City2vec:一种学习人口迁徙网络知识的新方法
今天给大家分享一篇最新录用在SCS(可持续城市与社会)上的文章,这个期刊主要关注城市的能源与建筑,也有很多GIS相关的如街景,健康分析,城市光伏能源的有趣应用,文末有对应的手稿分享。
SCS期刊信息
这篇文章是2020年的寒假开始收集数据,当初在床上躺着刷手机,无意中看到了腾讯地图数据提供了手机号码字段,这种数据不仅可以为商业营销有帮助(因为有POI所有者的营业类型,可以做商业的精准推送,也应用到了手机接听电话来识别出电话所有者),也在GIS的人口流动中具有应用潜力,连夜赶紧把全国的数据下载下来,大概有8,000万条左右,含有11位电话号码(非座机)的数据大概有一千万条。其中大部分都是使用的本地手机号,但是其中依然有266万条记录显示手机归属地与POI所在地不同的情况,这其实就暗含了一个人口流动的隐含信息,这与百度或腾讯迁徙记录短期交通不同,这个隐含交互记录的是人口的中长期流动,本文的动机也基于这种短期与长期流动的差异展开。话不多说,直接上内容。
● 摘要
由于社会和经济发展的需要,城市之间的人口流动经常大规模发生。城市之间自发的人口流动构成了一个规模巨大的移动网络,尽管已经有相当多的研究利用复杂网络的相关算法来解析这一结构,但仍无法定量描述不同城市之间的差异和相似之处。我们使用图嵌入算法,将传统的复杂网络对城市的一维认知方法扩展到二维认知。它可以通过学习人口流动关系,将城市信息投射到一个高维的数学空间,并计算出一个独特的向量表示。我们解析了腾讯电子地图提供的全国334个城市约8000万个POI中的手机号码数据,构建了一个包含2,662,596条有向边的城市移动网络,可以有效地捕捉到长期、长距离的人口迁移。城市嵌入实际上是移动网络的一个降维表示,可以保留更丰富的原始信息。我们的研究方法不仅可以完成传统复杂网络分析方法可以完成的任务,还可以实现对城市更高维度的认知(如城市之间的倾向性、空间关系和城市群的成熟度),是对传统图论方法的有效补充。
随着中国经济的快速发展和交通基础设施的进一步完善,人口迁移的规模也越来越大。根据中国2020年人口普查,35%的中国人口的户籍与他们的实际位置不一致,大约有4.9276亿人在城市之间自由流动,包括1.2484亿人跨省流动。如此规模的人口流动是人们自发选择和 "用脚投票 "的结果。经济学家Charles Tiebout提出,在对人口流动没有行政限制的假设下,大量的地方政府具有相同的税收制度和公开透明的信息。由于各城市的公共服务、就业机会和税收政策各不相同,居民会选择在提供最大利益的城市定居。居民可以自由地搬离不满意的地区,进入可以满足他们个人喜好的地区。
在中国城市化的前半段,由于沿海地区的城市率先实施改革开放政策,实行市场经济体制,提供税收减免和开放市场,它们吸引了大量的海外资本和技术。东部沿海地区经济迅速发展,对劳动力的需求急剧上升。由于更高的收入水平和更好的就业条件的吸引,大量的人从发展中的内陆地区迁移到更发达的沿海地区。在中国城市化的后半段,随着经济体制改革的逐步深入,资本、产业和人口的流动加快,内陆城市群的资源向中心城市内部富集。由于大城市可以提供更好的医疗服务,拥有更高的教育水平和更多样的工作选择;农村人口和中小城市人口向内陆地区中心城市的迁移也随之发生。上述两种方式是过去30年中国人口流动的主要动力,意味着一个复杂的群体决策和自然选择的过程。
人口迁移是人类跨地域流动的最重要表现(例如,在两个城市之间)。它通常涉及居住地的短期或长期变化,由自然环境、社会经济和政治等相关因素所驱动。越来越多的高度细化的时空数据为理解城市间的人类流动提供了最重要的来源。提取描述人类流动的隐藏模式是城市研究的长期挑战之一。
然而,在中国,识别人的长期流动比识别短期流动更加困难。人们可能会在短期内到另一个城市出差或到交通枢纽城市换乘交通工具。这将产生很多订单数据,这种短期流动很容易被捕捉到,而相当多的商业公司提供相应的数据接口。识别长期流动的最简单方法是从驾驶执照或户籍管理部门获得数据。由于中国的户籍管理制度,经济发达的城市设置了准入门槛。这导致相当一部分人在当地工作但没有被记录。为了摸清中国人口的实际分布情况,政府在过去70年里进行了7次大规模的人口普查。这种普查规模大、成本高、耗时长,最近的一次普查组建了67.9万个普查机构,雇用了700多万名普查人员。
电子地图是现实世界的孪生表示,丰富的数据为研究人口的长期流动性提供了新的机会。例如,餐厅类POI的所有者会提供一个电话号码供顾客联系。电话号码的第四至第七位数字代表用户的手机号码注册的城市。如果POI手机注册的城市与POI所在的城市不一样,那么这就隐含了一个从城市A到城市B的来源-目的地(OD)关系。当人们改变他们的居住地时,手机号码一般不会改变。在全国8000万个腾讯电子地图POI数据中,存在2,662,596条类似的互动OD信息。利用这些信息,我们可以构建一个全国规模的 "移动网络",以揭示人口的长期流动性。
为了处理这种长期人口流动的移动网络,最常见的方法是使用社会网络分析。城市被认为是网络节点,不同强度的城市间人口流动被认为是网络边缘。这种方法可以计算出城市节点的不同指标,如程度中心性、接近中心性、谐波中心性、间隔中心性等。这些指标可以从不同的角度清楚地反映出一个城市在网络中的关键程度。此外,由于人口的迁移(网络的边缘)与城市的社会经济要素密切相关,这也带来了揭示城市节点社区结构(城市集群)和层次结构(城市规模)的可能性。然而,传统的网络分析方法在本文的人口流动网络背景下是不够的。我们知道,城市之间存在着空间距离关系,鉴于两个城市的吸引力相似,大多数人都会选择离自己家乡更近或气候更相似的城市,但这种空间关系并没有反映在上述复杂的网络分析结果中。此外,随着城市群人口的增多和经济的发展,城市群内各城市之间的界限变得越来越模糊。传统的网络分析方法可以衡量城市的强弱,但不能评估城市群发展的成熟度,也不能解释城市对选择的倾向。
在此,我们设定高度成熟的城市群具有以下两个特征。首先,人们在城市群内的流动比在城市群外的流动要频繁得多;另外,城市群内发展水平相近的城市对其他城市人的吸引力相近,不存在太大的地理邻近效应。满足这两个特征意味着城市群的城市已经高度融合。
本文的主要贡献有两个方面。
-
首先,我们通过使用新的数据源构建人口流动网络来解决识别长期人口流动的问题。
-
其次,我们使用了一种新的方法来计算城市节点的嵌入表示,扩展了人类对人口流动的认识水平
相关工作
RELATED WORK /
图结构在自然中广泛存在,以图神经网络为代表的图算法在很多领域得到了广泛的应用,并成为地理学研究中的热门研究课题.我们使用了一种基于人口移动网络和图嵌入的Node2vec方法,它使用深度优先策略(DFS)和广度优先策略(BFS)来遍历城市关联图,并将其应用到城市网络当中。这种算法可以获得城市的关系序列,从而计算出嵌入的表达。它不仅保留了移动网络中复杂的网络属性,而且还获得了城市嵌入值,这为下游任务的开展带来了可能性。这里不详细介绍了,感兴趣可以移步原文,我们计算了中国300多个城市的城市向量,文末提供了嵌入结果大家可以自由取用。
研究方法
METHODS /
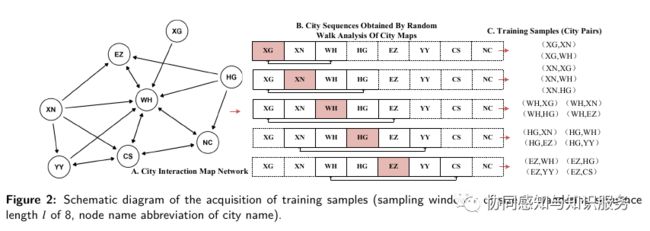
研究方法分为三部分,如图所示:第一是用人类自发产生的社会感知数据(POI数据)所隐含的交互信息构建人口移动网络。第二部分使用神经网络对图谱知识进行采样,得到城市的嵌入表达。最后一部分是基于第二部分的计算结果进行下游任务。

自然语言处理中出现了Skip-Gram和CBOW等算法来学习单词的连续特征表示。它扫描文档中的单词,并计算单词的嵌入特征,以预测附近的单词。这样的方法是基于分布假设的,即单词在相似的语境中往往具有相似的含义,并使用随机梯度下降(SGD)激励优化一个基于图的自定义目标函数。自然语言处理中的Word2vec模型将稀疏的知识转化为密集的实域向量知识。这种知识嵌入算法是语义驱动的,也就是说,知识嵌入是基于词的共现概率计算出来的。类比,我们研究的是自发的人口流动,它是由社会经济驱动的,即从人口移动网络学习特征。在这里我就不放公式了,放公式读者估计会跑掉一大半,详情移步论文。简而言之,图嵌入算法(非GCN这种)实际上是先对图进行序列采样(深度、广度检索),然后视采样后的序列为句子,再套用传统的word2vec就可以了。
中国的手机号码由11位数字组成,前三位数字代表网络识别码,用于区分不同的运营商。第四至第七位数字代表手机号码归属地的区号,即处理手机号码的地区。这部分信息非常有用,我们建立区域代码匹配库来解析这些信息。最后四位数据是用户识别码,在本文中没有使用。由于文化差异,在中国一个人几乎不会改变其手机号码,如果手机的注册地点与用户目前就业的地区不一致,这意味着从城市A(注册地点)到城市B(就业地点)的空间流动。与基于交通大数据(火车、航班)计算的迁移数据相比,这种流动很少被注意到,后者更加详细,记录了长时间(意味着人口迁移)和长距离(交通网络中的一次长途旅行可能被分为几个小段,比如换乘不同的交通工具,在交通枢纽转车和中转),我们的文章也是基于这两类空间流动在时间和空间尺度上的异同(交通流和迁徙流)。我们把迁徙流构建的空间互动网络称为人口移动网络。此外,为了验证城市嵌入是否包含经济属性的信息,我们还统计了每个城市的各种社会经济指标。这些指标收集自《中国统计年鉴》、NPP/VIIRS卫星夜光遥感数据、土地利用类型数据、MODIS NDVI植被指数数据、交通路网数据、人口数据和行政边界数据。

电子数据长这样 ↑
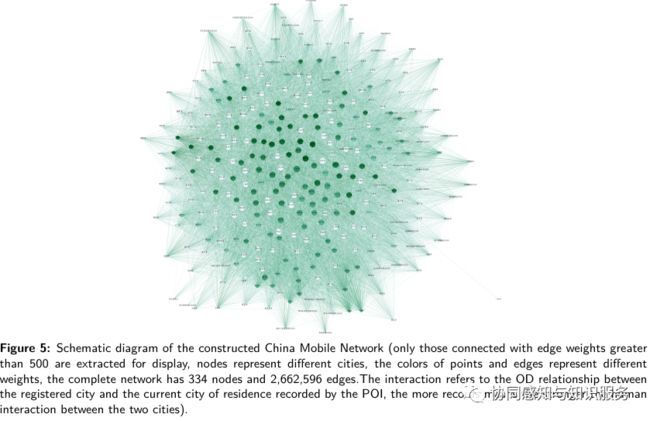
334个城市构成的人口移动网络长这样 ↑
人类语言有成千上万的词汇,在进行词汇向量训练时,为了捕捉更多的词汇特征,训练维度通常被设置为100甚至300维。然而,移动网络只有数百个节点,与人类语言的语义相比,网络信息的信息量较小。我们将城市向量的维度设置为网络节点数的1/15左右(20个维度);考虑到一个城市群中的城市数量一般不超过10个,我们将游走长度和扫描窗口大小设置为10,这样可以捕获长距离的交互信息。为了使我们的城市向量得到充分的训练,我们将每个节点的步行次数设置为200次;我们开启了4个线程来加速模型训练。为了验证City2vec方法的有效性,并揭示移动网络中隐含的知识,我们进行了一个对照实验。第1组基于城市向量,使用K-Means算法和HDBSCN算法来识别城市聚类,第2组基于传统方法解析移动结构,分别使用社区结构检测算法(Louvain算法)和谱聚类算法来识别城市聚类。
实验结果
RESULTS /

首先是比较简单的聚类计算,我们识别出了28个集群,感觉效果还是不错的,基本上与行政边界吻合,也就是说大部分人口流动发生在省内。其次是计算了城市群的识别效果,也是最优的。文章到这里还没有充分体现城市嵌入在下游任务中的应用场景,其实这种方法传统的复杂网络也能干,那他能不能揭示一些更有价值的结论呢?且看文章慢慢道来。
为了验证我们构建的网络的可靠性,我们把腾讯人口迁徙数据作为一个对比集。腾讯的交通数据平台统计了一年内城市间的总客流量,包括火车、汽车和飞机等。我们把腾讯的城市交通迁移数据所形成的城市网络称为交通网络。
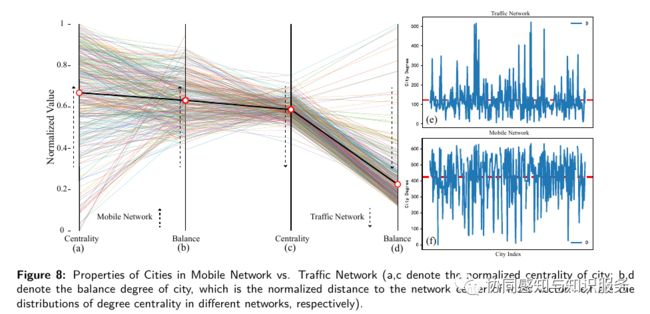
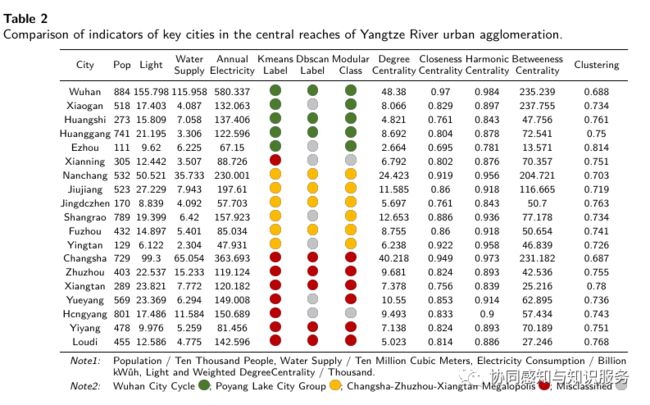
可以看出,交通网络中的城市具有很强的无标度特征,虽然网络的整体度很低(平均度=122),但有几个关键城市在交通网络中起着主导作用,掌握着大部分的交通量(d,e)。相比之下,移动网络的整体度数很高(平均度数=420),没有明显的异常值,与普通城市相比,高度值的关键城市之间的差异不是特别明显。这是由于交通网络记录了人口的短期流动,交通枢纽城市承担了交通 "集散 "的功能,大大加强了这类城市的核心地位。人口移动是由社会经济因素驱动的,主要是经济、政策、自然环境和就业吸引力(如某城市经济发展迅速,吸引其他城市的居民去工作;某城市环境温馨宜人,吸引其他城市的居民去做生意),而人口移动网络中的人口是双向流动的,即从大城市到小城市,从小城市到大城市。移动网络比交通网络更 "平等"。交通数据会经常记录两个城市之间的互动,反映了短期人口迁移,这实际上提高了交通枢纽城市的权重。我们的移动网络是建立在相对稳定的POI基础上的,这更接近于长期人口迁移(永久迁移)。
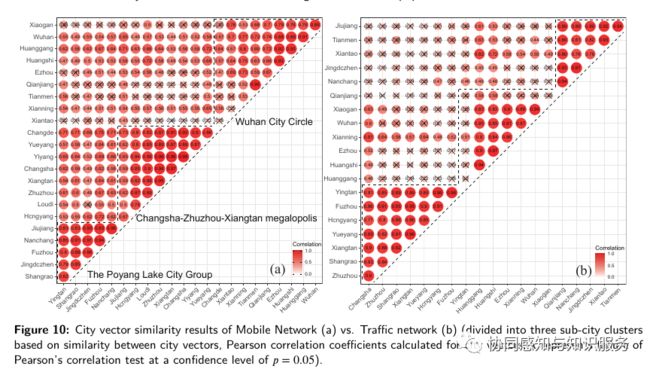
城市向量之间的皮尔逊相关系数 ↑
我们计算了长江中游城市群重点城市的城市向量之间的皮尔逊相关系数。如上图所示,很明显,城市群内城市之间的相似性远远高于不同城市群内城市之间的相似性,形成了三个明显不同的次城市群。可以看出交通网络(b)的组内相似性更显著。而组间的相关性非常弱。这说明交通网络有距离衰减效应,更注重近距离的空间互动。而移动网络(a)除了短距离的相互作用外,还善于捕捉长距离的空间关联。交通网络可以用来捕捉人口的短期、短距离迁移状态,可以应用于公共卫生事件以及自然灾害事件的风险评估。而本文提出的移动网络(a)可以用来捕捉人口的长期、多尺度迁移状态,可以用来分析网络和经济的复杂耦合效应。
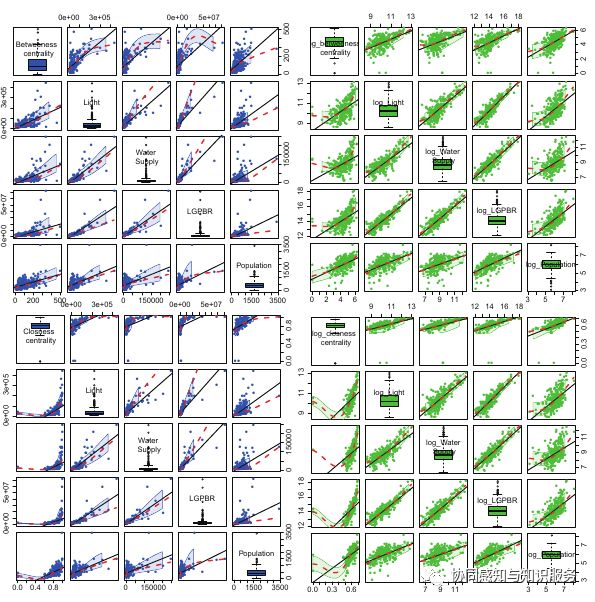
城市群社会经济指标与复杂网络属性线性拟合结果 ↑
考虑到人口迁移的主要驱动力是经济,我们将社会经济指标与复杂网络属性进行拟合(如上图所示)。我们先对一部分城市进行分析,大约有10个城市群的数百个城市,分别是长沙-株洲-湘潭大都市(标签=1)、中原城市群(标签=3)、太原城市群(标签=4)、成渝城市群(标签=7)。长江三角洲城市群(标签=8)、关中平原城市群(标签=10)、珠江三角洲城市群(标签=12)、海峡西岸城市群(标签=14)、武汉城市圈(标签=15)、鄱阳湖城市群(标签=16)。线性拟合结果说明,在 p=0.01 的置信水平下,城市节点的度值与经济属性有极强的正相关关系。
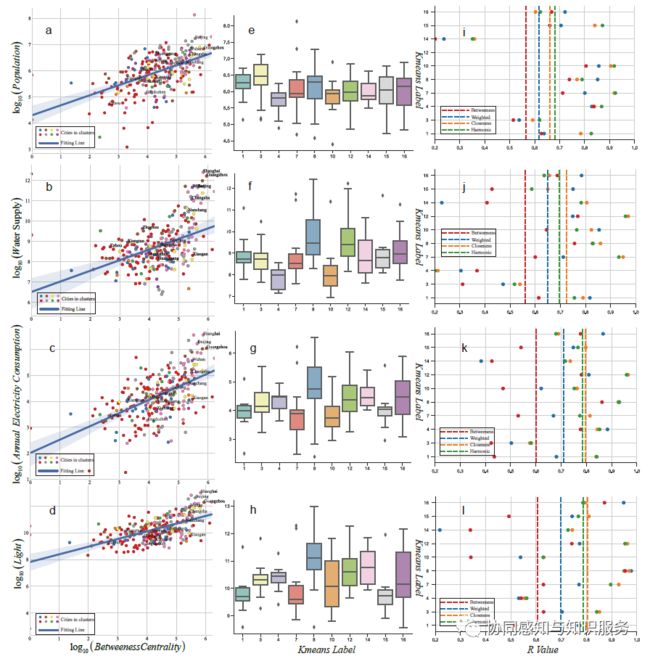
各个城市具体的指标 ↑
首先看看各个城市具体的指标(如上图所示),上图(e-h)显示了不同城市群的各城市指标的箱形图。上图(e)显示,中原城市群(标签=3)的平均城市人口最高,太原城市群(标签=4)的平均城市人口最低,长江三角洲城市群(标签=8)的城市人口峰值最高。上图(f)说明了长江三角洲城市群(标签=8)和珠江三角洲城市群(标签=12)的用水量最高,这两个城市群也是中国的经济和工业中心,需要大量的工业/农业用水。上图(g)显示,长江三角洲城市群(label=8)仍然是中国能源密集度最高的城市群。鄱阳湖城市群(标签=16)由于有大量的稀土和金属矿产工业,也有很高的能源消耗。上图(h)显示了不同城市群的夜光遥感值。长江中游城市群仍然是中国 "最亮 "的地区,反映了活跃的社会经济活动,而以鄱阳湖城市群(标签=16)的城市间亮度差异较大。
上图(i-l)显示了城市网络属性与城市群尺度的社会经济指标的拟合结果,Closeness Centrality和Harmonic Closeness Centrality(黄色虚线和绿色虚线)与夜间遥感和《统计年鉴》的各种社会经济指标的拟合效果最好。整个图的Closeness Centrality对所有指标的加权平均拟合R值约为0.8,证明了城市移动网络的信息量很丰富。城市在移动网络中的重要性与城市光照总量和城市能源消耗高度相关,而与人口总量和供水量的相关性较低,这意味着发达城市以较少的资源和人口创造了更多的经济总量。
应用案例
APPLICATION /
文章最精彩的应用要来啦,验证城市向量包含的地理位置属性。
此外,还进行了实验来验证城市向量是否包含地理特征。我们使用皮尔逊相关系数来计算城市之间两两的相似度r,并根据不同极值的城市生成城市谱。例如,以最北部城市的城市向量CityN和最南部城市的城市向量CityS作为光谱的两端。则每个城市的谱值为
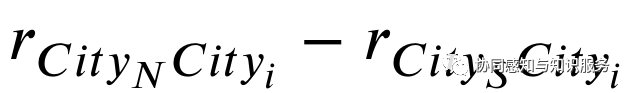
这样就可以验证生成的向量是否包含地理位置属性。
如下图(Figure 12)所示,我们计算了七组光谱,光谱中的每条竖线代表一个城市,黑线代表光谱平均值,表示流动人口对城市的倾向性(对城市的认可程度)。

我们可以将图12(a,b)分为一类,代表中国地理空间上最大的两个城市群,即珠江三角洲城市群(核心城市为广州,GZ和深圳,SZ)和环渤海城市群(核心城市为北京,BJ和天津,TJ)。衡量同一城市集聚下的核心城市的迁移倾向。
图12(c,d)分别显示了沿海(上海,SH)和内陆(武汉,WH),以及东部(上海,SH)和西部(成都,CD)之间的比较。可以看出,城市群的核心城市(图ref{spec}e,f),对人口的吸引力差别不大,城市倾向比较中性(黑色中位线)。珠江三角洲城市群显然比环渤海城市群更发达,人口来源也更接近。
相比之下,对比组的城市倾向(黑色中位线)(图12 c,d)发生了明显的转变,表明沿海城市比内陆城市和西部城市对人口的吸引力更大,表现出明显的地理空间差异。
图12(e,f)表示长江中游城市群的城市趋势。虽然武汉(WH)的GDP比长沙(CS)高,但长沙(CS)吸引人口的能力比武汉(WH)强。根据2021年第七次全国人口普查的数据,长沙在过去10年(2010-2020年)增加了300多万人口,而武汉在10年内增加了254.2万人口,略低于长沙,我们的研究有力地支持了这一结论。
此外,如图12(g)所示,我们将北方城市(北纬35度以北的城市,35度是中国的自然分界线和年降水量800毫米的分界线)标记为红色,南方城市(北纬35度以南的城市)标记为蓝色。北京和广州分别是中国南方(GZ)和北方(BJ)最具代表性的大城市,我们选择这两个城市作为极值。可以看出,北方城市的频谱更偏向于北京,南方城市的频谱明显偏向于广州,而频谱的平均值则在0左右。这意味着我们生成的向量包含了位置信息,这在频谱图中可以得到清晰的印证。
与传统的网络分析方法相比,我们的方法有如下优点。
-
如图12,我们可以计算出城市之间的相似度,以及全国300多个城市对该城市的 "投票 "结果,以充分说明城市的竞争力水平和人口来源。这比表2中对各类城市中心性的枯燥比较要直观和准确得多。
-
我们可以评估城市群的发展(网络的紧凑程度)。一个高度发达的城市群会逐渐 "抹平 "城市间的边界,而城市群外其他城市的 "投票 "结果也会变得更加集中。如图12(a,d)所示,城市群a(核心城市SZ,GZ)明显比城市群d(核心城市TJ,BJ)更加一体化。
-
我们计算的城市向量还包含地理和气候属性。如光谱图g所示,南方和北方城市之间存在明显的差异,这表明当人类做出迁移决定时,家乡(迁出地)与城市之间的距离和气候条件会被考虑在内。结果还包含了距离的影响。由于武汉和长沙分别是其所在省份的中心城市,这两个城市的经济水平和人口吸引力相差不大,但由于距离的差异,从小城市迁出的居民更喜欢较近的中心城市。
结论
CONCLUSION /
我们基于流动人口提供的大量城市共生关系,构建了一个空间交互网络(Mobile Network),并对嵌入各种知识的城市向量进行了训练。我们将城市的一维感知(即通过传统的复杂网络方法计算各种属性或城市经济指标来描述城市)扩展到二维认知(即可以对网络节点进行多维矢量,以比较不同的城市)。我们的研究证实,在城市聚集区识别任务中,城市嵌入算法比传统的网络社区划分算法取得了更好的分类结果。经过训练的城市向量善于捕捉长期和长距离的迁移信息,并富含社会经济属性、地理位置属性和复杂网络属性。我们的研究更注重经济方面,因为数据来自电子地图,这与商业高度相关。而更多的城市信息(如城市空间位置、城市评论数据、城市街景数据)可以在未来引入,以扩大我们对人口迁移的不同角度的理解。
讨论
关于城市向量我们的应用就这么多,它是否有潜力应用到其他场景?这还需要大家一起进行探究。欢迎转发,评论与引用。

文章手稿与城市嵌入结果:
链接:https://pan.baidu.com/s/1iEXqnI3UjjzkG3JOtwbnyQ?pwd=ofay
提取码:ofay

相关文章:
1. Chen N, Zhang Y, Du W, et al. KE-CNN: A new social sensing method for extracting geographical attributes from text semantic features and its application in Wuhan, China[J]. Computers, Environment and Urban Systems, 2021, 88: 101629.
一种从文本语义信息中抽取地理属性的社会感知新方法
2. Zhang Y, Chen N, Du W, et al. Multi-source sensor based urban habitat and resident health sensing: A case study of Wuhan, China[J]. Building and Environment, 2021, 198: 107883.
基于多源传感器的城市人居环境与居民健康感知:中国武汉的案例研究
3. Zhang Y, Chen Z, Zheng X, et al. Extracting the location of flooding events in urban systems and analyzing the semantic risk using social sensing data[J]. Journal of Hydrology, 2021, 603: 127053.
基于社会感知的城市洪涝位置提取与语义计算