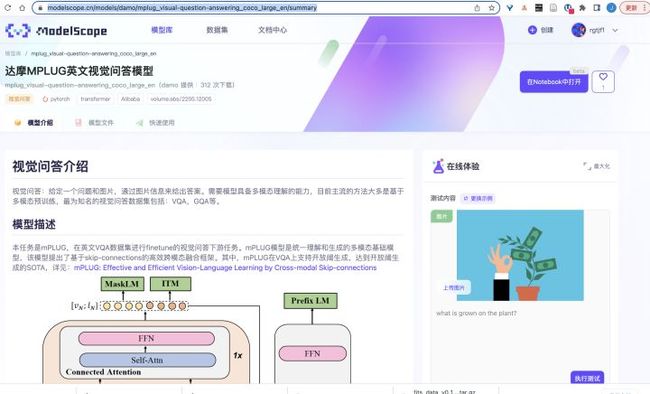
5分钟让你在大火的多模态领域权威榜单VQA上超越人类
ModelScope上开源了达摩院众多业界最强多模态模型,其中就有首超人类的多模态预训练视觉问答模型mPLUG,小编激动的搓搓小手,迫不及待的体验了一下。
一探:浅草才能没马蹄
市面上有好多号称“用户上手简单”,“一步到位”,“傻瓜式”,但是真的,如果不懂两三行代码,没有一些机器学习基础,不趟几次浑水,是真的没办法上手的。浅草才能没马蹄,ModelScope真的做到了,一步即可体验,所见即所得,没有任何的冗余,如丝般顺滑的的在线体验。
一步,点击「执行测试」,有手就行
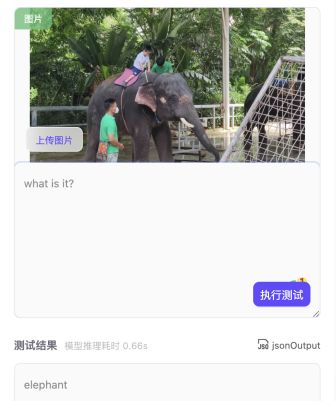
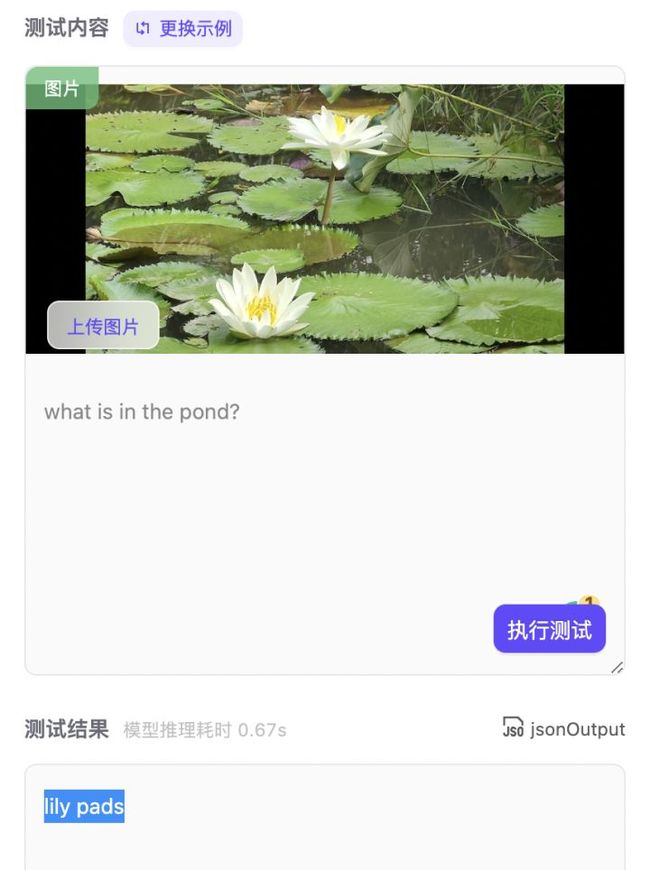
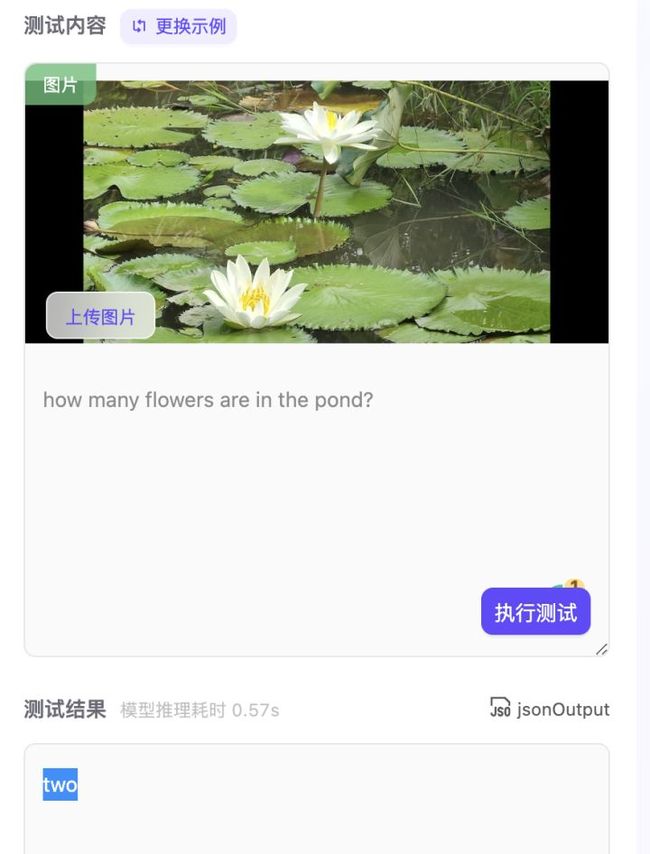
那么这个号称超人类的模型怎么样呢?小编马上开始测试模型!就拿小编最近去西双版纳的图片来测试!!!西双版纳是中国热带生态系统保存最完整的地区,素有“植物王国”、“动物王国”、“生物基因库”、“植物王国桂冠上的一颗绿宝石”等美称。同时西双版纳还有好多好吃的,舂鸡脚、泰国菜、孔雀宴、老挝冰咖啡、小菠萝、傣式烧烤等等。
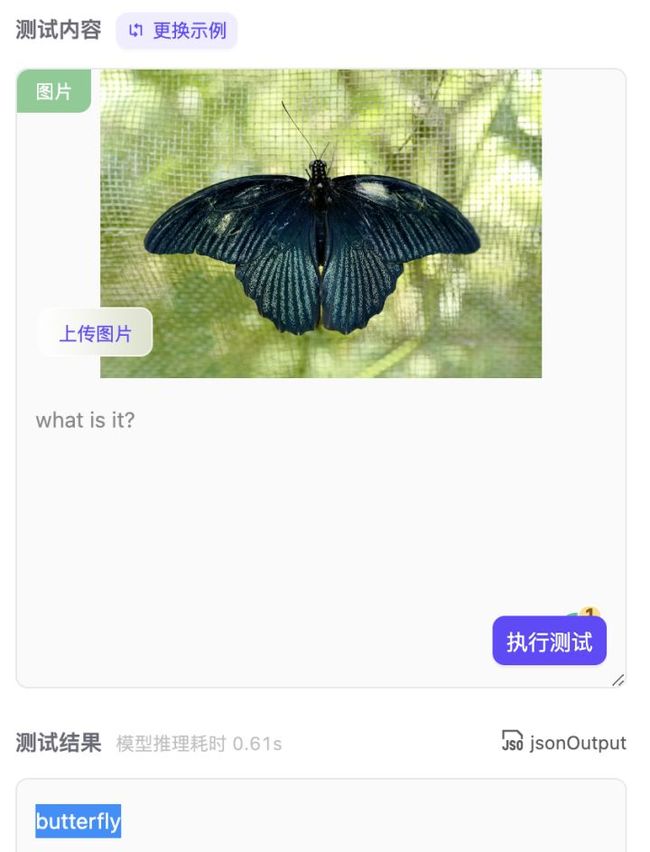
测完之后,真服了,真的是全知全能的问答模型,无论问物种、问数量、问位置,模型都能回答出来。图中小编刚认识的睡莲(lily pads)--泰国的国花都是精准无比,还有图4也能把背景中大象也能识别出来,实在太厉害了!

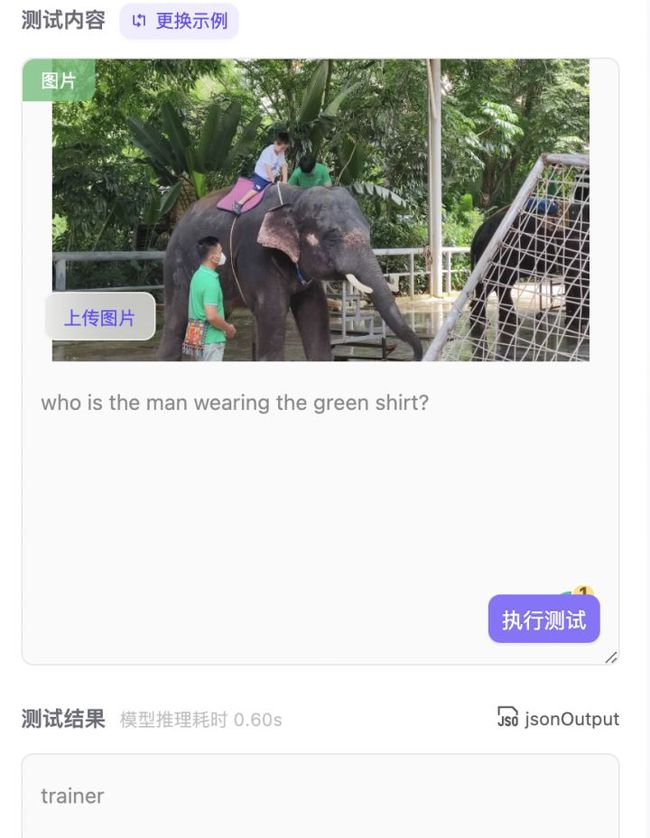
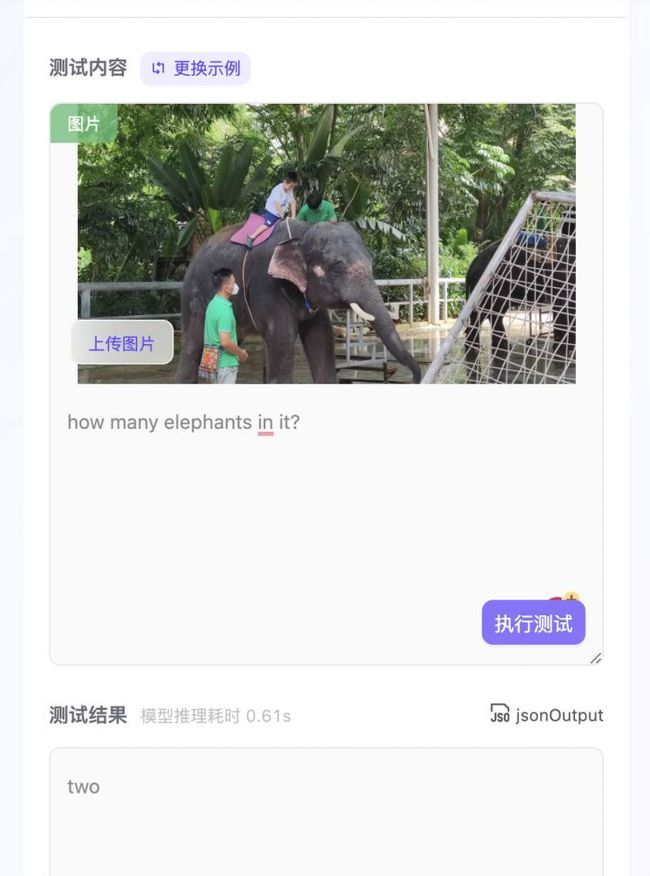

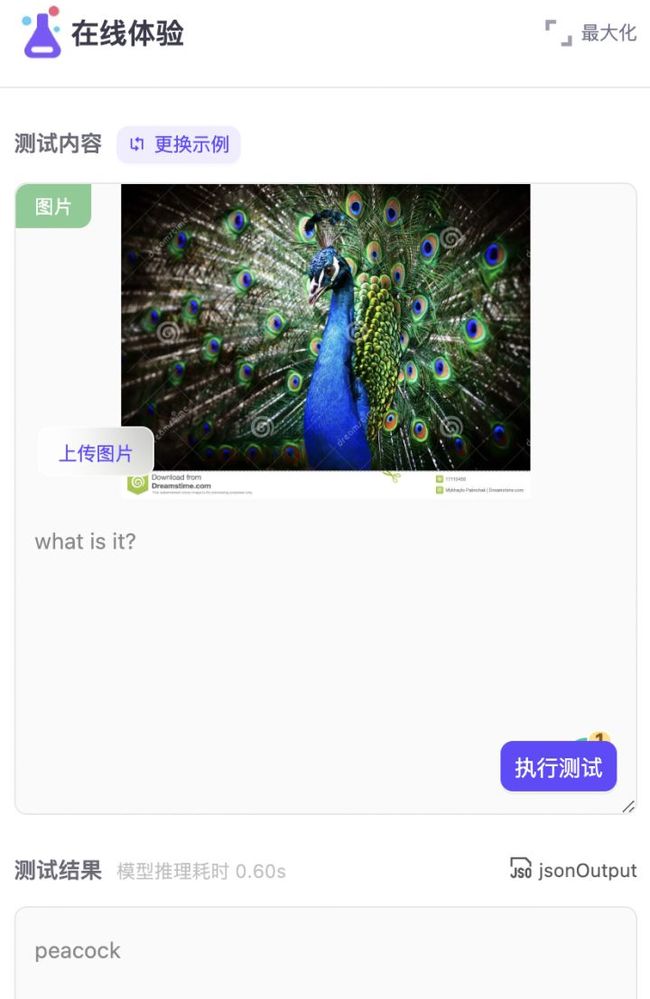
小编又想了个办法,我要测试孔雀&孔雀舞,这下终于难倒了模型!
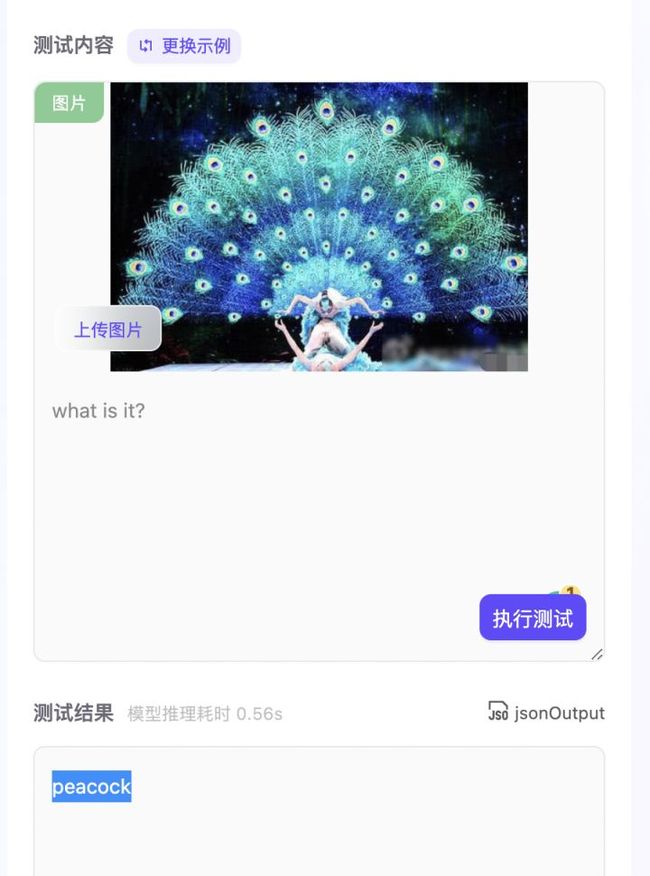
二探:觉知此事要躬行
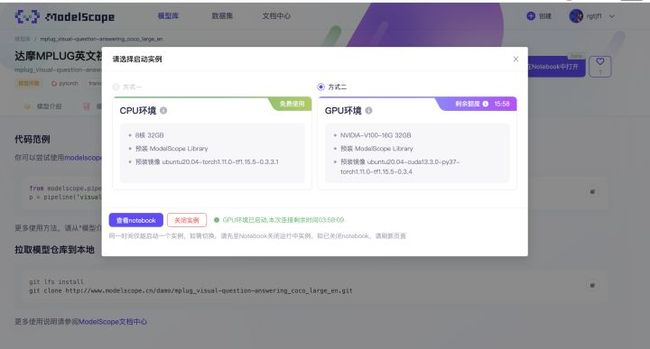
遇到这么强的模型,小编当然想深刻了解一下,觉知此事要躬行嘛!其实是想自己拥有一个,将来出去玩的时候可以把导游费给省了。ModelScope也为我考虑到了,右上角「在Notebook中打开」,点它!这里有CPU环境和GPU环境,看到GPU,小编眼睛都直了,这不就是和3090Ti齐名的V100,如此高性能的GPU,羊毛党果断薅一下。

测试过程非常流程,只需要会import就能实现整体流程,小编也整理了相关代码放出来可以使用!
###
!pwd
!mkdir data
!wget http://xingchen-data.oss-cn-zhangjiakou.aliyuncs.com/maas/visual-question-answering/visual_question_answering.png -O data/visual_question_answering.png
###
from PIL import Image
image = Image.open('data/visual_question_answering.png')
image.show()
###
from PIL import Image
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
model_id = 'damo/mplug_visual-question-answering_coco_large_en'
input_vqa = {
'image': Image.open('data/visual_question_answering.png'),
'question': 'What is grown on the plant?',
}
pipeline_vqa = pipeline(Tasks.visual_question_answering, model=model_id)
print(pipeline_vqa(input_vqa))
为了方便大家,小编也把运行中间步骤展示出来,这样无论是小白还是新手,都可以玩起来了。


离部署只差最后一步了,用gradio就可以满足你,按照文档提示即可完成。
三探:无招胜有招
多模态预训练模型mPLUG是建立在千万图文数据预训练的基础上,小编就想探究下模型是不是真的都学会了吗?最近文本生成图像模型DALLE和扩散模型开始如火如荼根据文本生成各种想象的图片,小编就想对于这些生成出来的图片,视觉问答模型mPLUG还可以正确回答吗?会不会因为没见过类似的样本就没有办法回答呀?
小编先尝试了对大名鼎鼎的DALLE生成的图像进行问答,DALLE是OpenAI放出的文本生成图像模型,取名DALL-E,是为了向艺术家萨尔瓦多-达利(Salvador Dali )和皮克斯的机器人WALL-E致敬。测试之后,看看下面的结果,连艺术家dali都能识别出来,不愧是见多识广,知识也太渊博了!




###
from modelscope.msdatasets import MsDataset
# from icecream import ic
dataset = MsDataset.load('vqa_trial', subset_name='vqa_trial', split="test")
print(dataset[0])
def resize_img(img):
# set the base width of the result
basewidth = 300
# determining the height ratio
wpercent = (basewidth/float(img.size[0]))
hsize = int((float(img.size[1])*float(wpercent)))
# resize image and save
img = img.resize((basewidth,hsize), Image.ANTIALIAS)
return img
resize_img(dataset[0]['image']).show()
###
from PIL import Image
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
model_id = 'damo/mplug_visual-question-answering_coco_large_en'
pipeline_vqa = pipeline(Tasks.visual_question_answering, model=model_id)
for item in dataset:
input_vqa = {
'image': item['image'],
'question': item['question'],
}
answer = pipeline_vqa(input_vqa)
resize_img(item['image']).show()
print('Q: ' + item['question'])
print('A: ' + answer['text'])同时小编也拿了ModelScope上的文生图模型进行测试,测试结果如下:
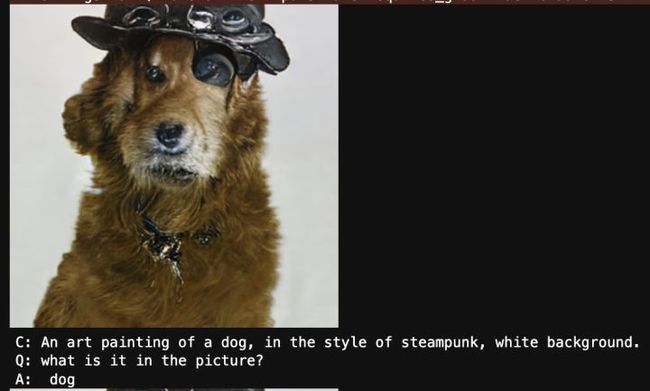



可以看到视觉问答模型mPLUG具有非常强的泛化能力,针对各种生成的图片,各个不同领域的来源,都能回答正确。这就是训练了千万次,理解了视觉特征之后,达到了“无招胜有招”,实际测试中就可以融会贯通!
结语
到这里就结束了,赶紧上ModelScope一键体验超人类的视觉问答模型,一键直达:https://www.modelscope.cn/models/damo/mplug_visual-question-answering_coco_large_en/summary 。
原文链接
本文为阿里云原创内容,未经允许不得转载。