Java 训练使用 XGBoost
Java 训练使用 XGBoost
背景
有个小项目需要使用xgboost进行数据分类。虽然已经在python训练好了模型,但是使用java来加载python的模型比较麻烦(pmml文件方式)。java也有XGboost的相关包,本文简单介绍一下。
下载xgboost4j jar包
地址:http://github.com/criteo-forks/xgboost-jars/releases/tag/ (不同操作系统有不同的包,下载需注意)
注意:也可以直接在maven仓库下载xgboost4j的包或者使用pom引入,但是windows下会由于缺少xgboost4j.dll文件而运行失败。
导入jar包
开发软件(Intellij) :File–>project structure–>Libraries–>"+" 导入刚下载的xgboost包。
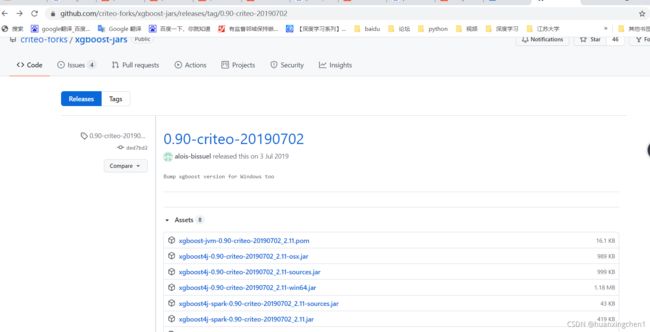
选择与操作系统相符的版本。(本文用的0.90–win64).
数据准备
数据集形式
java版xgboost数据形式可以有两种。
-
1 1:5.7 2:2.6 3:3.5 4:1.0 0 1:4.5 2:2.3 3:1.3 4:0.3 0 1:5.1 2:3.4 3:1.5 4:0.2 1 1:5.6 2:2.5 3:3.9 4:1.1 0 1:4.8 2:3.4 3:1.6 4:0.2其中第一列是类别。后面是特征的索引和特征值(本文用的方式)。
-
0,5.0,3.3,1.4,0.2 1,6.1,2.8,4.0,1.3 0,5.4,3.4,1.7,0.2 0,4.9,3.1,1.5,0.1 0,4.6,3.6,1.0,0.2其中第一列是类别。后面是特征值。
数据集准备
可以从sklearn中去鸢尾花数据集进行试验。
from numpy import random
import numpy as np
from sklearn.datasets import load_iris
data = load_iris()["data"]
target = load_iris()["target"]
target = target.reshape(-1, 1)
# 拼接,取前两类(二分类)
x_data = np.hstack((target, data))
x_data = x_data[x_data[:, 0] <= 1]
# 打乱顺序
random.shuffle(x_data)
# 生成训练集和测试集
train_len = int(len(x_data) * 0.8)
train_data = x_data[0: train_len]
test_data = x_data[train_len:]
# with open("./data/train.txt", "w", encoding="utf8") as w:
# for line in train_data:
# w.write(",".join([str(x) for x in line]) + "\n")
# with open("./data/test.txt", "w", encoding="utf8") as w:
# for line in test_data:
# w.write(",".join([str(x) for x in line]) + "\n")
# 保存数据成文本
with open("./data/train.txt", "w", encoding="utf8") as w:
for line in train_data:
line_w = ""
for i in range(len(line)):
if i == 0:
line_w = line_w + str(int(line[i])) + " "
else:
line_w = line_w + str(i) + ":" + str(line[i]) + " "
w.write(line_w + "\n")
with open("./data/test.txt", "w", encoding="utf8") as w:
for line in test_data:
line_w = ""
for i in range(len(line)):
if i == 0:
line_w = line_w + str(int(line[i])) + " "
else:
line_w = line_w + str(i) + ":" + str(line[i]) + " "
w.write(line_w + "\n")
上面就生成了一个训练集train.txt和一个测试集test.txt。
Java训练xgboost
把数据集放在resources目录下。
package xgboost_test;
import ml.dmlc.xgboost4j.java.Booster;
import ml.dmlc.xgboost4j.java.DMatrix;
import ml.dmlc.xgboost4j.java.XGBoost;
import ml.dmlc.xgboost4j.java.XGBoostError;
import java.util.HashMap;
import java.util.Map;
public class train01 {
private static DMatrix trainMat = null;
private static DMatrix testMat = null;
public static void main(String[] args) throws XGBoostError {
try {
trainMat = new DMatrix("src/main/resources/data/train.txt");
} catch (XGBoostError xgBoostError) {
xgBoostError.printStackTrace();
}
System.out.println("111");
try {
testMat = new DMatrix("src/main/resources/data/test.txt");
} catch (XGBoostError xgBoostError) {
xgBoostError.printStackTrace();
}
Map<String, Object> params = new HashMap<String, Object>() {
{
put("eta", 0.1);
put("max_depth", 3);
put("objective", "binary:logistic");
put("eval_metric", "logloss");
}
};
Map<String, DMatrix> watches = new HashMap<String, DMatrix>() {
{
put("train", trainMat);
put("test", testMat);
}
};
int nround = 100;
try {
Booster booster = XGBoost.train(trainMat, params, nround, watches, null, null);
booster.saveModel("src/main/resources/model.bin");
} catch (XGBoostError xgBoostError) {
xgBoostError.printStackTrace();
}
}
}
Java加载xgboost进行预测
在训练过程中会生成一个xgboost模型,可以加载进行预测。
package xgboost_test;
import ml.dmlc.xgboost4j.java.Booster;
import ml.dmlc.xgboost4j.java.DMatrix;
import ml.dmlc.xgboost4j.java.XGBoost;
import ml.dmlc.xgboost4j.java.XGBoostError;
public class predict01 {
public static void main(String[] args) throws XGBoostError {
// float[] data = new float[] {1.0f, 6.1f,3.0f,4.6f,1.4f};
// 第一列没有影响
float[] data = new float[] {0.0f, 4.6f,3.1f,1.5f,0.2f};
// 预测数据的行数
int nrow = 1;
// 预测数据的列数(特征数+1(类别))
int ncol = 5;
DMatrix dMatrix = new DMatrix(data, nrow, ncol);
Booster booster = XGBoost.loadModel("src/main/resources/model.bin");
float[][] predicts = booster.predict(dMatrix);
for (float[] array: predicts) {
for (float values: array) {
System.out.print(values + " ");
}
System.out.println();
}
}
}
结果:
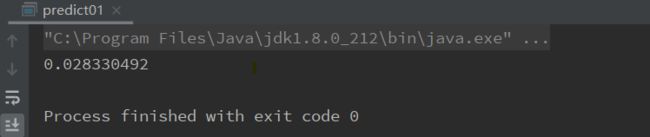
自己的理解:输出结果可以理解为该样本类别为1的概率。此处小于0.5,即类别为0。符合测试集的类别(可以用测试集测试)。如果有大神知道可以指正一下。
扩展
如果需要预测多分类。需要在训练参数中put(“objective”, “binary:logistic”);修改为put(“objective”, “multi:softmax”),并设置需要类别数: put(“num_class”, “3”) 以及将评价标准改为put(“eval_metric”, “mlogloss”)。该情况下,预测可以直接得到类别标签。