Pytorch框架--知识图谱可视化展示
文章目录
- 摘要
- 一. Pytorch框架基础学习
-
- 1.1 Dataset类的实战
- 1.2 tensorboard的使用
- 1.3 transforms如何使用
- 1.4 常见的Transforms的内置方法
- 1.5 torchvision数据集的使用
- 1.6 DataLoader的使用
- 二. Pytorch中神经网络的使用
- 三. 知识图谱可视化平台搭建与展示
-
- 3.1 安装neo4j 图数据库
- 3.2 使用Neo4j+InteractiveGraph实现豆瓣电影知识图谱可视化(对这个知识图谱的复现)
-
- 3.2.1 数据获取与导出成csv文件
- 3.2.2 csv文件批量导入neo4j图数据库
- 3.2.3 配置知识图谱可视化系统
- 3.2.4 启动可视化展示
- 小结
摘要
本章一是对pytorch 框架的基础使用,从Dataset类,到tensorboard的使用,与其中transform 的使用,以及常见的Transforms的内置方法,并学习了tensorboard可视化在训练模型其中的重要作用。还有torchvision数据集的使用案例DataLoader的使用,其就相当于对数据集 (Dataset) 一个打包的过程,以便更好的做后续的模型训练工作。(下节尽快完成基本模型的构建练习)
二是使用Neo4j+InteractiveGraph实现豆瓣电影知识图谱可视化(对这个知识图谱的复现)。其不足之处是对neo4j 图数据的Cypher语言的不熟悉,与对数据爬取,数据格式转换的不熟悉;最重要的是如何提取数据关系,创建节点,如何创建关系数据,这些都需要去加强。
一. Pytorch框架基础学习
1.1 Dataset类的实战
dataset 类是在获取图片地址路径和相对的图片,并划分训练集的标签。
1.获取文件夹,2.获取文件夹下的文件图片
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
# 初始化类的方法
# 1.获取文件夹,2.获取文件夹下的文件图片,图片的label标签是图片上一级的名称(ants) # dir是文件夹的意思
def __init__(self,root_dir,label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir)# 获取图片的路径地址(join拼接)
self.img_path = os.listdir(self.path) # 获取图片的(列表)
# 这是一个将数据看成序列去获取的方法(通过索引idx去获取图片相应的地址)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name) #获取每一个图片的位置(相对路径)
img = Image.open(img_item_path) #读取图片
label = self.label_dir
return img,label # 返回(img,label)
def __len__(self):
return len(self.img_path)
#创建 两个变量 (读取形式)
# 这便是解释了为什么需要把地址相加的原因,即可以重复使用类
root_dir="C:\\Users\\Administrator\\PycharmProjects\\pythonProject\\Dataset\\val"
ants_label_dir = "ants"
bees_label_dir = "bees"
# MyData类 实例化 对象
ants_dataset = MyData(root_dir,ants_label_dir) # 获取包含初始化函数中的变量
bees_dataset = MyData(root_dir,bees_label_dir)
print(ants_dataset[0])
print(bees_dataset[1])
# 输出( img,label)
train_dataset = ants_dataset + bees_dataset # 拼接训练集
注意:
getitem方法是可以返回: return img,label , 这里是没有去更改图片形式的,都是PIL image格式。
1.2 tensorboard的使用
tensorboard 是做为一个可视化的工具,具有比较好的效果。其在训练过程中是非常有用的,通过loss 每个步骤的可视化界面变化趋势,从而选择最合适的模型;也可以可视化在训练过程中每一步中图片数据的input,与其output 是怎么样的。
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("../logs") #将事件文件存储到logs文件下
image_path = "C:\\Users\\Administrator\\PycharmProjects\\pythonProject\\Dataset\\train\\ants_image\\0013035.jpg"
image_PIL = Image.open(image_path)
# print(type(image_PIL))
# <class 'PIL.JpegImagePlugin.JpegImageFile'>
image_array = np.array(image_PIL)
# 将PIL 转换成 numpy
print(type(image_array))
print(image_array.shape)
#输出图片的类型:<class 'numpy.ndarray'>
# 输出图片的形状:(512, 768, 3) (H,w,c)(高度,宽度,通道)
writer.add_image("test",image_array,1,dataformats='HWC')
# 上面是通过PIL获取的,而如果通过opencv 读取图片 就是numpy形式的,(也可以转换成tensor形)
# 或者使用opencv : cv_img = cv2.imread(img_path)
#假设显示y=x的
for i in range(100):
writer.add_scalar("y=x",i,i)
# tag-图表的标题,Scalar——value-是需要保存的数值(对应y轴), global_step -对应x轴
writer.close()
1.3 transforms如何使用
- Transforms在python中如何使用
- 为什么需要Tesnor 数据类型, 答案毫无疑问,其是里面包含神经网络模型训练的必要属性。
from PIL import Image
import cv2
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# python中的用法 》 tensor 的数据类型
# 通过transforms.Totensor 去看两个问题:
#1. Transforms在python中如何使用
#2. 为什么需要Tesnor 数据类型, 答案毫无疑问,其实是里面包含神经网络模型训练的必要属性
writer = SummaryWriter("../logs")
img_path = "C:\\Users\\Administrator\\PycharmProjects\\pythonProject\\Dataset\\train\\ants_image\\0013035.jpg"
img = Image.open(img_path) # 通过python内置的方式读取的图片(常用的读取图片的两种方式)
# 或者使用opencv : cv_img = cv2.imread(img_path)
# print(img)
# 问题1
tensor_trans = transforms.ToTensor() #直接在Transforms工具箱中引用ToTensor返回一个totensor的对象
tensor_image = tensor_trans(img) # 可查看其参数是 pic (cltrl+p) result=tool(input)
# 将一个image转换成tensor的image
# print(tensor_image)
writer.add_image("Tensor_img",tensor_image) # 将转换成tensor形图片可视化
writer.close()
需要注意: 打开tensorboard 的方法是在终端(Terminal)中输入:tensorboard --logdir=logs --port=6006(可指定端口)(logs为所保存事件日志的文件)
1.4 常见的Transforms的内置方法
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("../logs")
img= Image.open("C:\\Users\\Administrator\\PycharmProjects\\pythonProject\\Dataset\\train\\ants_image\\0013035.jpg")
print(img)
# Totensor的使用
tensor_trans = transforms.ToTensor()
tensor_image = tensor_trans(img)
writer.add_image("Tensor",tensor_image)
# ToPILImage 是将tensor or ndarray to PIL Image
# Normalize的使用(均值和方差进行归一化) ,将输入数据 正态化,使平均值1方差为0. output[-1,1]
print(tensor_image[0][0][0])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]) # 注意RGB有三个维度/信道 ,参数有(mean,std )
img_norm = trans_norm(tensor_image) #output[channel] = (input[channel] - mean[channel]) / std[channel]
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm,3)
# Resize的使用
print(img.size)
trans_resize = transforms.Resize((512,512))
# img PIL => resize => img_resize
img_resize = trans_resize(img)# 重置PIL格式图片的大小
# img PIL =>resize => tensor => img_resize tensor
# 新版本中Resize()可以是PIL,也可以是tensor 形式
img_resize= tensor_trans(img_resize)
# print(img_resize.size)
writer.add_image("Resize",img_resize,0)
# print(img_resize)
# compose 的使用 (其中都有内置函数call() )
# compose()的用法,其中的参数需要的是一个列表,数据需要transforms类型1,transforms类型2,.....,即compose([参数1,参数2,...])
# compose() 是把多参数的功能整合,比如下面第一个参数是改变图像大小,第二个参数是转换类型。
# compose() -resize -2 (resize的用法2)
trans_resize_2 = transforms.Resize(512) # 对图片进行等比缩放
# 从 PIL => PIL => tensor
trans_compose = transforms.Compose([trans_resize_2,tensor_trans]) # 列表里面的都是方法,前一个输出会是后一个的输入!
# 新版本中Resize()可以是PIL,也可以是tensor 形式
img_resize_2 = trans_compose(img) #PIL img 是resize 的input
writer.add_image(" compose_resize_2",img_resize_2 ,1)
print(img_resize_2.size)
# 随机裁剪 RandomCrop
trans_random = transforms.RandomCrop((500,500))
trans_compose_2 = transforms.Compose([trans_random,tensor_trans])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomcropHW",img_crop,i)
writer.close()
1.5 torchvision数据集的使用
CIFAR-10 数据集由 10 个类别的 60000 张 32x32 彩色图像组成,每类 6000 张图像。 有 50000 张训练图像和 10000 张测试图像。
参数有
root (string) – 数据集的根目录,其中目录 cifar-10-batches-py 存在或将在下载设置为 True 时保存到。
train (bool, optional) – 如果为 True,则从训练集创建数据集,否则从测试集创建。
transform (callable, optional) – 一个函数/转换,它接收一个 PIL 图像并返回一个转换后的版本。 例如,transforms.RandomCrop
target_transform (callable, optional) – 一个接收目标并转换它的函数/转换。
download (bool, optional) – 如果为 true,则从 Internet 下载数据集并将其放在根目录中。 如果数据集已经下载,则不会再次下载。
import torchvision
from torch.utils.tensorboard import SummaryWriter
# torchvision数据集的使用
dataset_transforms = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()])
# CIFAR-10 数据集由 10 个类别的 60000 张 32x32 彩色图像组成,每类 6000 张图像。 有 50000 张训练图像和 10000 张测试图像。
# 参数
# root (string) – 数据集的根目录,其中目录 cifar-10-batches-py 存在或将在下载设置为 True 时保存到。
#
# train (bool, optional) – 如果为 True,则从训练集创建数据集,否则从测试集创建。
#
# transform (callable, optional) – 一个函数/转换,它接收一个 PIL 图像并返回一个转换后的版本。 例如,transforms.RandomCrop
#
# target_transform (callable, optional) – 一个接收目标并转换它的函数/转换。
#
# download (bool, optional) – 如果为 true,则从 Internet 下载数据集并将其放在根目录中。 如果数据集已经下载,则不会再次下载。
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transforms,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transforms,download=True)
# print(test_set[0])
# # (img,label)
# print(test_set.classes[3])
# 这一个是在PIL image 格式下才可执行img.show()
# img,label = test_set[0]
# print(img)
# print(label)
# print(test_set.classes[label])
# img.show()
# print(test_set[0]) # 这里输出更改位tensor 形式后 输出第一张图片
writer = SummaryWriter("../P10logs")
for i in range(11):
img,target = test_set[i]
writer.add_image("test_set",img,i)
writer.close()
1.6 DataLoader的使用
Datalodaer的参数
数据集 (Dataset) – 从中加载数据的数据集。
batch_size (int, optional) – 每批加载的样本数量(默认值:1)。
shuffle (bool, optional) – 设置为 True 以在每个时期重新洗牌数据(默认值:False)。
batch_sampler(Sampler 或 Iterable,可选)——类似于采样器,但一次返回一批索引。与 batch_size、shuffle、sampler 和 drop_last 互斥。
num_workers (int, optional) – 用于数据加载的子进程数量。 0 表示数据将在主进程中加载。 (默认值:0)
collate_fn (callable, optional) – 合并一个样本列表以形成一个小批量的 Tensor(s)。在使用来自地图样式数据集的批量加载时使用。
drop_last (bool, optional) – 如果数据集大小不能被批处理大小整除,则设置为 True 以删除最后一个不完整的批处理。如果为 False 并且数据集的大小不能被批量大小整除,那么最后一批将更小。 (默认:假)
# DataLoader的使用
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备测试数据集 test_data
# Datalodaer的参数
# 数据集 (Dataset) – 从中加载数据的数据集。
# batch_size (int, optional) – 每批加载的样本数量(默认值:1)。
# shuffle (bool, optional) – 设置为 True 以在每个时期重新洗牌数据(默认值:False)。
# batch_sampler(Sampler 或 Iterable,可选)——类似于采样器,但一次返回一批索引。与 batch_size、shuffle、sampler 和 drop_last 互斥。
# num_workers (int, optional) – 用于数据加载的子进程数量。 0 表示数据将在主进程中加载。 (默认值:0)
# collate_fn (callable, optional) – 合并一个样本列表以形成一个小批量的 Tensor(s)。在使用来自地图样式数据集的批量加载时使用。
# drop_last (bool, optional) – 如果数据集大小不能被批处理大小整除,则设置为 True 以删除最后一个不完整的批处理。如果为 False 并且数据集的大小不能被批量大小整除,那么最后一批将更小。 (默认:假)
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
# batch_size 每次随机采样抓取64张图片 (可查看)
# 准备测试集的第一张 图片及label
# test_data 是一个测试集Dataset
img,target = test_data[0]
print(img.shape)
print(target)
# test_loader相当于一个打包的过程,怎么取出test_loader中的每一个返回,前提(torch.Tensor, numpy.array, or string/blobname)
writer = SummaryWriter("../logs1")
step=0
for data in test_loader:
imgs,targets=data
# print(imgs.shape)
# print(targets)
writer.add_images("test_data",imgs,step)
step = step+1
writer.close()
注意: batch_size 每次随机采样抓取64张图片 (可查看),如果将drop_last=True,则会出现不去最后不足64张的)。
如图所示:
如果迭代epoch采样的话:需要修改
# test_loader相当于一个打包的过程,怎么取出test_loader中的每一个返回,前提(torch.Tensor, numpy.array, or string/blobname)
writer = SummaryWriter("../logs1")
for epoch in range(2):
step=0
for data in test_loader:
imgs,targets=data
# print(imgs.shape)
# print(targets)
writer.add_images("epoch:{}".format(epoch),imgs,step)
step = step+1
writer.close()
当shuffle=True结果会出现,同样的step时,其采样会被重新洗牌的。如果为False则会出现一样的采样结果。如图:
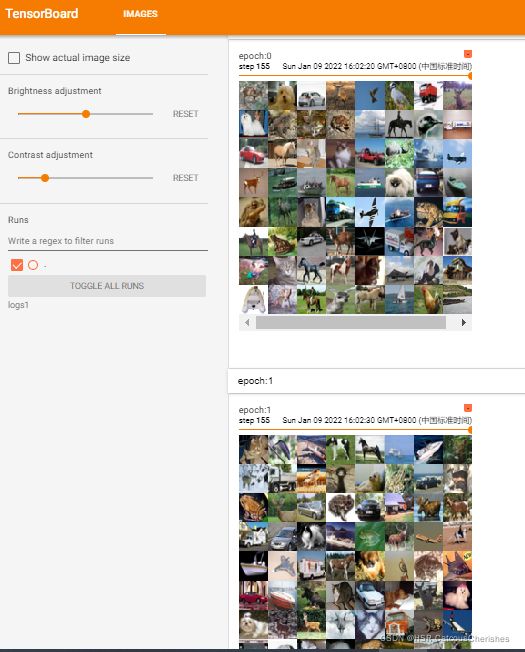
以上所做都是在做神经网络的输入,如何去采用pytorch框架去处理数据的。下节将对具体神经网络去练习使用,以及如何去构建一个完整的模型去做训练与测试。
二. Pytorch中神经网络的使用
三. 知识图谱可视化平台搭建与展示
3.1 安装neo4j 图数据库
neo4j是用Java语言编写的图形数据库,运行时需要启动JVM进程,因此,需安装JAVA SE的JDK。
安装时需要注意版本对应问题:可参考JDK与Neo4j版本对应。
安装JDK官网:下载地址
安装教程:最详细版安装JDK
配置环境变量后,安装好后cmd输入java -version检查是否安装好。
下载匹配的 Neo4j 社区版(Community)官网:下载地址,下载好后解压到自己想放的盘里。
Neo4j应用程序有如下主要的目录结构:
- bin目录:用于存储Neo4j的可执行程序;
- conf目录:用于控制Neo4j启动的配置文件;
- data目录:用于存储核心数据库文件;
- plugins目录:用于存储Neo4j的插件;
安装参考教程请测:安装ne04j(server)
安装并简单使用教程:neo4j的安装与简单使用
配置环境变量后,测试是否安装成功,输入neo4j.bat console,启动数据库。(不要关闭)随后打开浏览器:输入默认登入端口地址
http://localhost:7474/browser/
即可登入修改创建图数据库。
3.2 使用Neo4j+InteractiveGraph实现豆瓣电影知识图谱可视化(对这个知识图谱的复现)
首先需要知道:
1.InteractiveGraph-neo4j基于Neo4j数据库为InteractiveGraph提供服务器后端。
2.InteractiveGraph为大型图数据提供了一个基于web的交互操作框架,其数据可以来自于GSON文件,或者在线Neo4j图数据库。
InteractiveGraph 同时也提供了三个基于本框架的应用:图导航器(GraphNavigator), 图浏览器(GraphExplorer) 和 关系查找器(RelFinder)。
参考文章:参考案例原文
基于电影数据集构建了一个电影知识图谱。其中包括电影、演员、导演三种节点及相关关系。并使用InteractiveGraph对图谱完成可视化工作。
3.2.1 数据获取与导出成csv文件
数据来自openKG,抽取自豆瓣电影。数据集为JSON格式,在导入Neo4j之前还需要做一些处理。
下面是处理方式:(在pycharm中将JSON文件导入)
import pandas as pd
import numpy as np
# 读入数据集 特别注意需要格式为 utf-8
data = pd.read_json('data/dbmovies.json', dtype=object,encoding='utf-8')
#由于最终构建的图谱包含**电影**和**人**这两类节点,因此需要将人#物信息从电影信息中**抽取**出来。观察数据集可以发现,人物信息出
#现在主演、导演和编剧这三个字段中,所以需要将这三类信息转换成边
#信息并合并出人员节点数据。
# 对主演、导演和编剧这三个字段
person = pd.DataFrame()
labels = ['actor', 'director', 'composer']
for label in labels:
df = data[['id', label]]
df = df.dropna(axis=0, how='any')
df = pd.DataFrame({'id': df['id'].repeat(df[label].str.len()),
label: np.concatenate(df[label].values)})
person = pd.concat([person, df[label]], axis=0)
df.to_csv('data/' + label + '.csv', index=True,encoding='utf_8_sig')
person.drop_duplicates(inplace=True)
person.to_csv('data/person.csv', index=True,encoding='utf_8_sig')
#---------
# 对电影语言,类型,其他,这样的数组信息转换成字符串,导出成csv文件
data.drop(labels, axis=1, inplace=True)
list_labels = ['category', 'district', 'language', 'othername']
for list_label in list_labels:
data[list_label] = data[list_label].apply(lambda x: '、'.join(x) if x!=None else x)
data.to_csv('data/movie.csv', index=True,encoding='utf_8_sig')
3.2.2 csv文件批量导入neo4j图数据库
首先需要创建一个kg_movie的库:在conf配置文件中修改即可,然后重新启动服务。再把所有导出的CSV文件拷贝到Neo4j安装目录下的import目录中,并启动Neo4j。
//使用如下Cypher导入电影节点数据:
USING PERIODIC COMMIT 500
LOAD CSV WITH HEADERS FROM 'file:///movie.csv' AS line
CREATE (:Movie{
id: line.id,
name: line.title,
url: line.url,
image: line.cover,
rate: toFloat(line.rate),
category: line.category,
district: line.district,
language: line.language,
showtime: toInteger(line.showtime),
length: toInteger(line.length),
othername: line.othername
})
//导入人物数据:
USING PERIODIC COMMIT 500
LOAD CSV FROM 'file:///person.csv' AS line
CREATE (:Person{name:line[0]})
//创建对节点字段做索引
CREATE INDEX ON :Movie(id)
CREATE INDEX ON :Movie(name)
CREATE INDEX ON :Person(name)
//创建三种关系,分别是(人物)-[:饰演]->(电影),(人物)-[:导演]->(电影)和(人物)-[:编剧]->(电影)
//1
USING PERIODIC COMMIT 500
LOAD CSV WITH HEADERS FROM 'file:///actor.csv' AS line
MATCH (p:Person) where p.name = line.actor WITH p,line
MATCH (m:Movie) where m.id = line.id
MERGE (p)-[:play]->(m)
//2
USING PERIODIC COMMIT 500
LOAD CSV WITH HEADERS FROM 'file:///director.csv' AS line
MATCH (p:Person) where p.name = line.director WITH p,line
MATCH (m:Movie) where m.id = line.id
MERGE (p)-[:direct]->(m)
//3
USING PERIODIC COMMIT 500
LOAD CSV WITH HEADERS FROM 'file:///composer.csv' AS line
MATCH (p:Person) where p.name = line.composer WITH p,line
MATCH (m:Movie) where m.id = line.id
MERGE (p)-[:write]->(m)
3.2.3 配置知识图谱可视化系统
包括两个部分:InteractiveGraph和InteractiveGraph-neo4j:
Interactivehttps://blog.csdn.net/weixin_45965683/article/details/121342594Graph为可视化系统的Web前端部分,负责显示和交互;InteractiveGraph-neo4j为可视化系统的后端部分,负责管理数据以及提供各种数据访问接口。
InteractiveGraph-neo4j安装与配置:
从github下载最新的发行版war包:下载地址,将下载完成的war包放到Tomcat的webapps目录中,tomcat会自动解压war包生成graphserver文件夹。
下载安装部署tomcat的教程:Apache Tomcat
修改配置生成的文件graphserver/WEB_INF/conf1.properties:
allowOrigin=*
backendType=neo4j-bolt
neo4j.boltUrl=bolt://localhost:7687
neo4j.boltUser=neo4j
neo4j.boltPassword=neo4j
neo4j.regexpSearchFields=name
neo4j.strictSearchFields=label:name
neo4j.nodeCategories=Person:人物,Movie:电影
layout_on_startup=false
visNodeProperty.label==$prop.name
visNodeProperty.value==$prop.rate
visNodeProperty.image==$prop.image
visNodeProperty.x ==$prop.x
visNodeProperty.y ==$prop.y
visNodeProperty.info=<p align=center> #if($prop.image) <img width=150 src="${prop.image}"><br> #end <b>${prop.name}</b></p><p align=left><ul><li>评分:${node.rate}</li><li>类型:${node.category}</li><li>时长:${node.length}分钟</li><li>语言:${node.language}</li></ul></p>
# 其中visNodeProperty.info:前端信息面板的展示代码。
InteractiveGraph安装与配置:
从github下载最新的发行版:下载地址
igraph.zip 包含InteractiveGraph的js,css 文件,可以结合项目README的流程自行使用。(将得到两个文件: interactive-graph.min.js 和 interactive-graph.min.css.)
在 HTML 中引入 .js 和 .css 文件:
<script type="text/javascript" src="./lib/interactive-graph-0.1.0/interactive-graph.min.js"></script>
<link type="text/css" rel="stylesheet" href="./lib/interactive-graph-0.1.0/interactive-graph.min.css">
使用在 igraph 中定义的函数和类:
<script type="text/javascript">
igraph.i18n.setLanguage("chs");
var app = new igraph.GraphNavigator(document.getElementById('graphArea'));
app.loadGson("honglou.json");//honglou.json为JSON文件格式。
</script>
使用honglou.json中的数据创建一个 GraphNavigator 应用对象。(自行配置可以完成一个小demo)
修改配置:
igraph.i18n.setLanguage("chs");
var app = new igraph.GraphNavigator(document.getElementById('graphArea'), 'LIGHT');
//修改了这下面↓,上面不要改//其中localhost:8080为graphserver的地址
app.connect("http://localhost:8080/graphserver/connector-bolt");
3.2.4 启动可视化展示
GraphNavigator:图导航器,提供对整个图的全局视图可视化预览。
下面是展示复现的案例:(在浏览器中打开:http://IP:端口号/igraph/example.html)

下面做一个知识图谱项目汇总案例:(参考博客)github上知识图谱项目汇总
小结
- 下节尽快完成对pytorh 框架的后续模型使用;
- 学习知识图谱的基本理论知识(关键步骤,重点,难点),与后续知识图谱嵌入技术;
- 对爬虫技术的学习
- 前端JS的学习(这个也比较重要)