文档级关系抽取:A Densely Connected Criss-Cross Attention Network for Document-level Relation Extraction
提示:文档级关系抽取相关论文
A Densely Connected Criss-Cross Attention Network for Document-level Relation Extraction
- 摘要
- 一、引言
- 二、方法
-
- 2.1 编码器模块
- 2.2 密集CCNet模块
- 2.3 分类器模块
- 三、实验
-
- 3.1 数据集& 3.2实验配置
- 3.3 在DocRED上实验结果
- 3.4 在生物数据集上实验结果
- 3.5 消融实验
- 四、相关工作
- 五、结论和未来工作
- 总结
—xxgcdx
摘要
目的:提出密集连接纵横交错注意力网络(Dense-CCNet),可在实体对级完成逻辑推理。
具体来说,密集CCNet通过交叉注意(CCA)执行实体对级逻辑推理,它可以在实体对矩阵上收集水平和垂直方向的上下文信息,以增强相应的实体对表示。此外,我们密集地连接多层CCA以同时捕捉单跳和多跳逻辑推理的特征。
提示:以下仅为个人对于论文理解,也希望各位朋友一起交流学习
一、引言
与句子级RE相比,文档级RE的主要挑战是许多关系只能通过推理技术来提取。因为这些关系事实没有在文档中明确表达,所以模型必须捕获关系之间的相关性来推断这些关系。
在本文中,我们利用实体对之间的信息传递来更有效、更直接地捕捉关系之间的相关性,我们推测,具有重叠实体的三元组之间的交互是一种合理的实体对级推理方式。将CCA应用于实体对矩阵,可以实现具有重叠实体的实体对之间的交互,从而完成实体对级的逻辑推理。DenseCCNet的下层可以捕获实体对间的局部依赖关系,完成单跳逻辑推理;上层可以捕获实体对间的全局依赖关系,完成多跳逻辑推理。
为了减少不相关实体对的影响,我们使用了两种技术:(1)聚类损失:聚类损失将表示空间中的相关实体对(即两个实体之间存在关系)与不相关实体对分开。(2)注意偏差:在CCA注意得分的偏差项中加入一个偏差项,使CCA更加关注相关的实体对。
主要贡献:(1)我们引入了Dense-CCNet模块,它可以通过实体对级推理更直接、更有效地模拟关系之间的相关性;(2)我们引入了四种方法来进一步提高CCA的推理能力:密集连接、扩大注意领域、聚类损失和注意偏差;(3)在三个公开文档级RE数据集上的实验结果表明,我们的Dense-CCNet模型可以实现最先进的性能。
二、方法
我们的整个模型(如图2所示)主要由三部分组成:编码器模块(第2.1节)、密集CCNet模块(第2.2节)和分类器模块(第2.3节)。
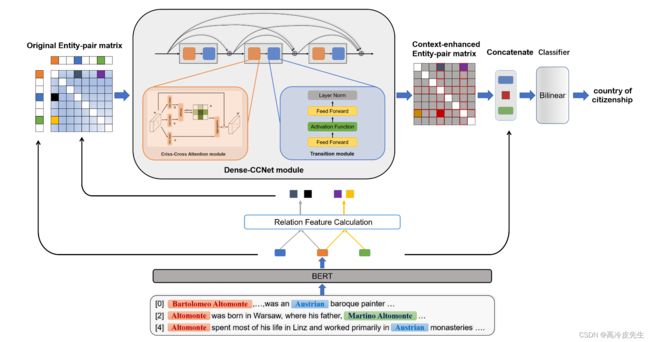
图2:我们基于密集CCNet的文档级RE模型的整体架构。首先,BERT模型对输入文档进行编码,以获得每个单词的上下文嵌入,然后通过池化操作获得实体(hes,heo)的表示。其次,通过关系特征计算模块计算所有实体对的关系特征(Ms,o/Mo,s),用于构造原始实体对矩阵(M)。第三,密集CCNet模块将M转换成上下文增强的实体对矩阵(M′)。最后,实体对(es,eo)的上下文增强关系特征(M’s,o)、主体实体嵌入(hes)和对象实体嵌入(heo)被连接并输入到分类器以预测关系。
2.1 编码器模块
我们首先将文档D视为一个单词序列,即D={wi}iL,其中L是文档中的单词总数。然后,我们插入特殊符号和<\Ei>来分别标记提及的开始和结束位置,其中Ei是提及的实体id。通过引入实体id信息来帮助对齐来自同一实体的不同提及的信息。最后,我们利用预训练的语言模型bert作为编码器,将文档D转换成上下文嵌入序列,如下所示。
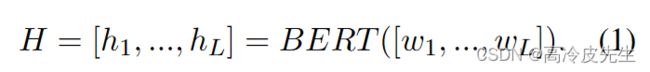
我们将嵌入在提及mj的开头作为提及嵌入hmj。然后,我们利用最大池化的光滑版本logsumexp池获得包含pi的实体ei的嵌入hei。
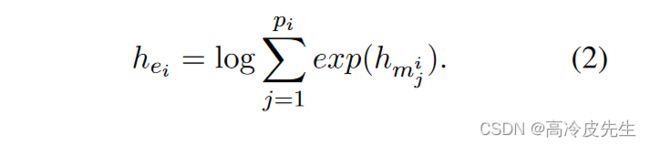
在获得文档中所有实体的嵌入后,我们通过关系特征计算模块构造一个实体对矩阵,其中Ne是指实体的数量,d是关系特征向量的维数。M中的Ms,o项表示实体es和实体eo之间的关系特征向量,其中hes是主题实体嵌入,heo是对象实体嵌入,hdoc是文档嵌入,并且cs,o是实体对感知上下文特征,FFN()指前馈神经网络,Wo,Ws是可学习权重矩阵其计算如下:

实体对感知上下文特征cs,o表示实体es和实体eo一起关注的文档中的上下文信息。其中As,i是关注文档中第i个令牌hi的实体es的注意分数。cs,o的公式如下:
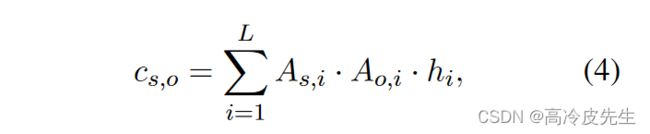
2.2 密集CCNet模块
密集CCNet模块由密集连接的N个相同层组成,这些层由两个子模块组成:交叉注意力(CCA)模块和过渡模块。
实体对矩阵中的每个实体对可以通过CCA模块关注水平和垂直方向上其他实体对的关系特征。其中A(s,o)→(s,i)是Ms,o关注Ms,i的注意力得分。CCA模块可以制定如下:
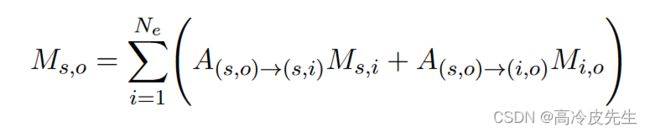
CCA模块可以在实体对矩阵上完成实体对级的一跳推理,并且可以通过堆叠CCA模块的多层来完成多跳推理。
使用递归交叉注意(RCCA)来完成实体对级的逻辑推理可能会有几个问题:
(1)只关注高级多跳推理特征,而忽略了对于文档级RE也非常重要的低级单跳推理特征;
(2)CCA模块只能对A→∑→B的推理模式进行建模,而不能对A→∑←B、A←∑←B、A←∑→B的推理模式进行建模;
(3)由于文档中的大多数实体对是不相关的,实体对矩阵M中含有大量的噪声,可能会影响模型的推理能力;
因此,区分相关实体对和不相关实体对,加强相关实体对的关系特征向量之间的交互作用,是提高模型推理能力的关键。为了解决这些问题,我们介绍了以下方法。
解决方法:
(1)密集连接:由于密集连接可以重用底层网络的特性,我们通过密集连接的框架堆叠多层CCA模块来解决问题(1)。此外,密集连接也可以在一定程度上减少噪声传播;
(2)扩展关注领域:为了允许CCA模块模拟更多的推理模式,我们修改CCA模块如下,修改后的CCA模块可以覆盖更广泛的推理模式,包括:a→→B、a→←B、a←←B和a←→B。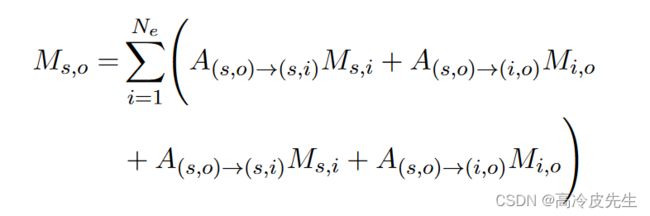
(3)聚类损失:我们设计了一个聚类损失函数,将特征空间中的相关实体对和不相关实体对分开,以减少不相关实体对对推理过程的影响。其中Nneg是不相关实体对的集合,Npos是相关实体对的集合,v0是Nneg中实体对的特征向量的平均向量,v1是Npos中实体对的特征向量的平均向量,fi是第i个实体对的特征向量,聚类损失的公式如下:
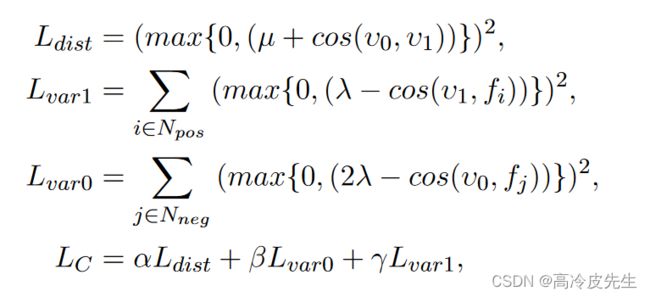
(4)注意偏差:为了使CCA更加关注相关的实体对,我们在CCA的注意得分中增加了一个偏差,偏差bias,可通过前馈神经网络进行预测和训练。
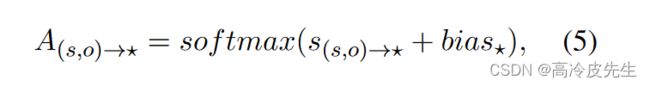
2.3 分类器模块
我们使用密集CCNet将原始的实体对矩阵M转换成新的上下文增强的实体对矩阵M’。给定一个实体对(es,eo),我们首先将两个实体嵌入(hes,heo)和新的关系特征M’so连接起来,然后通过一个双线性函数得到关系的分布。如下所示:

对于损失函数,我们使用自适应阈值损失,它为每个实体对学习自适应阈值。损失函数分为两部分,其中T H是一个引入的类,用于分离正类和负类:正类的概率高于T H,负类的概率低于T H,PD和ND分别是文档D中的正类集和负类集。公式如下所示:

我们的总损失函数定义如下:
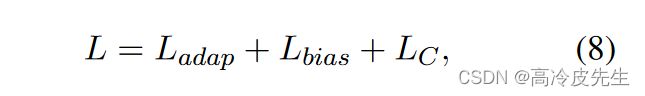
三、实验
3.1 数据集& 3.2实验配置
数据集:使用DocRED,CDR,GDA三个数据集,这里对此不再赘述。
实验配置:模型是基于PyTorch实现的,将密集CCNet的层数设置为3层。
3.3 在DocRED上实验结果
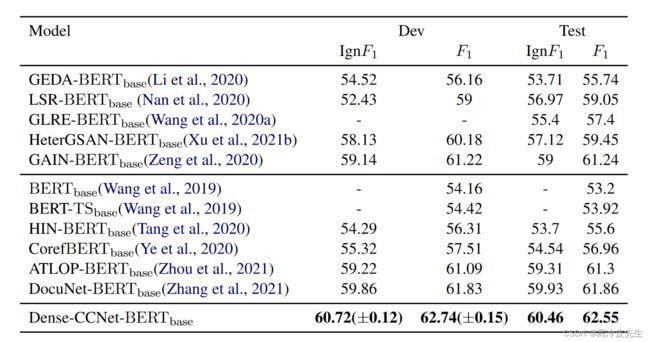
如表1所示,我们的Dense-CCNet模型在训练集和测试集中实现了62.74%的F1和62.55%的F1,分别优于0.91%的F1和0.69%的F1的最先进模型。与基于图的方法的最新模型增益模型相比,我们的模型在开发集上超过1.52%的F1,在测试集上超过1.31%的F1。这证明了实体对层次上的逻辑推理比以往提及或实体层次上的方法更有效。
3.4 在生物数据集上实验结果
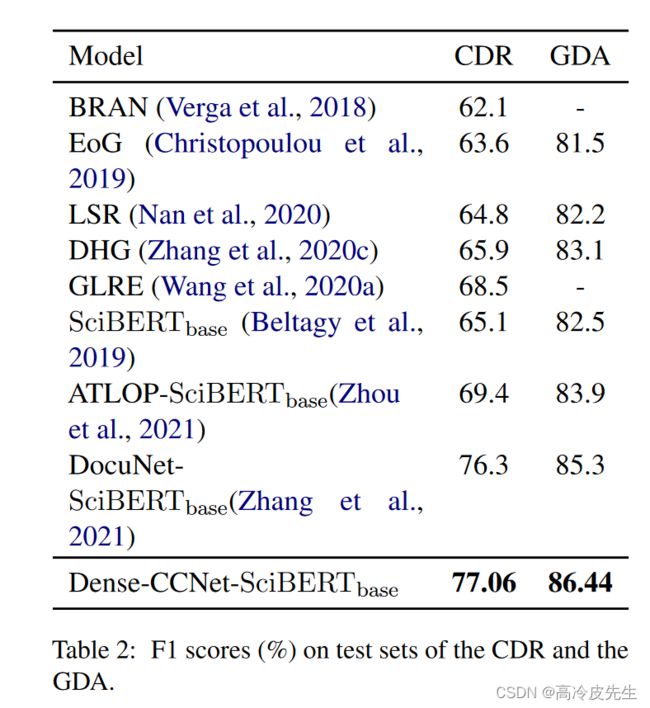
Dense-CCNet-SciBERTbase模型在CDR和GDA两个数据集上分别获得了77.06(0.71)%的F1和86.44(0.25)%的F1,这也是新的最先进的结果。与DocuNet-SciBERTbase相比,Dense-CCNetSciBERTbase在CDR和GDA上分别提高了0.76%和1.14%的F1评分。这些结果证明了我们的方法在生物医学领域具有很强的适用性和通用性。
3.5 消融实验
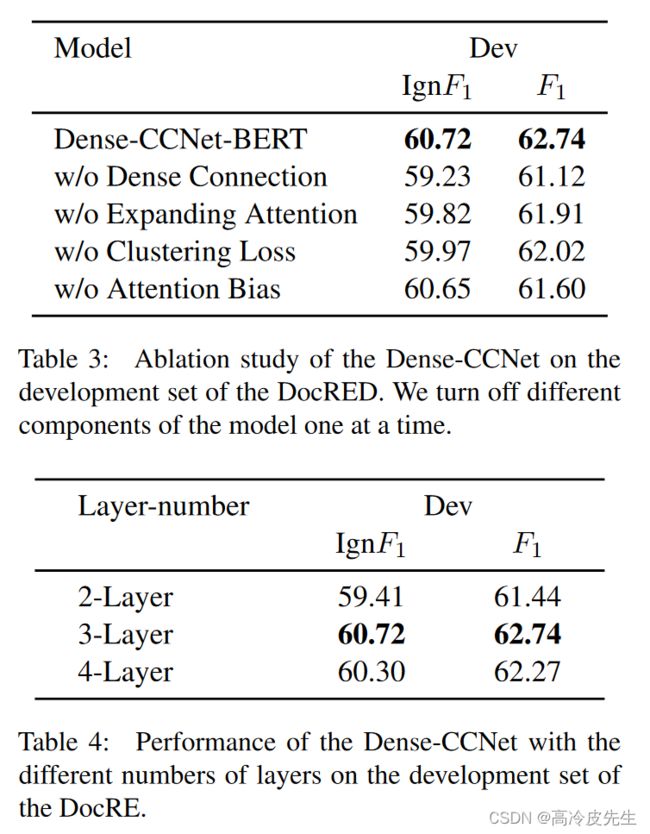
从表3中,我们可以观察到w/o密度导致f1下降1.62%,这表明低级推理的特征对关系提取非常有帮助,高级推理的特征可能包含噪声。w/o扩展注意导致性能下降0.83%f1,这表明文档级RE可能包含多种推理模式,我们的模型可以通过扩展注意技术的领域来有效地扩展交叉注意的推理模式。
当层数从2层增加到3层时,我们的模型可以捕捉更多的多跳推理特征,因此模型的性能提高了1.3%。然而,当层数增加到4时,性能略有下降0.37%f1点。可能的原因是噪声对高级特征有更大的影响,或者模型陷入过度拟合。
四、相关工作

密集CCNet模式和基线模型的案例研究。©表明我们的模型比基线具有更好的逻辑推理能力。(a)可视化实体对注意其他实体对的注意分数,表明我们的模型可以有效地捕捉实体对之间的相关性。
大量案例发现,没有一个模型通过实体对之间的信息传播来完成文档级RE的逻辑推理。我们的密集网络模型可以捕捉实体对之间的相关性,并通过将CCA集成到密集连接框架中来完成实体对级推理。
五、结论和未来工作
纵横交错的注意力进入密集连接的框架。密集CCNet模型可以完成实体对级的逻辑推理,并对实体对之间的相关性进行建模。将来,我们将尝试将我们的模型用于其他句子间或文档级任务,例如跨句子集体事件检测等。
总结
相对于上篇论文,这次对于整个论文所采用的模型结构有一个更加深入的认识,能根据目前所学知识对相应的模型结构和流程分析有一个初步的把握。看论文的路途还是很遥远,一起努力吧!