PURE(A Frustratingly Easy Approach for Entity and Relation Extraction)
写作动机(Movitation):
假设驱动:作者认为现有的表征仅仅只学习到了实体和上下文之间的联系,并没有学习到实体对之间的依赖关系。
相关工作(Related Work):
联合学习的子任务:
1.结构化预测问题(将实体抽取和关系抽取两个任务映射到一个联合框架):
a. 基于动作(action-based)的系统,将新发现的实体链接到之前发现的实体。Incremental Joint Extraction of Entity Mentions and Relations https://aclanthology.org/P14-1038.pdf
https://aclanthology.org/P14-1038.pdf
b. 填表方法(table-filling)
填表方法提出:
Modeling Joint Entity and Relation Extraction with Table Representationhttps://aclanthology.org/D14-1200.pdfEnd-to-End Neural Relation Extraction with Global Optimizationhttps://aclanthology.org/D17-1182.pdf
Two are Better than One: Joint Entity and Relation Extraction with Table-Sequence Encodershttps://aclanthology.org/2020.emnlp-main.133.pdf
c. 基于序列标注(sequence tagging-based)的方法
Going out on a limb: Joint Extraction of Entity Mentions and Relations without Dependency Treeshttps://aclanthology.org/P17-1085.pdfJoint Extraction of Entities and Relations Based on a Novel Tagging Schemehttps://aclanthology.org/P17-1113.pdf
d. 基于图(graph-based)的方法
Joint Type Inference on Entities and Relations via Graph Convolutional Networkshttps://aclanthology.org/P19-1131/
GraphRel: Modeling Text as Relational Graphs for Joint Entity and Relation Extractionhttps://aclanthology.org/P19-1136.pdf
e. 多轮问答问题(multi-tune qa)
GraphRel: Modeling Text as Relational Graphs for Joint Entity and Relation Extractionhttps://aclanthology.org/P19-1136.pdf
2.多任务学习问题:
a. 序列标注用于实体预测,基于树的LSTM模型用于关系抽取
End-to-End Relation Extraction using LSTMs on Sequences and Tree Structureshttps://aclanthology.org/P16-1105.pdf
b. 将多标签头选择问题转换为模型关系分类
Adversarial training for multi-context joint entity and relation extractionhttps://aclanthology.org/D18-1307v2.pdf
提出的方法(Methods):
使用两个编码器,一个编码器为实体模型,用于产生给定的span表示来预测实体和实体类型。另一个编码器为关系模型,根据实体模型产生的输出对关系模型的输入进行typed marker(具体来说是给实体加上了实体类型和主客体类型),之后送入关系模型产生实体对之间的表征,再送入前馈神经网络进行分类。此外为了是句子的输入信息更加丰富,在输入端还增加了上下文的词汇。
使用的技术(Techniques):
模型:使用bert-based-uncased和albert-xxlarge-v1作为两个基础编码器用于对结果进行比较。
损失函数:交叉熵
遇到的困难(Difficulties):
由于需要对每个实体对进行分类,为了加快运行的速度,提出了有效的batch 计算方法。主要是对标记使用和实体相同的位置嵌入和注意力层中的文本token不与标记token进行注意力的计算,这两个措施可以使我们重用文本token的计算,因为文本token的表示和标记token的表示分离开来了。在实践中,我们将所有实体对对标记插入到句子末尾组成输入,这加快了速度且仅仅导致了很少的性能损失。

实验结果(Results):
语料:
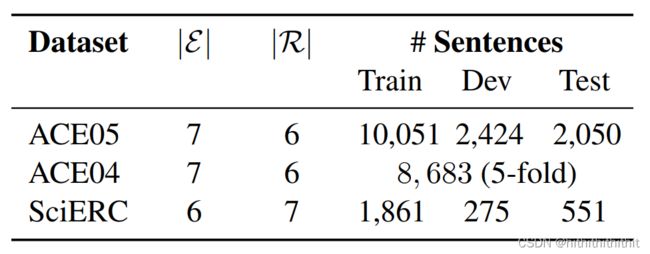
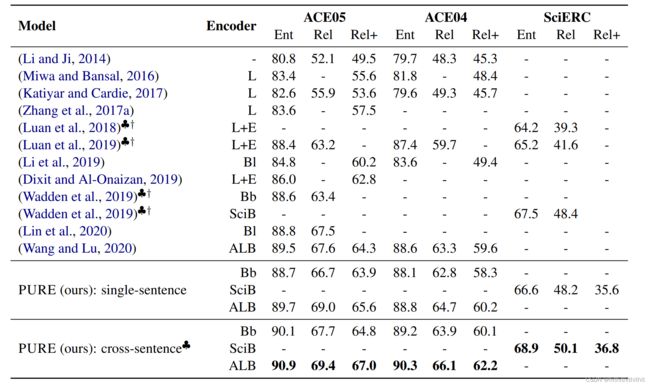
实验结果(使用cross-sentece机制模型性能得到了显著的提升):
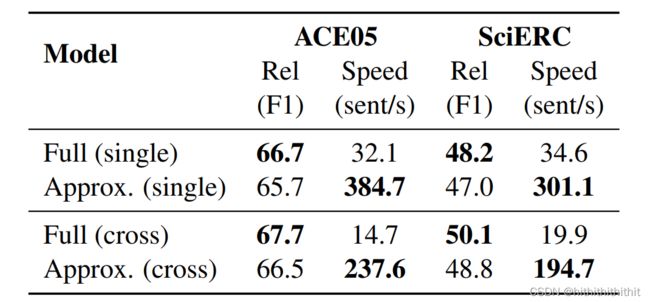
加速实验结果(处理速度得到了显著的提升):
做出的贡献(Contributions):
1. 使用了pipeline的方法,训练了两个独立的编码器,性能很好;
2. 我们对实验因素影响实验性能进行了分析,并且得出结果学习不同的(实体和关系)上下文表示比联合学习更好;
3.提出了加速的方法,大大加快了模型处理数据的速度,性能略微有所下降。
未来展望(Future Work):
Jointly真的比Pipeline好吗?