SLAM中的非线性最小二乘问题求解方法及应用
考虑一个简单的最小二乘问题
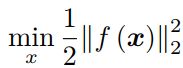
这里自变量 ![]() , f 是任意一个非线性函数,我们设它有 m 维:
, f 是任意一个非线性函数,我们设它有 m 维: ![]() 。下面讨论如何求解这样一个优化问题
。下面讨论如何求解这样一个优化问题
方法一:求导分析
 ,得到了导数为零处的极值,比较它们的函数值大小即可。
,得到了导数为零处的极值,比较它们的函数值大小即可。
(实际情况下,f 并没有一个明确的解析形式,也没办法求导分析,或者导函数相当复杂)
方法二:迭代寻优

这让求解导函数为零的问题,变成了一个不断寻找梯度并下降的过程。直到某个时刻增量非常小,无法再使函数下降。此时算法收敛,目标达到了一个极小,我们完成了寻找极小值的过程。在这个过程中,我们只要找到迭代点的梯度方向即可,而无需寻找全局导函数为零的情况。这个过程的关键是![]() ,即迭代的方向和步长。
,即迭代的方向和步长。
【参考】
【1】视觉slam14讲
【2】SLAM中的优化理论(二)- 非线性最小二乘
【3】非线性最小二乘问题的求解方法
(参考写的虽好,自己过一遍才是自己的)
目录
1、一阶和二阶梯度法
2、高斯牛顿法
3、列文伯格--马夸尔特方法
1、一阶和二阶梯度法
将目标函数在 x 附近进行泰勒展开:
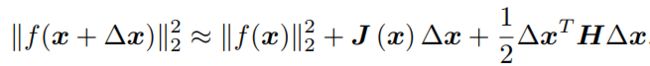
这里 J 是 ∥f(x)∥2 关于 x 的导数(雅可比矩阵),而 H 则是二阶导数(海塞(Hessian)矩阵)
如果只保留一阶项有
![]()
对等式右边求导可得梯度方向
![]()

然后我们再确定一下步长,只要我们沿着反向梯度方向前进即可找到最优解,这种方法称为最速下降法。
如果同时保留二阶项有

对等式右边求导并令导函数=0可得梯度方向
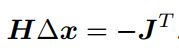
这种保留二阶项的方法称为牛顿法。
上述方法比较简洁,但是最速下降法过于贪心,容易走出锯齿路线,反而增加了迭代次数。而牛顿法则需要计算目标函数的 H 矩阵,这在问题规模较大时非常困难,我们通常倾向于避免 H 的计算。所以更加实用的方法是:高斯牛顿法(Gauss-Newton)和列文伯格——马夸尔特方法。


2、高斯牛顿法
与一阶二阶法不同,高斯牛顿将f(x)在x出进行泰勒展开,仅保留一阶项有
![]()
代入目标函数有
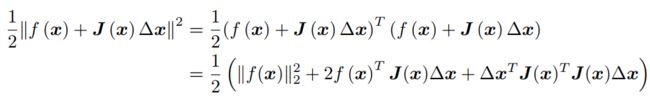
其中:![]()
对等式右边求导并令导函数=0可得梯度方向
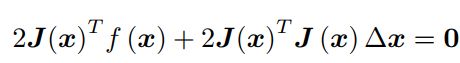

注意,我们要求解的变量是 ∆x,因此这是一个线性方程组,我们称它为增量方程,也可以称为高斯牛顿方程 (Gauss Newton equations) 或者正规方程 (Normal equations)。我们把左边的系数定义为 H,右边定义为 g,那么上式变为:
![]()
![]()
这里把左侧记作 H 是有意义的。对比牛顿法可见, Gauss-Newton 用 JT J 作为牛顿法中二阶 Hessian 矩阵的近似,从而省略了计算 H 的过程。 求解增量方程是整个优化问题的核心所在。

对于高斯牛顿法,同样是不完美的,因为
不是正定而是半正定的,用这样的矩阵求逆计算增量,稳定性就较差,导致算法不收敛。
Levenberg-Marquadt 方法在一定程度上修正了这些问题,一般认为它比 Gauss Newton 更为鲁棒。尽管它的收敛速度可能会比 Gauss Newton 更慢,被称之为阻尼牛顿法(Damped Newton Method),但是在 SLAM 里面却被大量应用。
3、列文伯格--马夸尔特方法
由于 Gauss-Newton 方法中采用的近似二阶泰勒展开只能在展开点附近有较好的近似效果,所以我们很自然地想到应该给 ∆x 添加一个信赖区域(Trust Region),不能让它太大而使得近似不准确。非线性优化种有一系列这类方法,这类方法也被称之为信赖区域方法 (Trust Region Method)。在信赖区域里边,我们认为近似是有效的;出了这个区域,近似可能会出问题。
那么如何确定这个信赖区域的范围呢?
一个比较好的方法是根据我们的近似模型跟实际函数之间的差异来确定这个范围:如果差异小,我们就让范围尽可能大;如果差异大,我们就缩小这个近似范围。因此,考虑使用

ρ 的分子是实际函数下降的值,分母是近似模型下降的值。如果 ρ 接近于 1,则近似是好的。如果 ρ 太小,说明实际减小的值远少于近似减小的值,则
认为近似比较差,需要缩小近似范围。反之,如果 ρ 比较大,则说明实际下降的比预计的更大,我们可以放大近似范围。
于是,我们构建一个改良版的非线性优化框架,该框架会比 Gauss Newton 有更好的效果:
这里近似范围扩大的倍数和阈值都是经验值,可以替换成别的数值。在式(6.24)中,我们把增量限定于一个半径为 µ 的球中,认为只在这个球内才是有效的。带上 D 之后,这个球可以看成一个椭球。在 Levenberg 提出的优化方法中,把 D 取成单位阵 I,相当于直接把 ∆x 约束在一个球中。随后, Marqaurdt 提出将 D 取成非负数对角阵——实际中通常用 JT J 的对角元素平方根,使得在梯度小的维度上约束范围更大一些。不论如何,在 L-M 优化中,我们都需要解式(6.24)那样一个子问题来获得梯度。这个子问题是带不等式约束的优化问题,我们用 Lagrange 乘子将它转化为一个无约束优化问题:
这里 λ 为 Lagrange 乘子。类似于 Gauss-Newton 中的做法,把它展开后,我们发现该问题的核心仍是计算增量的线性方程: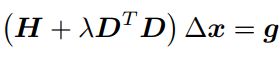
可以看到,增量方程相比于 Gauss-Newton,多了一项 λDT D。如果考虑它的简化形式,即 D = I,那么相当于求解:![]()
我们看到,当参数 λ 比较小时, H 占主要地位,这说明二次近似模型在该范围内是比较好的, L-M 方法更接近于 G-N 法。另一方面,当 λ 比较大时, λI 占据主要地位, L-M更接近于一阶梯度下降法(即最速下降),这说明附近的二次近似不够好。 L-M 的求解方式,可在一定程度上避免线性方程组的系数矩阵的非奇异和病态问题,提供更稳定更准确的增量 ∆x。
在实际中,还存在许多其它的方式来求解函数的增量,例如 Dog-Leg 等方法。我们在这里所介绍的,只是最常见而且最基本的方式,也是视觉 SLAM 中用的最多的方式。总而言之,非线性优化问题的框架,分为 Line Search 和 Trust Region 两类。 Line Search 先固定搜索方向,然后在该方向寻找步长,以最速下降法和 Gauss-Newton 法为代表。而 Trust Region 则先固定搜索区域,再考虑找该区域内的最优点。此类方法以 L-M 为代表。实际问题中,我们通常选择 G-N 或 L-M 之一作为梯度下降策略。
至此,方法都说完了,但是还要一些遗留。
1. 初值怎么确定?
初值的好坏决定了求解结果是趋向局部极小值还是全局极小值,在slam里面通过ICP、PnP之类的方法进行初始化。
2. 高维矩阵的逆怎么求?
增量的求解需要求解矩阵的逆,在实际问题中,矩阵是成千上万的维度,因此几乎没有直接求逆的,例如 QR、 Cholesky 等分解方法。而是有针对性的求解,视觉 SLAM 里,这个矩阵往往有特定的稀疏形式,大大提高了求解效率,这为实时求解优化问题提供了可能性。
矩阵求逆 QR、Cholesky 分解
(未完待续)