傻瓜攻略(十二)——MATLAB实现偏最小二乘回归PLS
这一定是一篇真正的傻瓜攻略,原理为根,算法为骨,应用为肉,傻瓜为皮。
本文主要介绍偏最小二乘回归的基本实现,主要内容基于司守奎《数学建模算法与应用》第11章,在其基础上进行优化。
偏最小二乘回归分析
偏最小二乘回归是回归分析方法的一种,其可以进行多对多线性回归建模,特别当两组变量的个数很多,且都存在多重相关性,而观测数据的数量(样本量)又较少时,用偏最小二乘回归建立的模型具有传统的经典回归分析等方法所没有的优点。
偏最小二乘回归分析在建模过程中集中了主成分分析、典型相关分析和线性回归分析方法的特点,因此在分析结果中,除了可以提供一个更为合理的回归模型外,还可以同时完成一些类似于主成分分析和典型相关分析的研究内容,提供一些更丰富、深入的信息。
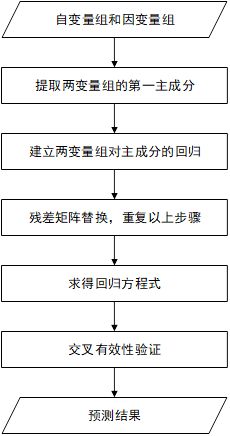
建模步骤
偏最小二乘回归分析的简单步骤如下图所示
代码实现
将以下数据保存到txt文件中,命名为pz.txt,作为分析的对象。
191 36 50 5 162 60
189 37 52 2 110 60
193 38 58 12 101 101
162 35 62 12 105 37
189 35 46 13 155 58
182 36 56 4 101 42
211 38 56 8 101 38
167 34 60 6 125 40
176 31 74 15 200 40
154 33 56 17 251 250
169 34 50 17 120 38
166 33 52 13 210 115
154 34 64 14 215 105
247 46 50 1 50 50
193 36 46 6 70 31
202 37 62 12 210 120
176 37 54 4 60 25
157 32 52 11 230 80
156 33 54 15 225 73
138 33 68 2 110 43
首先是数据处理,进行标准化;
%% 数据处理
ab0=load('pz.txt'); %原始数据存放在纯文本文件pz.txt中
mu=mean(ab0);sig=std(ab0); %求均值和标准差
rr=corrcoef(ab0); %求相关系数矩阵
ab=zscore(ab0); %数据标准化
a=ab(:,[1:3]); %提出标准化后的自变量数据
b=ab(:,[4:end]); %提出标准化后的因变量数据
通过提取成分的贡献率确定要用的主成分个数,即ncomp。也可以跳过这一步,直接指定ncomp数值进行下一步。这个的具体数值要根据效果而定,选的越多效果越好(应该是)。
%% 判断提出成分对的个数
[XL,YL,XS,YS,BETA,PCTVAR,MSE,stats] =plsregress(a,b);
xw=a\XS; %求自变量提出成分的系数,每列对应一个成分,这里xw等于stats.W
yw=b\YS; %求因变量提出成分的系数
a_0=PCTVAR(1,:);b_0=PCTVAR(2,:);% 自变量和因变量提出成分的贡献率
a_1=cumsum(a_0);b_1=cumsum(b_0);% 计算累计贡献率
i=1;%赋初始值
while ((a_1(i)<0.9)&(a_0(i)>0.05)&(b_1(i)<0.9)&(b_0(i)>0.05)) % 提取主成分的条件
i=i+1;
end
ncomp=i;% 选取的主成分对的个数
fprintf('%d对成分分别为:\n',ncomp);% 打印主成分的信息
for i=1:ncomp
fprintf('第%d对成分:\n',i);
fprintf('u%d=',i);
for k=1:size(a,2)%此处为变量x的个数
fprintf('+(%f*x_%d)',xw(k,i),k);
end
fprintf('\n');
fprintf('v%d=',i);
for k=1:size(b,2)%此处为变量y的个数
fprintf('+(%f*y_%d)',yw(k,i),k);
end
fprintf('\n');
end
确定主成分个数以后就开始回归分析,得到回归方程;
%% 确定主成分后的回归分析
[XL2,YL2,XS2,YS2,BETA2,PCTVAR2,MSE2,stats2] =plsregress(a,b,ncomp);
n=size(a,2); m=size(b,2);%n是自变量的个数,m是因变量的个数
beta3(1,:)=mu(n+1:end)-mu(1:n)./sig(1:n)*BETA2([2:end],:).*sig(n+1:end); %原始数据回归方程的常数项
beta3([2:n+1],:)=(1./sig(1:n))'*sig(n+1:end).*BETA2([2:end],:); %计算原始变量x1,...,xn的系数,每一列是一个回归方程
fprintf('最后得出如下回归方程:\n')
for i=1:size(b,2)%此处为变量y的个数
fprintf('y%d=%f',i,beta3(1,i));
for j=1:size(a,2)%此处为变量x的个数
fprintf('+(%f*x%d)',beta3(j+1,i),j);
end
fprintf('\n');
end
相关结果展示
根据回归方程计算预测值,并提取相应的真实值,用于后面的对比;对预测结果的展示,详情见MATLAB回归预测模型的结果展示和效果检验。
%% 求预测值
y1 = repmat(beta3(1,:),[size(a,1),1])+ab0(:,[1:n])*beta3([2:end],:); %求y1,..,ym的预测值
y0 = ab0(:,end-size(y1,2)+1:end); % 真实值
绘制回归系数的直方图,
%% 画回归系数的直方图
bar(BETA2','k')
分别绘制主成分对自变量和因变量的贡献率,较为直观;
%% 贡献率画图
figure
percent_explained1 = 100 * PCTVAR(1,:) / sum(PCTVAR(1,:));
pareto(percent_explained1);
xlabel('主成分')
ylabel('贡献率(%)')
title('主成分对自变量的贡献率')
figure
percent_explained = 100 * PCTVAR(2,:) / sum(PCTVAR(2,:));
pareto(percent_explained);
xlabel('主成分')
ylabel('贡献率(%)')
title('主成分对因变量的贡献率')
绘制预测值与真实值的对比图;
%% 绘制预测结果和真实值的对比
N = size(a,1);% 样本个数
for i =1:size(b,2)
yz = y0(:,i);% 真实值
yc = y1(:,i);% 预测值
R2 = (N*sum(yc.*yz)-sum(yc)*sum(yz))^2/((N*sum((yc).^2)-(sum(yc))^2)*(N*sum((yz).^2)-(sum(yz))^2)); %计算R方
figure
plot(1:N,yz,'b:*',1:N,yc,'r-o')
legend('真实值','预测值','location','best')
xlabel('预测样本')
ylabel('值')
string = {['第',num2str(i),'个因变量预测结果对比'];['R^2=' num2str(R2)]};
title(string)
end
通过三种方法评价回归模型的效果;
%% 三种方法检验网络性能
for i =1:size(b,2)
yz = y0(:,i);% 真实值
yc = y1(:,i);% 预测值
% 第一种方法,均方误差
perf = mse(y0,y1)
% 第二种方法,回归图
figure;
plotregression(yz,yc,['第',num2str(i),'个回归图'])
% 第三种方法,误差直方图
e = yz-yc;
figure;
ploterrhist(e,['第',num2str(i),'个误差直方图'])
end
笔者的其他博客,欢迎大家阅读学习,共同进步
傻瓜攻略(一)——MATLAB主成分分析代码及结果分析实例
MATLAB中plotconfusion函数的应用
傻瓜攻略(二)——MATLAB数据挖掘之Apriori算法实现
win10系统中通过conda命令安装tensorflow(cpu版本,不用pip)