【论文解读】A Frustratingly Easy Approach for Entity and Relation Extraction
Abstract
-
对于实体识别和关系抽取的联合任务,大多数使用结构化预测模型或共享参数。
-
而作者使用一个简单的流水线模型实现。方法使用两个独立的编码器,关系抽取的输入仅仅是实体识别的结果。
-
通过实验,验证了学习实体和关系的不同上下文表示、融合关系模型中的实体信息和整合全局上下文的重要性。(也就是说在关系模型中加入实体信息的重要性)
-
最后,提出了一个有效的近似方法,它只需要在推理时通过实体和关系编码器,实现8-16倍的加速,而精度略有降低
Introduction
在Introduction中作者表明:长期以来,人们一直认为联合模型可以更好地捕获实体和关系之间的交互作用,并有助于减少错误传播问题。实际上作者发现:
(1) 实体和关系模型的上下文表示本质上限制了不同的信息,因此共享它们的表示会影响性能;
(2) 在关系模型的输入层对实体信息(边界和类型)进行融合至关重要;
(3) 交叉信息在这两种任务中都是有用的。因此,我们期望这个简单的模型将作为端到端关系提取的一个非常强大的基线,并使我们重新思考实体和关系联合建模的价值。
对此,本文的主要贡献在于:
-
一种简单有效的端到端关系提取方法,该方法学习两个独立的编码器进行实体识别和关系提取。
-
得出结论,学习实体和关系的不同上下文表示比共同学习它们更有效。
-
提出了一种新的高效逼近方法,在精度下降很小的情况下,实现了较大的运行时间改进。
Method
-
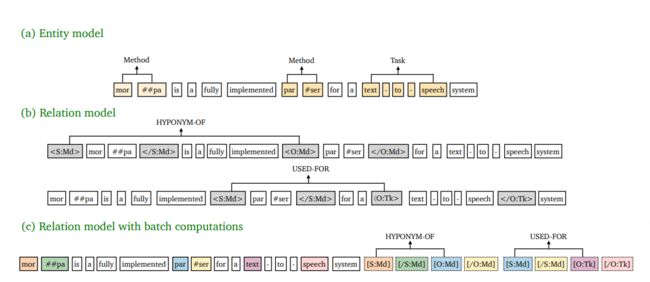
实体模型:如上图(a)所示,采取Span-level NER的方式,即基于片段排列的方式,提取所有可能的片段排列,通过SoftMax对每一个Span进行实体类型判断。这样做的好处是可以解决嵌套实体问题,但计算复杂度较高,因此需要限制Span长度(对于含n个token的文本,理论上共有 n(n+1)/2 种片段排列)。
-
关系模型:如上图(b)所示,对所有的实体pair进行关系分类。其中最重要的一点改进,就是将实体边界和类型作为标识符加入到实体Span前后,然后作为关系模型的input。例如,对于实体pair(Subject和Object)可分别在其对应的实体前后插入以下标识符:
-
-
S:Md和/S:Md:代表实体类型为Method的Subject,S是实体span的第一个token,/S是最后一个token;
-
O:Md和/O:Md:代表实体类型为Method的Object,O是实体span的第一个token,/O是最后一个token;
-
实体模型
构建span_embeddings
def _get_span_embeddings(self, input_ids, spans, token_type_ids=None, attention_mask=None):
sequence_output, pooled_output = self.bert(input_ids=input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask)
sequence_output = self.hidden_dropout(sequence_output)
"""
spans: [batch_size, num_spans, 3]; 0: left_ned, 1: right_end, 2: width
spans_mask: (batch_size, num_spans, )
"""
spans_start = spans[:, :, 0].view(spans.size(0), -1)
spans_start_embedding = batched_index_select(sequence_output, spans_start)
spans_end = spans[:, :, 1].view(spans.size(0), -1)
spans_end_embedding = batched_index_select(sequence_output, spans_end)
spans_width = spans[:, :, 2].view(spans.size(0), -1)
spans_width_embedding = self.width_embedding(spans_width)
# Concatenate embeddings of left/right points and the width embedding
spans_embedding = torch.cat((spans_start_embedding, spans_end_embedding, spans_width_embedding), dim=-1)
"""
spans_embedding: (batch_size, num_spans, hidden_size*2+embedding_dim)
"""
return spans_embedding
对于Span-level方法的实体识别,并不是对将整个句子做分类,而是将句子分为多个Span,然后对每个Span做分类:将Span的start,end与整个句子的bert_embedding对应起来,与width_embedding链接构成span_embedding。
模型结构
def forward(self, input_ids, spans, spans_mask, spans_ner_label=None, token_type_ids=None, attention_mask=None):
spans_embedding = self._get_span_embeddings(input_ids, spans, token_type_ids=token_type_ids, attention_mask=attention_mask)
ffnn_hidden = []
hidden = spans_embedding
for layer in self.ner_classifier:
hidden = layer(hidden)
ffnn_hidden.append(hidden)
logits = ffnn_hidden[-1]
if spans_ner_label is not None:
loss_fct = CrossEntropyLoss(reduction='sum')
if attention_mask is not None:
active_loss = spans_mask.view(-1) == 1
active_logits = logits.view(-1, logits.shape[-1])
active_labels = torch.where(
active_loss, spans_ner_label.view(-1), torch.tensor(loss_fct.ignore_index).type_as(spans_ner_label)
)
loss = loss_fct(active_logits, active_labels)
else:
loss = loss_fct(logits.view(-1, logits.shape[-1]), spans_ner_label.view(-1))
return loss, logits, spans_embedding
else:
return logits, spans_embedding, spans_embedding对于模型的结构其实很简单,就是将spans_embedding放入到全连接+softmax的分类器中,预测每个Spans的分类结果。
关系模型
def forward(self, input_ids, token_type_ids=None, attention_mask=None, labels=None, sub_idx=None, obj_idx=None, input_position=None):
outputs = self.bert(input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask, output_hidden_states=False, output_attentions=False, position_ids=input_position)
sequence_output = outputs[0]
sub_output = torch.cat([a[i].unsqueeze(0) for a, i in zip(sequence_output, sub_idx)])
obj_output = torch.cat([a[i].unsqueeze(0) for a, i in zip(sequence_output, obj_idx)])
rep = torch.cat((sub_output, obj_output), dim=1)
rep = self.layer_norm(rep)
rep = self.dropout(rep)
logits = self.classifier(rep)
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
return loss
else:
return logits关系模型也很简单,对每个sub和obj的组合进行分类,预测各实体之间的关系。