【Image Text Matching】Learning Semantic Concepts and Order for Image and Sentence Matching
Learning Semantic Concepts and Order for Image and Sentence Matching
CVPR 2018, Center for Research on Intelligent Perception and Computing (CRIPAC), National Laboratory of Pattern Recognition (NLPR)
Abstract
图像和句子匹配近年来取得了很大的进展,但由于视觉语义差异较大,仍然具有挑战性。这主要是由于像素级图像的表示通常缺乏其匹配句子中的高级语义信息。本文提出了一种语义增强的图像和句子匹配模型,该模型可以通过学习语义概念,然后按照正确的语义顺序组织它们来改进图像的表示。给定一个图像,本文首先使用多区域多标签CNN multi-regional multi-label CNN来预测其语义概念semantic concept,包括对象、属性、动作等。然后,考虑到不同的语义概念顺序导致不同的语义意义,使用上下文门控句子生成方案context-gated sentence generation scheme进行语义顺序学习。它同时使用包含概念关系的图像全局上下文作为参考,并使用匹配句子中的ground truth语义顺序作为监督。在获得改进的图像表示后,本文使用传统的LSTM学习句子表示,然后联合进行图像和句子匹配以及句子生成进行模型学习。
1. Introduction
图像和句子匹配的任务是指测量图像和句子之间的视觉-语义相似性。它已广泛应用于图像-句子跨模态检索的应用。虽然在这一领域已经取得了很大的进展,但由于存在巨大的视觉语义差异,准确地测量图像和句子之间的相似性仍然是很重要的。以图1中的一个图像及其匹配的句子为例,图像中出现的主要对象、属性和动作分别为:{cheetah, gazelle,grass}, {quick, young, green} 和 {chasing, running}。这些高级语义概念是需要与匹配的句子进行比较的基本内容,但它们不能轻易地从像素级图像中表示出来。大多数现有的方法通过提取一个全局的CNN 特征向量来联合表示所有的概念,其中这些概念相互纠缠。因此,一些主要的前景概念往往占主导地位,而其他次要的背景概念可能会被忽略,这对于细粒度的图像和句子匹配不是最优的。为了全面预测图像的所有语义概念,一种可能的方法是自适应地探索属性学习框架,但这种方法在图像和句子匹配方面还没有得到很好的研究。
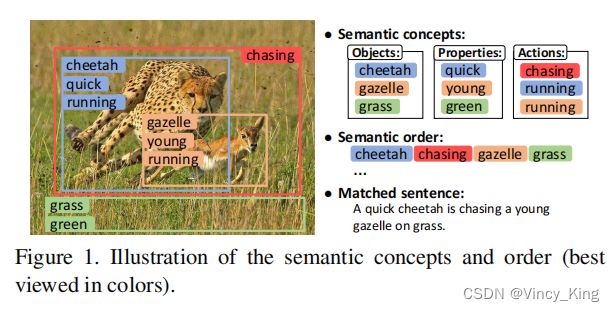
除了语义概念外,如何正确地组织它们,即语义顺序,在视觉-语义差异中起着个更重要的作用。如图1所示,根据上述语义概念,如果我们错误地将它们的语义顺序设置为:a quick gazelle is chasing a young cheetah on grass,那么它将与图像内容和匹配的句子有完全不同的含义。但是直接从语义概念中学习正确的语义顺序是非常困难的,因为存在各种语义上有意义的错误的语义顺序。
两种解决方法:第一,我们可以诉诸于图像的全局上下文,因为它已经从语义概念之间出现的空间关系中表明了正确的语义顺序,例如,猎豹在瞪羚的左边。但目前尚不清楚如何将它们与语义概念适当地结合起来,并使它们能直接与句子中的语义顺序相比较。第二,我们可以从图像中生成一个描述性的句子作为它的表示。然而,基于图像的句子生成image caption也是一个非常具有挑战性的问题。即使是那些最SOTA的方法,也不能总是生成非常真实的句子来捕捉所有的图像细节。图像细节对于匹配任务至关重要,因为全局图像-句子相似性是由图像细节的局部相似性聚合起来的。因此,这些方法在图像和句子匹配方面不能达到非常高的性能。
为了弥补图像和句子之间的视觉-语义差异,本文提出了一个语义增强的图像和句子匹配模型,该模型通过学习语义概念,然后以正确的语义顺序组织它们来改进图像的表示。为了学习语义概念,作者利用了一个multi-regional multi-labelCNN,它可以同时预测对象、属性、动作等方面的多个概念。该CNN的输入是从图像中选择性提取的多个区域,它可以全面捕获所有的概念,无论它们是否是主要的前景概念。为了以正确的语义顺序组织提取的语义概念,作者首先以门控的方式将它们与图像的全局上下文进行融合。上下文包括所有语义概念的空间关系,可作为促进语义顺序学习的参考。然后利用匹配句子中的基真值语义顺序作为监督,通过强制融合的图像表示来生成匹配的句子。
在用语义概念和顺序增强图像表示后,作者使用传统的LSTM 学习句子表示。然后将图像和句子的表示与一个结构化目标进行匹配,并与另一个句子生成目标相结合,进行联合模型学习。为了证明该模型的有效性,我们在两个公开的数据集上进行了多次图像注释和检索实验,并取得了SOTA结果。
2. Related Work
2.1 Visual-semantic Embedding Based Methods
Yan and Mikolajczyk 以深度典型相关分析为目标,将图像和句子关联起来,其中匹配的图像-句子对具有较高的相关性。基于类似的框架, Klein 等使用Fisher Vectors (FV) 学习更多的歧视表示句子,Lev等使用RNN聚合FV并进一步提高性能,和Plummer等探索区域短语对应的使用。相比之下,本文提出的模型考虑通过学习语义概念和顺序来弥补视觉-语义差异。
2.2 Image Captioning Based Methods
Chen和Zitnick 使用多模态自动编码器进行双向映射,并使用跨模态似然和重构误差来度量相似度。Mao等人提出了一种多模态从图像中生成句子的RNN模型,其中以生成句子的复杂性作为相似性。Donahue等人设计了一个用于image caption的长期循环卷积网络,它也可以扩展到图像和句子匹配。Vinyals等人开发了一种神经图像描述生成器,并显示了其对图像和句子匹配的有效性。这些模型最初是为了预测语法完整的句子而设计的,所以它们在测量图像-句子相似度方面的表现不是很好。与之不同的是,本文工作集中在相似度测量上,特别适合于图像和句子匹配的任务。
3. Semantic-enhanced Image and Sentence Matching
本节将详细提出语义增强图像和句子匹配模型: 1)基于传统LSTM的句子表示学习,2)语义概念提取与多区域多标签CNN,3) 语义顺序学习上下文门控句子生成方案,4)模型学习联合图像和句子匹配和句子生成。

3.1 Sentence Representation Learning
语义相关的词的语义顺序本质上是由句子的顺序性质所表现出来的,为了学习能够捕获这些与语义相关的单词并对其语义顺序建模的句子表示,本文使用传统的LSTM并得到最后一个时间步长的隐藏状态 s ∈ R H s∈R^H s∈RH。
3.2 Image Semantic Concept Extraction
本文手动构建了一个训练数据集,其只保留了名词、形容词、动词和数字作为语义概念,并消除了句子中所有与语义无关的单词,以及忽略使用频率很低的单词。此外,作者统一了动词的不同时态,名词的单复数形式,减少词汇量,得到了一个包含K个语义概念的词汇表。基于此词汇表,可以通过从句子中选择多个单词作为基本真理语义概念来生成训练数据集。然后,对语义概念的预测等价于一个多标签分类问题,作者简单地使用在ImageNet数据集上预训练的VGGNet作为多标签CNN。为了适应多标签分类化,作者将输出层修改为有K个输出,每个输出对应于一个语义概念的预测置信值。给定一幅图像,其对ground truth语义概念的one-hot表示为 y i ∈ { 0 , 1 } K y_i∈\{0,1\}^K yi∈{0,1}K,而多标签CNN预测的得分向量为 y ^ i ∈ { 0 , 1 } K \hat y_i∈\{0,1\}^K y^i∈{0,1}K,则可以通过优化以下目标来学习模型:
L c n n = ∑ c = 1 K log ( 1 + e ( − y i , c y ^ i , c ) ) L_{cnn}=\sum_{c=1}^K \log(1+e^{(-y_{i,c}\hat y_{i,c})}) Lcnn=c=1∑Klog(1+e(−yi,cy^i,c))
在测试过程中,考虑到语义概念通常出现在图像的局部区域中,且大小不同,作者以区域的方式进行概念预测。给定一个测试图像,首先选择性地提取r个图像区域,然后将它们调整为正方形形状。通过将这些区域分别输入学习到的多标签CNN模型中,可以得到一组预测的置信度得分向量confidence score vectors p p p。作者对这些分数向量执行元素级最大池化,以获得单个向量,其中包括对所有语义概念的期望置信度分数。
3.3 Image Semantic Order Learning
在获得语义概念后,如何按照正确的语义顺序合理地组织它们,对图像和句子匹配起着重要的作用。本文提出了一种上下文门控句子生成方案,以图像全局上下文作为参考,以上下文生成作为监督。
3.3.1 Global Context as Reference
因此,从分离的语义概念中直接学习语义顺序并不容易,因为语义顺序不仅涉及概念之间的超文本关系,还涉及高级语义层次中短语之间的文本隐含关系。为了解决这个问题,本文使用图像全局上下文作为语义顺序学习的辅助参考。如图3所示,全局上下文不仅可以在一个粗糙的层次上描述所有的语义概念,而且还可以表示它们彼此之间的空间关系,例如,两只长颈鹿站在左边,而篮子站在左上角。在组织分离的语义概念时,模型可以引用全局上下文来找出它们之间的关系,然后将它们结合起来,以促进语义顺序的预测。为了高效的实现,本文使用预先训练过的VGGNet来处理整个图像内容,然后提取最后一个全连接层中的向量作为所需的全局上下文。
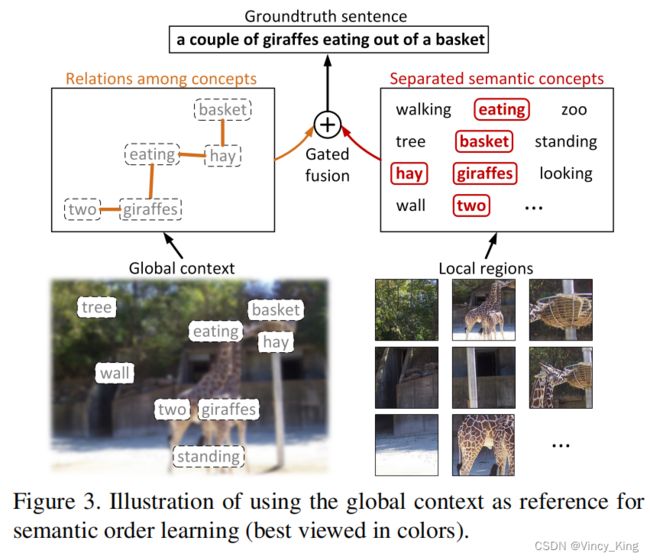
要对这样的过程进行建模,一个简单的方法是将全局上下文与语义概念求和在一起。但考虑到不同图像的内容可能是不同的,因此语义概念和上下文的相对重要性在大多数情况下是不相等的。对于那些内容复杂的图像,它们的全局上下文可能有点模糊,因此语义概念更具鉴别性。为了解决这个问题,作者设计了一个门控融合单元,它可以有选择性地平衡语义概念和上下文的相对重要性。该单元充当一个门,控制语义概念和上下文的信息对它们的融合表示的贡献。在获得归一化上下文向量 x ∈ R I x∈R^I x∈RI和概念得分向量 p ∈ R K p∈R^K p∈RK后,通过门控融合单元的融合可以表述为:
p ^ = ∣ ∣ W l p ∣ ∣ 2 , x ^ = ∣ ∣ W g x ∣ ∣ 2 , t = σ ( U l p + U g x ) \hat p=||W_lp||_2,\hat x=||W_gx||_2,t=\sigma(U_lp+U_gx) p^=∣∣Wlp∣∣2,x^=∣∣Wgx∣∣2,t=σ(Ulp+Ugx)
v = t ⊙ p ^ + ( 1 − t ) ⊙ x ^ v=t\odot \hat p +(1-t)\odot \hat x v=t⊙p^+(1−t)⊙x^
其中, v ∈ R H v∈R^H v∈RH为语义概念和全局上下文的融合表示。函数 σ σ σ将门向量 t ∈ R H t∈R^H t∈RH中的每个元素重新缩放到[0,1],从而使 v 成 为 p 和 x 的 v成为p和x的 v成为p和x的元素加权和。
3.3.2 Sentence Generation as Supervision
为了学习基于融合表示的语义顺序,一种直接的方法是直接从中生成一个句子,类似于image caption,虽然该方法可以生成有语义意义的句子,但它们生成的句子捕捉图像细节的准确性不是很高。即使生成的句子是高度语义的,并且进一步影响相似度的测量,句子中的一点错误也会被放大,而且相似度是在细粒度的水平上计算的。因此,即使是最先进的image caption模型也不能很好地完成图像和句子匹配任务。
事实上,图像和句子匹配任务没有必要生成一个语法完整的句子。我们也可以将融合的上下文和概念视为图像表示,并在句子生成过程中使用匹配句子中的ground truth语义顺序对其进行监督。作者将图像表示输入生成的LSTM的初始隐藏状态,并要求其能够生成匹配的句子。在cross-word和cross-phrase生成过程中,图像表示可以学习单词之间的文本关系和短语之间的文本隐含关系作为语义顺序。
在句子生成过程中,由于所有的单词都是以链的方式预测的,当前预测单词的概率 P P P依赖于其所有之前的单词,以及初始时间步的输入语义概念 p p p和上下文 x x x。
3.4 Joint Matching and Generation
在模型学习过程中,为了联合执行图像和句子匹配和句子生成,我们需要最小化以下组合目标:
L = L m a t + λ × L g e n L=L_{mat}+\lambda × L_{gen} L=Lmat+λ×Lgen
其中, λ λ λ是一个用于平衡的调优参数。 L m a t L_{mat} Lmat是一个结构化的目标,它鼓励匹配的图像和句子的余弦相似度得分大于不匹配的图像和句子:
∑ i k = max { 0 , m − s i i + s i k + max { 0 , m − s i i + s k i } } \sum_{ik}=\max\{0,m-s_{ii}+s_{ik}+\max \{0,m-s_{ii}+s_{ki}\}\} ik∑=max{0,m−sii+sik+max{0,m−sii+ski}}
其中 m m m是一个边缘参数, s i i s_{ii} sii是匹配的第 i i i个图像和第 i i i个句子的得分, s i k s_{ik} sik是不匹配的第 i i i个图像和第 k k k个句子的得分,与 s k i s_{ki} ski反之亦然。在我们的实验中,我们根据经验将每对配对的错配对总数设置为128对。 L g e n L_{gen} Lgen是给定语义概念 p p p和上下文 x x x的匹配句子的负条件对数似然值:
− ∑ t log P ( w t ∣ w t − 1 , w t − 2 , . . . , w 0 , x , p ) -\sum_t \log P(w_t|w_{t-1},w_{t-2},...,w_0,x,p) −t∑logP(wt∣wt−1,wt−2,...,w0,x,p)
其中,作者在实验中使用预测的语义概念,而不是ground truth概念。
除多区域多标签CNN外,本文模型的所有模块都可以构成一个完整的深度网络,可以进行从原始图像和句子到相似度评分的端到端联合训练。本文不需要在测试期间生成这个句子,只需要从x和p中计算出图像表示的v,然后将其与句子表示的s进行比较,从而得到它们的余弦相似度得分即可。
4. Experimental Results
4.1 Datasets and Protocols
- Flickr30k 由从Flickr网站收集的31783张图片组成。每幅图片都附有5个人工注释的句子。本文使用训练、验证和测试分割,它分别包含28000、1000和1000张图像。
- MSCOCO 由82783张训练图像和40504张验证图像组成,每张图像都与5个句子相关联。使用训练、验证和测试分割,分别有82783张、4000张和1000张(或5000张)图像。当使用1000张图像进行测试时,进行5倍交叉验证并报告平均结果。
4.2 Implementation Details
图像标注和检索常用的评价标准是“R@1”、“R@5”和“R@10”,即前1、5和10个结果的召回率。本文还通过平均所有6个召回率来计算一个额外的标准“mR”,以评估图像注释和检索的整体性能。

作者设计了不同的消融模型,如表1。
- “1-crop”和“10-crop”分别是指在提取全局上下文时从图像中裁剪1或10个区域。
- “concept”和“context”分别表示使用语义概念和全局上下文。
- “sum”和“gate”分别是通过特征求和和门控融合单元将语义概念和上下文结合起来的两种不同的方式。
- “sentence”,“generation”和“sampling”是三种不同的方法来学习语义顺序,“sentence”使用先进的image caption方法从图像生成句子,然后认为句子作为图像表示,“generation”使用句子生成监督在3.3.2节所述,和“sampling”另外使用预定抽样。
- “share”和“non-share”表示用于句子表示学习和句子生成的两个单词嵌入矩阵的参数是否共享。
4.3 Evaluation of Ablation Models
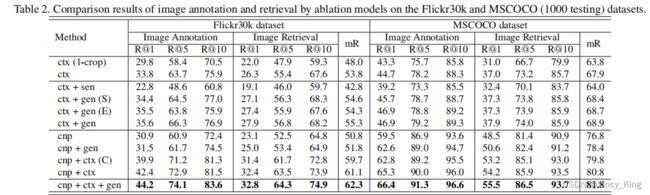
- 裁剪10个图像区域比仅裁剪1个区域可以实现更健壮的全局上下文特征。
- 直接使用预先生成的句子作为图像表示(如“ctx+sen”)并不能提高性能,因为生成的句子可能不能准确地包含图像细节。
- 利用句子生成来监督语义顺序学习(如“ctx+gen”)是非常有效的。但是额外地执行预定的抽样(如“ctx+gen(S)”)不能进一步提高性能。这可能是因为基本真语义顺序在采样过程中退化,因此模型不能很好地学习它。
- 使用一个共享的单词嵌入矩阵(如“ctx+gen(E)”)并不能提高性能,这可能是由于为两个任务学习一个单一化的矩阵是困难的。
- 使用语义概念(如“cnp”)已经可以获得良好的性能,特别是当训练数据在MSCOCO数据集上足够时。
- 简单地将概念和上下文相加(如“cnp+ctx©”)可以进一步改进结果,因为上下文包含了非常有用的概念之间的空间关系。
- 使用所提出的门控融合单元(如“cnp+ctx”)表现更好,由于有效的重要性平衡方案。
- 采用“cnp+ctx+gen”,通过门控融合单元将10个裁剪提取的上下文与语义概念结合起来,利用句子生成进行语义顺序学习。如果不使用语义概念(如“ctx+gen”)或上下文(如“cnp+gen”),性能就会严重下降。
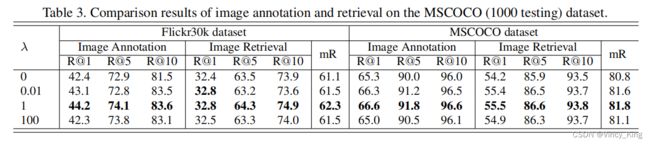
在接下来的实验中,将“cnp+ctx+gen”作为默认模型。对平衡参数λ调参,将其从0改变到100。相应的结果如表3所示,当λ=1时,模型可以达到其最好的性能。说明生成目标与匹配目标起着同样重要的作用。
4.4 Comparison with State-of-the-art Methods

- 在MSCOCO数据集上使用VGGNet或ResNet,本文模型在所有7个评估标准上都大大优于目前最先进的模型。它证明了学习图像表示的语义概念和顺序是非常有效的。
- 在Flickr30k数据集上使用VGGNet时,模型在R@1评价准则上的性能低于2WayNet,但在其余评价准则上的整体性能更好。
- 当在Flickr30k数据集上使用ResNet时,我们的模型能够获得最好的结果。
- 本模型在MSCOCO数据集上获得了比Flickr30k更大的改进。这是因为MSCOCO数据集有更多的训练数据,因此我们的模型可以更好地拟合来预测更准确的图像-句子相似性。
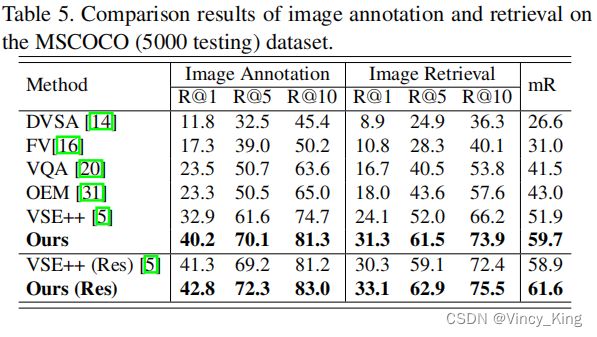
另外使用所有5000张图像及其句子进行测试,并在表5中给出了比较结果。所有方法的总体结果都低于表4。这可能是因为目标集要大得多,因此对于给定的查询存在更多的干扰物。但在所有模型中,本文模型仍然取得了最好的性能,再次证明了其有效性。其中,本文模型使用VGGNet比ResNet有更大的改进,这源于“Ours(Res)”只使用ResNet来提取全局上下文,而不使用语义概念。
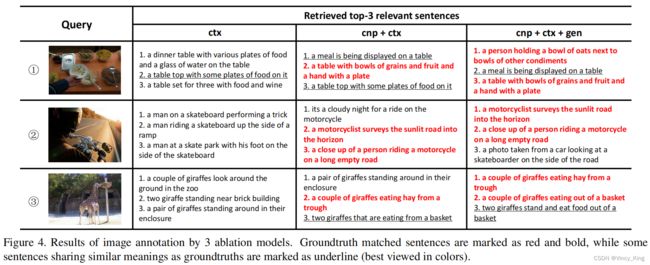
4.5 Analysis of Image Annotation Results
为了定性地验证模型的有效性,作者选择了几个具有复杂内容的代表性图像,通过3个消融模型“ctx”、“cnp+ctx”和“cnp + ctx + gen”检索相关句子。图4中显示了3个模型检索到的前3个相关句子,在图5中预测了置信度得分的前10个语义概念。
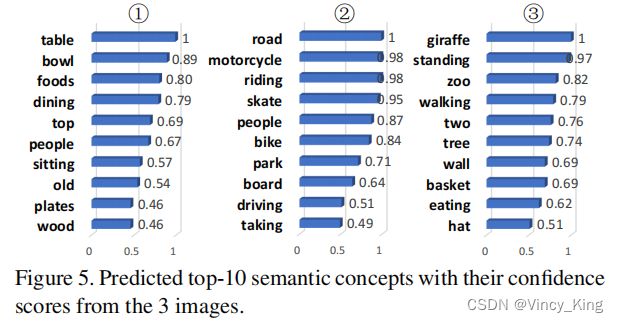
- 图5可以看出,多区域多标签CNN可以准确地预测出描述详细图像内容的高置信度得分的语义概念。注意到skate的分配错误,这可能是由于图像内容是复杂的。
- 如图4所示,如果没有预测的语义概念,“ctx”就不能准确地从复杂的图像内容中捕获语义概念。
- “cnp+ctx”结合预测的语义概念后,句子与图像的含义非常相似,能够将基本真实的句子排在前3位。但排名前1的句子仍然没有涉及部分图像细节
- 通过进一步学习句子生成的语义顺序,“cnp+ctx+gen”能够将所有相关概念关联起来,检索匹配的句子与所有图像细节。
5. Conclusions and Future Work
“zoom:50%;” />
- 图5可以看出,多区域多标签CNN可以准确地预测出描述详细图像内容的高置信度得分的语义概念。注意到skate的分配错误,这可能是由于图像内容是复杂的。
- 如图4所示,如果没有预测的语义概念,“ctx”就不能准确地从复杂的图像内容中捕获语义概念。
- “cnp+ctx”结合预测的语义概念后,句子与图像的含义非常相似,能够将基本真实的句子排在前3位。但排名前1的句子仍然没有涉及部分图像细节
- 通过进一步学习句子生成的语义顺序,“cnp+ctx+gen”能够将所有相关概念关联起来,检索匹配的句子与所有图像细节。
5. Conclusions and Future Work
本文提出了一个语义增强的图像和句子匹配模型。主要贡献是通过学习语义概念,然后按照正确的语义顺序组织它们来改进图像表示。这是通过在多区域多标签CNN、门控融合单元、联合匹配和生成学习等方面的一系列模型组件来实现的。本文系统地研究了这些成分对图像和句子匹配的影响,并通过实现显著的性能改进,证明了模型的有效性。在未来,作者将在多区域多标签CNN中使用ResNet替换所使用的VGGNet,以更准确地预测语义概念。该模型可以进行图像和句子匹配以及句子生成,因此作者希望将其扩展用于image caption任务。