时间点就是事件点。基于时间点过程的方法引入了条件强度函数,对这些时间点的演化特征进行了强有力的建模,在一个统一的框架内进行历史建模和未来预测。传统的基于时间点过程的方法总是参数化模型,条件强度函数是人工预先指定的[205],[206]。此外,它们只能对事件建模,而不考虑主语、谓语和宾语的语义。最近的一些研究[183]、[184]、[207]将传统的基于时间点过程的方法扩展到神经方法,利用深度神经网络拟合条件强度函数。基于神经时间点过程的模型在考虑事件元素的语义方面具有强大的功能。如Trivedi等[183]利用深度RNN学习论元的进化嵌入,根据所涉及论元的进化嵌入和谓词的嵌入,通过估计事件的条件概率来进行事件论元预测。即将事件的发生建模为一个多变量点过程,该过程的条件强度函数由其基于所涉及的嵌入的分数进行调节。这种方法更能对连续发生的事件进行建模,在这种情况下,同一时间戳中可能不会发生任何事件。为了进一步建模并发事件,Han等人[207]通过逐元素均值运算,将与给定主语相关的并发事件中对象的嵌入聚合为一个隐向量。然后,他们将时间建模为一个随机变量,并在时间KG上部署Hawkes过程[208]来捕捉潜在的动态,其中使用连续时间LSTM来估计强度函数。
一般来说, 现有的时序KG预测方法都集中在只有三个论元(主语、宾语和时间)的事件上,通常对给定的未来事件的其他元素进行论元预测或谓词预测。因此,时序KG预测仍然存在一些挑战。例如,如何用各种论元来模拟历史事件?如何从整体上实际预测未来事件,而不是要求每个未来事件只有一个元素是未知的?
5.1.3 其他基本应用
还有一些对EKG的直接分析,如时间轴的生成、溯因推理等。例如,Gottschalk和Demidova[209]使用以多语言事件为中心的时序KG EventKG[27]生成跨语言事件时间线。具体来说,对于查询实体或事件,他们依赖EventKG来提供关于事件流行度和事件与查询之间的关系强度的信息。Gottschalk和Demidova[210]和Gottschalk和Demidova[211]提出了传记时间轴生成的任务。对于被询问的人,他们从EventKG中提取了最相关的传记数据,简洁地描述了一个人的生活。其中使用了事件流行度、关系强度和谓词标签等特性。Du等人[212]提出了一种基于变分自编码器的事件图谱增强预训练语言模型用于溯因推理,该模型为观察到的事件找到最合理的可解释事件。具体来说,他们采用了一个额外的隐变量来从事件图谱中获取必要的知识。
5.2 深入应用
EKG可以进一步促进许多下游应用,如搜索、回答问题、推荐和文本生成。如Rudnik et al.[1]开发了一个基于事件的搜索引擎,既可以查询KGs的结构化数据,也可以查询新闻文章的非结构化文本内容,从而提高搜索能力。具体来说,他们将新闻文章中描述的事件映射到Wikidata中的事件[213],并且在可能的情况下,使用来自Wikidata实例的属性来注释新闻文章。然后,他们自动创建了一个粗粒度的模式。最后,他们实现了一个面向事件的KG和一个基于事件的搜索引擎。Yang et al.[2]实现了一个中医临床诊断和治疗的时间语义搜索系统。本搜索系统由在线部分和离线部分组成。离线部分主要是时序KG的构建、存储和索引,在线部分主要是对搜索语句的理解、转换和执行。Souza Costa等人的[3]解决了以事件为中心的问题,并采用EventKG[27]来创建查询。他们构建了第一个专注于以事件为中心的问题的问答数据集,以及唯一一个以EventKG为目标的问答数据集。Wu等人[4]提出了一种以事件为中心的旅游KG兴趣点(Point-of-Interest, POI)推荐CNN,该CNN融合了从事件为中心的旅游KG中获得的游客行为模式,以更有效地捕捉用户与POI之间的关系。因此,它们提高了推荐的准确性。Colas等人的[5]专注于图-文本生成(graph-to-text),以便以用户友好的方式更好地服务于图中的结构化信息。对于来自以事件为中心的时态KG EventKG的每个事件,他们使用来自Wikidata的额外信息来扩充数据,并将事件链接到Wikipedia页面以生成文本。
6.未来的发展方向
关于EKG的研究和成果有很多。然而,仍有几个方向需要关注和进一步研究。在本节中,我们将深入探讨这些未来的方向。
6.1 高性能的事件获取
最近的事件获取研究在有效性和效率上远远不能满足应用需求。特别是事件提取和事件关系提取的精度较低。从而阻碍了高质量基础EKG的构建。此外,现有的模型通常不重视复杂性问题。然而,高参数复杂度和高时间复杂度的模型不利于从大量数据中快速构建EKG。因此,高效率和高效率的事件获取是未来的一个重要方向。
6.2 多模态知识处理
在现实世界中,事件可能以文本、图像、音频和视频的形式呈现。然而,现有的关于EKG的研究多集中在文本处理上,而忽略了图像、音频、视频中的大量信息。对于多模态事件表示学习[214]和事件抽取[215]的研究很少。实际上,不同形式的事件可以消除歧义,相互补充。因此,多模态信息的联合利用是未来的一个重要方向。具体来说,来自所有模态的事件应在一个统一的框架中表示,事件获取研究应注意多模态提取,EKG推理也应考虑多模态信息。
6.3 可解释EKG研究
在EKG研究中,研究主要集中在用深度学习方法拟合训练数据。然而,它们通常缺乏可解释性,也就是说,对于它们为什么和如何工作没有明确的想法。实际上,了解最终结果的原因有助于在实际应用中采用它们。对于为什么最终结果是给定结果,这对于提供可解释性是友好的和令人信服的。未来可解释性EKG的研究将是一个重要的方向。
6.4 实践中的EKG研究
在EKG相关的任务中,有些任务形式化过于理想化,与现实场景相距甚远。例如,在一个现有的事件中,只完成一个缺失的论元或论元角色,通过从几个候选对象中选择它来预测未来的脚本事件,并且只预测未来事件的一个元素。在更实际的形式下进行研究更具挑战性,但也更有趣,对应用具有重要意义。
总结
EKG对于许多应用都很重要,包括智能搜索、问题回答、推荐和文本生成。本文从不同角度对EKG的研究进行了综述。特别地,我们深入研究了EKG的历史、本体、实例和应用视图。它的历史,定义,模式归纳,获取,相关的代表性的图/系统,和应用程序进行了深入的研究。根据其发展趋势,进一步总结了未来心电图研究的展望方向。