知识图谱学习初步总结
一、遇到问题汇总
问题1:
import torch爆出错误:ModuleNotFoundError: No module named ‘torch’
这是在已经加载到pytorch环境中发生的错误,环境下配置都正常。
解决方案:打开高级系统设置,将anaconda安装盘增加虚拟空间编辑

我的是c盘,就在c盘增加虚拟空间
问题2:
导入neo4j时无法导入成功,报错信息为:
neo4j.exceptions.ClientError: {code: Neo.ClientError.Statement.ExternalResourceFailed} {message: Couldn't load the external resource at: file:/F:/ENVIROMENT/neo4j-community-4.4.8/import/out_movies.csv ()}
解决方案:将所要导入的数据集复制到neo4j安装目录下的import问价夹才可以
编辑
问题3:
导入json文件格式有问题,不是正常字典模式,可以是由于某一步误按了键盘上的一个键
解决方案:将数据集复制到:JSON Online Validator and Formatter - JSON Lint,标黑的地方就是数据格式存在问题的地方
问题4:
如何爬取网站长时间而不被检测,不用设置延时函数,使用faker库用伪UA进行提取
from faker import Faker
headers = {'User-Agent': "fake.user_agent()"}
response = requests.get(url, headers=headers).text
这种方式既可以保证爬取的高效性,也可以不被服务器所检测出来,而且使用起来更为简单
二、BERT框架学习
BERT任务目标概述
1、需要熟悉word2vec,RNN网络模型,了解词向量如何建模
2、重点在于Transformer网络架构,BERT训练方法,实际应用
3、BERT开源项目都是现成的,直接套用
4、提供预训练模型,基本任务都能拿来用。
传统解决方案遇到的问题
1、基本组成依旧是机器翻译模型中常见的Seq2Seq网络
2、Transformer输入输出比较直观
3、传统的RNN网络模型 编辑缺点:每一个下一步都会用到前一步中间的状态,不能并行运算
编辑缺点:每一个下一步都会用到前一步中间的状态,不能并行运算
4、Transformer可以解决并行问题 、注意力问题
 编辑
编辑
5、传统的word2vec
预训练好的向量永远不变了,那不同语境相同的词如何表达。例如:干哈呐表示在干嘛或者是叫你出去干点啥
BERT框架使得同一个词在不同语境下的意思不同
6、整体框架
如和编码
输出结果是什么
Attention的目的
怎样组合在一起

编辑
注意力机制问题(Self-Attention)
对于输入的数据,关注点是什么
(不仅仅可以用于文本提取,还可以用于视觉,不过大部分用于NLP)
如何才让计算机关注有价值的信息
根据数据来判断什么比较重要,不同的语句语境有不同的重要行程度
 编辑
编辑
你需要知道这个it指代什么,将当前语境融入到词向量当中

 编辑
编辑
计算方法
每一个词对于上下文每一个词的权重
编辑
 编辑
编辑
特征分配与softmax机制
得到的内积作为分值然后换算成比例形成权重百分值,其实就是归一化
三、循环神经网络的复习以及对过去知识的补充
循环神经网络简介
大致结构如下:

编辑
t时刻的状态与t-1时刻状态和其当前输入状态有关,其公式如右![]() 编辑
编辑
在这个公式中fw和xt与上一个状态也就是ht-1无关,那么fw函数是一个什么样的函数?如下:

编辑
由这个公式可以看出包含一个矩阵Whh*ht-1+Wxh*xt这两个矩阵相乘的结果,最外面就是tanh,以这个非线性函数使状态结果坐落于一个合理的区间范围内,最终的状态结果只能是0-1中间的某个数字,然后这个状态经过矩阵乘法运算得到最终结果。注意:这一步实际上输出了两个结果,一个是状态一个是最终结果,其中状态还要带入下一步的RNN求出t+1时刻的状态。(tanh是激活函数:关于什么是激活函数:什么是激活函数&该选哪种激活函数?_哔哩哔哩_bilibili)

编辑
可应用与连续语音识别以及翻译

编辑
可应用于动作识别,行为识别,单词量有限的语音识别

编辑
应用于图片文字识别等等
图像注释:
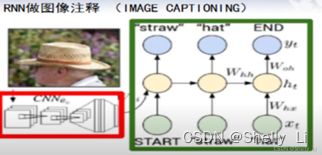
编辑
先由一个任意量START开始,加入CNN所形成的其中一个特征,进行第一步的操作,得到结果为Straw稻草,然后straw稻草加入第二步RNN以及当前CNN输入特征得到帽子,不断循环下去,最终读取到END结束RNN,将图像标上注释。
RNN的训练
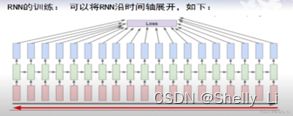
编辑
每一个时刻的y-y帽总和给一个loss,逐级求导
还有一种多层的RNN结构,但是一般不超过三层,超过三层收敛将变得困难:
四、文本向量化
import jieba
file = open("E:\桌面\边城.txt","r",encoding="utf-8",errors='ignore').read()
words = jieba.lcut(file)#读取文件
stopwords = open("E:\桌面\呆萌的停用词表.txt","r",encoding="utf-8").read()
c = stopwords.split("\n")
filtered_sentence = [w for w in words if not w in c]#从文本中剔除停用词
print(filtered_sentence)
以边城举例,网上有很多资源要找到合适的停用词
第一次会后补充:有些情况下尽量不使用停用词,那么用什么算法来省去不重要的词语呢
TF-IDF算法可以使用
1、TF-IDF算法介绍
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
(1)TF是词频(Term Frequency)
词频(TF)表示词条(关键字)在文本中出现的频率。
这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。
公式:  即:
即:

其中 ni,j 是该词在文件 dj 中出现的次数,分母则是文件 dj 中所有词汇出现的次数总和;
(2)IDF是逆向文件频率(Inverse Document Frequency)
逆向文件频率 (IDF) :某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。
如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。
公式: 
其中,|D| 是语料库中的文件总数。 |{j:ti∈dj}| 表示包含词语 ti 的文件数目(即 ni,j≠0 的文件数目)。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用 1+|{j:ti∈dj}|
即: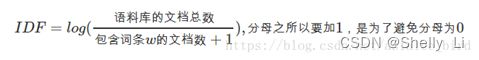
(3)TF-IDF实际上是:TF * IDF
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
公式: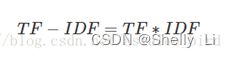
注: TF-IDF算法非常容易理解,并且很容易实现,但是其简单结构并没有考虑词语的语义信息,无法处理一词多义与一义多词的情况。
应用参见这篇博客:TF-IDF算法介绍及实现_Asia-Lee的博客-CSDN博客_tf-idf
五、会议要点简记
Torchvison:处理数据集非常方便,可以直接下载
博客需要记得清晰,也需要多分享博客
Jupyter对于编程的可视化非常好
代码也要讲细节