drop_path理解和pytorch代码
drop_path理解和代码分析
- drop_path理解
- drop_path代码pytorch
- 对比dropout结果
-
- drop_path输出结果:
- dropout输出结果:
- 总结
drop_path理解
网上的说法:DropPath/drop_path 是一种正则化手段,其效果是将深度学习模型中的多分支结构随机”删除“。
实际上在网上笔者找不到官方的说法…而且drop_path的方法实际上是一个很小众的方法,使用情况极其惨淡如下图:
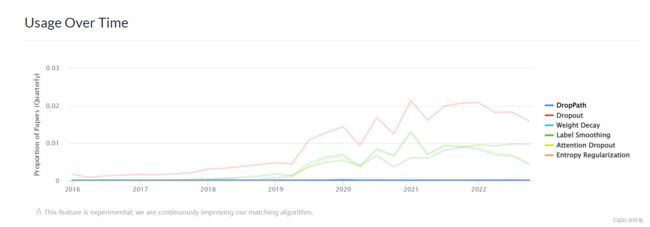
没错,蓝色线是drop_path,基本就是0了,笔者纯属是看了ViT的文章的代码实现才能发现这个玩意儿…
总的来说,根据代码理解其实drop_path就是在一个batch里面随机去除一部分样本,(drop_path:drop掉一部分样本前进的path…)如图为在ViT中的实现:
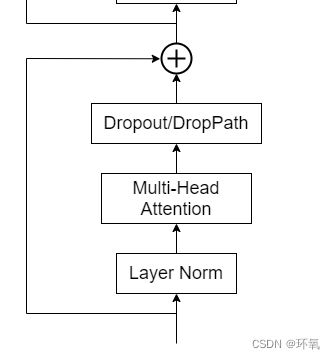
理解:
ViT里面结合了一个残差,可以这么理解:假设没有被drop_path的为x1,被drop_path的为x2。输入x=x1+x2,输出y=x+f(x1),这里假设f表示Layer Norm和Multi-Head Attention层。
drop_path代码pytorch
def drop_path(x, drop_prob: float = 0., training: bool = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor #若要保持期望和不使用dropout时一致,就要除以p。 参考网址:https://www.cnblogs.com/dan-baishucaizi/p/14703263.html
return output
class DropPath(nn.Module):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
ViT调用时的代码:
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
###x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
对比dropout结果
#随机生成一个shape为(4,2,4,2)的输入
input = torch.randn(4,2,4,2)
#输入如下
tensor([[[[ 2.0425e+00, -2.6742e+00],
[ 3.4364e-01, 7.8157e-01],
[ 5.3609e-01, 4.0572e-01],
[-1.6199e+00, -4.5512e-01]],
[[-2.4274e-02, -1.6998e+00],
[ 4.5311e-01, -8.6221e-02],
[-1.8669e+00, -7.3371e-01],
[ 1.0831e-01, 4.5137e-01]]],
[[[ 9.7152e-01, 1.6347e+00],
[ 6.0528e-01, 3.4858e-01],
[ 3.2635e-01, -1.0413e+00],
[-4.6009e-01, -4.2410e-01]],
[[ 1.7342e+00, 7.4081e-01],
[ 2.2524e-01, -1.0693e+00],
[ 1.1779e-01, -1.2914e+00],
[-1.2029e-01, 1.6342e-01]]],
[[[-8.7656e-01, -1.6065e+00],
[ 1.6007e-01, 1.4611e+00],
[ 4.0385e-01, 8.8475e-01],
[ 3.9036e-02, -2.2162e-03]],
[[-9.0586e-01, 2.0484e-01],
[ 9.0203e-01, -2.0338e-01],
[ 1.0276e+00, 1.6731e+00],
[ 8.7121e-02, 2.6277e-01]]],
[[[-8.1874e-01, -7.1293e-01],
[-2.3135e+00, 8.7495e-01],
[ 6.7622e-02, 6.9394e-01],
[ 1.0684e+00, 1.3567e+00]],
[[-1.3875e+00, 1.5329e+00],
[ 2.5272e-01, 3.9513e-01],
[-1.0625e+00, 3.1117e-01],
[-6.0871e-02, -2.6373e-02]]]])
drop_path输出结果:
tensor([[[[ 4.0851, -5.3485],
[ 0.6873, 1.5631],
[ 1.0722, 0.8114],
[-3.2397, -0.9102]],
[[-0.0485, -3.3996],
[ 0.9062, -0.1724],
[-3.7338, -1.4674],
[ 0.2166, 0.9027]]],
[[[ 0.0000, 0.0000],
[ 0.0000, 0.0000],
[ 0.0000, -0.0000],
[-0.0000, -0.0000]],
[[ 0.0000, 0.0000],
[ 0.0000, -0.0000],
[ 0.0000, -0.0000],
[-0.0000, 0.0000]]],
[[[-0.0000, -0.0000],
[ 0.0000, 0.0000],
[ 0.0000, 0.0000],
[ 0.0000, -0.0000]],
[[-0.0000, 0.0000],
[ 0.0000, -0.0000],
[ 0.0000, 0.0000],
[ 0.0000, 0.0000]]],
[[[-0.0000, -0.0000],
[-0.0000, 0.0000],
[ 0.0000, 0.0000],
[ 0.0000, 0.0000]],
[[-0.0000, 0.0000],
[ 0.0000, 0.0000],
[-0.0000, 0.0000],
[-0.0000, -0.0000]]]])``
dropout输出结果:
tensor([[[[ 4.0851e+00, -0.0000e+00],
[ 0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00],
[-3.2397e+00, -9.1024e-01]],
[[-4.8548e-02, -3.3996e+00],
[ 0.0000e+00, -1.7244e-01],
[-0.0000e+00, -1.4674e+00],
[ 0.0000e+00, 9.0274e-01]]],
[[[ 0.0000e+00, 3.2693e+00],
[ 0.0000e+00, 6.9715e-01],
[ 0.0000e+00, -2.0825e+00],
[-9.2018e-01, -8.4821e-01]],
[[ 3.4685e+00, 0.0000e+00],
[ 4.5047e-01, -2.1386e+00],
[ 2.3558e-01, -0.0000e+00],
[-0.0000e+00, 0.0000e+00]]],
[[[-1.7531e+00, -0.0000e+00],
[ 3.2015e-01, 0.0000e+00],
[ 8.0770e-01, 1.7695e+00],
[ 7.8073e-02, -4.4324e-03]],
[[-1.8117e+00, 4.0968e-01],
[ 1.8041e+00, -4.0676e-01],
[ 2.0552e+00, 0.0000e+00],
[ 1.7424e-01, 0.0000e+00]]],
[[[-0.0000e+00, -1.4259e+00],
[-4.6270e+00, 1.7499e+00],
[ 1.3524e-01, 0.0000e+00],
[ 2.1368e+00, 0.0000e+00]],
[[-0.0000e+00, 3.0657e+00],
[ 5.0544e-01, 0.0000e+00],
[-2.1249e+00, 0.0000e+00],
[-0.0000e+00, -0.0000e+00]]]])
总结
这玩意儿为什么有用我也不明白。。。既然是随机把一些样本置0,那跟我直接采样的时候随机少采样一点有什么区别?所以以后还是用dropout吧,稳妥起见…