PyTorch深度学习-跟着小土堆学习
目录
- 学习视频链接
- 一些问题
- P4:Python/PyTorch学习中两大法宝函数-dir()、help()
- P5:PyCharm及Jupyter使用及对比
- P6:PyTorch加载数据初认识
- P7:Dataset类代码实战
- P8:TensorBoard的使用(一)
- P9:TensorBoard的使用(二)
- P10-11:Transeforms的使用(一)(二)
- P12-13:常见的transforms(一)(二)
- P14:torchvision中的数据集使用
- P15:DataLoader的使用
- P16:神经网络的基本骨架-nn.Module的使用
- P17:土堆说卷积操作(可选看)torch.nn.functional.conv2d
- P18:神经网络-卷积层 torch.nn.Conv2d
- P19:神经网络-最大池化的使用 torch.nn.MaxPool2d
- P20:神经网络-非线性激活
- P21:神经网络-线形层及其他层介绍
- P22:神经网络-搭建小实战和Sequential的使用
- P23:损失函数与反向传播
- P24:优化器(一)
- P25:现有网络模型的使用及修改
- P26:自定义的网络模型的保存与读取
- P27:完整的模型训练套路(一)~(四)
学习视频链接
学习非一日之功,而我又是脑子转得慢,只有慢慢学起来呀!
先从第一个【小土堆】的视频学起来!
- PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
- 《PyTorch深度学习实践》完结合集-刘二大人
【小土堆】给出的资料:(2021-5-31完结的)
个人公众号:土堆碎念
各种资料,请自取。
代码:https://github.com/xiaotudui/PyTorch-Tutorial
蚂蚁蜜蜂/练手数据集:链接: https://pan.baidu.com/s/1jZoTmoFzaTLWh4lKBHVbEA 密码: 5suq
课程资源:https://pan.baidu.com/s/1CvTIjuXT4tMonG0WltF-vQ?pwd=jnnp 提取码:jnnp
有用的链接:
- cv2、plt 、PIL显示图像
- 解决 OpenCV cv2.imread()、cv2.imwrite()函数无法读取、写入以中文命名的图像文件及含有中文路径的图像文件
- 图像的3种表示格式的每个维度的含义:
- tensor:tensor.shape -> torch.Size([C, H, W]) # 在训练过程中通常会在0维上扩充一个维度来表示batchsize,即torch.Size([batchsize, C, H, W])
- numpy.ndarray:ndarray.shape -> (H, W, C) # 这个格式通常是用
cv2.imread(img_path)读取到的,或者用np.array(PIL.Image)转换得到的。 - PIL.Image:Image.size -> (W, H) # 注意这个使用的是size而不是shape,而且是只有两个元素的tuple,且分别表示的宽W、高H。(而不似tensor、numpy那样有3个元素且先表示的高H,再表示的宽W)
一些问题
- tensorboard中的x轴是step还是epoch?这是自己去设定的嘛?
P4:Python/PyTorch学习中两大法宝函数-dir()、help()
dir() 函数,打开工具箱(例如PyTorch,进一步打开某一些分隔区)
help() 函数,查看工具包中某一个工具函数的用法(说明书)
(1) 查看torch工具包有哪些分割区
dir(torch)
# ['AVG', 'AggregationType', 'AnyType', 'Argument', 'ArgumentSpec', 'BFloat16Storage', 'BFloat16Tensor',...]
(2) 查看torch.cuda有哪些分隔区
dir(torch.cuda)
# ['Any', 'BFloat16Storage', 'BFloat16Tensor', 'BoolStorage', 'BoolTensor', 'ByteStorage', ...]
(3) 查看torch.cuda.is_available()有哪些分隔区
dir(torch.cuda.is_available()) # 函数后面的()去掉,效果一样
# ['__abs__', '__add__', '__and__', '__bool__', '__ceil__', '__class__', ...]
此时发现前后都是带有两个下划线的:__这说明是规定好不可更改的,也就说明是torch.cuda.is_available不再是一个分隔区而是一个函数,因此可调用help()来查看该函数的基本作用。
help(torch.cuda.is_available) # 注意这后面不能跟有()
# 打印结果,该函数会返回一个bool值
# Help on function is_available in module torch.cuda:
# is_available() -> bool
# Returns a bool indicating if CUDA is currently available.
P5:PyCharm及Jupyter使用及对比
在这个教程中获得了一个在指定环境中打开Jupyter的小tips:
打开cmd,然后依次键入以下两行命令,然后将cmd中出现的URL粘贴进浏览器打开即可:
activate yolov5
jupyter notebook
---------------------------------------------------------------------------
oh!从这里开始就在编写另外一个博客了:关于使用Jupyter的几个tips
继续学习!!!
---------------------------------------------------------------------------

P6:PyTorch加载数据初认识

P7:Dataset类代码实战
如果是小白的话,真的很建议去看看这个视频!UP主用了PyCharm + Python Console配合着来看结果的生成的,非常棒!
主要内容:
- 手写加载数据集的类:MyData。主要是要重写
__init__()、__getitem__()、__len()__这3个类。 - get到一个小技巧,可以直接用
+对两个Data类进行拼接(可用于数据集不足时,直接将两个数据集这样加起来一起使用) new_path = os.path.join(path1,path2,...)将所有路径联合起来,返回一个整合路径(str)file_name_list = os.listdir(path)读取path路径中的所有文件名称,返回一个名称列表(list)
read_data.py:
from torch.utils.data import Dataset
from PIL import Image
import os
# 构造一个子文件夹数据集类MyData
class MyData(Dataset):
def __init__(self, root_dir, label_dir): # root_dir是指整个数据集的根目录,label_dir是指具体某一个类的子目录
# 在init初始化函数中,定义一些类中的全局变量,即跟在self.后的变量们
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_list = os.listdir(self.path)
def __getitem__(self, index): # 传入下标获取元素
img_name = self.img_list[index]
img_item_path = os.path.join(self.path, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label[:-6] # 返回的是一个元组
# 这里进行了截取,因为我不想要label_dir最后面的'_image'这6个元素
def __len__(self):
return len(self.img_list)
# --------------实例化ants_data和bees_data------------- #
root_dir = 'dataset/train'
ants_dir = 'ants_image'
bees_dir = 'bees_image'
ants_data = MyData(root_dir, ants_dir)
bees_data = MyData(root_dir, bees_dir)
# ---------------------------------------------------- #
# -------------返回一个元组,分别赋值给img和label------- #
img, label = ants_data[0]
# ----------------------------------------------------- #
# ---因为是元组,所以可用[0]、[1]直接提取出img、label---- #
print(label == ants_data[0][1]) # true
# ----------------------------------------------------- #
# ----------将ants_data和bees_data相加起来使用---------- #
y = ants_data + bees_data
len_ants = len(ants_data) # 124
len_bees = len(bees_data) # 121
len_y = len(y) # 245
print(len_y == len_ants+len_bees) # True
print(y[123][1]) # ants
print(y[124][1]) # bees
P8:TensorBoard的使用(一)
之前写过一篇文章,可能会有点帮助:tensorboard初体验
主要内容:
- 调用SummaryWriter类:
from torch.utils.tensorboard import SummaryWriter(摘要编写器)
Writes entries directly to event files in the log_dir to be consumed by TensorBoard.
TheSummaryWriterclass provides a high-level API to create an event file in a given directory and add summaries and events to it. The class updates the file contents asynchronously. This allows a training program to call methods to add data to the file directly from the training loop, without slowing down training.
将条目直接写入log_dir中的事件文件,供TensorBoard使用。
“SummaryWriter”类提供了一个高级API,用于在给定目录中创建事件文件,并向其中添加摘要和事件。该类异步更新文件内容。这允许训练程序调用方法直接从训练循环中向文件添加数据,而不会降低训练速度。
如果调用SummaryWriter类没有传入log_dir参数的话,会默认在当前目录下新建一个runs文件夹用于存放训练过程中的event事件文件。(SummaryWriter的其他参数一般用不到)
官方给出的例子:
(1) 使用自动生成的文件夹名称runs创建SummaryWriter()。
writer = SummaryWriter()
# folder location: runs/May04_22-14-54_s-MacBook-Pro.local/
(2) 使用指定的文件夹名称my_experiment创建SummaryWriter()。
writer = SummaryWriter("my_experiment")
# folder location: my_experiment
(3) 创建一个附加注释的SummaryWriter()。
writer = SummaryWriter(comment="LR_0.1_BATCH_16")
# folder location: runs/May04_22-14-54_s-MacBook-Pro.localLR_0.1_BATCH_16/
- 主要会用到两种方法:
writer.add_image(tag, tensor, step)# 添加图像(模型图像,观察训练结果)
writer.add_scalar(tag, tensor, step)# 添加标量(就是一些数据的变化曲线,比如loss)
writer.add_graph(model, input)# 查看模型计算图(在P22有使用到)
(1) writer.add_image() # 添加图像(模型图像,观察训练结果)
def add_image(self, tag, img_tensor, global_step=None, walltime=None, dataformats='CHW'):
Note that this requires the ``pillow`` package.
Args:
tag (string): Data identifier # 数据标识符(就是图标的title)
img_tensor (torch.Tensor, numpy.array, or string/blobname): Image data # 图像数据(指明传入的数据类型只能是torch.Tensor,numpy.array,string)
global_step (int): Global step value to record # 要训练多少步(就是x轴)
walltime (float): Optional override default walltime (time.time())
seconds after epoch of event
Shape:
img_tensor: Default is :math:`(3, H, W)`. You can use ``torchvision.utils.make_grid()`` to
convert a batch of tensor into 3xHxW format or call ``add_images`` and let us do the job.
Tensor with :math:`(1, H, W)`, :math:`(H, W)`, :math:`(H, W, 3)` is also suitable as long as
corresponding ``dataformats`` argument is passed, e.g. ``CHW``, ``HWC``, ``HW``.
Examples::
from torch.utils.tensorboard import SummaryWriter
import numpy as np
img = np.zeros((3, 100, 100))
img[0] = np.arange(0, 10000).reshape(100, 100) / 10000
img[1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000
img_HWC = np.zeros((100, 100, 3))
img_HWC[:, :, 0] = np.arange(0, 10000).reshape(100, 100) / 10000
img_HWC[:, :, 1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000
writer = SummaryWriter()
writer.add_image('my_image', img, 0)
# If you have non-default dimension setting, set the dataformats argument.
writer.add_image('my_image_HWC', img_HWC, 0, dataformats='HWC')
writer.close()
Expected result:
.. image:: _static/img/tensorboard/add_image.png
:scale: 50 %
(2) writer.add_scalar() # 添加标量(就是一些数据的变化曲线,比如loss)
def add_scalar(self, tag, scalar_value, global_step=None, walltime=None):
Args:
tag (string): Data identifier # 数据标识符(就是图标的title)
scalar_value (float or string/blobname): Value to save # 要保存的数值(就是y轴)
global_step (int): Global step value to record # 要训练多少步(就是x轴)
walltime (float): Optional override default walltime (time.time())
with seconds after epoch of event
Examples::
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
x = range(100)
for i in x:
writer.add_scalar('y=2x', i * 2, i)
writer.close()
Expected result:
.. image:: _static/img/tensorboard/add_scalar.png
:scale: 50 %
- 最后还需要关闭:
writer.close() - 打开tensorboard观察图表的方式:在pycharm的终端Terminal中键入
tensorboard --logdir=logs --port=6007(最后指定端口的操作是可选的,这里指定端口是为了避免:当前有多人在使用同一个服务器的默认端口进行训练而造成的拥塞)
注意:
1)当前面3步运行完之后,再通过第4步指定event文件的存放路径,将event文件们显示进行观察。
2)如果同一logdir下存放了多个相同tag的event文件,则绘图时会发生混乱。解决方案:将此logdir下的文件全部删除,然后重新运行。or构建子文件夹,也就是说创建新的SummaryWriter(‘新文件夹’)
本节例子只使用到了writer.scalar():
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('logs') # 实例化一个SummaryWriter为writer,并指定event的保存路径为logs
for i in range(10):
writer.add_scalar('y=2x', 2 * i, i)
writer.close() # 最后还需要将这个writer关闭
P9:TensorBoard的使用(二)
主要内容:
-
运用
writer.add_image()。由上节 P8 可知,add_image能处理的图像数据类型是:torch.Tensor、numpy.array、String。
(而在 P7 中运用的 PIL.Image 读取的数据类型是PIL.JpegImagePlugin.JpegImageFile,所以需要转换成 numpy.array 才可放进 add_image 中使用。本节课直接采用的opencv读取numpy数据) -
利用numpy.array() 将 PIL 转为 numpy.ndarray
from PIL import Image
image_path = 'dataset/train/ants_image/0013035.jpg'
img = Image.open(image_path)
print(type(img)) # - 又是一个重点,由 P8 可知,img_tensor的shape是有要求的!
img_tensor: Default is :math:
(3, H, W). You can usetorchvision.utils.make_grid()to convert a batch of tensor into 3xHxW format or calladd_imagesand let us do the job.
Tensor with :math:(1, H, W), :math:(H, W), :math:(H, W, 3)is also suitable as long as correspondingdataformatsargument is passed, e.g.CHW,HWC,HW.
要求:
- img_tensor的默认shape是
(3, H, W) - 如果要使用其他的shape,则需要通过
dataformats来指明一下,即:dataformats=‘CHW’、dataformats=‘HWC’、dataformats=‘HW’
通过方式2将PIL转换为numpy后,虽然满足了img_tensor的数据类型要求,但是没有满足img_tensor的默认shape要求。
因为转换后的numpy的shape是(H,W,C),也就是说channel=3在最后一维,所以还需要在add_image()中添加参数dataformats=(H,W,C)(或者手动调整一下维度,代码为img_array = img_array.transepose(2, 0, 1),然后就不用添加dataformats参数了)。
print(img_array.shape) # (512, 768, 3)
opencv是按照BGR读取的图像,记得转换为RGB:cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
整体代码为:
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
writer = SummaryWriter('logs_3') # 实例化一个SummaryWriter为writer,并指定event的保存路径为logs
image_path1 = 'dataset/train/ants_image/0013035.jpg'
image_path2 = 'dataset/train/bees_image/16838648_415acd9e3f.jpg'
img = Image.open(image_path2) # image_path1
img_array = np.array(img)
print(type(img)) # (1)同一个tag显示多张图像(拖动滑条)

(2)多个tag显示

P10-11:Transeforms的使用(一)(二)
主要内容:
- torchvision中的transeforms,主要是对图像进行变换(预处理)。
from torchvision import transforms


- transeforms中常用的就是以下几种方法:(
Alt+7可唤出左侧的Structure结构)
“Compose”, “ToTensor”, “PILToTensor”, “ConvertImageDtype”, “ToPILImage”, “Normalize”, “Resize”, “Scale”,“CenterCrop”

- Compose: Composes several transforms together. Args:list of transforms to compose.将几个变换组合在一起。参数:[Transform对象列表],例如transforms.Compose([transforms.CenterCrop(10),transforms.ToTensor(),…])
- ToTensor: Convert a
PIL Imageornumpy.ndarrayto tensor. - ToPILImage: Convert a
tensoror anndarraytoPIL Image. - Normalize(torch.nn.Module): Normalize a
tensor imagewith mean and standard deviation.This transform does not support PIL Image.用平均值和标准偏差归一化张量图像。此转换不支持PIL图像。(为n个维度给定mean:(mean[1],…,mean[n])和std:(std[1],…,std[n]),此转换将对每个channel进行归一化) - Resize(torch.nn.Module): Resize the input image
(PIL Image or Tensor)to the given size.Return PIL Image or Tensor: Rescaled image.将输入的图像(PIL Image or Tensor)的大小缩放到指定的size尺寸。size (sequence or int),当是sequence时则调整到指定的(h, w);当是int时,就将原图的min(h,w)调整到size大小,然后另一条边进行等比例缩放。 - RandomCrop(torch.nn.Module): Crop the given image
(PIL Image or Tensor)at a random location.在随机位置裁剪给定的size大小的图像(size的输入要求跟Resize一样)。
- python的用法 -> tensor数据类型
通过transforms.ToTensor去看两个问题:
(1)transforms该如何使用(python)
(2)为什么我们需要Tensor数据类型:因为在tensor中封装了许多训练神经网络中会用到的参数,例如requires_grad等。
(1)用ToTensor()将PIL Image转为tensor
也可以用 ToTensor() 将 numpy.ndarray 转为tensor(用opencv读入的数据类型是numpy.ndarray)
import numpy as np
from torchvision import transforms
from PIL import Image
image_path = 'dataset/train/ants_image/0013035.jpg'
image = Image.open(image_path)
# 1.transforms该如何使用(python)
tensor_trans = transforms.ToTensor() # ToTensor()中不带参数
tensor_img = tensor_trans(image) # 不能直接写成transforms.ToTensor(image)
print(np.array(image).shape) # (512, 768, 3)
print(tensor_img.shape) # torch.Size([3, 512, 768]),通道数变到第0维了
(2)ToTensor与Tensorboard配合使用
import numpy as np
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
image_path = 'dataset/train/ants_image/0013035.jpg'
image = Image.open(image_path)
# 1.transforms该如何使用(python)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(image)
print(np.array(image).shape)
print(tensor_img.shape)
# 写入tensorboard
writer = SummaryWriter('logs')
writer.add_image('tag', tensor_img, 1)
writer.close()
P12-13:常见的transforms(一)(二)
这张图挺棒的!因为图像的数据类型在不同场景往往不同,很容易出错,需要转换为特定格式才能使用!

主要内容:
- 了解python中某个类的内置函数
__call__的用法(用__表示是内置函数)
参考链接:详解Python的__call__()方法
__call__()方法的作用:把一个类的实例化对象变成了可调用对象。调用该实例对象就是执行__call__()方法中的代码。- 可以通过内置函数
callable来判断是否是可调用对象。例如判断p是否为可调用对象:print(callable(p))返回 True 或 False。
CallTest.py
class Person:
def __call__(self, name):
print('__call__' + ' Hello ' + name)
def hello(self, name):
print('hello ' + name)
person = Person() # 实例化一个对象person
person('zhangsan') # 像调用函数一样调用person对象
person.__call__('zhangshan_2') # 也可像调用类函数调用
person.hello('wangwu') # 调用类函数person
# __call__ Hello zhangsan
# __call__ Hello zhangshan_2
# hello wangwu
- 例子ToTensor、Normalize、Resize、Compose
- Compose: Composes several transforms together. Args:list of transforms to compose.将几个变换组合在一起。参数:[Transform对象列表],例如transforms.Compose([transforms.CenterCrop(10),transforms.ToTensor(),…])
注意:Compose的参数列表是会按照参数的顺序来对图像进行操作的,相当于list[0]的输出会作为list[1]的输入,以此类推,要注意每种transforms函数的输入数据格式要求,有些是要求为tensor,有些是PIL。 - ToTensor: Convert a
PIL Imageornumpy.ndarrayto tensor. - ToPILImage: Convert a
tensoror anndarraytoPIL Image. - Normalize(torch.nn.Module): Normalize a
tensor imagewith mean and standard deviation.This transform does not support PIL Image.用平均值和标准偏差归一化张量图像。此转换不支持PIL图像。(为n个维度给定mean:(mean[1],…,mean[n])和std:(std[1],…,std[n]),此转换将对每个channel进行归一化) - Resize(torch.nn.Module): Resize the input image
(PIL Image or Tensor)to the given size.Return PIL Image or Tensor: Rescaled image.将输入的图像(PIL Image or Tensor)的大小缩放到指定的size尺寸。size (sequence or int),当是sequence时则调整到指定的(h, w);当是int时,就将原图的min(h,w)调整到size大小,然后另一条边进行等比例缩放。 - RandomCrop(torch.nn.Module): Crop the given image
(PIL Image or Tensor)at a random location.在随机位置裁剪给定的size大小的图像(size的输入要求跟Resize一样)。
总结使用方法:
- 查看函数的官方文档(
Ctrl+点击进去):主要关注它的输入和输出是什么数据格式、所需的输入参数、作用是什么。 - 配合使用Debug:不清楚到变量image某一步的时候值或类型是什么的时候,可以打上断点,用Debug,然后在Debug的console执行type(image)、image.shape等操作进行查看。(可看下我的这篇文章:PyCharm的Debug和中断方法)
use_transforms.py
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
image_path = 'images/cat2.jpg'
image = Image.open(image_path)
writer = SummaryWriter('logs_2')
# 1.Totensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(image)
writer.add_image('ToTensor', img_tensor) # 这里只传入了tag和image_tensor,没有写入第3个参数global_step,则会默认是第0步
# 2.Normalize 可以改变色调
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(img_tensor)
writer.add_image('Normalize', img_norm)
trans_norm = transforms.Normalize([1, 3, 5], [3, 2, 1])
img_norm_2 = trans_norm(img_tensor)
writer.add_image('Normalize', img_norm_2, 1)
trans_norm = transforms.Normalize([2, 0.5, 3], [5, 2.6, 1.5])
img_norm_3 = trans_norm(img_tensor)
writer.add_image('Normalize', img_norm_3, 2)
# 3.Resize 将PIL或者tensor缩放为指定大小然后输出PIL或者tensor
w, h = image.size # PIL.Image的size先表示的宽再表示的高
trans_resize = transforms.Resize(min(w, h) // 2) # 缩放为原来的1/2
img_resize = trans_resize(image) # 对PIL进行缩放
writer.add_image('Resize', trans_totensor(img_resize)) # 因为在tensorboard中显示,所以需要转换为tensor或numpy类型
trans_resize = transforms.Resize(min(w, h) // 4) # 缩放为原来的1/4
img_resize_tensor = trans_resize(img_tensor)
writer.add_image('Resize', img_resize_tensor, 1)
# 4.compose 组合这些操作
trans_compose = transforms.Compose(
[transforms.Resize(min(w, h) // 2), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
img_campose = trans_compose(image) # image是PIL.Image格式
writer.add_image('Compose', img_campose)
# 5.Randomcrop 随机裁剪
trans_randomcrop = transforms.RandomCrop(min(w, h) // 4) # 从原图中任意位置裁剪1/4
# img_ranomcrop = trans_randomcrop(img_tensor)
for i in range(10):
img_ranomcrop = trans_randomcrop(img_tensor)
writer.add_image('RandomCrop', img_ranomcrop, i)
# close()一定要记得写啊!
writer.close()
P14:torchvision中的数据集使用
主要内容:
之前的课程中transforams是对单张图片进行处理,而制作数据集的时候,是需要对图像进行批量处理的。因此本节是将torchvision中的datasets和transforms联合使用对数据集进行预处理操作。
- (torchvision官方文档地址:https://pytorch.org/vision/stable/index.html)
torchvision.datasets中提供了内置数据集和自定义数据集所需的函数(DatasetFolder、ImageFolder、VisionDataset)。(torchvision.datasets官方文档地址:https://pytorch.org/vision/stable/datasets.html)torchvision.models中包含了已经训练好的图像分类、图像分割、目标检测的神经网络模型。(torchvision.models的官方文档地址:https://pytorch.org/vision/stable/models.html)
(图像分类还比较全面,目标检测不太全,没有包含yolo,可以去下载mmdetection包:https://github.com/open-mmlab/mmdetection)torchvision.transforms对图像进行转换和增强。(torchvision.transforms的官方文档地址:https://pytorch.org/vision/stable/transforms.html)torchvision.utils包含各种实用工具,主要用于可视化(tensorboard是在torch.utils.tensorboard中)。(torchvision.utils的官方文档地址:https://pytorch.org/vision/stable/utils.html)
太宝藏的UP主了,迅雷下载也教!源代码中会提供数据集的下载链接。例如用Ctrl+点击CIFAR10跳进其源码,往上翻一下就能看到下载链接是url = "https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz"。然后将这个链接粘贴进迅雷中就可以快速下载了!
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torchvision.transforms import transforms
# 1. 用transforms设置图片转换方式
data_transform = transforms.Compose([ # 用Compose将所有转换操作集合起来
transforms.ToTensor() # 因为CIFAR10数据集的每张图像size=(32,32)比较小,所以只进行ToTensor的操作
])
# 2. 加载内置数据集CIFAR10,并设置transforms(download最好一直设置成True)
# 1. root:(若要下载的话)表示数据集存放的根目录
# 2. train=True 或者 False,分别表示是构造训练集train_set还是测试集test_set
# 3. transform = data_transform,用自定义的data_transform对数据集中的每张图像进行预处理
# 4. download=True 或者 False,分别表示是否从网上下载数据集到root中(如果root下已有数据集,尽管设置成True也不会再下载了,所以download最好一直设置成True)
train_set = torchvision.datasets.CIFAR10('./dataset', train=True, transform=data_transform, download=True)
test_set = torchvision.datasets.CIFAR10('./dataset', train=False, transform=data_transform, download=True)
# 3. 写进tensorboard查看
writer = SummaryWriter('CIFAR10')
for i in range(10):
img, label = test_set[i] # test_set[i]返回的依次是图像(PIL.Image)和类别(int)
writer.add_image('test_set', img, i)
writer.close()
P15:DataLoader的使用
官方文档地址:torch.utils.data.DataLoader
CLASS torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False,
sampler=None, batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None,
multiprocessing_context=None, generator=None, *, prefetch_factor=2,
persistent_workers=False)
除了dataset(指明数据集的位置)之外的参数都设置了默认值。
torch.utils.data.DataLoader重点关注的参数有:
- dataset (Dataset):指明从哪个数据集加载数据(如上节中自定义的
train_set) - batch_size (int):每个批次(batch)加载多少样本。
- shuffle (bool):每轮(epoch)是否打乱样本的顺序。(最好设置成True)
- num_workers (int):有多少个子流程用于数据加载。
0表示主进程加载。(在Windows下只能设置成0,不然会出错!虽然default=0,但是最好还是手动再设置一下num_workers=0) - drop_last (bool):如果数据集大小不能被batch_size整除,则最后一个批次将会不完整(即样本数
False,即会保存最后那个不完整的批次)。

P16:神经网络的基本骨架-nn.Module的使用
主要内容:
- 搭建Neural Network骨架主要用到的包是
torch.nn,官方文档网址:https://pytorch.org/docs/stable/nn.html,其中torch.nn.Module很重要,是所有所有神经网络模块的基类(即自己搭建的网络必须继承torch.nn.Module基类),官方文档地址:https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module。 - 自己搭建模型时,集成torch.nn.Module后必须要重写两个函数:
__init__()和forward()。
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
P17:土堆说卷积操作(可选看)torch.nn.functional.conv2d
主要内容:
torch.nn包含了torch.nn.functional,两者中都包含了Conv、Pool等层操作,且用法和效果都是一样的(但是具体的输入参数有所不同)。本节是用的torch.nn.functional.conv2d举例,但其实在以后使用中,torch.nn.Conv2d更常用。
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1) → Tensor
CLASS torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=‘zeros’, device=None, dtype=None)
torch.nn.functional.conv2d中的Input、weight(也就是kernel)都必须是4维张量,每维的含义是[batch_size, C, H, W],必要的时候,可用reshape()或unsqueeze()对张量进行扩维。
(1) reshape是对改变tensor的形状,各维度的乘积与原本保持一致。
(2) unsqueeze是在指定维度上扩充一个1维。
import torch
x = torch.arange(15)
x2 = torch.reshape(x, [3, 5]) # 用list或tuple表示形状都可以
y1_reshape = torch.reshape(x, [1, 1, 3, 5]) # reshape:只要所有维度乘在一起的积不变,就可以任意扩充多个维度
y2_unsqueeze = torch.unsqueeze(x2, 2) # unsequeeze:第二个参数的数据类型是int,所以只能在指定维度上扩充一个1维(升维)
c_squeeze = torch.squeeze(y1_reshape) # sequeeze:只传入一个tensor参数,然后将tensor的所有1维删掉(降维)
print('x.shape:{}'.format(x.shape))
print('x2.shape:{}'.format(x2.shape))
print('y1_reshape.shape:{}'.format(y1_reshape.shape))
print('y2_unsqueeze.shape:{}'.format(y2_unsqueeze.shape))
print('c_squeeze.shape:{}'.format(c_squeeze.shape))
- 代码
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
print(input.shape)
print(kernel.shape)
# input、kernel都扩充到4维
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
out = F.conv2d(input, kernel, stride=1)
print('out={}'.format(out))
out2 = F.conv2d(input, kernel, stride=2)
print('out2={}'.format(out2))
out3 = F.conv2d(input, kernel, stride=1, padding=1)
print('out3={}'.format(out3))
P18:神经网络-卷积层 torch.nn.Conv2d
torch.nn.Conv2d的官方文档地址
CLASS torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=‘zeros’, device=None, dtype=None)
卷积动画的链接:https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
注意:
- 默认
bias=True,这说明PyTorch中Con2d是默认给卷积操作加了偏置的。 - 还有一些默认值:stride=1,padding=0等。
- out_channels输出通道数,相当于就是卷积核的个数。
- dilation:需要使用空洞卷积时再进行设置。
import torch
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import datasets
from torchvision.transforms import transforms
# 1. 加载数据
dataset = datasets.CIFAR10('./dataset', train=False, transform=transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
# 2. 构造模型
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1)
def forward(self, x):
return self.conv1(x)
writer = SummaryWriter('./logs/Conv2d')
# 3. 实例化一个模型对象,进行卷积
model = Model()
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images('imgs_ch3', imgs, step)
# 4. 用tensorboard打开查看图像。但是注意,add_images的输入图像的通道数只能是3
# 所以如果通道数>3,则可以先采用小土堆的这个不严谨的做法,在tensorboard中查看一下图片
outputs = model(imgs)
outputs = torch.reshape(outputs, (-1, 3, 30, 30))
writer.add_images('imgs_ch6', outputs, step)
step += 1
writer.close()
P19:神经网络-最大池化的使用 torch.nn.MaxPool2d
池化也可成为下采样(就是缩小输入图像尺寸,但是不会改变输入图像的通道数)。常见的有MaxPool2d、AvgPool2d等。相反有上采样MaxUnPool2d。
MaxPool2d的官方文档地址:https://pytorch.org/docs/stable/generated/torch.nn.MaxPool2d.html#torch.nn.MaxPool2d
CLASS torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
注意:
- stride默认=kernel_size
- ceil_mode默认是False,也就是说事向下取整
pool和conv后的图像尺寸N计算公式是一样的: N = ( W − F + 2 ∗ P ) / S + 1 N=(W-F+2*P)/S+1 N=(W−F+2∗P)/S+1,且都是默认N向下取整。

主要内容:
- 在构造tensor的时候,最好指定元素的数据类型是float,即在最后加上
dtype=torch.float32,这样后面有些操作才不会出错。 - 池化的作用:保持输入图像的特征,且减小输入量,能加快训练。
(就类似于B站视频有10080P的也会有720P的,720P虽然不如1080P那么高清,但是仍然能够看出视频中物体的特征信息,有点像打了马赛克一样) - 代码:
import torch
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.maxpool1 = nn.MaxPool2d(kernel_size=3) # 默认:stride=kernel_size,ceil_mode=False
self.maxpool2 = nn.MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, x):
return self.maxpool1(x), self.maxpool2(x)
model = Model()
# -------------1.上图例子,查看ceil_mode为True或False的池化结果--------------- #
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
input = torch.reshape(input, (-1, 1, 5, 5))
out1, out2 = model(input)
print('out1={}\nout2={}'.format(out1, out2))
# --------------2.加载数据集,并放入tensorboard查看图片----------------------- #
dataset = torchvision.datasets.CIFAR10('dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64, shuffle=True)
writer = SummaryWriter('./logs/maxpool')
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images('imgs', imgs, step)
imgs, _ = model(imgs)
writer.add_images('imgs_maxpool', imgs, step)
step += 1
writer.close()
P20:神经网络-非线性激活
官方文档地址:https://pytorch.org/docs/stable/nn.html#non-linear-activations-weighted-sum-nonlinearity
- 常用的:Sigmoid、ReLU、LeakyReLU等。
(1) Sigmoid ( x ) = σ ( x ) = 1 1 + exp ( − x ) \operatorname{Sigmoid}(x)=\sigma(x)=\frac{1}{1+\exp (-x)} Sigmoid(x)=σ(x)=1+exp(−x)1
(2) R e L U ( x ) = ( x ) + = m a x ( 0 , x ) ReLU(x)=(x)^+=max(0,x) ReLU(x)=(x)+=max(0,x)
(3) LeakyRELU ( x ) = { x , if x ≥ 0 negative_slope × x , otherwise \operatorname{LeakyRELU}(x)= \begin{cases}x, & \text { if } x \geq 0 \\ \text { negative\_slope } \times x, & \text { otherwise }\end{cases} LeakyRELU(x)={x, negative_slope ×x, if x≥0 otherwise - 作用:为模型引入非线性特征,这样才能在训练过程中训练出符合更多特征的模型。
- 其中有个参数是
inplace,默认为False,表示是否就地改变输入值,True则表示直接改变了input不再有另外的返回值;False则没有直接改变input并有返回值(建议是inplace=False)。
import torch
from torch import nn
input = torch.tensor([[3, -1],
[-0.5, 1]])
input = torch.reshape(input, (1, 1, 2, 2))
relu = nn.ReLU()
input_relu = relu(input)
print('input={}\ninput_relu:{}'.format(input, input_relu))
# input=tensor([[[[ 3.0000, -1.0000],
# [-0.5000, 1.0000]]]])
# input_relu:tensor([[[[3., 0.],
# [0., 1.]]]])
P21:神经网络-线形层及其他层介绍
主要内容:
- 本节课主要讲
Linear Layers中的torch.nn.Linear(in_features, out_features, bias=True)。默认bias=True。
对传入数据应用线性变换: y = x A T + b y=xA^T+b y=xAT+b
Parameters:
in_features– size of each input sample(每个输入样本的大小)out_features– size of each output sample(每个输出样本的大小)bias– If set to False, the layer will not learn an additive bias. Default: True(如果为False,则该层不会学习加法偏置,默认为true)
Shape:(相当于 H i n H_{in} Hin和 H o u t H_{out} Hout都是只分别关注输入、输出的最后一个维度的大小,在训练过程中,nn.Linear往往是当作的展平为一维后最后几步的全连接层,所以此时就只关注了通道数,即往往Input和Outputs是一维的)
Input: ( ∗ , H i n ) (*,H_{in}) (∗,Hin) where ∗ * ∗ means any number of dimensions including none and H i n = i n _ f e a t u r e s H_{in}=in\_features Hin=in_features.Outputs: ( ∗ , H o u t ) (*,H_{out}) (∗,Hout) where all but the last dimension are the same shape as the input and H o u t = o u t _ f e a t u r e s H_{out}=out\_features Hout=out_features.
“展平为一维”经常用到torch.nn.Flatten(start_dim=1, end_dim=- 1)
想说一下start_dim,它表示“从start_dim开始把后面的维度都展平到同一维度上”,默认是是1,在实际训练中从start_dim=1开始展平,因为在训练中的tensor是4维的,分别是[batch_size, C, H, W],而第0维的batch_size不能动它,所以是从1开始的。
- 还比较重要的有:torch.nn.BatchNorm2d、torch.nn.Dropout、
Loss Functions(之后再讲)。其它的Transformer Layers、Recurrent Layers都不是很常用。
import torch
# 对4维tensor展平,start_dim=1
input = torch.arange(54)
input = torch.reshape(input, (2, 3, 3, 3))
y_0 = torch.flatten(input)
y_1 = torch.flatten(input, start_dim=1)
print(input.shape)
print(y_0.shape)
print(y_1.shape)
# torch.Size([2, 3, 3, 3])
# torch.Size([54])
# torch.Size([2, 27])
P22:神经网络-搭建小实战和Sequential的使用
主要内容:
torch.nn.Sequential的官方文档地址,模块将按照它们在构造函数中传递的顺序添加。- 本节代码实现的是下图:

版本1——未用Sequential
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
# 3,32,32 ---> 32,32,32
self.conv1 = Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2)
# 32,32,32 ---> 32,16,16
self.maxpool1 = MaxPool2d(kernel_size=2, stride=2)
# 32,16,16 ---> 32,16,16
self.conv2 = Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2)
# 32,16,16 ---> 32,8,8
self.maxpool2 = MaxPool2d(kernel_size=2, stride=2)
# 32,8,8 ---> 64,8,8
self.conv3 = Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2)
# 64,8,8 ---> 64,4,4
self.maxpool3 = MaxPool2d(kernel_size=2, stride=2)
# 64,4,4 ---> 1024
self.flatten = Flatten() # 因为start_dim默认为1,所以可不再另外设置
# 1024 ---> 64
self.linear1 = Linear(1024, 64)
# 64 ---> 10
self.linear2 = Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
model = Model()
print(model)
input = torch.ones((64, 3, 32, 32))
out = model(input)
print(out.shape) # torch.Size([64, 10])
版本2——用Sequential
代码更简洁,而且会给每层自动从0开始编序。
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2, stride=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2, stride=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2, stride=2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
return self.model(x)
model = Model()
print(model)
input = torch.ones((64, 3, 32, 32))
out = model(input)
print(out.shape) # torch.Size([64, 10])
在代码最末尾加上writer.add_gragh(model, input)就可看到模型计算图,可放大查看。
writer = SummaryWriter('./logs/Seq')
writer.add_graph(model, input)
writer.close()

P23:损失函数与反向传播
害,不是很能理解每一个损失函数的计算过程,先放一个在这儿,只有在结合官方文档学习一下吧!pytorch损失函数之nn.CrossEntropyLoss()、nn.NLLLoss()
主要内容:
- 概念

- 所需的Loss计算函数都在torch.nn的LossFunctions中,官方网址是:https://pytorch.org/docs/stable/nn.html#loss-functions。本节课举例了L1Loss、MSELoss、CrossEntropyLoss。
- 在这些Loss函数的使用中,有以下注意的点:
(1) 参数reduction='mean',默认是'mean'表示对差值的和求均值,还可以是'sum'则不会求均值。
(2) 一定要注意Input和target的shape。
L1Loss
创建一个标准,用于测量中每个元素之间的Input: x x x 和 target: y y y。
创建一个标准,用来测量Input: x x x 和 target: y y y 中的每个元素之间的平均绝对误差(MAE)( L 1 L_1 L1范数)。

Shape:
- Input: ( ∗ * ∗), where ∗ * ∗ means any number of dimensions. 会对所有维度的loss求均值
- Target: ( ∗ * ∗), same shape as the input. 与Input的shape相同
- Output: scalar.返回值是标量。
假设 a a a 是标量,则有:
- type(a) = torch.Tensor
- a.shape = torch.Size([])
- a.dim = 0
MSELOSS
创建一个标准,用来测量Input: x x x 和 target: y y y 中的每个元素之间的均方误差(平方L2范数)。

Shape:
- Input: ( ∗ * ∗), where ∗ * ∗ means any number of dimensions. 会对所有维度求loss
- Target: ( ∗ * ∗), same shape as the input. 与Input的shape相同
- Output: scalar.返回值是标量。
CrossEntropyLoss
----------以下是自己对官方文档不准确的翻译----------
CLASS torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=- 100, reduce=None, reduction='mean', label_smoothing=0.0)
该标准计算 input 和 target 之间的交叉熵损失。
非常适用于当训练 C C C 类的分类问题(即多分类问题,若是二分类问题,可采用BCELoss)。如果要提供可选参数 w e i g h t weight weight ,那 w e i g h t weight weight 应设置为1维tensor去为每个类分配权重。这在训练集不平衡时特别有用。
期望的 input应包含每个类的原始的、未标准化的分数。input必须是大小为 C C C(input未分批)、( m i n i b a t c h , C minibatch,C minibatch,C) or ( m i n i b a t c h , C , d 1 , d 2 , . . . d k minibatch,C,d_1,d_2,...d_k minibatch,C,d1,d2,...dk)的Tensor。最后一种方法适用于高维输入,例如计算2D图像的每像素交叉熵损失。
期望的 target应包含以下内容之一:
(1) (target包含了)在 [ 0 , C ) [0,C) [0,C)区间的类别索引, C C C是类别总数量。如果指定了 ignore_index,则此损失也接受此类索引(此索引不一定在类别范围内)。reduction='none'情况下的loss为:
注意: l o g log log默认是以10为底的。
ℓ ( x , y ) = L = { l 1 , … , l N } ⊤ , l n = − w y n log exp ( x n , y n ) ∑ c = 1 C exp ( x n , c ) ⋅ 1 { y n ≠ ignore_index } \ell(x, y)=L=\left\{l_{1}, \ldots, l_{N}\right\}^{\top}, \quad l_{n}=-w_{y_{n}} \log \frac{\exp \left(x_{n, y_{n}}\right)}{\sum_{c=1}^{C} \exp \left(x_{n, c}\right)} \cdot 1\left\{y_{n} \neq \text { ignore\_index }\right\} ℓ(x,y)=L={l1,…,lN}⊤,ln=−wynlog∑c=1Cexp(xn,c)exp(xn,yn)⋅1{yn= ignore_index }
x x x是input, y y y是target, w w w是权重weight, C C C是类别数量, N N N涵盖minibatch维度且 d 1 , d 2 . . . , d k d_1,d_2...,d_k d1,d2...,dk分别表示第k个维度。(N太难翻译了,总感觉没翻译对)如果reduction='mean'或'sum',则公式为:
ℓ ( x , y ) = { ∑ n = 1 N 1 ∑ n = 1 N w y n ⋅ 1 { y n ≠ ignore_index } l n , if reduction = ’mean’; ∑ n = 1 N l n , if reduction = ’sum’ \ell(x, y)= \begin{cases}\sum_{n=1}^{N} \frac{1}{\sum_{n=1}^{N} w_{y_{n}} \cdot 1\left\{y_{n} \neq \text { ignore\_index }\right\}} l_{n}, & \text { if reduction }=\text { 'mean'; } \\ \sum_{n=1}^{N} l_{n}, & \text { if reduction }=\text { 'sum' }\end{cases} ℓ(x,y)={∑n=1N∑n=1Nwyn⋅1{yn= ignore_index }1ln,∑n=1Nln, if reduction = ’mean’; if reduction = ’sum’
Note that this case is equivalent to the combination of
LogSoftmaxandNLLLoss.
nn.CrossEntropyLoss()是nn.logSoftmax()和nn.NLLLoss()的整合,可以直接使用它来替换网络中的这两个操作。(softmax输出,所有输出概率和为1。NLLLoss:The negative log likelihood loss 负数对数似然损失)
(2) Probabilities for each class。这种不常用,官方也更建议使用第一种方式,那就不写了。
Shape:

好像一般采用的是:input.shape=(N,C),target.shape=(N)
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
dataset = torchvision.datasets.CIFAR10('./dataset', train=False, transform=transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2, stride=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2, stride=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2, stride=2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x): # 模型前向传播
return self.model(x)
model = Model() # 定义模型
loss_cross = nn.CrossEntropyLoss() # 定义损失函数
for data in dataloader:
imgs, targets = data
outputs = model(imgs)
# print(outputs) # 先打印查看一下结果。outputs.shape=(2, 10) 即(N,C)
# print(targets) # target.shape=(2) 即(N)
# 观察outputs和target的shape,然后选择使用哪个损失函数
res_loss = loss_cross(outputs, targets)
res_loss.backward() # 损失反向传播
print(res_loss)
#
# inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
# targets = torch.tensor([1, 2, 5], dtype=torch.float32)
#
# inputs = torch.reshape(inputs, (1, 1, 1, 3))
# targets = torch.reshape(targets, (1, 1, 1, 3))
#
# # -------------L1Loss--------------- #
# loss = nn.L1Loss()
# res = loss(inputs, targets) # 返回的是一个标量,ndim=0
# print(res) # tensor(1.6667)
#
# # -------------MSELoss--------------- #
# loss_mse = nn.MSELoss()
# res_mse = loss_mse(inputs, targets)
# print(res_mse)
#
# # -------------CrossEntropyLoss--------------- #
# x = torch.tensor([0.1, 0.2, 0.3]) # (N,C)
# x = torch.reshape(x, (1, 3))
# y = torch.tensor([1]) # (N)
# loss_cross = nn.CrossEntropyLoss()
# res_cross = loss_cross(x, y)
# print(res_cross)
P24:优化器(一)
官方文档地址:torch.optim
Debug过程中查看的grad所在的位置:
model --> Protected Atributes --> _modules --> ‘model’ --> Protected Atributes --> _modules --> ‘0’(任选一个conv层) --> weight(查看weight下的data和grad的变化)

简易训练代码,添加了Loss、Optim。
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
dataset = torchvision.datasets.CIFAR10('./dataset', train=False, transform=transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2, stride=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2, stride=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2, stride=2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x): # 模型前向传播
return self.model(x)
model = Model() # 定义模型
loss_cross = nn.CrossEntropyLoss() # 定义损失函数
optim = torch.optim.SGD(model.parameters(), lr=0.01) # lr不能过大或者过小。刚开始的lr可设置得较大一点,后面再对lr进行调节
len = len(dataloader)
for epoch in range(20):
total_loss = 0.0
for imgs, targets in dataloader:
outputs = model(imgs)
res_loss = loss_cross(outputs, targets)
optim.zero_grad() # 优化器对model中的每一个参数进行梯度清零
res_loss.backward() # 损失反向传播
optim.step() # 对model参数开始调优
total_loss += res_loss
print('epoch:{}\ttotal_loss:{}\tmean_loss:{}.'.format(epoch, total_loss, total_loss / len))
# epoch:0 total_loss:9374.806640625 mean_loss:1.8749613761901855.
# epoch:1 total_loss:7721.240234375 mean_loss:1.544248104095459.
# epoch:2 total_loss:6830.775390625 mean_loss:1.3661550283432007.
P25:现有网络模型的使用及修改
这节课以VGG为例,官方文档地址为:torchvision.models中的vgg。常用的是VGG16、VGG19。
注意:参数pretrained=True表示加载模型架构+训练好的参数,pretrained=False(default)表示只加载模型架构。一般最好设定为true。
预训练权重自己就默认下载到C:\Users\dadandan\.cache\torch\hub\checkpoints\vgg16-397923af.pth中了,大小为528MB。(想要更改pth默认下载位置,可参考这篇文章:Pytorch中更改预训练权重文件的下载位置)
VGG16是在ImageNet数据集中训练的,对1000种物体分类。那如何对自己的数据集分类呢?以CIFAR10为例,需要分出10个类别。
(嗨呀!真可恶!本来开弹幕是想看能不能学到另外的好方法,结果全是在说“早就没跟着写代码了,写代码太费时间了”,我就是老老实实跟着写代码,学了一个星期还没学完!本就心情不好了,还看到这样的话,就仿佛我跟着写代码是一种很蠢的行为一样!我不管,我要坚持把最后几节也学了!TMD)
方法1:直接在VGG16的模型架构后面再添加一层全连接层nn.Linear(1000,10),其中1000表示ImageNet分1000个类别,10表示CIFAR10要分出10个类别。
import torchvision
from torch import nn
# 1.加载现有模型,并通过设置pretrained是否选择也加载预训练权重参数
# 下载到C:\Users\dadandan\.cache\torch\hub\checkpoints\vgg16-397923af.pth
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
train_data = torchvision.datasets.CIFAR10('./dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
# 在vgg16最后面添加一层,取名叫'add_linear'
vgg16_true.add_module('add_linear', nn.Linear(1000, 10))
print(vgg16_true)

方法2:直接在VGG16的模型架构classifier中的后面再添加一层全连接层nn.Linear(1000,10)。可直接索引下标查看:print(vgg16_true.classifier[7])('add_linear’层在classifier中下标排序是7)。
# classifier的最后面添加一层,取名叫'add_linear'
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))

方法3:直接更改VGG16的模型架构classifier中的最后一层。
# 直接更改classifier的最后面一层
cls_len = len(vgg16_true.classifier) # 获取classifier共有多少层
vgg16_true.classifier[cls_len - 1] = nn.Linear(4096, 10)

P26:自定义的网络模型的保存与读取
模型保存:model_save.py
import torch
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
# 自定义的模型Model
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2, stride=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2, stride=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2, stride=2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x): # 模型前向传播
return self.model(x)
# 加载和保存自定义的模型
model = Model() # 还没有训练过,所以还没有参数,因此以下两种方式保存的文件大小应该是差不多的
# 保存方式1,保存模型 + 参数,文件体积会比方法2大
torch.save(model, './model/model1.pth')
# 保存方式2,保存参数为字典模式,文件体积会稍微小一些(官方推荐)
torch.save(model.state_dict(), './model/model2.pth')
模型加载:model_load.py
import torch
from model_save import Model # 导入自定义的模型
# way1:直接加载 模型+参数
model1 = torch.load('./model/model1.pth')
print(model1)
# way2:先构建模型,再加载参数(字典类型)
model2 = Model()
model2.load_state_dict(torch.load('./model/model2.pth'))
print(model2)
way1通过from model_save import Model导入自定义模型,但是这句话仍然会是灰色的。但是没有这句话就会报下面的错误。

P27:完整的模型训练套路(一)~(四)

在P30和P31,老师讲了怎么用Google Colab进行GPU加速,很值得看看!
注意:
-
加在代码中训练和验证阶段的
model.train()和model.eval()的意思分别是:将模块设置为训练模式、验证模式。这只对某些模块有影响(Doprout和batchNormalize)可详见官方文档解释。
(但是以防万一,还是加上model.train()、model.eval()比较好,因为就算没有Dropout和BatchNorm模块,加上也不会有错和不好的影响) -
argmax(1) 行方向 或 argmax(0)列方向 取最大值
import torch
# axis=0 行方向
# axis=1 列方向
output = torch.tensor([[0.1, 0.2],
[0.5, 0]])
target = torch.tensor([1, 0])
pred = output.argmax(1)
print(pred == target)
# 得到对应位置相等(为True)的个数
num = (pred == target).sum()
print(num)

to(device)利用GPU训练:网络模型、数据(输入、标注)、损失函数,loss和model可以直接写成loss.to(device)、model.to(device),但是数据必须要再接收一次:imgs = imgs.to(deivce)、targets = targets.to(device)。(为了减少记忆,就直接loss、model、imgs、targets全都再赋值回去吧)
# 定义训练的设备
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
-
计时,导入包
import time,再打点计时start = time.time(),end = time.time(),时间差t1 = end-start,是s级。 -
转换RGB三通道:
image=image.convert('RGB')。png是4通道,除了RGB外还有一个透明度通道;jpg是RGB三通道。

-
在
test.py中需要先对图像大小Resize成符合模型的输入大小32x32。 -
在train.py的验证阶段和test.py中,一定要记得使用
with torch.no_grad(),因为不用再优化梯度,这样可以节约内存、节约性能。 -
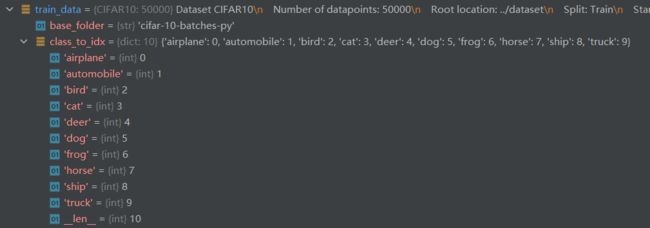
模型训练的数据集CIFAR10组成:
迅雷网盘分享:
链接:https://pan.xunlei.com/s/VN2LZwrGbf20guxIWpLph6WXA1
提取码:aggh
(1) model.py
import torch
from torch import nn
import torchvision
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
from torch.utils.tensorboard import SummaryWriter
# 写模型
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
return self.model(x)
if __name__ == '__main__':
model = Model()
print(model)
input = torch.ones((64, 3, 32, 32))
out = model(input)
print(out.shape)
(2) train.py
import os
import torch
from torch import nn
import torchvision
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
from model import Model
from torch.utils.tensorboard import SummaryWriter
# ------------------1. 一些定义---------------- #
# 定义训练的设备
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device: {}'.format(device))
# 指定pth存储文件夹
pth_dir = './model_pth'
if not os.path.exists(pth_dir): # os模块判断并创建
os.mkdir(pth_dir)
# 训练的轮数
epoch = 10
train_step = 0
test_step = 0
lr = 1e-2
# ------------------2.构建数据集----------------- #
trans = transforms.Compose([
transforms.Resize(32),
transforms.ToTensor()
])
train_data = torchvision.datasets.CIFAR10('../dataset', train=True, transform=trans, download=True)
test_data = torchvision.datasets.CIFAR10('../dataset', train=False, transform=trans, download=True)
# 数据集的长度
len_train = len(train_data)
len_test = len(test_data)
# -----------------3. 加载数据集(按照batchsize=64打包)-------------- #
train_load = DataLoader(train_data, 64, shuffle=True)
test_load = DataLoader(test_data, 64, shuffle=True)
# -----------------4. 模型、损失函数、优化器、摘要器------------- #
# 构建模型
model = Model()
model.to(device) # 用gpu训练
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)
# 优化器
optim = torch.optim.SGD(model.parameters(), lr=lr)
# 构建tensoroboard摘要器
writer = SummaryWriter('logs_train')
# 开始训练
for i in range(epoch):
print('-----------第 {} 轮训练开始-------------'.format(i + 1))
# 训练步骤开始
model.train()
for data in train_load: # train_load,每个循环包含了64张
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
out = model(imgs)
loss = loss_fn(out, targets)
# optim 优化模型
optim.zero_grad() # 梯度清零
loss.backward() # 损失反向传播
optim.step() # 优化
# writer
if train_step % 200 == 0:
print('训练步数: {}, Loss: {}'.format(train_step, loss.item()))
writer.add_scalar('train_loss', loss.item(), train_step)
train_step += 1
# 验证步骤开始
model.eval()
total_test_loss = 0
total_test_accuracy = 0
with torch.no_grad(): # 没有梯度,不会对其进行调优
for data in test_load:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
out = model(imgs)
loss = loss_fn(out, targets)
total_test_loss += loss.item()
accuracy = (out.argmax(1) == targets).sum().item()
total_test_accuracy += accuracy
print('整体测试集上的Loss: {}'.format(total_test_loss))
print('整体数据集上的准确率Acc: {}'.format(total_test_accuracy / len_test))
writer.add_scalar('test_loss', total_test_loss, test_step)
writer.add_scalar('test_Acc', total_test_accuracy / len_test, test_step)
test_step += 1
# 保存方式1
torch.save(model, pth_dir + '/model_{}.pth'.format(i))
# 保存方式2(官方推荐)
# torch.save(model.state_dict(), pth_dir + '/model_{}.pth'.format(i))
print('model_{}.pth 已保存'.format(i))
writer.close()
(3) test.py:对整个文件夹中的图像分类,并打印出类别,如’dog’。
注意看这里面的注释,写的挺清楚的,hhh~
import os
import torch
import torchvision
from PIL import Image
import time
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
classes = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
# Resize成符合模型的输入大小
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()
])
imagetype = ['bmp', 'dib', 'png', 'jpg', 'jpeg', 'pbm', 'pgm', 'ppm', 'tif', 'tiff']
imagelist_path = 'images'
imagelist = os.listdir(imagelist_path)
for imagename in imagelist:
start = time.perf_counter()
if imagename.split('.')[1] not in imagetype:
print('{} is not an image.'.format(imagename))
else:
# ----------------读取图像---------------- #
image_path = os.path.join(imagelist_path, imagename)
image = Image.open(image_path)
# ----------------调整图像---------------- #
image = image.convert('RGB') # 1.转为3通道图像
image = transform(image) # 2.调整图像尺寸为model输入的32x32
image = torch.unsqueeze(image, 0) # 3.升维为4维张量:[batchsize, C, H,W]
image = image.to(device) # 4.因为模型使用gpu训练的,所以验证时报错,让我也用gpu验证
# ----------------加载模型-------------- #
model = torch.load('./model_pth/model_9.pth')
model.to(device) # 5.model也用gpu加载,好像要比cpu快些
# ----------------开始测试-------------- #
model.eval()
with torch.no_grad():
output = model(image) # 输出的是各类别得分
# ----------------打印类别-------------- #
index = output.argmax(1).item()
print('这张图象的类别是:{}'.format(classes[index]))
end = time.perf_counter()
print('这张图像测试用时:{} s'.format(end - start))
完结,撒花❀❀❀❀❀❀❀❀❀❀❀