Machine Learning with Python Cookbook 学习笔记 第3章
Machine Learning with Python Cookbook 学习笔记 第3章
前言
-
本笔记是针对人工智能典型算法的课程中Machine Learning with Python Cookbook的学习笔记
-
学习的实战代码都放在代码压缩包中
-
实战代码的运行环境是python3.9 numpy 1.23.1
-
上一章:(88条消息) Machine Learning with Python Cookbook 学习笔记 第2章_五舍橘橘的博客-CSDN博客
Chapter 3 Data Wrangling(数据整理)
3.0 Introduction
-
Data wrangling is a broad term used, often informally, to describe the process of transforming raw data to a clean and organized format ready for use.
(数据整理(data wrangling)指将数据转换为可供使用的干净且有组织的格式组织)
-
The most common data structure used to “wrangle” data is the data frame, which can be both intuitive and incredibly versatile. Data frames are tabular, meaning that htey are based on rows and columns like you’d find in a spreadsheet
(用于“整理”数据的最常见数据结构是data frame,它既直观又非常通用。
对于书中的例子:
# Load library
import pandas as pd
# Create URL
url = 'https://tinyurl.com/titanic-csv'
# Load data as a dataframe
dataframe = pd.read_csv(url)
# Show first 5 rows
dataframe.head(5)
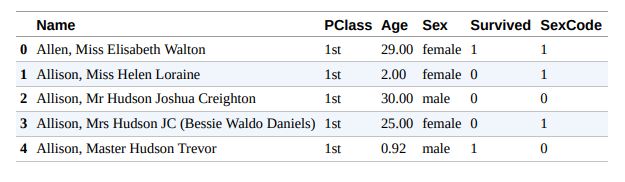
需要注意3点:
- 首先,在data frame中,每一行对应一个观察值(例如,一名乘客),每一列对应一个特征(性别、年龄等)。例如,通过查看第一个observation,我们可以看到 Elisabeth Walton Allen 小姐留在头等舱,29 岁,是女性,并且在灾难中幸存下来。
- 其次,每列包含一个名称(例如,姓名、PClass、年龄),每行包含一个索引号(例如,幸运的伊丽莎白沃尔顿艾伦小姐为 0)。 我们将使用这些来选择和操作观察和特征。
- 第三,Sex 和 SexCode 两列包含不同格式的相同信息。在 Sex 中,女性用字符串 female 表示,而在 SexCode 中,女性用整数 1 表示。我们希望所有特征都是唯一的,因此我们需要删除其中一列。 在本章中,我们将介绍使用 pandas 库操作数据帧的各种技术,目的是创建一个干净、结构良好的观察集以供进一步预处理。
3.1 Creating a Data Frame
Problem
You want to create a new data frame.
Solution
pandas has many methods of creating a new DataFrame object. One easy method is to create an empty data frame using DataFrame and then define each column separately:
pandas拥有许多methods来创建新的DataFrame
emptyDataFrameExample.py
import pandas as pd
# Create DataFrame
dataframe = pd.DataFrame()
# 用字典的方式添加新的一行
dataframe['Name'] = ['Jacky Jackson', 'Steven Stevenson']
dataframe['Age'] = [38, 25]
dataframe['Driver'] = [True, False]
# 展示dataframe
print(dataframe)
# 创建新的一行
new_person = pd.Series(['Molly Mooney', 40, True], index=['Name', 'Age', 'Driver'])
# 拼接一行
dataframe = dataframe.append(new_person,ignore_index=True)
print(dataframe)

值得注意的是未来append属性要被废除,所以最好还是创建小的dataframe然后用concat拼接到总的Dataframe中
Discussion
- pandas库提供无数种创建DataFrame的方法
- 现实中常常采用从其他来源产生一个DataFrame而不是创建一个新的DataFrame然后填充
3.2 Describing the Data
查看DataFrame的相关信息
DescribeExample.py
import pandas as pd
# 因为无法访问国外的csv文件,使用国内的网站代替
url = 'https://www.gairuo.com/file/data/dataset/GDP-China.csv'
df = pd.read_csv(url)
# show first two rows
print(df.head(2)) # also try tail(2) for last two rows
# show dimensions
print("Dimensions: {}".format(df.shape))
# show statistics
print(df.describe())

Discussion
- 由于数据量过大,为了能够更好的访问数据,需要了解数据类型和结构,这就需要获取小的切片和获取统计信息
- 一些数字列往往代表类别或者其他枚举类信息,这样的信息的统计信息往往没有意义,例如性别由0和1表示,而他的方差往往没有统计意义
3.3 Navigating DataFrames
需要选取单个数据或者数据切片
navigateExample.py
# Load library
import pandas as pd
# Create URL
url = 'titanic.csv'
# Load data
dataframe = pd.read_csv(url)
# Select first row
print(dataframe.iloc[0])
print()
# Select three rows
print(dataframe.iloc[1:4])
# Set index
dataframe = dataframe.set_index(dataframe['Lname'])
print(dataframe.loc['Braund'])
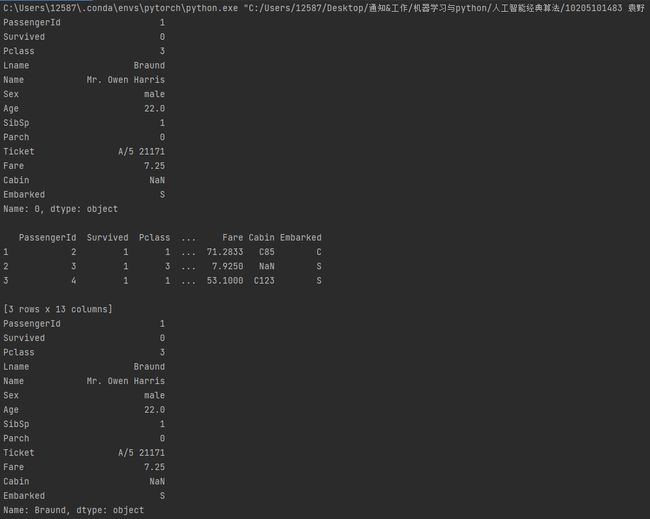
Discussion
- pandas创建的dataframe都含有索引,默认是一个整数
- DataFrame可以设置唯一的字母数字字符串作为索引
- loc可以根据自定义的标签来返回对应的元素
- iloc通过位置来返回对应的一行
- loc和iloc是非常有用的数据清理函数
3.4 Selecting Rows Based on Conditionals
查找某些行元素
selectExample.py
# 引入库
import pandas as pd
url = 'titanic.csv'
dataframe = pd.read_csv(url)
# 单条件查询
print(dataframe[dataframe['Sex'] == 'female'].head(2))
# 多条件查询
print(dataframe[(dataframe['Sex'] == 'female') & (dataframe['Age'] >= 50)])
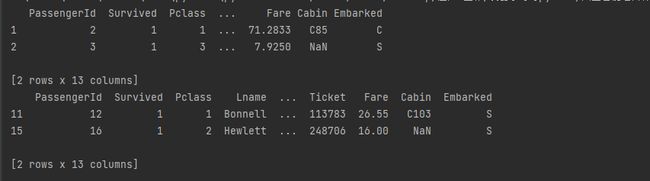
Discussion
- 有效使用条件筛选和过滤是数据清理的重要任务之一
3.5 Replacing Values
目标:替换指定列的值
replaceExample.py
import pandas as pd
url = 'titanic.csv'
dataframe = pd.read_csv(url)
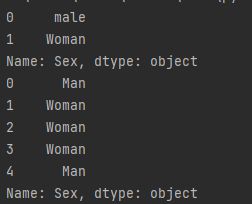
# 替换female 为male
print(dataframe['Sex'].replace("female", "Woman").head(2))
# 替换 "female" and "male 为 "Woman" and "Man"
print(dataframe['Sex'].replace(["female", "male"], ["Woman", "Man"]).head(5))
3.6 Renaming Columns
重命名属性
renameExample.py
import pandas as pd
url = 'titanic.csv'
dataframe = pd.read_csv(url)
# 替换一列
print(dataframe.rename(columns={'Pclass': 'Passenger Class'}).head(2))
# 同时替换两列
print(dataframe.rename(columns={'Pclass': 'Passenger Class','Lname': 'Last Name'}).head(2))
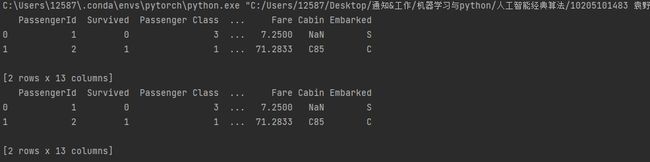
Discussion
-
通过字典来重命名是首选方法
-
可以通过集合来一次性设置所有列,例:
# Load library import collections # Create dictionary column_names = collections.defaultdict(str) # Create keys for name in dataframe.columns: column_names[name] # Show dictionary column_names defaultdict(str, {'Age': '', 'Name': '', 'PClass': '', 'Sex': '', 'SexCode': '', 'Survived': ''})
3.7 Finding the Min, Max, Sum, Average, and Count
查找最大最小、和、平均值和出现次数
statisticExample.py
import pandas as pd
url = 'titanic.csv'
dataframe = pd.read_csv(url)
# 计算统计属性值
print('Maximum:', dataframe['Age'].max())
print('Minimum:', dataframe['Age'].min())
print('Mean:', dataframe['Age'].mean())
print('Sum:', dataframe['Age'].sum())
print('Count:', dataframe['Age'].count())
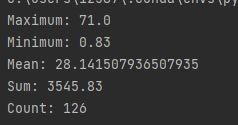
Discussion
-
除了解决方案中使用的统计数据,pandas 还提供方差(var)、标准差(std)、峰度(kurt)、偏度(skew)、均值的标准误差(sem)、众数(mode)、中位数(median ),以及其他一些。
-
可以直接作用于整个DataFrame
import pandas as pd url = 'titanic.csv' dataframe = pd.read_csv(url) # 计算全部属性的次数 print(dataframe.count())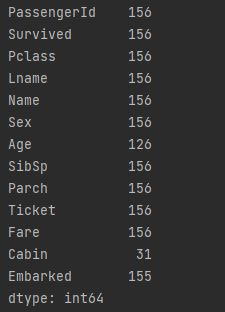
3.8 Finding Unique Values
查重
uniqueExample.py
import pandas as pd
url = 'titanic.csv'
dataframe = pd.read_csv(url)
# 查看所有可能的值,返回一个数组
print(dataframe['Sex'].unique())
# 显示次数
print(dataframe['Sex'].value_counts())
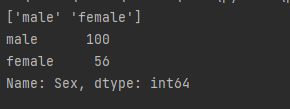
Discussion
- unique 和 value_counts 对于操作和探索分类列都很有用。 很多时候,在分类列中会有需要在数据整理阶段处理的类。
- value_counts会出现问题:当出现某种不合规的“类”时,往往这些类的统计数据是不需要的:(例如该图中的*)
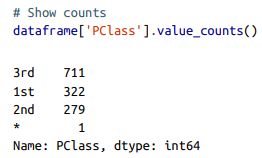
- 可以使用nunique()来查看有多少种不一样的类别
3.9 Handling Missing Values
处理null的值
nullExample.py
import pandas as pd
url = 'titanic.csv'
dataframe = pd.read_csv(url)
## Select missing values, show two rows
print(dataframe[dataframe['Age'].isnull()].head(2))

Discussion
- 缺失值是数据整理中普遍存在的问题,但许多人低估了处理缺失数据的难度。 pandas 使用 NumPy 的 NaN(“非数字”)值来表示缺失值,但重要的是要注意 NaN 在 pandas 中并没有完全实现。
例如:
# Attempt to replace values with NaN
dataframe['Sex'] = dataframe['Sex'].replace('male', NaN)
结果:
NameError Traceback (most recent call last) in () 1 # Attempt to replace values with NaN ----> 2 dataframe[‘Sex’] = dataframe[‘Sex’].replace(‘male’, NaN) NameError: name ‘NaN’ is not defined
-
为了拥有 NaN 的全部功能,我们需要首先导入 NumPy 库:
# Load library import numpy as np # Replace values with NaN dataframe['Sex'] = dataframe['Sex'].replace('male', np.nan) -
通常,数据集使用特定值来表示缺失的观察值,例如 NONE、-999 或 … pandas 的 read_csv 包含一个参数,允许我们指定用于表示缺失值的值:
# Load data, set missing values dataframe = pd.read_csv(url, na_values=[np.nan, 'NONE', -999])
3.10 Deleting a Column
删除1列,
调用函数drop()
deleteColExample.py
import pandas as pd
url = 'titanic.csv'
dataframe = pd.read_csv(url)
# 删除age
print(dataframe.drop('Age', axis=1).head(2))
# 删除两列
print(dataframe.drop(['Age', 'Sex'], axis=1).head(2))
# 通过列的description删除
print(dataframe.drop(dataframe.columns[1], axis=1).head(2))

Discussion
-
不推荐使用del dataframe[‘Age’]方法(因为他的底层实现方式)
查阅资料:(87条消息) #深入分析# pandas中使用 drop 和 del删除列数据的区别_energy_百分百的博客-CSDN博客_tensorflow删除列
1、del是内置函数
2、drop可以同时操作多个项目效率高
3、drop更加灵活。可以在本地操作也可以返回副本
-
不推荐调用pandas库函数的时候使用inplace=True的参数,这可能会导致更复杂的数据处理管道出现问题,因为我们将 DataFrame 视为可变对象(它们在技术上是可变对象)。应该将DataFrame使用时视为不可变对象
-
#Create a new DataFramedataframe_name_dropped = dataframe.drop(dataframe.columns[0], axis=1)
就是一个例子,如果将DataFrames视为不可变对象,那将减少很多麻烦
3.11 Deleting a Row
删除一行
deleteRowExample.py
import pandas as pd
url = 'titanic.csv'
dataframe = pd.read_csv(url)
# 删除female的前两列
print(dataframe[dataframe['Sex'] != 'male'].head(2))
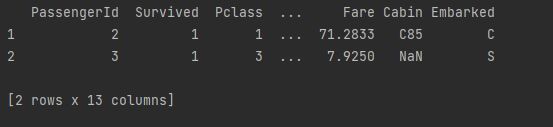
Discussion
- 可以使用drop函数来实现删除行,但是更实用的方法将条件包装在dataframe[]中
- 可以通过索引来删除
3.12 Dropping Duplicate Rows
删除重复的行
现在样例中添加重复的行

dropDupRowsExample.py
import pandas as pd
url = 'titanic.csv'
dataframe = pd.read_csv(url)
# 去除重复的行
print(dataframe.drop_duplicates().head(2))
#检查行数
print("Number Of Rows In The Original DataFrame:", len(dataframe))
print("Number Of Rows After Deduping:", len(dataframe.drop_duplicates()))

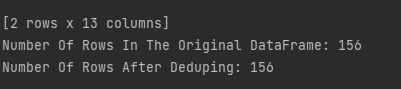
重复的行被删除了
Discussion
-
该解决方案并没有删除任何行。原因是因为 drop_duplicates 默认只删除在所有列中完全匹配的行。
-
通常我们想要筛选数据可以通过子集来检查行
dataframe.drop_duplicates(subset=['Sex']) -
可以通过keep参数来保留重复行的第一次出现
# Drop duplicates dataframe.drop_duplicates(subset=['Sex'], keep='last') -
还有一个相关的函数是
duplicate可以判断这行是不是重复的,可以完成一些复杂的筛选工作
3.13 Grouping Rows by Values
组操作
groupExample.py
import pandas as pd
url = 'titanic.csv'
dataframe = pd.read_csv(url)
# Group rows by the values of the column 'Sex', calculate mean
# of each group
print(dataframe.groupby('Sex').mean())
# 对某列计数
print(dataframe.groupby('Survived')['Name'].count())
# 对某列求平均值
print(dataframe.groupby(['Sex','Survived'])['Age'].mean())
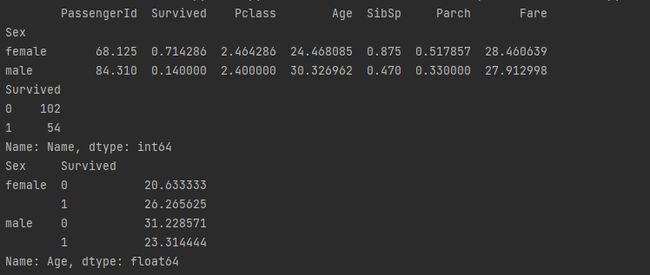
Discussion
- groupby是数据清理真正的起始点
- groupby往往需要搭配统计类函数
- 可以通过字典的方式对单一列进行统计
3.14 Grouping Rows by Time
按照日期进行分组
timeGroupExample.py
# Load libraries
import pandas as pd
import numpy as np
# Create date range
time_index = pd.date_range('06/06/2017', periods=100000, freq='30S')
# Create DataFrame
dataframe = pd.DataFrame(index=time_index)
# Create column of random values
dataframe['Sale_Amount'] = np.random.randint(1, 10, 100000)
# Group rows by week, calculate sum per week
print(dataframe.resample('W').sum())
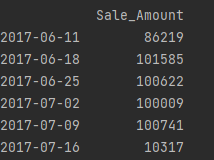
Discussion
- resample要求是数据集的索引是一个类似时间属性的值
- resample常用的一个参数可以指定时间间隔’W’表示周,‘M’表示月,还可以配置一定的比例例如’2W’
- resample默认返回时间组的“右边缘”也就是最小值,例如上述例子2017-06-11为右边缘
- 详细的讲解可以看python时序分析之重采集(resample) - 知乎 (zhihu.com)
3.15 Looping Over a Column
迭代某一列的所有元素
LoopingColExample.py
import pandas as pd
url = 'titanic.csv'
dataframe = pd.read_csv(url)
# Print first two names uppercased
for name in dataframe['Name'][0:2]:
print(name.upper())
# Show first two names uppercased
print([name.upper() for name in dataframe['Name'][0:2]])

Discussion
- 可以用列表的方式进行访问
- 下一节的apply方法更加常用
3.16 Applying a Function Over All Elements in a Column
对某一列元素使用函数
applyExample.py
import pandas as pd
url = 'titanic.csv'
dataframe = pd.read_csv(url)
# 大写函数
def uppercase(x):
return x.upper()
# apply作用后的前两行
print(dataframe['Name'].apply(uppercase)[0:2])

Discussion
- 作者评价apply是个好函数
3.17 Applying a Function to Groups
对分组后的元素进行apply操作
applyGroupExample.py
import pandas as pd
url = 'titanic.csv'
dataframe = pd.read_csv(url)
# Group rows, apply function to groups
print(dataframe.groupby('Sex').apply(lambda x: x.count()))
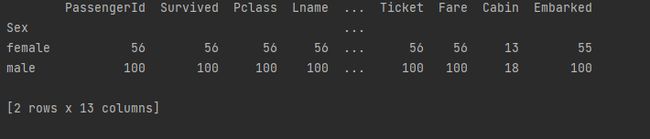
Discussion
- 作者评价apply和group一起很有用
3.18 Concatenating DataFrames
连接两个数据帧
使用pandas.concat函数
concatExample.py
# Load library
import pandas as pd
# Create DataFrame
data_a = {'id': ['1', '2', '3'],
'first': ['Alex', 'Amy', 'Allen'],
'last': ['Anderson', 'Ackerman', 'Ali']}
dataframe_a = pd.DataFrame(data_a, columns = ['id', 'first', 'last'])
# Create DataFrame
data_b = {'id': ['4', '5', '6'],
'first': ['Billy', 'Brian', 'Bran'],
'last': ['Bonder', 'Black', 'Balwner']}
dataframe_b = pd.DataFrame(data_b, columns = ['id', 'first', 'last'])
# 连接行
print(pd.concat([dataframe_a, dataframe_b], axis=0))
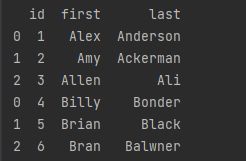
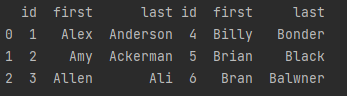
此外还可以连接列
print(pd.concat([dataframe_a, dataframe_b], axis=1))
Discussion
- concatenating——将两个对象粘合在一起,通过axis来指示方向
- 可以使用append凭借series(前面资料查阅发现新版本的pandas会废弃append函数)
3.19 Merging DataFrames
合并两个DataFrrames
mergeExample.py
# Load library
import pandas as pd
# Create DataFrame
employee_data = {'employee_id': ['1', '2', '3', '4'],
'name': ['Amy Jones', 'Allen Keys', 'Alice Bees',
'Tim Horton']}
dataframe_employees = pd.DataFrame(employee_data, columns=['employee_id',
'name'])
# Create DataFrame
sales_data = {'employee_id': ['3', '4', '5', '6'],
'total_sales': [23456, 2512, 2345, 1455]}
dataframe_sales = pd.DataFrame(sales_data, columns=['employee_id', 'total_sales'])
# 自然连接
print(pd.merge(dataframe_employees, dataframe_sales, on='employee_id'))
# 外连接
print(pd.merge(dataframe_employees, dataframe_sales, on='employee_id', how='outer'))
# 左连接
print(pd.merge(dataframe_employees, dataframe_sales, on='employee_id', how='left'))
# 指定属性链接
print(pd.merge(dataframe_employees,
dataframe_sales,
left_on='employee_id',
right_on='employee_id'))
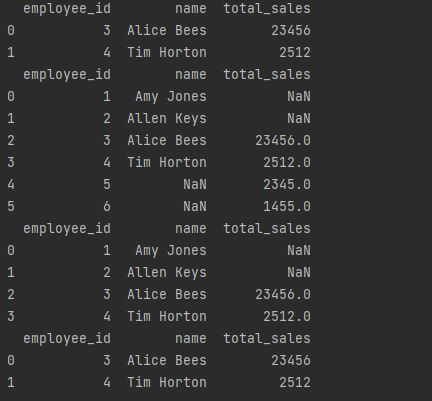
Discussion
- merge与数据库中的join非常相似
- 支持的几种连接方式
- inner: 仅返回在两个 DataFrame 中匹配的行(例如,返回任何行 在 dataframe_employees 和 dataframe_sales 中都有一个employee_id 值)。
- outer: 返回两个 DataFrame 中的所有行。如果一行存在于一个 DataFrame 中但不存在于另一个 DataFrame 中,则为缺失值填充 NaN 值(例如,返回 employee_id 和 dataframe_sales 中的所有行)。
- left: 返回左侧 DataFrame 中的所有行,但仅返回右侧的行 与左侧 DataFrame 匹配的 DataFrame。为缺失值填充 NaN 值(例如,返回 dataframe_employees 中的所有行,但仅返回 dataframe_sales 中具有出现在 dataframe_employees 中的employee_id 值的行)。 ‘
- right: 返回右侧 DataFrame 中的所有行,但仅返回左侧的行 与正确 DataFrame 匹配的 DataFrame。为缺失值填充 NaN 值(例如,返回 dataframe_sales 中的所有行,但仅返回 dataframe_employees 中具有出现在 dataframe_sales 中的employee_id 值的行)。
下一章:(89条消息) Machine Learning with Python Cookbook 学习笔记 第4章_五舍橘橘的博客-CSDN博客