一、用Python从零实现横向联邦图像分类
文章目录
- 前言:用Python从零实现横向联邦图像分类
- 一、环境配置
-
- 1. 下载Anaconda
- 2. 下载显卡对应的CUDA
- 3. 安装cuDNN
- 4. 配置pytorch-gpu环境
- 二、用Python从零实现横向联邦图像分类
-
- 运行代码
- 1. 数据集
- 2. 服务器端
- 3. 客户端
- 4. 聚合
- 5. `Resnet18`在`cifar10`上的联邦学习与中心化训练的效果对比
- 6. `Resnet18`在`MNIST`上的联邦学习与中心化训练的效果对比
- 总结
前言:用Python从零实现横向联邦图像分类
联邦学习是一种新型的、基于数据隐私保护技术实现的分布式训练范式,自提出以来,就受到学术界和工业界的广泛的关注。近年来,随着联邦学习的飞速发展,使得其成为解决数据孤岛和用户隐私问题的首选方案,但当前市面上这方面的实战书籍却尚不多见。本书是第一本权威的联邦学习实战书籍,结合联邦学习案例,有助于读者更深入的理解联邦学习这一新兴的学科。本专栏通过对《联邦学习实战》一书中的代码重现加深对联邦学习概念的理解。本专栏实战内容主要是针对包含可信第三方的联邦学习框架,针对去中心化的联邦学习模型也亟待研究,包括且不限于与区块链、秘密共享技术的融合,在保证通信开销在可承受范围内做到安全系数更高模型更加简化的联邦学习是下一步的研究趋势。
下面简单介绍一下联邦学习。杨强教授给出一个形象的比喻,我们把数据比作“草”,把机器学习模型或者深度学习模型比作“羊”。在联合学习的过程中,传统的集中式学习模型是将从各方收集到的数据集中到一起,从而feed我们的机器学习模型从而得到更准确的模型,按照我们上面的比喻就是把所有的草都集中到羊圈中,一步步地把羊喂肥。这个集中式的过程,草是离开生长地的,而羊是不动的,即“羊不动草动”。
但随着个人和国家对数据隐私的高度重视,包括欧盟出台的GDPR还有我国刚出台的《网络空间安全法》都体现了国家对于个人数据隐私的保护,“草动”变得不再合法,也危害了个人数据安全。这个时候急需一种既能够保证数据隐私又能联合各方数据训练的联合模型。这个时候联邦学习应运而生。
2017年由谷歌率先提出了联邦学习的概念,并给出了经典的FedAvg算法。联邦学习按照我们上面的比喻,就是我们把羊迁到长草的地方去吃草,即“草不动羊动”,也就是“数据不动模型动”。当我们保证了用户的数据不离开本地时,用户的数据安全也得到了最可靠的保护,这实际上也打破了“数据孤岛”的难题。
联邦学习因为其实用性和安全性在金融、医疗、风控等领域都存在大量应用。虽然在模型参数的通信过程中,有研究已经指明攻击者可以根据模型参数反推出数据的统计信息从而达到窃取数据信息的目的,但模型攻击和防御本来就是一种博弈。在攻击者的不断攻击下,安全可靠且高效的联邦学习模型的研究也必然成为热点。
杨强教授给出了联邦学习的三个分类:横向联邦学习、纵向联邦学习、联邦迁移学习。
横向联邦学习(Horizontal FL)是参与方数据具有重叠的数据特征,即在不同参与方之间数据特种是对齐的,不同的是我们的样本。例如两家银行,他们的数据特征是有重叠的,但是他们的用户很少重叠。横向联邦学习又称为样本划分的联邦学习,行代表样本ID,列代表数据特征,横向联邦学习其实就是数据特征对齐的联邦学习: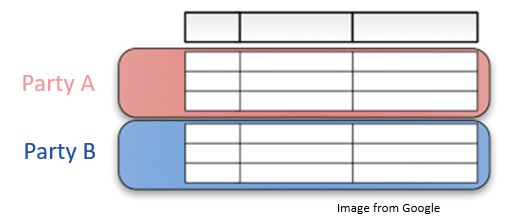
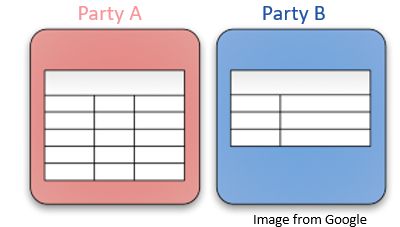
纵向联邦学习(Vertical FL)是参与方数据具有重叠的样本,即样本对齐,不同的是数据特征。比如说同地区的一家银行和一家电商平台,他们具有重叠的用户样本,但是在银行和电商平台办理的业务是不同的。比如银行和超市可以联合描绘出用户更具体的消费画像,根据用户的支出能力为其推荐商品。所以纵向联邦学习又称为特征划分的联邦学习:
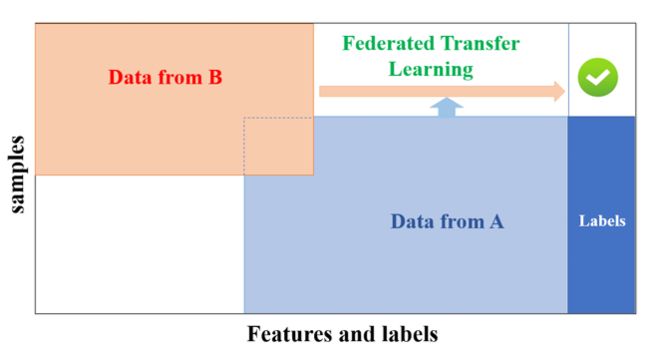
联邦迁移学习的数据样本和数据特征都很少重叠,适合异构数据的联邦问题。联邦迁移学习研究进展缓慢,也将成为今后的热点:
本文使用Python实现了一个简单的横向联邦学习模型。使用的联邦算法是经典的FedAvg算法:

在该文实现的横向联邦学习中主要有两个角色:客户端和服务器端。服务端的主要功能是将被选择的客户端上传的本地模型进行模型聚合。客户端主要功能是接收服务端的下发指令和全局模型,利用本地数据进行局部模型训练。机构图如下:
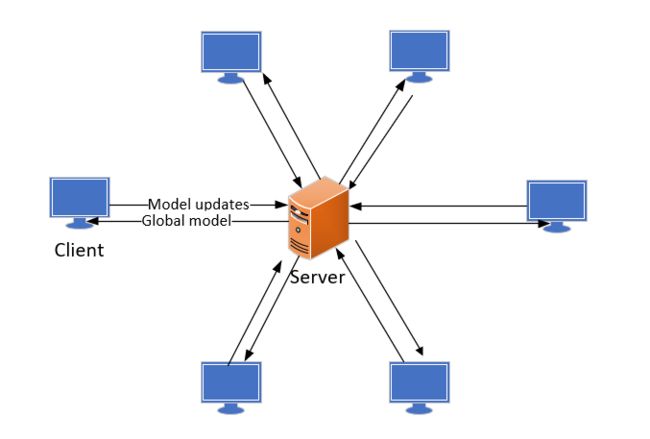
注意本文只是在本地模拟了客户端和服务器端的通信过程,并未在真实的网络环境中实现服务器端和客户端的通信,因此本地模拟的通信时延无实际意义,本实验的目的在于证明联邦学习的有效性以及与集中式学习的性能对比。实际的网络部署,以及通信参数的隐私保护都需要进一步的探索,FATE中实现了单机部署和集群部署也对隐私保护的方法进行了挖掘,感兴趣的读者可以自行在FATE官网学习。
一、环境配置
本章的代码运行需要首先安装Python、Pytorch环境,并下载Cifar10数据集放置到data文件夹下面。
1. 下载Anaconda
Anaconda的下载直接在官网下载即可,不再赘述。
2. 下载显卡对应的CUDA
我电脑的配置如下:
| 系统 | CPU | GPU | CUDA | cuDNN |
|---|---|---|---|---|
| win10 | intel i5 10210U | MX350 | 10.2 | 7.6.5 |
首先查看显卡支持的CUDA版本号:打开英伟达控制面板→帮助→系统信息→组件,查看CUDA版本:
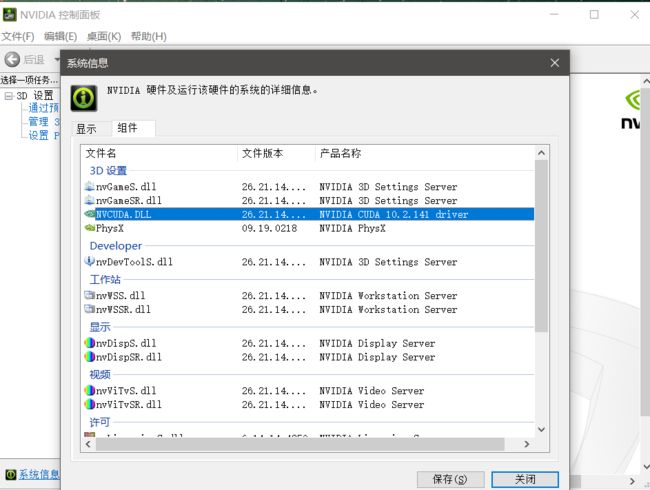
到英伟达官网下载对应的CUDA版本。我下载的版本是CUDA10.2。
这里提醒一下最好选择离线安装,在线安装版本安装过程巨慢。我用IDM将离线版本下载下来在电脑上进行了本地安装。注意选择自定义安装并取消勾选 Visual Studio Integration。安装路径默认即可。
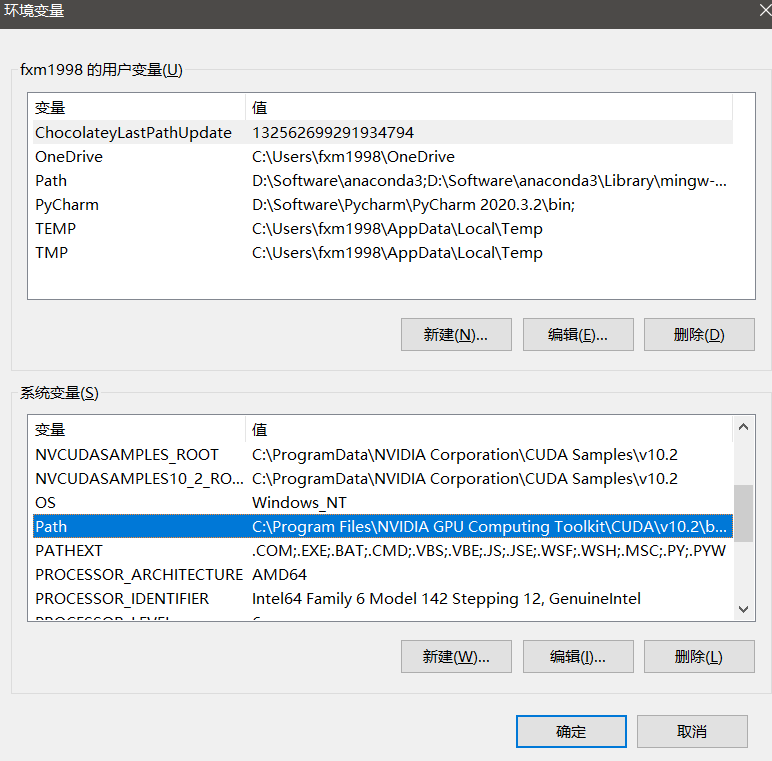
安装完成后配置CUDA的环境变量:
在Path中手动添加如下路径:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\lib\x64
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\extras\CUPTI\lib64
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.2\bin\win64
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.2\common\lib\x64
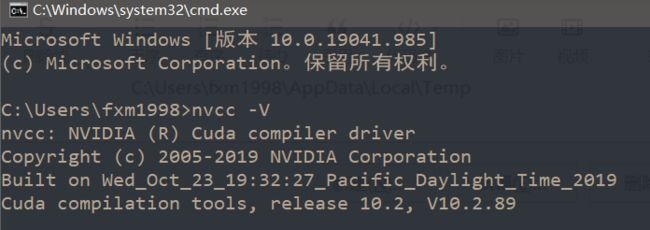
验证CUDA是否安装成功:
3. 安装cuDNN
到官网下载与CUDA对应的cuDNN,我下载的是 cuDNN v7.6.5。需要登录账号下载,没有账号注册即可。
下载之后,解压缩,将CUDNN文件夹里面的bin、include、lib文件直接复制到CUDA的安装目录(默认路径:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2)下,直接覆盖安装即可。
4. 配置pytorch-gpu环境
打开Anaconda prompt命令行。
常用环境管理的conda命令有:
conda env -h #查看环境管理的全部命令帮助
conda info --envs
conda env list #列举当前所有环境
conda create --name your_env_name #创建环境
conda create --name your_env_name python=3.5 #创建指定python版本的环境
conda activate your_env_name #进入某个环境
conda deactivate #退出某个环境
conda create --name new_env_name --clone old_env_name #复制某个环境
conda remove --name your_env_name --all #删除某个环境
常用包管理命令:
conda list #列举当前环境已安装的抱
conda install -n env_name package_name #安装包
conda remove package_name #删除包
conda源安装十分缓慢,建议换成清华源,主要操作:
#查看当前conda配置
conda config --show channels
#设置通道
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
#设置搜索是显示通道地址
conda config --set show_channel_urls yes
# conda install pytorch torchvision cudatoolkit=10.0 # 删除安装命令最后的 -c pytorch,才会采用清华源安装。
不建议在base环境中直接安装pytorch,建议新建虚拟环境再安装pytorch,有gpu就下载gpu版本没有则下载cpu版本。
# 创建pytorch_gpu环境
conda create --name pytorch_gpu python=3.7
conda activate pytorch_gpu
conda install pandas
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch
# 注意要去掉后面的-c pytorch,否则是从pytorch源下载,过程缓慢;去掉之后从清华源下载
conda install pytorch torchvision torchaudio cudatoolkit=10.2
测试安装是否成功,可以正常打印出版本号则没问题。测试能否用GPU加速,返回True。

二、用Python从零实现横向联邦图像分类
运行代码
在本章项目地址下载代码到本地。
本项目的代码结构如下:
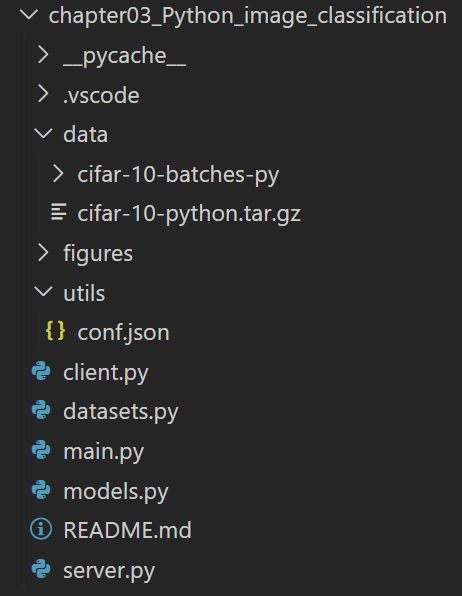
示例代码使用横向联邦来实现了对cifar10图像数据集的分类,模型使用的是ResNet-18.
进入上述创建的pytorch_pgu环境,在本地代码目录下在命令行运行命令:
python main.py -c ./utils/conf.json
此时代码会一轮轮的跑起来,运行信息如下:
从上述运行信息以及下面conf.json中的配置信息很清晰的看出本地模型训练迭代次数local_epochs=3,全局模型迭代次数global_epochs=20,每一轮迭代时,服务端会从所有客户端中挑选k=5个客户端参与训练。
配置信息在conf.json中定义,示例的配置文件如下:
{
"model_name" : "resnet18",
#本地和全局使用的模型类型
"no_models" : 10,
#客户端数量
"type" : "cifar",
#数据集信息,为了模拟横向联邦,数据集按照样本维度划分成不重叠的数据,每一份存放在本地客户端进行本地训练。
"global_epochs" : 20,
#全局迭代次数,即服务端与客户端的通信迭代次数。通常会设置一个最大的全局迭代次数,但在训练过程中,只要模型收敛,训练会提前停止。
"local_epochs" : 3,
#本地模型训练迭代次数。每一个客户端的本地迭代次数可以相同,可以不同。
"k" : 5,
#每一轮迭代时,服务端会从所有客户端中挑选k个客户端参与训练。每一次迭代都从所有的客户端中挑选部分客户端进行本地训练,不影响全局训练效果,提升了训练效率。
"batch_size" : 32,
#本地训练每一轮的样本数
#本地训练的超参数设置
"lr" : 0.001,
"momentum" : 0.0001,
"lambda" : 0.1
}
当然这只是简单的运行起了代码,我们要对代码进行深入理解。
1. 数据集
数据集设置在datasets.py中进行了定义:
import torch
from torchvision import datasets, transforms
def get_dataset(dir, name):
if name=='mnist':
train_dataset = datasets.MNIST(dir, train=True, download=True, transform=transforms.ToTensor())
eval_dataset = datasets.MNIST(dir, train=False, transform=transforms.ToTensor())
elif name=='cifar':
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
#随机切割中心点,size为32*32的正方形,填充4个像素
transforms.RandomHorizontalFlip(),
#随机水平翻转给定的PIL.Image,概率为0.5。即:一半的概率翻转,一半的概率不翻转。
transforms.ToTensor(),
#把一个取值范围是[0,255]的PIL.Image或者shape为(H,W,C)的numpy.ndarray,转换成形状为[C,H,W],取值范围是[0,1.0]的torch.FloadTensor
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
#给定均值:(R,G,B) 方差:(R,G,B),将会把Tensor正则化。即:Normalized_image=(image-mean)/std。
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
# 获取数据集并对图片进行transforms
train_dataset = datasets.CIFAR10(dir, train=True, download=True,
transform=transform_train)
eval_dataset = datasets.CIFAR10(dir, train=False, transform=transform_test)
return train_dataset, eval_dataset
根据conf.json中的type字段获取数据集。此处使用torchvision的datasets内置的cifar10数据集。若使用其他数据集可自行修改。
上述torchvision的datasets的参数简要说明如下,相信说明请查看pytorch官方文档。
#MNIST
datasets.MNIST(root, train=True, transform=None, target_transform=None, download=False)
#参数说明:
#- root :processed/training.pt 和 processed/test.pt 的主目录
#- train :True = 训练集, False = 测试集
#- download :True = 从互联网上下载数据集,并把数据集放在root目录下. 如果数据集之前下载过,将处理过的数据(minist.py中有相关函数)放在processed文件夹下。
#CIFAR10、CIFAR100
datasets.CIFAR10(root, train=True, transform=None, target_transform=None, download=False)
datasets.CIFAR100(root, train=True, transform=None, target_transform=None, download=False)
参数说明:
#- root : cifar-10-batches-py 的根目录
#- train : True = 训练集, False = 测试集
#- download : True = 从互联上下载数据,并将其放在root目录下。如果数据集已经下载,什么都不干。
2. 服务器端
横向联邦学习的服务端的主要功能是将被选择的客户端上传的本地模型进行模型聚合。但这里需要特别注意的是,事实上,对于一个功能完善的联邦学习框架,比如我们将在后面介绍的FATE平台,服务端的功能要复杂得多,比如服务端需要对各个客户端节点进行网络监控、对失败节点发出重连信号等。本实验在本地模拟的,不涉及网络通信细节和失败故障等处理,因此不讨论这些功能细节,仅涉及模型聚合功能。
下面我们首先定义一个服务端类Server,类中的主要函数包括以下几个。
- 定义构造函数。
在构造函数中,服务端的工作包括:
第一,将配置信息拷贝到服务端中;
第二,按照配置中的模型信息获取模型,这里我们使用torchvision的models模块内置的ResNet-18模型。
class Server(object):
def __init__(self, conf, eval_dataset):
self.conf = conf
self.global_model = models.get_model(self.conf["model_name"])
self.eval_loader = torch.utils.data.DataLoader(eval_dataset,
batch_size=self.conf["batch_size"], shuffle=True)
其中dataloader的参数说明如下:
class torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, num_workers=0, collate_fn=<function default_collate>, pin_memory=False, drop_last=False)
#dataset (Dataset) – 加载数据的数据集。
#batch_size (int, optional) – 每个batch加载多少个样本(默认: 1)。
#shuffle (bool, optional) – 设置为True时会在每个epoch重新打乱数据(默认: False).
#sampler (Sampler, optional) – 定义从数据集中提取样本的策略。如果指定,则忽略shuffle参数。
#num_workers (int, optional) – 用多少个子进程加载数据。0表示数据将在主进程中加载(默认: 0)
#collate_fn (callable, optional) –
#pin_memory (bool, optional) –
#drop_last (bool, optional) – 如果数据集大小不能被batch size整除,则设置为True后可删除最后一个不完整的batch。如果设为False并且数据集的大小不能被batch size整除,则最后一个batch将更小。(默认: False)
- 定义模型聚合函数。
前面我们提到服务端的主要功能是进行模型的聚合,因此定义构造函数后,我们需要在类中定义模型聚合函数,通过接收客户端上传的模型,使用聚合函数更新全局模型。聚合方案有很多种,本节我们采用经典的FedAvg算法。
def model_aggregate(self, weight_accumulator):
for name, data in self.global_model.state_dict().items():
# state_dict()存的是每一层每一个参数名字和数值的键值对
update_per_layer = weight_accumulator[name] * self.conf["lambda"]
if data.type() != update_per_layer.type():
data.add_(update_per_layer.to(torch.int64))
else:
data.add_(update_per_layer)
- 定义模型评估函数。
对当前的全局模型,利用评估数据评估当前的全局模型性能。通常情况下,服务端的评估函数主要对当前聚合后的全局模型进行分析,用于判断当前的模型训练是需要进行下一轮迭代、还是提前终止,或者模型是否出现发散退化的现象。根据不同的结果,服务端可以采取不同的措施策略。
def model_eval(self):
self.global_model.eval()
total_loss = 0.0
correct = 0
dataset_size = 0
for batch_id, batch in enumerate(self.eval_loader):
data, target = batch
dataset_size += data.size()[0]
if torch.cuda.is_available():
data = data.cuda()
target = target.cuda()
output = self.global_model(data)
total_loss += torch.nn.functional.cross_entropy(output, target,
reduction='sum').item() # sum up batch loss
pred = output.data.max(1)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
acc = 100.0 * (float(correct) / float(dataset_size))
total_l = total_loss / dataset_size
return acc, total_l
3. 客户端
横向联邦学习的客户端主要功能是接收服务端的下发指令和全局模型,利用本地数据进行局部模型训练。与前一节一样,对于一个功能完善的联邦学习框架,客户端的功能同样相当复杂,比如需要考虑本地的资源(CPU、内存等)是否满足训练需要、当前的网络中断、当前的训练由于受到外界因素影响而中断等。读者如果对这些设计细节感兴趣,可以查看当前流行的联邦学习框架源代码和文档,比如FATE,获取更多的实现细节。
本节我们仅考虑客户端本地的模型训练细节。我们首先定义客户端类Client,类中的主要函数包括以下两种。
- 定义构造函数。
在客户端构造函数中,客户端的主要工作包括:
首先,将配置信息拷贝到客户端中;
然后,按照配置中的模型信息获取模型,通常由服务端将模型参数传递给客户端,客户端将该全局模型覆盖掉本地模型;
最后,配置本地训练数据,在本案例中,我们通过torchvision的datasets模块获取cifar10数据集后按客户端ID切分,不同的客户端拥有不同的子数据集,相互之间没有交集。
class Client(object):
def __init__(self, conf, model, train_dataset, id = -1):
self.conf = conf
self.local_model = model
self.client_id = id
self.train_dataset = train_dataset
all_range = list(range(len(self.train_dataset)))
data_len = int(len(self.train_dataset) / self.conf['no_models'])
train_indices = all_range[id * data_len: (id + 1) * data_len]
self.train_loader = torch.utils.data.DataLoader(self.train_dataset,
batch_size=conf["batch_size"], sampler=torch.utils.data.sampler.SubsetRandomSampler(train_indices))
- 定义模型本地训练函数。
本例是一个图像分类的例子,因此,我们使用交叉熵作为本地模型的损失函数,利用梯度下降来求解并更新参数值,实现细节如下面代码块所示。
def local_train(self, model):
for name, param in model.state_dict().items():
self.local_model.state_dict()[name].copy_(param.clone())
optimizer = torch.optim.SGD(self.local_model.parameters(), lr=self.conf['lr'],
momentum=self.conf['momentum'])
self.local_model.train()
for e in range(self.conf["local_epochs"]):
for batch_id, batch in enumerate(self.train_loader):
data, target = batch
if torch.cuda.is_available():
data = data.cuda()
target = target.cuda()
optimizer.zero_grad()
output = self.local_model(data)
loss = torch.nn.functional.cross_entropy(output, target)
loss.backward()
optimizer.step()
print("Epoch %d done." % e)
diff = dict()
for name, data in self.local_model.state_dict().items():
# 计算本地模型和全局模型的差,即本地模型的更新
diff[name] = (data - model.state_dict()[name])
return diff
4. 聚合
当配置文件、服务端类和客户端类都定义完毕,我们将这些信息组合起来。首先,读取配置文件信息。
with open(args.conf, 'r') as f:
conf = json.load(f)
接下来,我们将分别定义一个服务端对象和多个客户端对象,用来模拟横向联邦训练场景。
train_datasets, eval_datasets = datasets.get_dataset("./data/", conf["type"])
server = Server(conf, eval_datasets)
clients = []
for c in range(conf["no_models"]):
clients.append(Client(conf, server.global_model, train_datasets, c))
每一轮的迭代,服务端会从当前的客户端集合中随机挑选一部分参与本轮迭代训练,被选中的客户端调用本地训练接口local_train进行本地训练,最后服务端调用模型聚合函数model_aggregate来更新全局模型,代码如下所示。
for e in range(conf["global_epochs"]):
candidates = random.sample(clients, conf["k"])
weight_accumulator = {}
for name, params in server.global_model.state_dict().items():
weight_accumulator[name] = torch.zeros_like(params)
for c in candidates:
diff = c.local_train(server.global_model)
for name, params in server.global_model.state_dict().items():
weight_accumulator[name].add_(diff[name])
server.model_aggregate(weight_accumulator)
acc, loss = server.model_eval()
print("Epoch %d, acc: %f, loss: %f\n" % (e, acc, loss))
5. Resnet18在cifar10上的联邦学习与中心化训练的效果对比
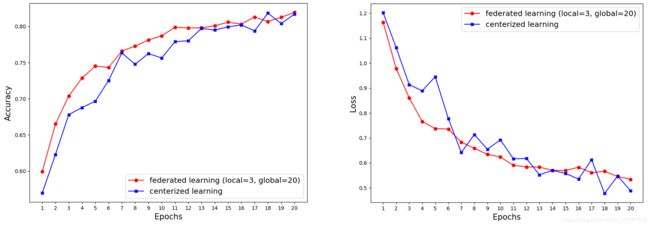
官方示例的配置是Resnet18在cifar10上的模型评估。
- 联邦训练配置:一共10台客户端设备(
no_models=10),每一轮任意挑选其中的5台参与训练(k=5), 每一次本地训练迭代次数为3次(local_epochs=3),全局迭代次数为20次(global_epochs=20)。 - 集中式训练配置:我们不需要单独编写集中式训练代码,只需要修改联邦学习配置既可使其等价于集中式训练。具体来说,我们将客户端设备no_models和每一轮挑选的参与训练设备数k都设为1即可。这样只有1台设备参与的联邦训练等价于集中式训练。其余参数配置信息与联邦学习训练一致。
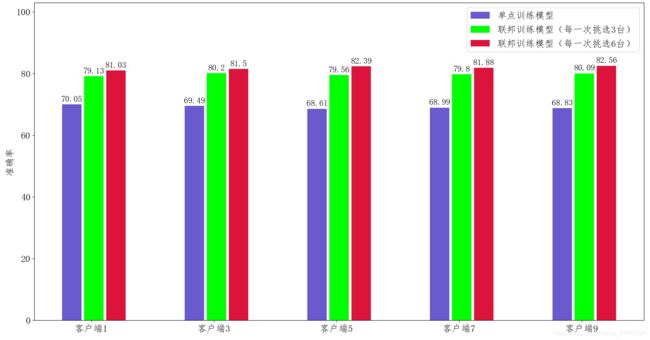 图中的单点训练只的是在某一个客户端下,利用本地的数据进行模型训练的结果。
图中的单点训练只的是在某一个客户端下,利用本地的数据进行模型训练的结果。
- 我们看到单点训练的模型效果(蓝色条)明显要低于联邦训练 的效果(绿色条和红色条),这也说明了仅仅通过单个客户端的数据,不能够 很好的学习到数据的全局分布特性,模型的泛化能力较差。
- 此外,对于每一轮 参与联邦训练的客户端数目(k 值)不同,其性能也会有一定的差别,k 值越大,每一轮参与训练的客户端数目越多,其性能也会越好,但每一轮的完成时间也会相对较长。
6. Resnet18在MNIST上的联邦学习与中心化训练的效果对比
为了更好地展现联邦学习和中心化训练之间相互逼近的效果,使用MNIST数据集进行了训练。
需要注意的是resnet18输入的CHW是(3, 224, 224),而mnist数据集中单张图片CHW是(1, 28, 28)。如果我们想使用resnet18 使用迁移==迁移学习来训练mnist数据集,需要对MNIST数据集进行预处理。
在datasets.py中加入transform变换:
import torch
from torchvision import datasets, transforms
def get_dataset(dir, name):
if name=='mnist':
# 对原始 MNIST图像进行预处理,主要是将通道数从1改成3,然后修改尺寸和正则化
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.Grayscale(3),
transforms.ToTensor(),
transforms.Normalize((0.1307,0.1307,0.1307), (0.3081,0.3081,0.3081)),
])
train_dataset = datasets.MNIST(dir, train=True, download=True, transform=transform)
eval_dataset = datasets.MNIST(dir, train=False, transform=transform)
resnet18是在imagenet上训练的,输出特征数是1000;而对于mnist来说,需要分10类,因此要在models.py中改一下全连接层的输出:
if name == "resnet18":
model = models.resnet18(pretrained=pretrained)
# 使用mnist数据集时
# resnet18是在imagenet上训练的,输出特征数是1000;而对于mnist来说,需要分10类,因此要改一下全连接层的输出。
in_features = model.fc.in_features
model.fc = torch.nn.Linear(in_features, 10)
conf.json修改为:
{
"model_name" : "resnet18",
"no_models" : 10,
"type" : "mnist",
"global_epochs" : 20,
"local_epochs" : 3,
"k" : 5,
"batch_size" : 32,
"lr" : 0.0001, //使用了迁移学习,所以学习率调小一点,从示例的1e-3改为1e-4。
"momentum" : 0.0001,
"lambda" : 0.1
}
resnet18相较于普通的一两层卷积网络来说已经比较深了,且mnsit数据集还是挺大的,总共有7万张图片。所以在服务器上使用GeForce GTX 1080 Ti来训练(资金有限![]() )。然后得到了
)。然后得到了Resnet18在MNIST在中心化学习和联邦学习训练的Accuracy和Loss的对比图像:
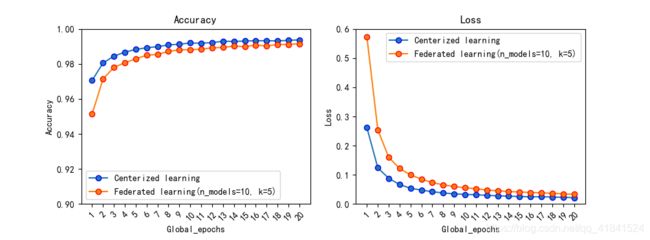
我们可以看出联邦学习的模型性能已经无限逼近了中心化学习的模型性能。那这个时候我们就要想到联邦学习的最主要特征是什么,“数据不离本地”。我们在做到这一点充分保护了用户的数据安全的基础上,达到了集中式学习的效果,这一点是值得肯定的。
联邦学习真正实现了“草不动羊动”,虽然这仅是一个简单的小例子,实际的应用和安全需求、激励机制、去中心化机制等问题都需要进行进一步研究。
总结
本实验在本地模拟了横向联邦图像识别模型,证明了联邦学习的有效性以及与集中式学习相媲美的准确性。当然,本实验的模拟过于简陋,针对参数的保护,参数通信都需要进一步深挖。但作为我们实战专栏的第一个小case,横向联邦学习的概念大家肯定已经理解得比较透彻了。
下面的章节我们将学习微众银行的FATE架构,从更复杂更全面的角度来进行联邦学习的实战。
