复现问题记录 | StackGAN-v2 (in python3)(一)
复现问题记录
-
- 1.py2与py3中easydict版本兼容问题
- 2.py2和py3中xrange( )函数版本兼容性问题
- 3.pickle.load()函数中字符编码问题
- 4. 'str' object has no attribute 'decode'
- 5.torch版本兼容问题
复现这篇论文时最开始按github指示在py2环境运行,但是明明是用服务器gpu却无法识别gpu(cuda._available为false),相关解决方案都让用cpu跑(这怎么可能),找了很多教程全部失败。
最后换了一种思路怀疑是因为cuda、torch、python三者版本不匹配,并且找到了适合服务器cuda、python版本的torch1.4。但是这次torch包安装失败,用了各种镜像,开了也没成功,实在是太搞心态了,可能这个版本比较老,于是放弃转战python3。
本文记录python3环境下运行StackGAN-v2遇到的报错处理。
复现问题记录 | StackGAN-v2 (in python3)(二)
复现问题记录 | StackGAN-v2 (in python3)(三)
1.py2与py3中easydict版本兼容问题
报错信息:
/mnt/data3/yc/StackGAN-v2/code/miscc/config.py:103: YAMLLoadWarning: calling yaml.load() without Loader=... is deprecated, as the default Loader is unsafe. Please read https://msg.pyyaml.org/load for full details.
yaml_cfg = edict(yaml.load(f))
Traceback (most recent call last):
File "main.py", line 75, in
cfg_from_file(args.cfg_file)
File "/mnt/data3/yc/StackGAN-v2/code/miscc/config.py", line 105, in cfg_from_file
_merge_a_into_b(yaml_cfg, __C)
File "/mnt/data3/yc/StackGAN-v2/code/miscc/config.py", line 73, in _merge_a_into_b
for k, v in a.iteritems():
AttributeError: 'EasyDict' object has no attribute 'iteritems'
/mnt/data3/yc/StackGAN-v2/code/miscc/config.py:104: YAMLLoadWarning: calling yaml.load() without Loader=... is deprecated, as the default Loader is unsafe. Please read https://msg.pyyaml.org/load for full details.
yaml_cfg = edict(yaml.load(f))
Traceback (most recent call last):
File "main.py", line 75, in
cfg_from_file(args.cfg_file)
File "/mnt/data3/yc/StackGAN-v2/code/miscc/config.py", line 106, in cfg_from_file
_merge_a_into_b(yaml_cfg, __C)
File "/mnt/data3/yc/StackGAN-v2/code/miscc/config.py", line 76, in _merge_a_into_b
if not b.has_key(k):
AttributeError: 'EasyDict' object has no attribute 'has_key'
问题:py2和py3兼容性的问题
#在py2中,遍历的写法:
d={'name':'abc','location':'BeiJing'}
for i in d.iteritems():
print(i)
#在py3中,遍历的写法::
d={'name':'abc','location':'BeiJing'}
for i in d.items():
print(i)
#在py2中,判断key是否属于dict的写法可以是:
d={'name':'abc','location':'BeiJing'}
if d.has_key('location'):
print(d['location'])
#在py3中,判断key是否属于字典的写法可以是:
d={'name':'abc','location':'BeiJing'}
if 'location' in d:
print(d['location'])
2.py2和py3中xrange( )函数版本兼容性问题
报错信息:
Traceback (most recent call last):
File "main.py", line 128, in
transform=image_transform)
File "/mnt/data3/yc/StackGAN-v2/code/datasets.py", line 200, in __init__
self.bbox = self.load_bbox()
File "/mnt/data3/yc/StackGAN-v2/code/datasets.py", line 230, in load_bbox
for i in xrange(0, numImgs):
NameError: name 'xrange' is not defined
问题:py2和py3兼容性的问题
xrange适用于python2.7版,在3版中range与xrange已经合并为range了。
解决办法:将xrange( )函数全部换为range( )即可。
在Python 2.x中,经常会用xrange()创建一个可迭代对象,通常出现在“for循环”或“列表/集合/字典推导式”中。这种行为与生成器非常相似(如”惰性求值“),但这里的xrange-iterable无尽的,意味着可能在这个xrange上无限迭代。由于xrange的“惰性求知“特性,如果只需迭代一次(如for循环中)range()通常比xrange()快一些。不过不建议在多次迭代中使用range(),因为range()每次都会在内存中重新生成一个列表。
在Python 3中,range()的实现方式与xrange()函数相同,所以就不存在专用的xrange()(在Python 3中使用xrange()会触发NameError)。
参考:https://blog.csdn.net/u013346007/article/details/52782410
3.pickle.load()函数中字符编码问题
报错信息:
Traceback (most recent call last):
File "main.py", line 128, in
transform=image_transform)
File "/mnt/data3/yc/StackGAN-v2/code/datasets.py", line 206, in __init__
self.embeddings = self.load_embedding(split_dir, embedding_type)
File "/mnt/data3/yc/StackGAN-v2/code/datasets.py", line 265, in load_embedding
embeddings = pickle.load(f)
UnicodeDecodeError: 'ascii' codec can't decode byte 0xbe in position 3: ordinal not in range(128)
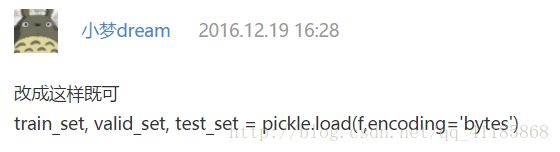
在代码中将embeddings = pickle.load(f)改为embeddings = pickle.load(f, encoding='bytes')
参考:https://blog.csdn.net/qq_41185868/article/details/79039604
4. ‘str’ object has no attribute ‘decode’
报错信息:
Traceback (most recent call last):
File "main.py", line 128, in
transform=image_transform)
File "/mnt/data3/yc/StackGAN-v2/code/datasets.py", line 208, in __init__
self.captions = self.load_all_captions()
File "/mnt/data3/yc/StackGAN-v2/code/datasets.py", line 252, in load_all_captions
captions = load_captions(caption_name)
File "/mnt/data3/yc/StackGAN-v2/code/datasets.py", line 244, in load_captions
captions = f.read().decode('utf8').split('\n')
AttributeError: 'str' object has no attribute 'decode'
python 3中只有unicode str,所以把decode方法去掉了,但是还有encode方法,所以搜出来很多解决方案是说把decode()改为encode(),但我总感觉不靠谱,搜了一下两个函数干的也不是一件事。
两个函数功能大概意思如下(表述不是很严谨):
encode()方法把字符编码为xx乱码,decode()方法把xx乱码编码为字符编码。
Encoded String: dGhpcyBpcyBzdHJpbmcgZXhhbXBsZS4uLi53b3chISE=
Decoded String: this is string example....wow!!!
继续努力搜索下终于弄懂了这个问题的本质,python3环境中,f.read()已经是unicode str了,不用decode。如果文件内容不是unicode编码的,要先以二进制方式打开,读入比特流,再解码,即读取f的时候open(cap_path, "rb")。
修改:
def load_all_captions(self):
def load_captions(caption_name): # self,
cap_path = caption_name
#with open(cap_path, "r") as f:
with open(cap_path, "rb") as f:
captions = f.read().decode('utf8').split('\n')
captions = [cap.replace("\ufffd\ufffd", " ")
for cap in captions if len(cap) > 0]
return captions
参考:https://blog.csdn.net/qq_34343669/article/details/81874065
5.torch版本兼容问题
报错信息:
Traceback (most recent call last):
File "main.py", line 144, in
algo.train()
File "/mnt/data3/yc/StackGAN-v2/code/trainer.py", line 724, in train
errD = self.train_Dnet(i, count)
File "/mnt/data3/yc/StackGAN-v2/code/trainer.py", line 610, in train_Dnet
summary_D = summary.scalar('D_loss%d' % idx, errD.data[0])
IndexError: invalid index of a 0-dim tensor. Use tensor.item() to convert a 0-dim tensor to a Python number
pytorch1.4.0版本更新问题,在0.4-0.5版本的pytorch会出现警告,不会报错,但是0.5版本以上的pytorch就会报错。
修改:errD.data[0]改为 errD.item()
#summary_D = summary.scalar('D_loss%d' % idx, errD.data[0])
summary_D = summary.scalar('D_loss%d' % idx, errD.item())
参考:https://blog.csdn.net/chen645096127/article/details/94019443