机器学习——特征预处理
文章目录
- 特征预处理
-
- 1 归一化
-
- 1.1 归一化使用
- 2 标准化
-
- 2.1 标准化使用
- 3 特征降维
-
- 3.1 特征选择-Filter过滤式
- 3.2Filter低方差过滤式使用
- 3.3 PCA主成分分析
- 3.4 PCA使用
特征预处理
特征预处理:通过一些转换函数将一些特征数据转换成更适合算法模型的特征数据的过程。
1 归一化
解决无量纲化问题,处理异常值中因为最大值和最小值的影响。
- 归一化:通过对原始的数据进行变换把数据映射到[0,1]->[mi,mx]之间
- 稳定性差:异常值的出现:影响最大值最小值的
- 方程:x’'=(x-min)/(max-min)*(mx-mi)+mi
关键字:MinMaxScaler
1.1 归一化使用
代码:
from sklearn.preprocessing import MinMaxScaler,StandardScaler
def minmax_demo():
'''
归一化:通过对原始的数据进行变换把数据映射到[0,1]->[mi,mx]之间
稳定性差:异常值的出现:影响最大值最小值的
方程:x''=(x-min)/(max-min)*(mx-mi)+mi
'''
#1、获取数据
data=pd.read_csv("dating.txt")
data=data.iloc[:, :3]#数据提取指定列数
print("data:\n",data)
#2、实例一个转换器类
transfer=MinMaxScaler(feature_range=[2,3])#可以自己设定归一化范围
#3、调用fit_transform
data_new=transfer.fit_transform(data)
print("data_new\n",data_new)
return None
if __name__=="__main__":
minmax_demo()
结果:
根据设定的feature_range=[2,3],将数据映射到自己想要的结果。

2 标准化
- 标准化是对归一化的进一步提升
- 方程:(x - mean) / std
- 应用场景:在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
- 较为稳定的特征处理
关键字:StandardScaler
2.1 标准化使用
代码:
from sklearn.preprocessing import MinMaxScaler,StandardScaler
def stand_demo():
'''
标准化:
较为稳定
方程:x'=(x-mean)/标准差
'''
#1、获取数据
data=pd.read_csv("dating.txt")
data=data.iloc[:, :3]
print("data:\n",data)
#2、实例一个转换器类
transfer=StandardScaler()#可以自己设定归一化范围
#3、调用fit_transform
data_new=transfer.fit_transform(data)
print("data_new\n",data_new)
return None
if __name__=="__main__":
stand_demo()
结果:

3 特征降维
降低的对象:二维数组;降低特征的个数,效果:要求特征与特征之间不相关
3.1 特征选择-Filter过滤式
方差选择法:低方差特征过滤
相关系数 - 特征与特征之间的相关程度
- 取值范围:–1≤ r ≤+1
- 皮尔逊相关系数
3.2Filter低方差过滤式使用
代码:
from sklearn.feature_selection import VarianceThreshold
import pandas as pd
def variance_demo():
'''
特征选择
过滤低方差数据:Filter过滤式
'''
#1、获取数据
data=pd.read_csv("factor_returns.csv")
data=data.iloc[:, 1:-2]
print("data\n",data)
#2、实例化一个转换器类
transfer=VarianceThreshold(threshold=5)#设定阈值:可以过滤一些不太重要的特征
#3、调用fit_transform
data_new=transfer.fit_transform(data)
print("data_new\n",data_new)
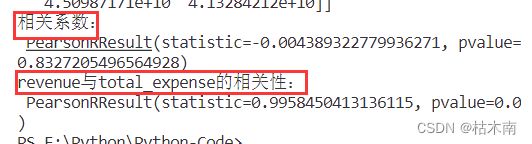
#4、计算某两个变量之间的相关系数
r1 = pearsonr(data["pe_ratio"], data["pb_ratio"])
print("相关系数:\n", r1)
r2=pearsonr(data['revenue'],data['total_expense'])
print("revenue与total_expense的相关性:\n",r2)
return None
if __name__=="__main__":
variance_demo()
结果:
3.3 PCA主成分分析
将高维数据降为低维数据的过程
sklearn.decomposition.PCA(n_components=None)
n_components
小数 表示保留百分之多少的信息
整数 减少到多少特征
3.4 PCA使用
代码:
from sklearn.decomposition import PCA
def pca_demo():
'''
主成分分析(PCA):将高维数据降为低维数据的过程
'''
data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]]
#1、实例化一个转换器类
transfer=PCA(n_components=0.95)#传整数:降至几维。传小数:保留百分之多少信息。
#2、调用fit_transform
data_new= transfer.fit_transform(data)
print("PCA降维:\n",data_new)
return None
if __name__=="__main__":
pca_demo()
结果:
