词嵌入及方法one-hot、词袋、TFIDF
词嵌入
1. 词嵌入的含义
机器学习和深度学习等统计算法处理数字。要对文本应用统计算法,你需要将文本转换为数字。例如,你不能将两个词 apples 和 oranges加起来。你需要将文本转换为数字才能对单词应用数学运算。
词嵌入实际上是一类技术,单个词在预定义的向量空间中被表示为实数向量,每个单词都映射到一个向量。举个例子,比如在一个文本中包含“猫”“狗”“爱情”等若干单词,而这若干单词映射到向量空间中,“猫”对应的向量为(0.1 0.2 0.3),“狗”对应的向量为(0.2 0.2 0.4),“爱情”对应的映射为(-0.4 -0.5 -0.2)(本数据仅为示意)。像这种将文本X{x1,x2,x3,x4,x5……xn}映射到多维向量空间Y{y1,y2,y3,y4,y5……yn },这个映射的过程就叫做词嵌入。
之所以希望把每个单词都变成一个向量,目的还是为了方便计算,比如“猫”,“狗”,“爱情”三个词。对于我们人而言,我们可以知道“猫”和“狗”表示的都是动物,而“爱情”是表示的一种情感,但是对于机器而言,这三个词都是用0,1表示成二进制的字符串而已,无法对其进行计算。而通过词嵌入这种方式将单词转变为词向量,机器便可对单词进行计算,通过计算不同词向量之间夹角余弦值cosine而得出单词之间的相似性。

2. 词嵌入的方法
SKlearn 库中可以构建绝大部分模型
sklearn.feature_extraction.text
离散表示
- one-hot 编码
- 词袋模型(bag of words)
- TF-IDF方法
- n-gram模型
**神经网络表示 **
- Word2Vec
- sense2vec
2.1 离散表示

2.1.1 one-hot 编码
核心思想: 文档中每个单词的出现都是独立的,与其他词无关。对单词编码后的向量中只有数字0和1, 且其中只有一个维度是1。

劣势: 稀疏矩阵;高维;无法学习语义,向量间的距离无法反映语义差异
应用: 输出类别标注

2.1.2 bag of words
核心思想intuition: 文档中每个单词的出现都是独立的,每个词都有独一无二的含义,与其他词无关。考虑单个文档中词频的重要性,忽略词序、词义、语境。

优劣:
优势:向量表示比one-hot稠密,但依然很稀疏,考虑词频信息
劣势:稀疏矩阵;高维;无法学习语义信息,向量间的距离无法反映语义差异
应用场景 长文档(每个文档的单词数多)的文档表示
2.1.3 TF-IDF(term frequency–inverse document frequency)
核心思想intuition:如果某个单词在一篇文章中出现的频率(Term-Frequency,TF),并且在其他文章中很少出现,则认为词或者短语具有很好的类别区分能力,适合用来分类;用以评估一个字词在所有文档中的重要程度。字词的重要性随着它在单个文档中出现的次数成正比增加,但同时随着它在所有文档中出现的频率成反比下降。

案例
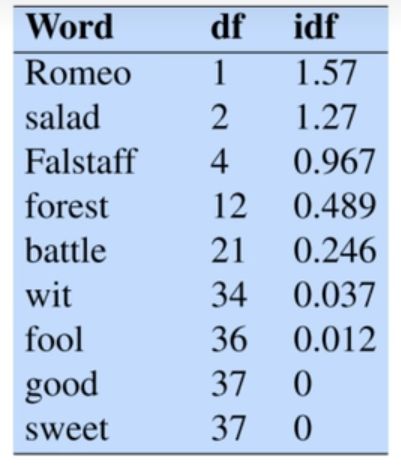
优劣势
优势:考虑了单一文档中的词频信息、以及词在所有文档中的相对重要性
劣势:没有词义
应用场景: 关键词抽取、主题词抽取;计算文档间的相似性,文档聚类。
2.1.4 n-gram模型
intuition 分布假设:相似的词往往出现在同一环境中(例如,在眼睛或检查等词附近)。出现在非常相似的分部(其相邻的词是相似的)中的两个词具有相似的含义
n-gram模型为了保持词的顺序,做了一个滑窗的操作,这里的n表示的就是滑窗的大小,例如2-gram模型,也就是把2个词当做一组来处理,然后向后移动一个词的长度,再次组成另一组词,把这些生成一个字典,按照词袋模型的方式进行编码得到结果。改模型考虑了词的顺序。
John likes to watch movies. Mary likes too
John also likes to watch football games.
以上两句可以构造一个词典,{"John likes”: 1, "likes to”: 2, "to watch”: 3, "watch movies”: 4, "Mary likes”: 5, "likes too”: 6, "John also”: 7, "also likes”: 8, “watch football”: 9, “football games”: 10}
那么第一句的向量表示为:[1, 1, 1, 1, 1, 1, 0, 0, 0, 0],其中第一个1表示John likes在该句中出现了1次,依次类推。
**缺点:**随着n的大小增加,词表会成指数型膨胀,会越来越大。
2.1.5 2.5 离散表示存在的问题
由于存在以下的问题,对于一般的NLP问题,是可以使用离散表示文本信息来解决问题的,但对于要求精度较高的场景就不适合了。
无法衡量词向量之间的关系。
词表的维度随着语料库的增长而膨胀。
n-gram词序列随语料库增长呈指数型膨胀,更加快。
离散数据来表示文本会带来数据稀疏问题,导致丢失了信息,与我们生活中理解的信息是不一样的。