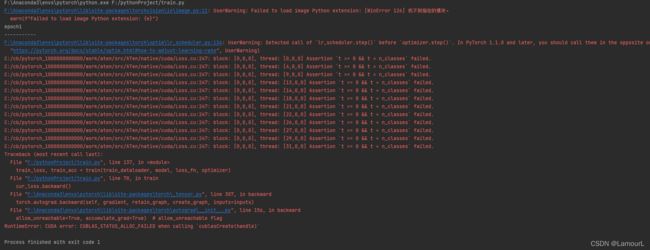
RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`,求解
RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling cublasCreate(handle)
问题求解啊!!!
代码报错这样子的
代码如下:
import torch
from torch import nn
from net import MyAlexNet
import numpy as np
from torch.optim import lr_scheduler
import os
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
解决中文显示问题
plt.rcParams[‘font.sans-serif’] = [‘SimHei’]
plt.rcParams[‘axes.unicode_minus’] = False
ROOT_TRAIN = r’F:/pythonProject/data/train’
ROOT_TEST = r’F:/pythonProject/data/val’
将图像的像素值归一化到【-1, 1】之间
normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
normalize])
val_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
normalize])
train_dataset = ImageFolder(ROOT_TRAIN, transform=train_transform)
val_dataset = ImageFolder(ROOT_TEST, transform=val_transform)
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=True)
device = ‘cuda’ if torch.cuda.is_available() else ‘cpu’
model = MyAlexNet().to(device)
定义一个损失函数
loss_fn = nn.CrossEntropyLoss()
定义一个优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
学习率每隔10轮变为原来的0.5
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
定义训练函数
def train(dataloader, model, loss_fn, optimizer):
loss, current, n = 0.0, 0.0, 0
for batch, (x, y) in enumerate(dataloader):
image, y = x.to(device), y.to(device)
output = model(image)
cur_loss = loss_fn(output, y)
_, pred = torch.max(output, axis=1)
cur_acc = torch.sum(y==pred) / output.shape[0]
# 反向传播
optimizer.zero_grad()
cur_loss.backward()
optimizer.step()
loss += cur_loss.item()
current += cur_acc.item()
n = n+1
train_loss = loss / n
train_acc = current / n
print('train_loss' + str(train_loss))
print('train_acc' + str(train_acc))
return train_loss, train_acc
定义一个验证函数
def val(dataloader, model, loss_fn):
# 将模型转化为验证模型
model.eval()
loss, current, n = 0.0, 0.0, 0
with torch.no_grad():
for batch, (x, y) in enumerate(dataloader):
image, y = x.to(device), y.to(device)
output = model(image)
cur_loss = loss_fn(output, y)
_, pred = torch.max(output, axis=1)
cur_acc = torch.sum(y == pred) / output.shape[0]
loss += cur_loss.item()
current += cur_acc.item()
n = n + 1
val_loss = loss / n
val_acc = current / n
print('val_loss' + str(val_loss))
print('val_acc' + str(val_acc))
return val_loss, val_acc
定义画图函数
def matplot_loss(train_loss, val_loss):
plt.plot(train_loss, label=‘train_loss’)
plt.plot(val_loss, label=‘val_loss’)
plt.legend(loc=‘best’)
plt.ylabel(‘loss’)
plt.xlabel(‘epoch’)
plt.title(“训练集和验证集loss值对比图”)
plt.show()
def matplot_acc(train_acc, val_acc):
plt.plot(train_acc, label=‘train_acc’)
plt.plot(val_acc, label=‘val_acc’)
plt.legend(loc=‘best’)
plt.ylabel(‘acc’)
plt.xlabel(‘epoch’)
plt.title(“训练集和验证集acc值对比图”)
plt.show()
开始训练
loss_train = []
acc_train = []
loss_val = []
acc_val = []
epoch = 20
min_acc = 0
for t in range(epoch):
lr_scheduler.step()
print(f"epoch{t+1}\n-----------")
train_loss, train_acc = train(train_dataloader, model, loss_fn, optimizer)
val_loss, val_acc = val(val_dataloader, model, loss_fn)
loss_train.append(train_loss)
acc_train.append(train_acc)
loss_val.append(val_loss)
acc_val.append(val_acc)
# 保存最好的模型权重
if val_acc >min_acc:
folder = 'save_model'
if not os.path.exists(folder):
os.mkdir('save_model')
min_acc = val_acc
print(f"save best model, 第{t+1}轮")
torch.save(model.state_dict(), 'save_model/best_model.pth')
# 保存最后一轮的权重文件
if t == epoch-1:
torch.save(model.state_dict(), 'save_model/last_model.pth')
matplot_loss(loss_train, loss_val)
matplot_acc(acc_train, acc_val)
print(‘Done!’)