【Image Captioning】Improve Image Captioning by Estimating the Gazing Patterns from the Caption
Improve Image Captioning by Estimating the Gazing Patterns from the Caption
Department of Computer Science, The George Washington University, CVPR 2022
Abstract
CNN等神经网络模型中提取的图像特征中产生类人描述方面达到了良好的性能。然而,之前没有一种明确的方法能够反映人类对图像的感知,比如凝视模式。在本文中,作者假设在image caption中的名词(即实体)及其顺序反映了人类的凝视模式和感知。为此,作者从caption中的单词中预测注视序列gaze sequence,然后训练一个指针网络pointer network来学习在新图像中给定一组object后自动生成gaze sequence。作者将pointer network生成的gaze sequence与现有的image caption模型融合,并研究其性能。实验表明,当使用object的gaze sequence作为额外特征时,image caption模型的性能显著提高。
1. Introduction
image caption是自动生成图像的human-like自然语言描述的过程。其能为医生提供指导和帮助视觉受损人士理解视觉内容。然而,image caption并不是一项简单的任务,它还受到了人类认知的启发,即图像感知(理解图像内容,包括物体及其关系)和句子规划和生成(用自然语言描述图像)的启发。
为了生成一个image caption,目前最先进的模型严重依赖于CNN和R-CNN来提取视觉特征作为模型的输入。这些研究仅仅依赖于这些特征,而没有明确地建模图像的细微差别和caption之间的关系。最近的研究提出了不同的机制来解决这个问题,注意机制可以隐式地学习图像中实体和区域之间的关系。也有研究将图卷积网络集成到图像编码器中以学习图像中对象之间的关系。虽然这些模型可以成功地生成human-like caption,但这些图像并不能用于字幕的目的。具体来说,CNN和R-CNN分别构建和训练用于识别和检测目的,但这些图像并不是为了caption而被感知的。研究表明,在检测和描述任务中,人类的感知(特别是凝视模式)是不同的。因此,图像编码器可以通过从反映图像最初描述时的凝视行为的caption中获得的显式视觉特征来增强。
一些工作利用凝视信息来提高image caption模型中的注意力。这些研究表明了将凝视信息整合到image caption中的有效性。然而,凝视信息是从眼球追踪系统中提取的,这是昂贵的,并不是所有的研究人员都可以获得的,目前并没有研究提出一种在没有使用眼球追踪系统的情况下为看不见的图像生成注视信息的方法。在本文中,作者假设当人类最初生成由心理语言学研究驱动的caption时,caption中提到的实体可以反映人类对图像的感知,这表明单词生成与眼球运动之间存在关系。例如,许多研究人员研究了描述图像的说话者的句子产生,同时跟踪他们的眼球运动。
现有研究说明,凝视物体的顺序与在一个句子(描述)中提及这些物体的顺序是相关联的。caption中提到的实体是人类选择描述的更多的重要对象,它们的顺序反映了人类最初生成标题时对图像(凝视模式)的感知。本文开发了一个基于指针网络的模型,该模型从caption中的实体中学习,自动生成gaze sequence,然后将学习到的gaze sequence集成到image caption模型中。指针网络已被广泛用于排序句子或故事。作者将这种凝视模式作为一个子网络集成到当前的image caption模型中。
贡献如下:
- 直接从说明中提到的实体来估算凝视模式,而不是使用昂贵的眼球追踪系统。
- 提出了基于指针网络的注视模式预测模型,该模型可以自动生成看不见图像的注视模式。
- 提出了一个 model-agnostic的凝视模式子网络,它可以作为一个附加的视觉特征集成到image caption模型中。
2. Related Work

Image Captions. 大多数image caption方法利用CNN对图像进行编码,并将递归神经网络作为语言模型。为了进一步提高图像字幕模型,在image caption模型中引入了注意机制,使图像编码器和语言模型之间有更多的交互。更具体地说,每个区域的重要性得分被计算出来,同时生成一个特定的单词,然后用softmax函数进行归一化;然后将这些分数应用于区域,以反映其在生成该单词中的重要性。图像的区域要么表示为从固定大小网格CNN特征中提取的向量,语义属性,或者表示为从R-CNN检测区域中提取的自下而上的特征。为了生成丰富的图像描述,大部分研究引入了具有多个lstm的从粗到细的多阶段模型,从早期阶段生成粗描述到后期阶段为描述添加细节。此外,Transformer已被用于image caption作为图像编码器或作为语言建模。在这项工作中,我们专注于通过利用可以从caption中学习到的视觉特征来增强基于LSTM的image caption模型。
在image caption模型中,一些工作提出了提高视觉特征的方法,通过将图卷积网络集成到图像编码器。比如整合图像中对象之间的语义和空间关系,或明确地将该关系建模为卷积图中的一个附加节点。
与本文工作类似,Cornia等人和Alahmadi等人集成了在caption中的实体与他们相应的序列或区域集对应的image caption模型。相反,本文学习的凝视序列更有可能是由人类自动描述图像而产生的,且提出的凝视预测模型可以嵌入到不同的image caption模型中,以提高其性能。
Image Captions with Gazing Information.
很少有研究将注视信息结合注意机制来改进image caption模型。注视数据从眼球追踪系统中获得,然后整合到注意力模型中。一些研究将凝视数据汇总成一个静态显著性图,而没有考虑它们的顺序性质。其他研究将顺序注视信息在图像标题中整合,以提高注意。与之前的研究不同,本文从标题中自动提取凝视模式,而不是使用获取成本昂贵的眼球追踪系统。我们使用学习到的凝视数据作为模型的输入,而不是替换或增强注意机制。
3. Model
模型体系结构的概述如图2所示,由两部分组成:1) Gazing Pattern Prediction Model:用来产生gaze sequence;2)Image Caption with Gazing Sequence:融合gaze sequence的image caption模型。
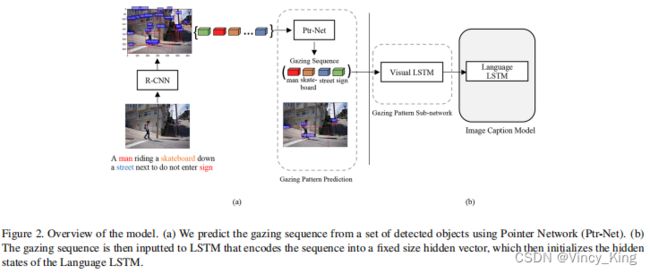
3.1 Gazing Pattern Prediction Model
图像描述由可以在视觉上基于图像区域的单词序列组成。根据这些描述和它们在图像中的基准区域grounding regions,可以构建一个图像区域序列,以反映它们在caption中的顺序,并称之为gazing sequence R。
R = [ r 1 , r 2 , . . . , r n ] R=[r_1,r_2,...,r_n] R=[r1,r2,...,rn]
其中 r t r_t rt是 t t t位置的一个与caption中的一个实体相关联的区域,n是注视区域的数量gazed regions。
给定 m m m个区域 r = [ r o 1 , r o 2 , . . . , r o m ] r = [r_{o_1},r_{o_2},...,r_{o_m}] r=[ro1,ro2,...,rom]的任意顺序 o = [ o 1 , o 2 , . . . , o m ] o=[o_1,o_2,...,o_m] o=[o1,o2,...,om],其中 r r r是R-CNN检测到的区域集合, o o o是它们的任意顺序, m m m是R-CNN检测到的区域数。该小结的目的是通过最大化 P ( o ∗ ∣ r ) P(o^∗|r) P(o∗∣r)找到最接近gold order o ∗ = [ o 1 ∗ , o 2 ∗ , . . . , o n ∗ ] o^∗= [o^∗_1,o^∗_2,...,o^*_n] o∗=[o1∗,o2∗,...,on∗]来找的凝视序列R的顺序 o ^ = [ o 1 ^ , o 2 ^ , . . . , o n ^ ] \hat{o}=[\hat{o_1},\hat{o_2},...,\hat{o_n}] o^=[o1^,o2^,...,on^]
P ( o ∗ ∣ r ) > P ( o ∣ r ) ∀ o ∈ ψ P(o^∗|r)>P(o|r) \forall o \in \psi P(o∗∣r)>P(o∣r)∀o∈ψ
其中 ψ ψ ψ是 o o o的所有排列的集合, n n n是caption中提到的区域数, n ≤ m n≤m n≤m。
3.1.1 Model Features
一个区域 r t r_t rt通过连接三个特征来表示:视觉、文本和空间特征,例如: r t = [ v t ; t t ; l t ] r_t=[v_t;t_t;l_t] rt=[vt;tt;lt]。从Faster R-CNN中提取视觉特征,然后由两个全连接层进行处理,文本特征是对该区域的类标签的glove嵌入,并由一个全连接层进行处理。空间特征是区域边界框的标准化位置和大小。然后通过一个完全连接的层对所连接的特征进行编码。
3.1.2 Pointer Network
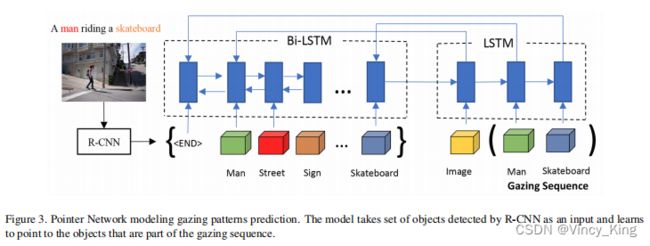
作者使用指针网络对注视模式预测进行建模。指针网络由Bi-LSTM作为编码器,从任意顺序的区域序列中学习特征,而LSTM作为解码器,学习指向区域以生成凝视序列。用从编码器中学习到的特征来初始化解码器中的第一个时间步长。剩余的时间步长使用从上一步学到的信息。解码器还利用来自注意机制的信息,计算所有编码器输入的概率分布;概率最高的区域被选择为位置 i i i中的区域。
h i d , c i = L S T M ( h i − 1 d , c i − 1 , r i ) h_i^d,c_i=LSTM(h^d_{i-1},c_{i-1},r_i) hid,ci=LSTM(hi−1d,ci−1,ri)
u j i = v T t a n h ( W 1 h j e + W 2 h i d ) u_j^i=v^T tanh(W_1h_j^e+W_2h_i^d) uji=vTtanh(W1hje+W2hid)
P ( r i ∣ r i − 1 , . . . , r 0 ) = S o f t m a x ( u i ) P(r_i|r_{i-1},...,r_0)=Softmax(u^i) P(ri∣ri−1,...,r0)=Softmax(ui)
其中 v ∈ R d v∈R^d v∈Rd, W 1 W_1 W1和 W 2 ∈ R d × d W_2∈R^{d×d} W2∈Rd×d可学习参数, j ≤ m j≤m j≤m和 P ( r i ∣ r i − 1 , . . . , r 0 ) P(r_i|r_{i-1},...,r_0) P(ri∣ri−1,...,r0)是时间 i i i下chosen region的概率, u j i u^i_j uji是在输入作为指针输入元素的输出分布。在时间步长 i i i处对解码器的输入是先前预测的区域。在第一个时间步中,输入是图像的特征,因此模型可以在指向第一个区域之前拥有上下文信息。
备注:Pointer Network 计算 Attention 值之后不会把 Encoder 的输出融合,而是将 Attention 作为输入序列 P 中每一个位置输出的概率。这也是为什么本文使用pointer network的原因。
3.2 Image Caption with Gazing Sequence
3.2.1 Model-agnostic Gazing Pattern Sub-network
本文基于LSTM(简称VisualLSTM)以指针网络生成的注视区域序列 [ x 0 , x 1 , x 2 , . . . , x n ] [x_0,x_1,x_2,...,x_n] [x0,x1,x2,...,xn]作为输入,并得到隐藏层向量 h n v = V i s u a l L S T M ( x n , h n − 1 v ) h_n^v=VisualLSTM(x_n,h_{n-1}^v) hnv=VisualLSTM(xn,hn−1v)。其中n为regions的数量。在此基础上,再用一个LSTM(简称LanguageLSTM)进行优化,得到 h e 1 = L a n g u a g e L S T M ( w 1 , h n v ) h_e^1=LanguageLSTM(w_1,h_{n}^v) he1=LanguageLSTM(w1,hnv),其中 w 1 w_1 w1是caption第一个word 的word embedding。
3.2.2 Integrating Image Captioning Models with Gazing Patterns

作者整合凝视模式子网络三个基线image caption模型:不应用任何注意的Neural Image Captioning (NIC),应用注意固定网格CNN特性的Adaptive attention model (Ada-att)和应用注意自下而上特性的Attention on attention model (AoA)。
这三个模型都使用LSTM作为编码器来生成caption。在NIC中,图像被编码到从CNN的最后一层提取的特征向量中。作者选择NIC作为基线之一,以展示将凝视模式集成到一个简单模型中的有效性,并将其性能与注意力模型进行比较。另一方面,Ada-att和AoA都是基于注意力的模型。在生成一个单词时,Ada-att动态地决定是否参加卷积图中的一个区域。AoA通过添加一个加权最终注意信息的注意门来扩展注意操作符。
4. Experiments
4.1 Datasets
对于gaze sequence prediction模型,使用公开可用的COCO entities release,其为COCO图像caption数据集提供的caption中的每个实体提供了一个带有边界框和类标签的区域。这些区域与预先训练的快速R-CNN模型检测到的区域相连,在ImageNet 和Visual Genome数据集上训练ResNet-101,以提供自下而上的特征,获得每个区域2048维向量。注视模式预测模型的输入是被检测区域的shuffled set。
对于image caption模型,使用MS COCO数据集,其包含123,287张图像,作者剔除了在整个训练语料库中出现次数小于5次的单词。
4.2 Conditions
+GP: gazing pattern generated by pointer network
+GT-Seq: ground truth gazing sequence
+GT-Set: the ground truth gazing set extracted from the captions
4.3 Image Captions Results

Gazing Pattern Sub-network Performance.
-
所有的image caption模型都在一定程度上受益于凝视模式子网络。
-
在NIC(NIC+GP)中集成凝视子网络时,所有指标的显著改善。
Attention vs. Gazing Pattern
-
NIC+GP在注意力方面略优于NIC。
-
NIC+GT-Seq与NIC+Att性能存在显著差异。
-
NIC+GT-Seq的性能与Ada-att+GT-Seq相当,但NIC+GT-Seq仍然低于AoA。
Ground Truth Gazing Sequence and Set.
- 用两种凝视模式来评估image caption模型的性能:the ground truth gazing sequence and the ground truth gazing set。这两个模式都包含相同的object。ground truth gazing sequence(+GT-Seq)包含了根据其在caption中的位置进行排序的object,ground truth gazing set(+GT-Set)是在caption中提到的一组object。
- 该实验的目的是测试被注视的序列中物体的顺序是否会对性能产生影响。使用GT-Set训练模型显著提高了基线的性能,因为模型有关于更有可能被描述的对象的信息,而不管它们的顺序如何。这表明了在凝视模式中包含凝视对象的重要性。从GT-Seq中可看出在凝视模式中保持顺序可以进一步提高性能。
- AoA+GP的性能与其使用ground truth注视模式的性能相当。

Comparison with state-of-the-art model.
- 比较AoA+GP与最先进的模型在offline COCO Karpathy test split上的性能。我们报告了两种优化的结果:交叉熵损失和CIDEr优化。
4.4 Gazing Sequence Model results
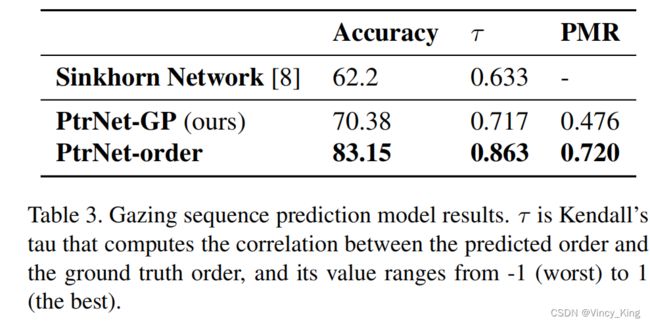
- PtrNet-GP的性能显著优于Sinkhorn network。指针网络选择重要的对象,然后根据caption中的实体顺序对它们进行排序,而Sinkhorn网络只对预先选择的对象进行排序。
- 为了进行公平的比较,作者训练了指针网络模型对caption PtrNet-order中已经提到的区域进行排序。PtrNet-order的性能显著优于Sinkhorn网络。
4.5 Qualitative Results

- 虽然AoA可以生成与图像相关的字幕,但添加凝视模式可以产生更准确的描述。
5. Conclusion
本文我们提出了一个凝视子网络gaze sub-network,它将人类感知作为image caption模型的附加视觉特征进行建模。首先从caption中的实体中估计凝视序列gaze sequence,然后采用自动产生类似序列的指针网络point network。实验表明,在图像编码器中添加一个凝视模式作为一个附加的特征提高了image caption模型的性能。
6. Limitation
- gaze sequence prediction模型的数据集和image caption的数据集不一样,并不能确保gaze sequence prediction训练出来的模型能够很好的去预测image caption中的gaze sequence。
- 虽然可以不使用昂贵的眼动仪,但并没有理论和实验证明这种预测方式是否真的符号人类浏览过程。