VL-BERT: Pre-training of Generic Visual-Linguistic Representations
目录
- Introduction
- Model Architecture
- Pre-training VL-BERT
- Experiments
-
- Visual Commensense Reasoning (VCR)
- Visual Question Answering (VQA)
- Referring Expression Comprehension
- Visualization of Attention maps in VL-BERT
- References
Introduction
- VL-BERT 其实就是一个增加了视觉元素输入的多模态 BERT,它能高效地融合对齐视觉和语言信息,可以被当作大多数视觉-语言下游任务的预训练模型. The backbone of VL-BERT is of (multi-modal) Transformer attention module taking both visual and linguistic embedded features as input. In it, each element is either of a word from the input sentence, or a region-of-interest (RoI) from the input image, together with certain special elements to disambiguate different input formats.
Model Architecture
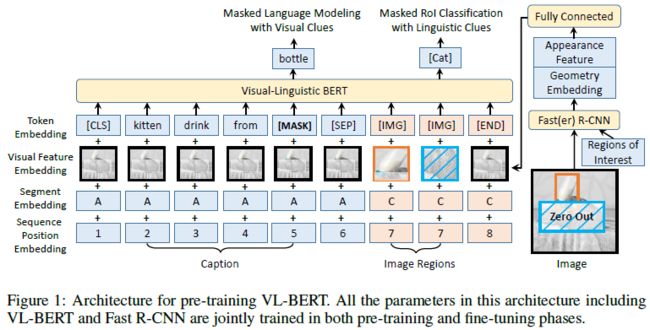
- Token Embedding: 语言部分的 Token Embedding (图一中的蓝色部分) 与 BERT 完全相同,都是使用 WordPiece embeddings。视觉部分的 Token Embedding 则为一个特殊的标记
[IMG],并且以特殊标记[END]结尾 - Visual Feature Embedding: VL-BERT 提供的视觉信息是由 Fast(er) RCNN 提供的 RoI 的视觉外观特征 (visual appearance feature) 以及提供 RoI 几何信息的视觉几何嵌入 (visual geometry embedding) 组成
- Fast(er) RCNN: 我们知道,Faster RCNN 是一个二阶的目标检测网络,由 RPN 网络和 RCNN 网络组成。对于 VL-BERT 来说,由于训练任务并不提供图片的 GT box 信息,不方便对 RPN 网络进行训练,因此 VL-BERT 使用的 Fast(er) RCNN 直接抛弃了 RPN 网络,转而由另一个已经预训练好的 Faster R-CNN 提供图片中的 RoI 信息 (相当于是一个用 pre-trained Faster RCNN 代替 RPN 网络的 Faster RCNN 或是用 pre-trained Faster RCNN 代替 Selective Search 的 Fast RCNN),每张图片最多选取 100 个 score 高于 0.5 的 RoI,最少选出 10 个 RoI (不管它们的 score 为多少)。作者的原话是: “Actually, we drop the RPN branch of Faster RCNN in our VL-BERT since how to tune it is non-trivial in our case, we use Fast RCNN in our VL-BERT instead of Faster RCNN, the difference is that Fast RCNN doesn’t have RPN so we need to input the boxes precomputed by pre-trained Faster RCNN.”
- 视觉外观特征 (visual appearance feature): 对于 RoI 而言,Fast(er) R-CNN 首先由 backbone 提取出整张图片的 feature map,然后由 pre-trained Faster RCNN 提供的 RoI 位置从 feature map 中抽取出 RoI 相应的特征区域,经过 RoI pooling 以及 RCNN 的部分全连接层 (prior to the output layer) 后得到该 RoI 的视觉外观特征 (2048- d d d);对于其他非视觉元素而言 (e.g. text tokens, special tokens),视觉外观特征为 backbone 提取出的整张图片的 feature map
- 视觉几何嵌入 (visual geometry embedding): 视觉几何嵌入为 VL-BERT 提供输入视觉元素的几何位置信息。首先,每个 RoI 的位置信息都可以由一个四维向量 ( x L T W , y L T H , x R B W , y R B H ) × 100 (\frac{x_{LT}}{W},\frac{y_{LT}}{H},\frac{x_{RB}}{W},\frac{y_{RB}}{H})\times100 (WxLT,HyLT,WxRB,HyRB)×100,其中 ( x L T , y L T ) (x_{LT},y_{LT}) (xLT,yLT) 表示左上坐标, ( x R B , y R B ) (x_{RB},y_{RB}) (xRB,yRB) 表示右下坐标, W , H W,H W,H 分别为图片的宽高。得到上述 4- d d d 向量后,再通过不同波长的正余弦函数为每一个坐标构造一个 512- d d d 的坐标嵌入向量,因此一个 RoI 的嵌入向量就为 2048- d d d
- 视觉特征嵌入 (Visual Feature Embedding): 最终的视觉特征嵌入是将视觉外观特征和视觉几何嵌入连接起来,再通过一个全连接层得到
- Segment Embedding: 有 A , B , C A,B,C A,B,C 三种 Segment Embedding,分别表示第一个句子、第二个句子以及视觉元素。这个 Embedding 与 BERT 一样,是直接由模型学得的
- Sequence Position Embedding: 在文本部分,位置嵌入与 BERT 完全一样,也是由模型学得的。而由于视觉元素没有顺序,因此所有 RoI 对应的位置嵌入都是一样的
Pre-training VL-BERT
预训练数据集
- To better exploit the generic representation, we pre-train VL-BERT on both visual-linguistic (i.e. the massive-scale Conceptual Captions dataset) and text-only datasets (i.e. BooksCorpus & English Wikipedia).
- Conceptual Captions 数据集含有 330 万配有说明的图片,但该数据集的图片说明主要是简单从句,这对于许多下游任务而言过于简单,因此为了使 VL-BERT 更好地理解长难句,VL-BERT 还和 BERT 一样,使用 MLM 预训练任务在 BooksCorpus 和 English Wikipedia 上进行预训练
预训练任务
- (1) 每个 batch 都按 1:1 的比例从 Conceptual Captions 和 BooksCorpus & English Wikipedia 中抽取训练样本
- (2) 对于从 Conceptual Captions 中抽取的样本,模型的输入格式为
- Task #1 Masked Language Modeling with Visual Clues: 这个预训练任务与 BERT 中使用的 MLM 类似,区别在于 VL-BERT 在预测 masked word 时不仅会考虑 unmasked word,也会考虑提供的视觉信息,这使得模型不仅能理解文本的上下文信息,还能更好地捕捉视觉和语言内容上的联系 (align the visual and linguistic contents)。例如上图中输入的文本为 “kitten drinking from [MASK]”,如果不提供视觉信息,被遮掩的单词可能是任何容器。如果模型想要正确预测出 “bottle”,就必须捕捉出单词 “bottle” 和其对应 RoI 之间的联系
- Task #2: Masked RoI Classification with Linguistic Clues: 这个任务与任务一类似,图像中的每一个 RoI 都有 15% 的概率被遮掩 (zero out),模型的任务就是预测被遮掩 RoI 的类别 (将 pre-trained Faster R-CNN 输出的 RoI 类别视为 Ground-truth)。值得注意的是,为了防止该 RoI 信息泄露在其他视觉特征中,图片在经过 Fast(er) RCNN 的 backbone 之前就已经将相应的 RoI 区域置零了
- (3) 对于从 BooksCorpus & English Wikipedia 中抽取的样本,模型的输入格式为
We found the task of Sentence-Image Relationship Prediction used in all of the other concurrent works (e.g., ViLBERT and LXMERT is of no help in pre-training visual-linguistic representations. Thus such a task is not incorporated in VL-BERT. (根据论文中的 ablation study,这项预训练任务对 VL-BERT 的三个下游任务甚至是有害的,作者的解释是 “The task of Sentence-Image Relationship Prediction
would introduce unmatched image and caption pairs as negative examples. Such unmatched samples
would hamper the training of other tasks”)
模型的初始化参数
- 由于 VL-BERT 只是在 BERT 的基础上增加了视觉信息的输入,在进行预训练任务之前,VL-BERT 的 BERT 部分可以直接用 BERT 的参数进行初始化,由 BERT BASE \text{BERT}_{\text{BASE}} BERTBASE 和 BERT LARGE \text{BERT}_{\text{LARGE}} BERTLARGE 分别得到 VL-BERT BASE \text{VL-BERT}_{\text{BASE}} VL-BERTBASE 和 VL-BERT LARGE \text{VL-BERT}_{\text{LARGE}} VL-BERTLARGE,用于得到视觉信息的 Faster R-CNN + ResNet-101 则由在 Visual Genome 上训练的 Faster R-CNN + ResNet-101 参数进行初始化。其余新增部分使用均值为 0,标准差为 0.02 的高斯分布随机初始化
Experiments
Visual Commensense Reasoning (VCR)
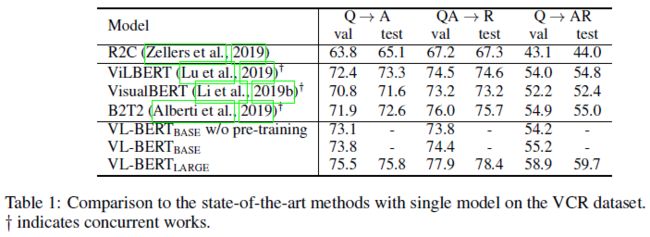
- Visual Commensense Reasoning (VCR): 给定一张图片和图片上分好类的 RoI,提出一个问题,模型需要选出问题正确的答案并提供一个合理的选择理由 (Q → AR) (每个问题都提供 4 个答案和 4 个选择理由,因此就是让模型做两个选择题)。Q → AR 这个问题又可以被分解为 question answering (Q → A) 和 answer justification (QA → R) 这两个子问题。VCR 数据集 由 256k 个样本组成,其中训练集、验证集、测试集大小分别为 213k、27k、25k
输入输出形式
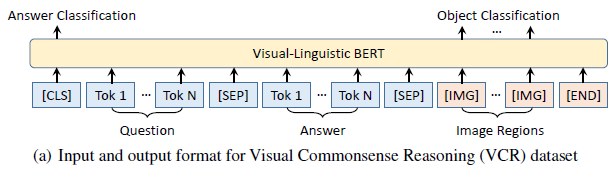
- For the sub-task of Q → A, ‘Q’ and ‘A’ are filled to the Question section and Answer section respectively. For the sub-task of QA → R , the concatenation of ‘Q’ and ‘A’ is filled to the Question section, and ‘R’ is filled to the Answer section. The input RoIs to VL-BERT are the ground-truth annotations in the dataset.
- The final output feature of
[CLS]element is fed to a Softmax classifier for predicting whether the given Answer is the correct choice. During fine-tuning, we adopt two losses, the classification over the correctness of the answers and the RoI classification with linguistic clues.
实验结果
Visual Question Answering (VQA)
- Visual Question Answering (VQA): 给定一个图片及一个相关问题,模型需要生成/选择正确答案
VQA 2.0 数据集
- VQA 2.0 数据集基于 COCO 数据集中的图像. The VQA v2.0 dataset is split into train (83k images and 444k questions), validation (41k images and 214k questions), and test (81k images and 448k questions) sets. For each question, the algorithm should pick the corresponding answer from a shared set consisting of 3,129 answers.
输入输出形式

- As the possible answers are from a shared pool independent to the question, we only fill a [MASK] element to the Answer section. The answer prediction is made from a multi-class classifier based upon the output feature of the [MASK] element.
实验结果
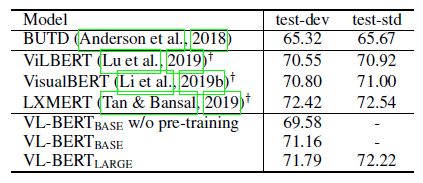
- Except for LXMERT, our VL-BERT achieves better performance than the other concurrent works. This is be-cause LXMERT is pre-trained on massive visual question answering data (aggregating almost all the VQA datasets based on COCO and Visual Genome). While our model is only pre-trained on captioning and text-only dataset, where there is still gap with the VQA task.
Referring Expression Comprehension
- Referring Expression Comprehension: 在图片中找出给定物体的位置
RefCOCO+
- RefCOCO+ dataset consists of 141k expressions for 50k referred objects in 20k images in the COCO dataset.
- RefCOCO+ are split into four sets, training set (train), validation set (val), and two testing sets (testA and testB). Images containing multiple people are in testA set, while images containing multiple objects of other categories are in testB set.
输入输出形式
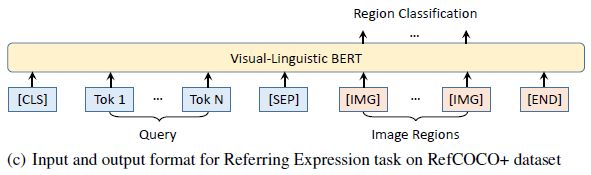
- Model training and evaluation are conducted either on the ground-truth RoIs or on the detected boxes in MAttNet. And the results are reported either in the track of ground-truth regions or that of detected regions, respectively.
- During training, we compute the classification scores for all the input RoIs. For each RoI, a binary classification loss is applied.
- During inference, we directly choose the RoI with the highest classification score as the referred object of the input referring expression.
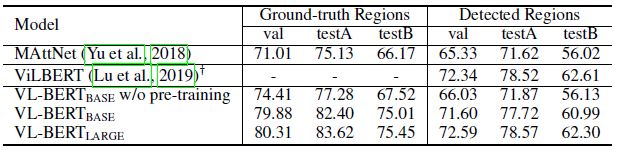
实验结果
Visualization of Attention maps in VL-BERT
- 可视化工具: BertViz3 (Github)

Line intensity indicates the magnitude of attention probability
- We can see different attention patterns across attention heads. For some attention heads, text tokens attend more on the associated image RoIs. While in some other heads, text tokens attend uniformly to all RoIs. It demonstrates the ability of VL-BERT in aggregating and aligning visual-linguistic contents.
References
- VL-BERT: Pre-training of Generic Visual-Linguistic Representations (ICLR 2020)
- code: https://github.com/jackroos/VL-BERT