Github复现之TransUNet(Transformer用于语义分割)
Transformer最近应该算是一个发文章的新扩展点了,下面给出了三个网络的结构分别是TransFuse,TransUNet,SETR。很明显,结构里那个Transformer层都是类似的,感觉只要用一下那个层,包装一下,发文章会比纯做卷积网络创新相对轻松些,目前我只用了TransUNet,也没有怎么训练,还没法给出实际效果的好坏评价,后续会多做实验,评估这些网路用于实际时究竟怎样,接下来就先完成一下TransUNet的复现,没有修改的代码需要去源码里面下载。
更新,效果调整不出来请移步我的更新:https://blog.csdn.net/qq_20373723/article/details/117225238
TransFuse
论文链接:https://arxiv.org/abs/2102.08005
暂未找到GitHub链接
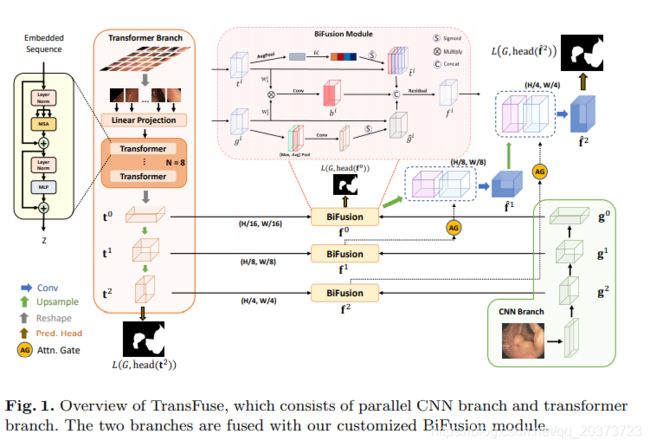
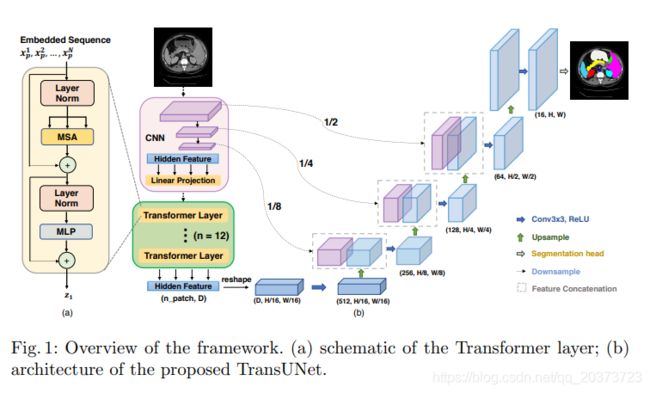
TransUNet
论文链接:https://arxiv.org/abs/2102.04306
GitHub链接:https://github.com/Beckschen/TransUNet
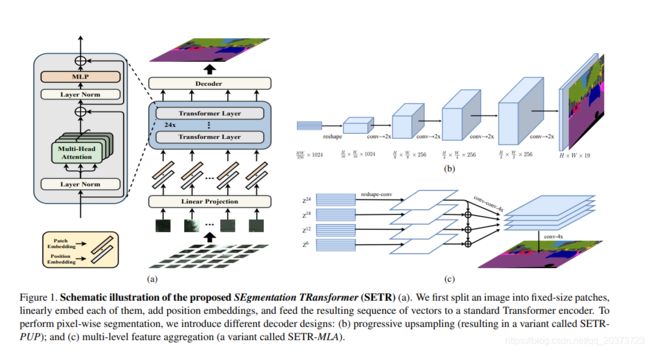
SETR
论文链接:https://arxiv.org/abs/2012.15840
GitHub链接:https://github.com/fudan-zvg/SETR
由于TransUNet最初是用于医学影像的分割,现在我们要用自己的数据集,需要改的主要还是数据的入口,下面具体代码如下:
1.数据准备,我们就按照常规的数据目录方式准备好数据,images和labels文件夹里的数据是一一对应的,名字相同,都是png格式的图片,格式没有限制,也可以是jpg,这里是二分类,其中的标签值是0和255,如果是多分类的话,不会改可以找我讨论

2.数据导入
创建TransUNet/datasets/own_data.py文件
import os
import cv2
import random
import numpy as np
from shutil import copyfile, move
from PIL import Image
import torch
import torch.utils.data as data
from torchvision import transforms
from datasets import custom_transforms as tr
def read_own_data(root_path, split = 'train'):
images = []
masks = []
image_root = os.path.join(root_path, split + '/images')
gt_root = os.path.join(root_path, split + '/labels')
for image_name in os.listdir(image_root):
image_path = os.path.join(image_root, image_name)
label_path = os.path.join(gt_root, image_name)
images.append(image_path)
masks.append(label_path)
return images, masks
def own_data_loader(img_path, mask_path):
img = Image.open(img_path).convert('RGB')
mask = Image.open(mask_path)
mask = np.array(mask)
mask[mask>0] = 1 #这里我把255转到了1
mask = Image.fromarray(np.uint8(mask))
return img, mask
class ImageFolder(data.Dataset):
def __init__(self, args, split='train'):
self.args = args
self.root = self.args.root_path
self.split = split
self.images, self.labels = read_own_data(self.root, self.split)
def transform_tr(self, sample):
composed_transforms = transforms.Compose([
tr.RandomHorizontalFlip(),
tr.RandomScaleCrop(base_size=self.args.base_size, crop_size=self.args.img_size),
tr.RandomGaussianBlur(),
tr.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
tr.ToTensor()
])
return composed_transforms(sample)
def transform_val(self, sample):
composed_transforms = transforms.Compose([
tr.FixScaleCrop(crop_size=self.args.img_size),
tr.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
tr.ToTensor()
])
return composed_transforms(sample)
def __getitem__(self, index):
img, mask = own_data_loader(self.images[index], self.labels[index])
if self.split == "train":
sample = {'image': img, 'label': mask}
return self.transform_tr(sample)
elif self.split == 'val':
img_name = os.path.split(self.images[index])[1]
sample = {'image': img, 'label': mask}
sample_ = self.transform_val(sample)
sample_['case_name'] = img_name[0:-4]
return sample_
# return sample
def __len__(self):
assert len(self.images) == len(self.labels), 'The number of images must be equal to labels'
return len(self.images)
创建TransUNet/datasets/custom_transforms.py文件
这个文件来自这里:https://github.com/jfzhang95/pytorch-deeplab-xception/blob/master/dataloaders/custom_transforms.py
import torch
import random
import numpy as np
from PIL import Image, ImageOps, ImageFilter
class Normalize(object):
"""Normalize a tensor image with mean and standard deviation.
Args:
mean (tuple): means for each channel.
std (tuple): standard deviations for each channel.
"""
def __init__(self, mean=(0., 0., 0.), std=(1., 1., 1.)):
self.mean = mean
self.std = std
def __call__(self, sample):
img = sample['image']
mask = sample['label']
img = np.array(img).astype(np.float32)
mask = np.array(mask).astype(np.float32)
img /= 255.0
img -= self.mean
img /= self.std
return {'image': img,
'label': mask}
class ToTensor(object):
"""Convert ndarrays in sample to Tensors."""
def __call__(self, sample):
# swap color axis because
# numpy image: H x W x C
# torch image: C X H X W
img = sample['image']
mask = sample['label']
img = np.array(img).astype(np.float32).transpose((2, 0, 1))
mask = np.array(mask).astype(np.float32)
img = torch.from_numpy(img).float()
mask = torch.from_numpy(mask).float()
return {'image': img,
'label': mask}
class RandomHorizontalFlip(object):
def __call__(self, sample):
img = sample['image']
mask = sample['label']
if random.random() < 0.5:
img = img.transpose(Image.FLIP_LEFT_RIGHT)
mask = mask.transpose(Image.FLIP_LEFT_RIGHT)
return {'image': img,
'label': mask}
class RandomRotate(object):
def __init__(self, degree):
self.degree = degree
def __call__(self, sample):
img = sample['image']
mask = sample['label']
rotate_degree = random.uniform(-1*self.degree, self.degree)
img = img.rotate(rotate_degree, Image.BILINEAR)
mask = mask.rotate(rotate_degree, Image.NEAREST)
return {'image': img,
'label': mask}
class RandomGaussianBlur(object):
def __call__(self, sample):
img = sample['image']
mask = sample['label']
if random.random() < 0.5:
img = img.filter(ImageFilter.GaussianBlur(
radius=random.random()))
return {'image': img,
'label': mask}
class RandomScaleCrop(object):
def __init__(self, base_size, crop_size, fill=0):
self.base_size = base_size
self.crop_size = crop_size
self.fill = fill
def __call__(self, sample):
img = sample['image']
mask = sample['label']
# random scale (short edge)
short_size = random.randint(int(self.base_size * 0.5), int(self.base_size * 2.0))
w, h = img.size
if h > w:
ow = short_size
oh = int(1.0 * h * ow / w)
else:
oh = short_size
ow = int(1.0 * w * oh / h)
img = img.resize((ow, oh), Image.BILINEAR)
mask = mask.resize((ow, oh), Image.NEAREST)
# pad crop
if short_size < self.crop_size:
padh = self.crop_size - oh if oh < self.crop_size else 0
padw = self.crop_size - ow if ow < self.crop_size else 0
img = ImageOps.expand(img, border=(0, 0, padw, padh), fill=0)
mask = ImageOps.expand(mask, border=(0, 0, padw, padh), fill=self.fill)
# random crop crop_size
w, h = img.size
x1 = random.randint(0, w - self.crop_size)
y1 = random.randint(0, h - self.crop_size)
img = img.crop((x1, y1, x1 + self.crop_size, y1 + self.crop_size))
mask = mask.crop((x1, y1, x1 + self.crop_size, y1 + self.crop_size))
return {'image': img,
'label': mask}
class FixScaleCrop(object):
def __init__(self, crop_size):
self.crop_size = crop_size
def __call__(self, sample):
img = sample['image']
mask = sample['label']
w, h = img.size
if w > h:
oh = self.crop_size
ow = int(1.0 * w * oh / h)
else:
ow = self.crop_size
oh = int(1.0 * h * ow / w)
img = img.resize((ow, oh), Image.BILINEAR)
mask = mask.resize((ow, oh), Image.NEAREST)
# center crop
w, h = img.size
x1 = int(round((w - self.crop_size) / 2.))
y1 = int(round((h - self.crop_size) / 2.))
img = img.crop((x1, y1, x1 + self.crop_size, y1 + self.crop_size))
mask = mask.crop((x1, y1, x1 + self.crop_size, y1 + self.crop_size))
return {'image': img,
'label': mask}
class FixedResize(object):
def __init__(self, size):
self.size = (size, size) # size: (h, w)
def __call__(self, sample):
img = sample['image']
mask = sample['label']
assert img.size == mask.size
img = img.resize(self.size, Image.BILINEAR)
mask = mask.resize(self.size, Image.NEAREST)
return {'image': img,
'label': mask}
到此数据准备和读入已经可以了,下面是对应的添加数据的读入接口到tran.py文件中了
3.训练
修改train.py文件
import argparse
import logging
import os
import random
import numpy as np
import torch
import torch.backends.cudnn as cudnn
from networks.vit_seg_modeling import VisionTransformer as ViT_seg
from networks.vit_seg_modeling import CONFIGS as CONFIGS_ViT_seg
from trainer import trainer_synapse
parser = argparse.ArgumentParser()
parser.add_argument('--root_path', type=str,
default='../data/Synapse/train_npz', help='root dir for data')
parser.add_argument('--dataset', type=str,
default='Synapse', help='experiment_name')
parser.add_argument('--list_dir', type=str,
default='./lists/lists_Synapse', help='list dir')
parser.add_argument('--num_classes', type=int,
default=9, help='output channel of network')
parser.add_argument('--max_iterations', type=int,
default=30000, help='maximum epoch number to train')
parser.add_argument('--max_epochs', type=int,
default=150, help='maximum epoch number to train')
parser.add_argument('--batch_size', type=int,
default=2, help='batch_size per gpu')
parser.add_argument('--n_gpu', type=int, default=1, help='total gpu')
parser.add_argument('--deterministic', type=int, default=1,
help='whether use deterministic training')
parser.add_argument('--base_lr', type=float, default=0.01,
help='segmentation network learning rate')
parser.add_argument('--base_size', type=int,
default=512, help='input patch size of original input')
parser.add_argument('--img_size', type=int,
default=224, help='input patch size of network input')
parser.add_argument('--seed', type=int,
default=0, help='random seed') #这里修改为0
parser.add_argument('--n_skip', type=int,
default=3, help='using number of skip-connect, default is num')
parser.add_argument('--vit_name', type=str,
default='R50-ViT-B_16', help='select one vit model')
parser.add_argument('--vit_patches_size', type=int,
default=16, help='vit_patches_size, default is 16')
args = parser.parse_args()
if __name__ == "__main__":
if not args.deterministic:
cudnn.benchmark = True
cudnn.deterministic = False
else:
cudnn.benchmark = False
cudnn.deterministic = True
args.dataset = 'own'
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed(args.seed)
dataset_name = args.dataset
dataset_config = {
'Synapse': {
'root_path': './data/Synapse/train_npz',
'list_dir': './lists/lists_Synapse',
'num_classes': 9,
},
'own': {
'root_path': './data/GLASS/',
'list_dir': '',
'num_classes': 2,
},
}
args.num_classes = dataset_config[dataset_name]['num_classes']
args.root_path = dataset_config[dataset_name]['root_path']
args.list_dir = dataset_config[dataset_name]['list_dir']
args.is_pretrain = True
args.exp = 'TU_' + dataset_name + str(args.img_size)
snapshot_path = "./model/{}/{}".format(args.exp, 'TU')
snapshot_path = snapshot_path + '_pretrain' if args.is_pretrain else snapshot_path
snapshot_path += '_' + args.vit_name
snapshot_path = snapshot_path + '_skip' + str(args.n_skip)
snapshot_path = snapshot_path + '_vitpatch' + str(args.vit_patches_size) if args.vit_patches_size!=16 else snapshot_path
snapshot_path = snapshot_path+'_'+str(args.max_iterations)[0:2]+'k' if args.max_iterations != 30000 else snapshot_path
snapshot_path = snapshot_path + '_epo' +str(args.max_epochs) if args.max_epochs != 30 else snapshot_path
snapshot_path = snapshot_path+'_bs'+str(args.batch_size)
snapshot_path = snapshot_path + '_lr' + str(args.base_lr) if args.base_lr != 0.01 else snapshot_path
snapshot_path = snapshot_path + '_'+str(args.img_size)
snapshot_path = snapshot_path + '_s'+str(args.seed) if args.seed!=1234 else snapshot_path
if not os.path.exists(snapshot_path):
os.makedirs(snapshot_path)
config_vit = CONFIGS_ViT_seg[args.vit_name]
config_vit.n_classes = args.num_classes
config_vit.n_skip = args.n_skip
if args.vit_name.find('R50') != -1:
config_vit.patches.grid = (int(args.img_size / args.vit_patches_size), int(args.img_size / args.vit_patches_size))
net = ViT_seg(config_vit, img_size=args.img_size, num_classes=config_vit.n_classes).cuda()
# net.load_from(weights=np.load(config_vit.pretrained_path))
trainer = {'Synapse': trainer_synapse,'own': trainer_synapse,}
trainer[dataset_name](args, net, snapshot_path)
修改情况如下:
(1)添加root_path参数,后面会用到

(2)添加自己数据读入的接口

(3)注释源码中的预模型加载,这个因为要外网下载,不想浪费流量了,直接注释了从头来训练把,想下载使用的去源码链接里下载吧

修改trainer.py文件
这里要改的就是用自己的数据读入函数替换原始的
import argparse
import logging
import os
import random
import sys
import time
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from tensorboardX import SummaryWriter
from torch.nn.modules.loss import CrossEntropyLoss
from torch.utils.data import DataLoader
from tqdm import tqdm
from utils import DiceLoss
from torchvision import transforms
from datasets.own_data import ImageFolder
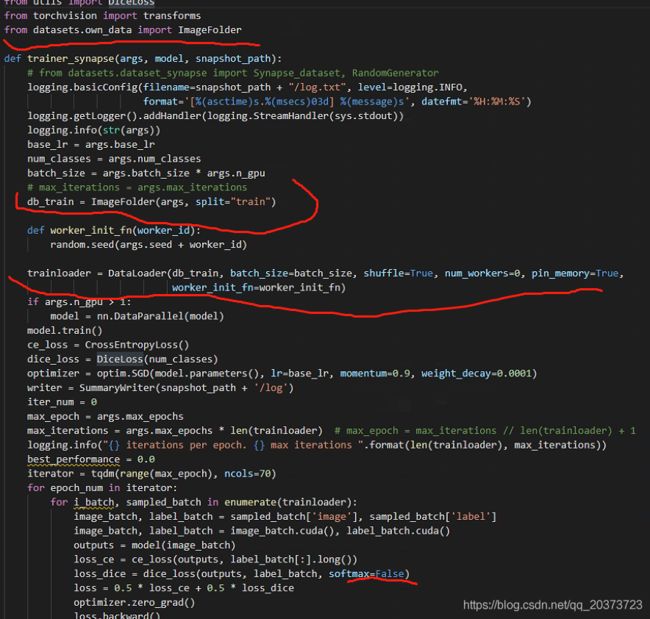
def trainer_synapse(args, model, snapshot_path):
# from datasets.dataset_synapse import Synapse_dataset, RandomGenerator
logging.basicConfig(filename=snapshot_path + "/log.txt", level=logging.INFO,
format='[%(asctime)s.%(msecs)03d] %(message)s', datefmt='%H:%M:%S')
logging.getLogger().addHandler(logging.StreamHandler(sys.stdout))
logging.info(str(args))
base_lr = args.base_lr
num_classes = args.num_classes
batch_size = args.batch_size * args.n_gpu
# max_iterations = args.max_iterations
db_train = ImageFolder(args, split="train")
def worker_init_fn(worker_id):
random.seed(args.seed + worker_id)
trainloader = DataLoader(db_train, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True,
worker_init_fn=worker_init_fn)
if args.n_gpu > 1:
model = nn.DataParallel(model)
model.train()
ce_loss = CrossEntropyLoss()
dice_loss = DiceLoss(num_classes)
optimizer = optim.SGD(model.parameters(), lr=base_lr, momentum=0.9, weight_decay=0.0001)
writer = SummaryWriter(snapshot_path + '/log')
iter_num = 0
max_epoch = args.max_epochs
max_iterations = args.max_epochs * len(trainloader) # max_epoch = max_iterations // len(trainloader) + 1
logging.info("{} iterations per epoch. {} max iterations ".format(len(trainloader), max_iterations))
best_performance = 0.0
iterator = tqdm(range(max_epoch), ncols=70)
for epoch_num in iterator:
for i_batch, sampled_batch in enumerate(trainloader):
image_batch, label_batch = sampled_batch['image'], sampled_batch['label']
image_batch, label_batch = image_batch.cuda(), label_batch.cuda()
outputs = model(image_batch)
loss_ce = ce_loss(outputs, label_batch[:].long())
loss_dice = dice_loss(outputs, label_batch, softmax=False)
loss = 0.5 * loss_ce + 0.5 * loss_dice
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr_ = base_lr * (1.0 - iter_num / max_iterations) ** 0.9
for param_group in optimizer.param_groups:
param_group['lr'] = lr_
iter_num = iter_num + 1
writer.add_scalar('info/lr', lr_, iter_num)
writer.add_scalar('info/total_loss', loss, iter_num)
writer.add_scalar('info/loss_ce', loss_ce, iter_num)
logging.info('iteration %d : loss : %f, loss_ce: %f' % (iter_num, loss.item(), loss_ce.item()))
if iter_num % 20 == 0:
image = image_batch[1, 0:1, :, :]
image = (image - image.min()) / (image.max() - image.min())
writer.add_image('train/Image', image, iter_num)
outputs = torch.argmax(torch.softmax(outputs, dim=1), dim=1, keepdim=True)
writer.add_image('train/Prediction', outputs[1, ...] * 50, iter_num)
labs = label_batch[1, ...].unsqueeze(0) * 50
writer.add_image('train/GroundTruth', labs, iter_num)
save_interval = 50 # int(max_epoch/6)
if epoch_num > int(max_epoch / 2) and (epoch_num + 1) % save_interval == 0:
save_mode_path = os.path.join(snapshot_path, 'epoch_' + str(epoch_num) + '.pth')
torch.save(model.state_dict(), save_mode_path)
logging.info("save model to {}".format(save_mode_path))
if epoch_num >= max_epoch - 1:
save_mode_path = os.path.join(snapshot_path, 'epoch_' + str(epoch_num) + '.pth')
torch.save(model.state_dict(), save_mode_path)
logging.info("save model to {}".format(save_mode_path))
iterator.close()
break
writer.close()
return "Training Finished!"
修改情况如下:
(1)导入自己的函数,数据读入替换,二分类softmax=False
4.预测
修改test.py这里只针对了带有标签的数据进行预测,不带标签的你们自己改下,这个不难
import argparse
import logging
import os
import random
import sys
import numpy as np
import torch
import torch.backends.cudnn as cudnn
import torch.nn as nn
from torch.utils.data import DataLoader
from tqdm import tqdm
from datasets.dataset_synapse import Synapse_dataset
from datasets.own_data import ImageFolder
from utils import test_single_volume
from networks.vit_seg_modeling import VisionTransformer as ViT_seg
from networks.vit_seg_modeling import CONFIGS as CONFIGS_ViT_seg
parser = argparse.ArgumentParser()
parser.add_argument('--root_path', type=str,
default='../data/Synapse/train_npz', help='root dir for data')
parser.add_argument('--volume_path', type=str,
default='../data/Synapse/test_vol_h5', help='root dir for validation volume data') # for acdc volume_path=root_dir
parser.add_argument('--dataset', type=str,
default='Synapse', help='experiment_name')
parser.add_argument('--num_classes', type=int,
default=4, help='output channel of network')
parser.add_argument('--list_dir', type=str,
default='./lists/lists_Synapse', help='list dir')
parser.add_argument('--max_iterations', type=int,default=20000, help='maximum epoch number to train')
parser.add_argument('--max_epochs', type=int, default=30, help='maximum epoch number to train')
parser.add_argument('--batch_size', type=int, default=24,
help='batch_size per gpu')
parser.add_argument('--img_size', type=int, default=224, help='input patch size of network input')
parser.add_argument('--is_savenii', action="store_true", default=True, help='whether to save results during inference')
parser.add_argument('--n_skip', type=int, default=3, help='using number of skip-connect, default is num')
parser.add_argument('--vit_name', type=str, default='ViT-B_16', help='select one vit model')
parser.add_argument('--test_save_dir', type=str, default='../predictions', help='saving prediction as nii!')
parser.add_argument('--deterministic', type=int, default=1, help='whether use deterministic training')
parser.add_argument('--base_lr', type=float, default=0.01, help='segmentation network learning rate')
parser.add_argument('--seed', type=int, default=0, help='random seed')
parser.add_argument('--vit_patches_size', type=int, default=16, help='vit_patches_size, default is 16')
args = parser.parse_args()
def inference(args, model, test_save_path=None):
db_test = args.Dataset(args, split="val")
testloader = DataLoader(db_test, batch_size=1, shuffle=False, num_workers=0)
logging.info("{} test iterations per epoch".format(len(testloader)))
model.eval()
metric_list = 0.0
for i_batch, sampled_batch in tqdm(enumerate(testloader)):
h, w = sampled_batch['image'].size()[2:]
image, label, case_name = sampled_batch['image'], sampled_batch['label'], sampled_batch['case_name'][0]
metric_i = test_single_volume(image, label, model, classes=args.num_classes, patch_size=[args.img_size, args.img_size],
test_save_path=test_save_path, case=case_name, z_spacing=args.z_spacing)
metric_list += np.array(metric_i)
logging.info('idx %d case %s mean_dice %f mean_hd95 %f' % (i_batch, case_name, np.mean(metric_i, axis=0)[0], np.mean(metric_i, axis=0)[1]))
metric_list = metric_list / len(db_test)
for i in range(1, args.num_classes):
logging.info('Mean class %d mean_dice %f mean_hd95 %f' % (i, metric_list[i-1][0], metric_list[i-1][1]))
performance = np.mean(metric_list, axis=0)[0]
mean_hd95 = np.mean(metric_list, axis=0)[1]
logging.info('Testing performance in best val model: mean_dice : %f mean_hd95 : %f' % (performance, mean_hd95))
return "Testing Finished!"
if __name__ == "__main__":
if not args.deterministic:
cudnn.benchmark = True
cudnn.deterministic = False
else:
cudnn.benchmark = False
cudnn.deterministic = True
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed(args.seed)
dataset_config = {
'Synapse': {
'Dataset': Synapse_dataset,
'volume_path': '../data/Synapse/test_vol_h5',
'list_dir': './lists/lists_Synapse',
'num_classes': 9,
'z_spacing': 1,
},
'own': {
'Dataset': ImageFolder,
'root_path': './data/GLASS/',
'volume_path': './data/GLASS/',
'list_dir': '',
'num_classes': 2,
'z_spacing': 1,
},
}
args.dataset = 'own'
args.vit_name = 'R50-ViT-B_16'
args.batch_size = 2
args.max_epochs = 150
dataset_name = args.dataset
args.root_path = dataset_config[dataset_name]['root_path']
args.num_classes = dataset_config[dataset_name]['num_classes']
args.volume_path = dataset_config[dataset_name]['volume_path']
args.Dataset = dataset_config[dataset_name]['Dataset']
args.list_dir = dataset_config[dataset_name]['list_dir']
args.z_spacing = dataset_config[dataset_name]['z_spacing']
args.is_pretrain = True
# name the same snapshot defined in train script!
args.exp = 'TU_' + dataset_name + str(args.img_size)
snapshot_path = "./model/{}/{}".format(args.exp, 'TU')
snapshot_path = snapshot_path + '_pretrain' if args.is_pretrain else snapshot_path
snapshot_path += '_' + args.vit_name
snapshot_path = snapshot_path + '_skip' + str(args.n_skip)
snapshot_path = snapshot_path + '_vitpatch' + str(args.vit_patches_size) if args.vit_patches_size!=16 else snapshot_path
snapshot_path = snapshot_path + '_epo' + str(args.max_epochs) if args.max_epochs != 30 else snapshot_path
if dataset_name == 'ACDC': # using max_epoch instead of iteration to control training duration
snapshot_path = snapshot_path + '_' + str(args.max_iterations)[0:2] + 'k' if args.max_iterations != 30000 else snapshot_path
snapshot_path = snapshot_path+'_bs'+str(args.batch_size)
snapshot_path = snapshot_path + '_lr' + str(args.base_lr) if args.base_lr != 0.01 else snapshot_path
snapshot_path = snapshot_path + '_'+str(args.img_size)
snapshot_path = snapshot_path + '_s'+str(args.seed) if args.seed!=1234 else snapshot_path
config_vit = CONFIGS_ViT_seg[args.vit_name]
config_vit.n_classes = args.num_classes
config_vit.n_skip = args.n_skip
config_vit.patches.size = (args.vit_patches_size, args.vit_patches_size)
if args.vit_name.find('R50') !=-1:
config_vit.patches.grid = (int(args.img_size/args.vit_patches_size), int(args.img_size/args.vit_patches_size))
net = ViT_seg(config_vit, img_size=args.img_size, num_classes=config_vit.n_classes).cuda()
snapshot = os.path.join(snapshot_path, 'best_model.pth')
if not os.path.exists(snapshot): snapshot = snapshot.replace('best_model', 'epoch_'+str(args.max_epochs-1))
net.load_state_dict(torch.load(snapshot))
snapshot_name = snapshot_path.split('/')[-1]
log_folder = './test_log/test_log_' + args.exp
os.makedirs(log_folder, exist_ok=True)
logging.basicConfig(filename=log_folder + '/'+snapshot_name+".txt", level=logging.INFO, format='[%(asctime)s.%(msecs)03d] %(message)s', datefmt='%H:%M:%S')
logging.getLogger().addHandler(logging.StreamHandler(sys.stdout))
logging.info(str(args))
logging.info(snapshot_name)
if args.is_savenii:
args.test_save_dir = './predictions'
test_save_path = os.path.join(args.test_save_dir, args.exp, snapshot_name)
os.makedirs(test_save_path, exist_ok=True)
else:
test_save_path = None
inference(args, net, test_save_path)
修改情况如下:
(1)数据函数导入,路径参数添加
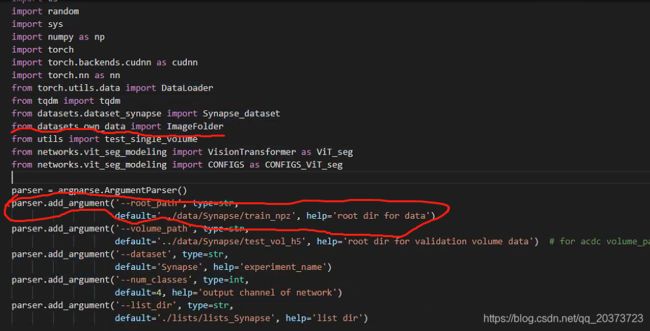
(2)参数赋值,路径修改

修改utils.py文件
import numpy as np
import torch
from medpy import metric
from scipy.ndimage import zoom
import torch.nn as nn
import SimpleITK as sitk
import cv2
class DiceLoss(nn.Module):
def __init__(self, n_classes):
super(DiceLoss, self).__init__()
self.n_classes = n_classes
def _one_hot_encoder(self, input_tensor):
tensor_list = []
for i in range(self.n_classes):
temp_prob = input_tensor == i # * torch.ones_like(input_tensor)
tensor_list.append(temp_prob.unsqueeze(1))
output_tensor = torch.cat(tensor_list, dim=1)
return output_tensor.float()
def _dice_loss(self, score, target):
target = target.float()
smooth = 1e-5
intersect = torch.sum(score * target)
y_sum = torch.sum(target * target)
z_sum = torch.sum(score * score)
loss = (2 * intersect + smooth) / (z_sum + y_sum + smooth)
loss = 1 - loss
return loss
def forward(self, inputs, target, weight=None, softmax=False):
if softmax:
inputs = torch.softmax(inputs, dim=1)
target = self._one_hot_encoder(target)
if weight is None:
weight = [1] * self.n_classes
assert inputs.size() == target.size(), 'predict {} & target {} shape do not match'.format(inputs.size(), target.size())
class_wise_dice = []
loss = 0.0
for i in range(0, self.n_classes):
dice = self._dice_loss(inputs[:, i], target[:, i])
class_wise_dice.append(1.0 - dice.item())
loss += dice * weight[i]
return loss / self.n_classes
def calculate_metric_percase(pred, gt):
pred[pred > 0] = 1
gt[gt > 0] = 1
if pred.sum() > 0 and gt.sum()>0:
dice = metric.binary.dc(pred, gt)
hd95 = metric.binary.hd95(pred, gt)
return dice, hd95
elif pred.sum() > 0 and gt.sum()==0:
return 1, 0
else:
return 0, 0
def test_single_volume(image, label, net, classes, patch_size=[256, 256], test_save_path=None, case=None, z_spacing=1):
image, label = image.squeeze(0).cpu().detach().numpy(), label.squeeze(0).cpu().detach().numpy()
if len(image.shape) == 3:
prediction = np.zeros_like(image)
for ind in range(image.shape[0]):
slice = image[ind, :, :]
x, y = slice.shape[0], slice.shape[1]
if x != patch_size[0] or y != patch_size[1]:
slice = zoom(slice, (patch_size[0] / x, patch_size[1] / y), order=3) # previous using 0
input = torch.from_numpy(slice).unsqueeze(0).unsqueeze(0).float().cuda()
net.eval()
with torch.no_grad():
outputs = net(input)
# out = torch.argmax(torch.softmax(outputs, dim=1), dim=1).squeeze(0)
out = torch.argmax(torch.sigmoid(outputs), dim=1).squeeze(0)
out = out.cpu().detach().numpy()
if x != patch_size[0] or y != patch_size[1]:
pred = zoom(out, (x / patch_size[0], y / patch_size[1]), order=0)
else:
pred = out
prediction[ind] = pred
prediction = prediction[0]
else:
input = torch.from_numpy(image).unsqueeze(
0).unsqueeze(0).float().cuda()
net.eval()
with torch.no_grad():
out = torch.argmax(torch.softmax(net(input), dim=1), dim=1).squeeze(0)
prediction = out.cpu().detach().numpy()
metric_list = []
for i in range(1, classes):
metric_list.append(calculate_metric_percase(prediction == i, label == i))
# if test_save_path is not None:
# img_itk = sitk.GetImageFromArray(image.astype(np.float32))
# prd_itk = sitk.GetImageFromArray(prediction.astype(np.float32))
# lab_itk = sitk.GetImageFromArray(label.astype(np.float32))
# img_itk.SetSpacing((1, 1, z_spacing))
# prd_itk.SetSpacing((1, 1, z_spacing))
# lab_itk.SetSpacing((1, 1, z_spacing))
# sitk.WriteImage(prd_itk, test_save_path + '/'+case + "_pred.nii.gz")
# sitk.WriteImage(img_itk, test_save_path + '/'+ case + "_img.nii.gz")
# sitk.WriteImage(lab_itk, test_save_path + '/'+ case + "_gt.nii.gz")
if test_save_path is not None:
cv2.imwrite(test_save_path + '/'+case + '.png', prediction*255)
return metric_list
修改情况如下:
注释掉源码里的图像信息存储代码,那些都是针对特定医学影像的,直接添加cv2的存储函数就好了

如果这篇复现起来感觉有点难度,可以区看看我另一篇试试
https://blog.csdn.net/qq_20373723/article/details/117225238?spm=1001.2014.3001.5502