高性能RPC框架BRPC核心机制分析
作者:tom-sun
链接:https://zhuanlan.zhihu.com/p/113427004
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1. 简介
百度开源的RPC框架BRPC,以其高性能、低延迟、易用性等优势,使得其在高性能的C++开发领域非常受欢迎。
为什么高性能、低延迟上能够有足够大的优势
- 线程模型(Thread Module):使用bthread 用户态协程,结合N:M的调度模型,以及work-steal 抢占式调度实现;为bthread打造的butex同步组件,为实现高性能的RPC框架提供了较为高效和简洁的并发编程基础。
- 内存管理(Buffer & Memory Management):buffer-ManangerMent通过IOBuf(非连续零拷贝缓存)方式减少数据传递处理过程中的拷贝。各种ThreadLocal的ResoucePool,Object Pool等来优化定长的短生命周期的申请和释放。
- 执行队列(exec queue):多生产者单消费者无锁队列,实现了多生产者单消费者之间的的高效通信,在实现单TCP连接复用,高效发送-接收数据上发挥了很重要的作用。
- 超时定时器(Timer Keeping): 使用高效的定时器管理超时的RPC,并进行回调。
- 避免过多编码:将数据Body作为Attachment的方式,而不需要编解码
易用性体现在哪里:
- ProtoBuf 支持:支持google ProtoBuf 定义RPC协议
- 单端口多协议支持:支持在同一端口识别不同的协议(Redis等)
- 高性能bvar统计:通过高性能的bvar进行方面的性能统计,并且支持导出到普罗米修斯-形成一整套监控方案。
- IO模式:支持方面的同步和异步的编程模型
- 扩展性:支持自定义的协议实现
- 等等
BRPC作为非常优秀的高性能并发编程范例,在并发编程、性能优化方面有非常深入的实践探索,本文对其核心机制进行深入探究。
本文分析的部分核心机制内容板块如下
- 线程模型(Thread Model)
- 同步机制(Butex)
- 执行队列(ExecutionQueue)
- Buffer管理(Buffer ManageMent)
2. Thread Model
线程模型解决的问题,是如何高效的利用多个物理核,进行工作任务的调度,使得系统能够有更高有效的吞吐,更加低的延迟。而不是把时间花在大量的比如系统层面的工作:比如context-switch(PS:实际contextSwitch的时间),cache的同步、线程等待等contention上面)
线程模型这块当前典型的线程模型有几大类
- 连接独占模型:也就是一个连接进来请求后,独占一个线程(进程)进行处理。(无论其中中间在做什么事情,比如调用第三方的服务,等待过程中也是独占着整个线程),比如传统的tomcat servlet就是这么干的。
- 单线程Reactor模型:使用单个线程处理所有连接上的请求,使用epoll-wait 方式,实现事件多路复用机制。典型比如Redis,适用于简单比如小数据的内存数据的获取。每一个回调逻辑都比较简单。(缺点就是:某个回调卡住,真个Reactor 反应堆就block了)
- 多线程Reactor模型: 单线程Reactor不能利用多线程Reactor的优势,所以当前大多数RPC/反向代理的框架大多数都是按照这个来玩的。也就是多个线程/进程Accept同一个连接上的请求(如何更好的处理惊群问题参考见 Nginx)。
但是这种固定线程数的模型中,都需要避免一个问题,就是避免在如上回调逻辑中调用block的逻辑否则一个事件处理Block,就是将整个线程反应堆都给Block了。比如Nginx针对磁盘IO推出多线程支持,在Nginx中磁盘IO层面的请求,不直接inplace在对应的反应堆中进行,而是将磁盘IO的阶段委派给专门的单独的线程池进行。(比如Proxy_temp_file从后端拉数据缓存在本地磁盘消费的场景 )
总结来说连接独占模型,主要依赖多开线程的方式来提供服务端的吞吐。但是多开线程势必带来的问题就是系统层面的开销比较大(contex-switch、cache-bounding等等),对于高性能场景典型就不太适用。
而从编程模式上,异步的编程模式总归来说是非常复杂的,比如1个请求需要请求N个模块完成的情况下,如果使用异步模式,那简直就是太不直观,写出正确逻辑的代价会非常大,测试也非常困难。
作为专门领域的实现使用Reactor模式没有太大的问题。但是如果是在RPC场景下,对接RPC后端的是复杂的业务逻辑情况下,要基于Reactor来玩真的就太难了,从业务层面最希望的就是同步方式的编程模型。所以从实现通用的RPC框架层面来说,基于这样的线程模型的同时,再上层提供简洁的并发编程组件,就显得格外重要。
那从实现层面,就需要在block(比如网络调用)的情况下,保留当前task执行的上线文(栈、寄存器、signal等),然后切换到别的可以执行的task上。在task具备执行条件的时候将当前执行线程的context替换为为对应的task中保存的上下文,从而实现执行逻辑的切换。(PS:除了网络,其他block的系统调用,如磁盘IO(依赖中断机制),用户态线程当前看是无能为力的,直接卡pthread,所以当前高性能的nvme磁盘肯定会向异步接口发展,比如内核现在提供的iouring方式的新接口体系)
这种实现模式一般来说称为用户态线程、协程(coroutine),
这个方面实现最彻底的是golang语言,直接在语言runtime层面把这个问题搞定。brpc框架则设计了bthread和相关的组件来实现。从调度模式来看,用户态线程主要分几大类
- N:1用户态线程库模型: N个用户态下线程对应1个native 的thread,如腾讯开源的libco等。
- M:N 用户态线程库模型:典型如go语言的goroutine、brpc的 bthread、开源实现libgo。并且支持work-steal的调度模型来避免长尾效应。
PS1:加上现在高性能硬件越来越多,基本都开始bypass内核,玩异步polling的模式。所以这种模型显得格外重要。
PS2:用户态线程的优势,切换 50~100ns(2GhzCPU情况下100~200个cycle)级别 相比 linux原生内核线程切换1~2 us。近1个数量级的性能提升。
// 以下简单测试了 intel E5-2670 v3 CPU (4.9.65 内核情况下)在各种switch方面的性能和参考文献的一些性能数据。
// 参考文献(https://blog.tsunanet.net/2010/11/how-long-does-it-take-to-make-context.html)
// https://github.com/tsuna/contextswitch/blob/master/timesyscall.c
* 陷入内核的context-switch (使用轻量级的gettid调用进行测试)
Intel 5150: 105ns/syscall
Intel E5440: 87ns/syscall
Intel E5520: 58ns/syscall
Intel X5550: 52ns/syscall
Intel L5630: 58ns/syscall
Intel E5-2620: 67ns/syscall
Intel E5-2670 v3:211ns/syscall
也就是从当前看,纯粹从陷入内核方面已经不太跟常规切换的context一样耗时间,基本在百来个cpu cycle能够完成。
* 进程/线程之间的context-switch (产生竞争情况下使用SYS_futex陷入内核等待的性能,2个进程相互唤醒的方式测试)
// https://github.com/tsuna/contextswitch/blob/master/timectxsw.c
// https://github.com/tsuna/contextswitch/blob/master/timetctxsw.c
Intel 5150: ~4300ns/context switch
Intel E5440: ~3600ns/context switch
Intel E5520: ~4500ns/context switch
Intel X5550: ~3000ns/context switch
Intel L5630: ~3000ns/context switch
Intel E5-2620: ~3000ns/context switch
Intel E5-2670 v3: ~1769.5ns/context switch
PS3: 存储级别的访问时间也可以关注下(当前cpu 一般在2Ghz左右,1个cycle大概0.5ns左右)(L1 3cycles、L2 11cycles、L3 25 Cycles Main Memory 100 cycles)
2.1 Bthread实现基础
native thread 是当前linux操作系统内核调度的最基本的单元。当thread通过系统调用进入内核的时候,管辖权就全交给内核了。线程运行在用户态有几大我们看不到的东西,也就是用户态的context,这些是一个线程独有的运行时状态。
- 栈(stack):保存当前线程的函数调用链 以及 参数信息,返回函数跳转地址。
- 寄存器(register):比如esp:当前栈顶指针,eip:当指令寄存器,指示当前执行的代码段。
2.1.1 栈管理
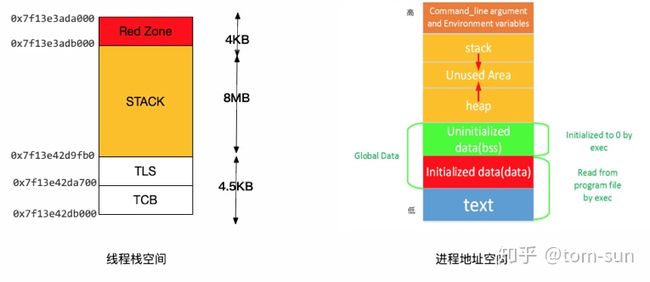
使用mmap映射一段可用的虚拟地址空间。系统默认的栈的空间的大小可以通过(ulimit -s ) 进行查看到,在默认情况下位8MB。pthread的实现中,是使用mmap的机制向操作系统申请一段连续的8MB的虚拟地址空间。mmap的特点是直到使用的时候才会分配。比如如下的程序,可以通过strace & 查看进程地址空间方式查看对应的栈的管理机制。
#include
#include
#include
void threadfunc(void) {
std::cout << "i am a thread\n";
sleep(3600);
}
int main(void) {
std::thread t(threadfunc);
t.join();
return 0;
}
通过strace 可以看到对应的系统调用分配到的空间申请了8MB+4KB的地址空间。0x7f13e42d9fb0~0x7f13e3ada000,其中低地址的放置堆栈溢出越界处理。
getrlimit(RLIMIT_STACK, {rlim_cur=8192*1024, rlim_max=RLIM64_INFINITY}) = 0
brk(NULL) = 0x55d78f83f000
brk(0x55d78f871000) = 0x55d78f871000
futex(0x7f13e513103c, FUTEX_WAKE_PRIVATE, 2147483647) = 0
futex(0x7f13e5131048, FUTEX_WAKE_PRIVATE, 2147483647) = 0
mmap(NULL, 8392704, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0) = 0x7f13e3ada000
mprotect(0x7f13e3ada000, 4096, PROT_NONE) = 0
clone(child_stack=0x7f13e42d9fb0, flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID, parent_tidptr=0x7f13e42da9d0, tls=0x7f13e42da700, child_tidptr=0x7f13e42da9d0) = 2080547
通过cat /proc/pid/smaps 的内存map中看到这段地址分配。
7f13e3ada000-7f13e3adb000 ---p 00000000 00:00 0
Size: 4 kB
Rss: 0 kB
Pss: 0 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 0 kB
Referenced: 0 kB
Anonymous: 0 kB
AnonHugePages: 0 kB
ShmemPmdMapped: 0 kB
Shared_Hugetlb: 0 kB
Private_Hugetlb: 0 kB
Swap: 0 kB
SwapPss: 0 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Locked: 0 kB
ProtectionKey: 0
VmFlags: mr mw me ac sd
7f13e3adb000-7f13e42db000 rw-p 00000000 00:00 0
Size: 8192 kB
Rss: 8 kB
Pss: 8 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 8 kB
Referenced: 8 kB
Anonymous: 8 kB
AnonHugePages: 0 kB
ShmemPmdMapped: 0 kB
Shared_Hugetlb: 0 kB
Private_Hugetlb: 0 kB
Swap: 0 kB
SwapPss: 0 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Locked: 0 kB
可以发现进程栈的地址空间分配如下图所示,其中8MB为对应线程的堆栈地址空间,高地址空间的一部分用于分配线程对应的TLS(Thread Local Storage)和TCB(Task Control block)。最低地址空间的4KB为越界保护地址区,防止在栈溢出情况下把别的线程的堆栈给踩了。右图为一个典型的Linux系统中的进程地址空间。
如上是一个典型的native thread的栈内存管理方式。bthread 使用的栈的实现也是一样的。但是也根据其应用场景(高性能RPC)进行了性能上的优化。
由于使用bthread之后,会有非常频繁和大量的bthread的创建-销毁(一个请求的处理就是启动一个新的bthread,请求处理完成既要销毁,并且bthread的数量直接跟 rpc server 并发度有关,对于高性能RPC来说,同一时间会有巨量的bthread,10w,甚至100w)
所以Bthread 在性能上做了一些优化,避免每次进行系统调用使用mmap进行分配内存,使用了object pool 结合thread_local的方式来管理stack对象。但是一旦做了这种优化,其实没法单独设置某个bthread的stack的大小。但是绝大多数情况下大多数使用场景不用关心stack的大小,而是统一大小即可,当前默认brpc server的stack_size 为1MB,可参考3。
所有native thread 堆栈方面的问题 bthread 的stack 一样会遇到,比如stack-overflow,甚至在极端情况下把别的bthread的stack 给踩了,从而从现幽灵问题,我们在使用过程中有遇到过在函数中开辟较大的本地数组而从导致出现把别的bthread的stack给污染的幽灵问题,可参考2。
ps: 在64系统里,一个线程里头可以映射的stack 的数量理论上可以认为是没有太大限制的,但是linux操作系统mmap的地址空间映射数量有限 可以通过cat /proc/sys/vm/max_map_count查看。
struct StackStorage {
int stacksize; // stack 有效大小
int guardsize; // guardpage 的大小,使用mprotect为保护地址空间,用于检测stack_overflow
void* bottom; // 栈底指正(高地址端)。
}
2.1.1 Content Switch
- x86-64 函数调用&栈帧原理
Content Switch也是通过基本的函数调用实现的,所以介绍Context Switch之前先分析下基础的寄存器的信息和函数调用信息。

如上为寄存器的基本信息
- %rax: 通常用于存储函数调用的返回结果
- %rsp:栈指针寄存器,通常指向栈顶为止,push/pop操作就是通过改变 %rsp的值移动栈指针进行实现
- %rbp:栈帧指针,用于表示当前栈帧的起始位置 (用于获取父函数压栈的参数)
- %rdi, %rsi, %rdx, %rcx,%r8, %r9:六个寄存器用于依次存储函数调用时的6个参数(超过6个的参数会压堆栈)
- miscellaneous registers: 此类寄存器更加通用广泛的寄存器,编译器或汇编程序可以根据需要存储任何数据
- Caller Save & Callee Save: 即表示寄存器是由“调用者保存”还是由“被调用者保存”,产生函数调用的时候,通用寄存器也会被子函数调用,为了确保不会被覆盖,需要进行保存和恢复。
进行函数调用和返回后的栈的状态如下图所示。
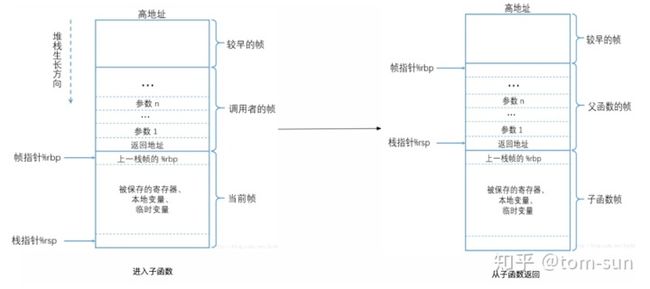
函数调用的时候,执行的操作:
- 父函数将调用参数从后往前压栈
- 将返回地址压栈
- 跳转到子函数起始执行地址
- 子函数将父函数栈帧起始(基)地址压栈
- 将%rbp 的值设置为当前的%rsp (即将rbp指向子函数的栈帧起始地址)
... # 参数压栈
call FUNC # 将返回地址压栈,并跳转到子函数 FUNC 处执行
... # 函数调用的返回位置
FUNC: # 子函数入口
pushq %rbp # 保存旧的帧指针,相当于创建新的栈帧
movq %rsp, %rbp # 让 %rbp 指向新栈帧的起始位置
subq $N, %rsp # 在新栈帧中预留一些空位,供子程序使用,用 (%rsp+K) 或 (%rbp-K) 的形式保留空位
函数返回的时候:
函数返回就是设置返回值,并且将栈恢复到原来的状态,然后跳转到父函数返回地址处继续执行
- 将当前的栈指针rsp设置为其栈帧起始地址rbp(相当于popo数据)
- 从栈中pop出父函数栈帧的起始地址到rbp(还原父函数的rbp)(1,2 当前合并为leave指令)
- 从栈中pop出父函数的返回地址,跳转到返回地址继续执行(当前为ret指令,返回值放置在RAX中)
movq %rbp, %rsp # 使 %rsp 和 %rbp 指向同一位置,即子栈帧的起始处
popq %rbp # 将栈中保存的父栈帧的 %rbp 的值赋值给 %rbp,并且 %rsp 上移一个位置指向父栈帧的结尾处12
ret- context switch
上节为context switch的基础。如下介绍context switch。所谓状态的切换就是把如上当前函数执行过程中的栈信息(RBP、RSP),函数执行的地址,以及各种状态寄存器的值进行合理的保存。
对于linux平台X86来说说器基本的context_stack的基本结构如下,之所以成为context _stack 是因为,进行用户态线程(bthread)切换的时候,对应用户态线程的context的信息是保存在栈头部,当前brpc采用的bthread 的context基本就是使用的boost的context,以下以boost的context为例子进行介绍。
/* bthread基本使用的基本使用的boost的context切换,如下以make_x86_64_sysv_macho_gas.S作为介绍 */
/* context_stack的结构可以认为如下,栈的底部首先是保存context。context后面的部分才是常规的stack */
/* ---------------------------------------------------|
* <--------stackdata--------| context |
* ---------------------------------------------------|
*/
/* 如下为以context的基本结构(如下为64字节,比如R12为8个字节) */
/****************************************************************************************
* *
* ---------------------------------------------------------------------------------- *
* | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | *
* ---------------------------------------------------------------------------------- *
* | 0x0 | 0x4 | 0x8 | 0xc | 0x10 | 0x14 | 0x18 | 0x1c | *
* ---------------------------------------------------------------------------------- *
* | fc_mxcsr|fc_x87_cw| R12 | R13 | R14 | *
* ---------------------------------------------------------------------------------- *
* ---------------------------------------------------------------------------------- *
* | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | *
* ---------------------------------------------------------------------------------- *
* | 0x20 | 0x24 | 0x28 | 0x2c | 0x30 | 0x34 | 0x38 | 0x3c | *
* ---------------------------------------------------------------------------------- *
* | R15 | RBX | RBP | RIP | *
* ---------------------------------------------------------------------------------- *
* *
****************************************************************************************/
Bthread context的切换机制,基本是按照boost.context 方式进行的改写,其主要的函数几个。bthread_make_fcontext以及bthread_jump_context 如下进行详细分析;
/*
* @brief 通过外部传入stack 和 函数指针构建context的基础信息
* @param[in] sp: 当前栈顶指针(一般来说为初始化的栈-无数据) (rdi(对应存放的寄存器))
* @param[in] size: 栈的大小(rsi)
* @param[in] fn: 保存该context的入口函数(类似pthread的func),程序起始入口地址 (rdx)
*/
fcontext_t make_fcontext(void* sp, size_t size, void (* fn)( transfer_t));
typedef void* fcontext_t;
struct transfer_t {
fcontext_t fctx; //父context_stack的栈顶地址
void *data; //fn 函数地址
};
// 其汇编实现如下
.text
.global _make_fcontext
.align 8
_make_fcontext:
/* first arg of make_fcontext == top of context-stack*/
/* bthread_make_fcontext的第一个参数加载到rax(即栈顶)*/
movq %rdi, %rax
/* shift address in RAX to lower 16 byte boundary */
/* 将context-stack 调整到向下16字节对齐,此时RAX指向真正的context-stack可以使用的基地址*/
andq $-16, %rax
/* reserve space for context-data on context-stack */
/* on context-function entry: */
/* 保留64字节的地址留给context,此时RAX从RIP的0x3c处跳转到0x0出(如上图所示) */
leaq -0x40(%rax), %rax
/* third arg of make_fcontext(0 == address of context-function*/
/* stored in RBX */
/* 将当前第三个参数,即fn函数路口,放入RBX)*/
movq %rdx, 0x28(%rax)
/* save MMX control- and status-word */
/* 如上图fc_mxcsr */
stmxcsr (%rax)
/* save x87 control-word */
/* 如上图 fc_x87_cw */
fnstcw 0x4(%rax)
/*计算trampoline绝对地址,并且保存在RIP中*/
/*后续调用bthread_jump_fcontext的时候首先会进入调用这个函数*/
/* compute abs address of label trampoline */
leaq trampoline(%rip), %rcx
/* save address of trampoline as return-address for context-function */
/* will be entered after calling jump_fcontext() first time */
movq %rcx, 0x38(%rax)
/* 计算finish 函数的地址,然后保存在 RBP中*/
/* context-function 返回的时候首先会调用这个函数*/
/* compute abs address of label finish */
leaq finish(%rip), %rcx
/* save address of finish as return-address for context-function */
/* will be entered after context-function returns */
movq %rcx, 0x30(%rax)
/*返回 指向context-data的,0x0处,返回rax当前值(rax是返回值寄存器)*/
ret /* return pointer to contect-data */
/*这个函数干的就是,在bthreadjump_fcontext进入调用trampoline之后,跳转到对应的context-function*/
trampoline:
/* 保存旧的栈指针,用于返回父函数调用时候恢复父函数的栈帧指针*/
/* store return address on stack */
/* fix stack alignment */
push %rbp
/* 直接跳转到fn中执行 */
/* jump to context-function */
jmp *%rbx
/*这个函数的调用就是设置状态,调用__exist 函数*/
finish:
/* exit code is zero */
xorq %rdi, %rdi
/* exit application */
call __exit
hlt
/*
* @brief 从当前线程的context切换到新的context
* @param[in] to: 用于指示要跳转到的context-stack (rdi)
* @param[intptr_t] vp,用于指向参数列表 (rsi)
* @return tranfer_t 指向当前context的指针
*/
transfer_t jump_fcontext(fcontext_t const to, void* vp);
struct transfer_t {
fcontext_t fctx;
void * data;
};
// 其对应的汇编的实现如下
.text
.globl _jump_fcontext
.align 8
_jump_fcontext:
/* 调整堆栈(申请空间),用于保存当前线程的context-data(PS rsp默认为栈寄存器)*/
leaq -0x38(%rsp), %rsp /* prepare stack */ //(PS:为什么是-38不是,不是-40,RIP呢?)
//因为push %rip,这一步保存返回地址和进行跳转是在函数调用者的call指令?
/* 然后将当前线程执行现场的寄存器一个个保存到stack中 */
#if !defined(BOOST_USE_TSX)
stmxcsr (%rsp) /* save MMX control- and status-word */
fnstcw 0x4(%rsp) /* save x87 control-word */
#endif
movq %r12, 0x8(%rsp) /* save R12 */
movq %r13, 0x10(%rsp) /* save R13 */
movq %r14, 0x18(%rsp) /* save R14 */
movq %r15, 0x20(%rsp) /* save R15 */
movq %rbx, 0x28(%rsp) /* save RBX */
movq %rbp, 0x30(%rsp) /* save RBP */
/*到此为止rsp栈寄存器指向了context-data, 保存在rax中(也就是设置ofc这个指针指向的值)*/
/*当前线程的context 已经保存在器堆栈中,并且地址设置在出参寄存器RAX中*/
/* store RSP (pointing to context-data) in RAX */
movq %rsp, %rax
/*切换rsp为新的context 的栈顶(即入参to寄存器为rdi),栈顶指向context-data*/
/* restore RSP (pointing to context-data) from RDI */
movq %rdi, %rsp
// 将返回地址地址放置在r8中,也就是将目的context的RIP(也就是上文trampoline) 保存在r8中
movq 0x38(%rsp), %r8 /* restore return-address */
// restore 当前线程的寄存器为当前目的context的context-data)
#if !defined(BOOST_USE_TSX)
ldmxcsr (%rsp) /* restore MMX control- and status-word */
fldcw 0x4(%rsp) /* restore x87 control-word */
#endif
movq 0x8(%rsp), %r12 /* restore R12 */
movq 0x10(%rsp), %r13 /* restore R13 */
movq 0x18(%rsp), %r14 /* restore R14 */
movq 0x20(%rsp), %r15 /* restore R15 */
movq 0x28(%rsp), %rbx /* restore RBX */
movq 0x30(%rsp), %rbp /* restore RBP */
// (因为现在context-data已经弹出到cpu寄存器中,stack不需要保留,更新stack顶部)
leaq 0x40(%rsp), %rsp /* prepare stack */
/* return transfer_t from jump */
/* RAX == fctx, RDX == data */
movq %rsi, %rdx /*取出第2个参数vp,保存在寄存器rdx中,供jmp到新的context执行使用*/
/* pass transfer_t as first arg in context function */
/* RDI == fctx, RSI == data */
movq %rax, %rdi /*rax中保存为父context-stack的栈顶,当前指向父context的0x0处,放到第一个参数rdi 作为跳转trampoline 参数 */
/* indirect jump to context */
jmp *%r8 // 跳转到新context 的trampoline执行
//rax, rbx, rcx, rdx, rbp, rsp, rsi or rdi
2.2 Bthread实现
bthread的实现基础实现原理2.1 节已经充分进行说明,以下结合以上基础信息分析,分析整个用户态线程库是如何work的
2.2.1 Task结构与Bthread调度
每个任务处理上下文中记录context之外,还有很多的信息,如下为当前bthread 基本的task的meta信息。
struct TaskMeta {
// 用于Bthread 在bmutex挂起和唤醒(比如在该执行体调用brpc的接口发送rpc请求的时候
// 使用mutex实现同步的时候,为了防止阻塞pthread,通过这个item将执行体挂起)
butil::atomic current_waiter;
uint64_t current_sleep;
// A builtin flag to mark if the thread is stopping.
// 用于表示该bthread退出
bool stop;
// The thread is interrupted and should wake up from some blocking ops.
bool interrupted;
// Scheduling of the thread can be delayed.
bool about_to_quit;
// [Not Reset] guarantee visibility of version_butex.
pthread_spinlock_t version_lock;
// [Not Reset] only modified by one bthread at any time, no need to be atomic
uint32_t* version_butex;
// The identifier. It does not have to be here, however many code is
// simplified if they can get tid from TaskMeta.
bthread_t tid;
// bthread 调用的函数fn和对应的参数
void* (*fn)(void*);
void* arg;
// ContextualStack(如上文所示)用于保存对应的stack 和 context信息
ContextualStack* stack;
// Attributes creating this task(保存创建该bthread的attr,类比pthread_attr)
bthread_attr_t attr;
// Statistics(task 执行统计信息,执行时间,执行时间,context-switch的次数)
int64_t cpuwide_start_ns;
TaskStatistics stat;
// bthread local storage, sync with tls_bls (defined in task_group.cpp)
// when the bthread is created or destroyed.
// DO NOT use this field directly, use tls_bls instead.
LocalStorage local_storage;
}
// 2 个task之间的切换,即主要是切换将当前运行的task_meta的信息保存在 TaskGroup(Pthread驱动,具体下文解释) 的_cur_meta 指针字段中。
// 并且进行线程上下文的替换(如下)
inline void jump_stack(ContextualStack* from, ContextualStack* to) {
bthread_jump_fcontex(&from->context, to->context, 0/*not skip remained*/);
}
2.2.2 TaskGroup 1:N的 pthread调度器
通过TaskGroup管理归属于这个TaskGroup的所有Task,TaskGroup本身是由一个Pthread 驱动运行的。如下为其基本结构和数据结构说明
// 如下为TaskGroup核心管理数据结构
class TaskGroup {
public:
/*
* @biref 在前台创建一个bthread,并且立即执行,对应于外部接扣bthread_start_urgent接口
* 将当前的bthread压入待执行队列,立即创建一个新的Bthread执行对应的逻辑(fn和参数),
* @param[out/in] pg: bthread有可能被steal到别的thread?
* @param[out] tid: 返回对应的id
* @param[in] attr:类似pthread attr(如栈大小)
* @param[in] fn: 传入函数
* @param[in] arg: 传入参数
*/
static int start_foreground(TaskGroup** pg,
bthread_t* __restrict tid,
const bthread_attr_t* __restrict attr,
void* (*fn)(void*),
void* __restrict arg);
/*
* @brief 创建一个bthread,对应外部接口为bthread_start_background,将对应
* 的新创建的bthread的tid push 到当前TaskGroup的 runqueue(_rq)
* 并且继续执行当前执行体的逻辑
* @param[out] tid: 设置对应的id
* @param[in] attr:类似pthread attr
* @param[in] fn: 传入函数
* @param[in] arg: 传入参数
*/
template
int start_background(bthread_t* __restrict tid,
const bthread_attr_t* __restrict attr,
void* (*fn)(void*),
void* __restrict arg);
/*
* @brief 调度下一个bthread
* @param[in/out] pg: 对应传入的TaskGroup
*/
static void sched(TaskGroup** pg);
static void ending_sched(TaskGroup** pg);
/*
* @brief 如下基本的利用bthread之间的同步(接下来固定章节进行分析)
*/
static void join(bthread_t tid, void** return_value);
static void yield(TaskGroup** pg);
static void usleep(TasKGroup** pg, uint64_t timeout_us);
static void set_stopped(bthread_t tid);
/*
* TaskGroup 的main 函数的入口
*/
void run_main_task();
private:
TaskMeta* _cur_meta; // 当前执行过程中的Bthread对应的TaskMeta
TaskControl* _control; // 当前Pthread(TaskGroup)所属的TaskControl(线程池)
int _num_signal; // push任务到自身队列,未signal唤醒其他TaskGroup的次数
int _nsignaled; // push任务到自身队列,signal其他TaskGroup的次数(一旦signal置0)
int64_t _last_run_ns; // 上一次调度执行的时间
int64_t __cumulated_cputime_ns; // 总共累计的执行时间
size_t _nswitch; // bthread之间的切换次数
/*
* 在执行下一个任务(task)之前调用的函数,比如前一个bthread 切入到新的bthread之后
* 需要把前一个任务的btread_id push 到runqueue以备下次调用_等
*/
RemainedFn _last_context_remained; // 执行函数
void* _last_context_remained_args; // 执行参数
// 没有任务在的时候停在停车场等待唤醒
ParkingLot* _pl;
ParkingLot::State _last_pl_state; // 停车场的上一次状态,用户wakeup
// 本TaskGroup(pthread) 从其他TaskGroup抢占任务的随机因子信息(work-steal)
size_t _steal_seed;
size_t _steal_offset;
ContexualStack* _main_stack; // 初始化执行该TaskGroup的Pthread的初始_main_stack
bthread_t _main_tid; // 对应的maiin thread 的pthread信息
WorkStrealingQueue _rq; // 本taskGroup的runqueue_
RemoteTaskQueue _remote_rq; // 用于存放非TaskControl中线程创建的Bthread(比如)
// 外围的Pthread直接调用bthread库接口创建的bthread
int _remote_num_nosignal;
int _remote_nsignaled;
}
- TaskGroup的调度循环
/*
* @brief: 由TaskControl创建的线程(Pthread) 通过调用如下函数进入调度所有Bthread任务的主循环
*
*/
TaskGroup::run_main_task() {
// 启动时候任务队列中没有任何(或者说任务做完之后),需要等待
// 任务可能已经放入自身的remote_queue,也有可能从别的TaskGroup中steal
while(wait_task(&tid)) {
// 获取到任务进行持续调度,这里会在设置完tid对应的task-meta之后
// 调用TaskGroup::task_runner 函数对当前任务进行处理,然后持续调用
// ending_shced 从自身的run_queue和remote_queue中或者steal的方式调度任务
TaskGroup::sched_to(&dummy,tid);
}
// 返回退出
}
- TaskGroup对外的核心接口
// 调度到next_tid对应的bthread并进行执行
inline void TaskGroup::sched_to(taskGroup** pg, bthread_t next_tid);
// 按照调度顺序,调度到下一个bthread(runqueue, 自己的remotequeue,从其他TaskGroup steal)
void TaskGroup::sched();
// 将tid对应的bthread push到该TaskGroup的run_queue
void TaskGroup::ready_to_run(bthread_t tid, bool nosignal);
// 将tid对应的bthread push到该TaskGroup的remote_queue
void TaskGroup::ready_to_run_remote(bthread_t tid)
// wrapper of user bthread function,所有的bthread任务调用的入口
// 如果有Remainfunc需要调用,首先调用RemainFunc,然后
// 执行bthread 对应的func,完成之后,继续调用ending_sched调度执行其他任务
void TaskGroup::task_runner(intptr_t)
// 在执行下一个任务之前调用的函数,比如迁移bthread执行完毕之后的清理工作
// 前一个bthread 切入到新的bthread之后,需要把前一个任务的btread_id push 到runqueue_等
typedef void (*RemainedFn)(void*);
void set_remained(RemainedFn cb, void* arg) {
_last_context_remained = cb;
_last_context_remained_arg = arg;
}
2.2.3 TaskContrl & WorkSteal
TaskControl 主要负责如下几大块的内容
- 管理所有的Taskgroup,比如start,stop, add
- 在TaskControl管辖的Pthread之外的Pthread创建的Bthread,由TaskControl 随机选一个TaskGroup进行bthread投递。
- signal_task,用于唤醒没有任务在等待的TaskGroup处理任务
- steal_task, 用于TaskGroup在自身队列中没有任务情况下进行抢占任务。
// TaskControl 的核心数据结构如下
class TaskControl {
public:
/*
* @brief:创建对应数量的pthread和TaskGroup,pthread 1对1驱动TaskGroup
* 创建全局timer_thread,用于驱动超时timer
* @param[in] nconcurrency: 用于定义并发度
*/
int init(int nconcurrency);
/*
* @brief:用于TaskGroup之间相互steal task
* @param[out] tid: steal到的bthread对应的tid
* @param[in/out] seed: 上一次steal的TaskGroup在TaskGroup Array中位置
* @param[in] offset: 在TaskGroup Array中steal work的步长
*/
bool steal_task(bthread_t* tid, size_t* seed, size_t offset);
/*
* @brief:主要是用于唤醒在停车场等待的TaskGroup
*
* @param[in]: signal的TaskGroup的数量
*/
void signal_task(int num_task);
/*
* @brief: 关闭所有的_worker(pthread)
*/
void stop_and_join();
......
private:
// TaskGroup相关管理接口
butil::atomic _ngroup;
TaskGroup** _groups;
butil::Mutex _modify_group_mutex;
bool _stop; // 标记全部退出
butil::atomic _concurrency; // 并发度
std::vector _workers; // 记录的对应的pthread
// 各种计数器
bvar::Adder _nworkers;
butil::Mutex _pending_time_mutex;
butil::atomic _pending_time;
bvar::PassiveStatus _cumulated_worker_time;
bvar::PerSecond > _worker_usage_second;
bvar::PassiveStatus _cumulated_switch_count;
bvar::PerSecond > _switch_per_second;
bvar::PassiveStatus _cumulated_signal_count;
bvar::PerSecond > _signal_per_second;
bvar::PassiveStatus _status;
bvar::Adder _nbthreads;
// 停车场,用于TaskGroup 没有任务的时候在这里停车和唤醒
static const int PARKING_LOT_NUM = 4;
ParkingLot _pl[PARKING_LOT_NUM];
}
- WorkSteal 算法
steal_task算法很简单,内容在bool steal_task(bthread_t* tid, size_t* seed, size_t offset);
如上的输入参数是各个TaskGroup的 seed ,是在TaskGroup初始化的时候调用随机算法生成。offset 是使用表的方式引入?表?没错是质数表,这种伪随机比较优秀?,各个质数之间没有公因子,所以相对来说就非常独立, 按道理说所有数都可以通过质数换算得到,所有质数可以作为构建所有数的基地。
TaskGroup::TaskGroup(TaskControl* c)
......
_steal_seed = butil::fast_rand();
_steal_offset = OFFSET_TABLE[_steal_seed % ARRAY_SIZE(OFFSET_TABLE)];
_pl = &c->_pl[butil::fmix64(pthread_numeric_id()) % TaskControl::PARKING_LOT_NUM];
......
}
const size_t OFFSET_TABLE[] = {
#include "bthread/offset_inl.list"
};
// offset_inl.list 有点怪又没有?
/*
36809,36821,36833,36847,36857,36871,36877,36887,36899,36901,36913,36919,
36923,36929,36931,36943,36947,36973,36979,36997,37003,37013,37019,37021,
37039,37049,37057,37061,37087,37097,37117,37123,37139,37159,37171,37181,
37189,37199,37201,37217,37223,37243,37253,37273,37277,37307,37309,37313,
37321,37337,37339,37357,37361,37363,37369,37379,37397,37409,37423,37441,
37447,37463,37483,37489,37493,37501,37507,37511,37517,37529,37537,37547,
37549,37561,37567,37571,37573,37579,37589,37591,37607,37619,37633,37643,
*/
// 停车场停车
bool TaskGroup::wait_task(bthread_t* tid) {
if (_last_pl_state.stopped()) {
return false;
}
_pl->wait(_last_pl_state);
if (steal_task(tid)) {
return true;
}
}
}
// 调用futex进行等待
void wait(const State& expected_state) {
futex_wait_private(&_pending_signal, expected_state.val, NULL);
}
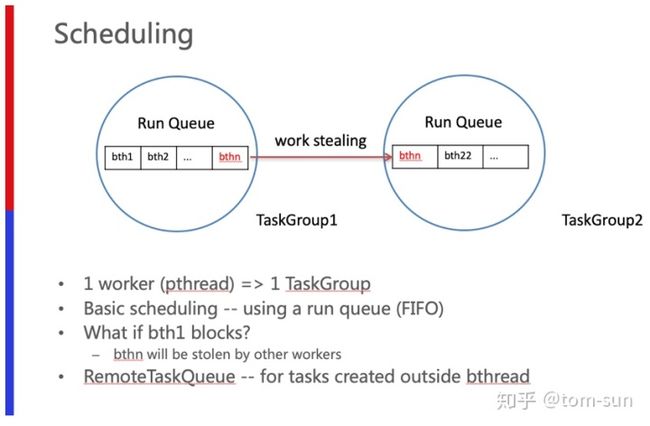
3 Bthread 之间的同步机制
- Butex
类似于当前pthread依赖的futex锁的方式实现。通过原子变量 + 用户态任务链表 的方式进行管理。产生竞争情况下,直接将bthread挂到等待队列,然后执行其他的Task,而不是通过操作系统调用Futex的方式陷入内核挂到内核任务队列。
ps:Butex核心并不是LockFree,而是在Lock的情况下,可以将Block住的Bthread 挂起来,然后执行其他可执行的Bthread。对应的WaitUp逻辑,就是将等待队列中的Bthread,重新插入到可执行队列。也就说如果基于Butex产生较为严重的竞争,其实也得陷入内核,而且还做了Butex一大堆事情,所以开销反而可能会比常规的pthread_mutex更加高,但是好处挂住bthread之后,释放Pthread。
bthread_mutex_t m;
typedef struct {
unsigned* butex; //指向如下Butex结构的value的指针
bthread_contention_site_t csite;
} bthread_mutex_t;
typedef struct {
int64_t duration_ns;
size_t sampling_range;
} bthread_contention_size_t;
// 内部核心数据结构
typedef butil::LinkedList ButexWaiterList;
struct BAIDU_CACHELINE_ALIGNMENT Butex {
butil::atomic value; // 原子变量,用于处理是否唤醒和block
ButexWaiterList waiters; // 等待队列(用于挂起对应的bthread)
internal::FastPthreadMutex waiter_lock; // 可以认为就是pthread_mutex
}
// bthread 实际block的时候使用的结构
// non_pthread_task allocates this structure on stack and queue it in
// Butex::waiters.
struct ButexBthreadWaiter : public ButexWaiter {
TaskMeta* task_meta; // 记录对应的task(该结构与TaskMeta中current_waiter双向关联)
TimerThread::TaskId sleep_id; // 超时等待情况下的sleep_id
WaiterState waiter_state; // 当前状态
int expected_value;
Butex* initial_butex;
TaskControl* control;
};
struct TaskMeta {
// [Not Reset]
butil::atomic current_waiter;
.....
}
// non_pthread_task allocates this structure on stack and queue it in
// Butex::waiters.
struct ButexPthreadWaiter : public ButexWaiter {
butil::atomic sig;
};
// Butex 的value字段 在内部使用的转换的时候会转换为如下结构
struct MutexInternal {
butil::static_atomic locked; // 1 字节用于判断是否lock
butil::static_atomic contended; // 1 字节用于判断contented;
unsigned short padding; // 2 字节用于padding
};
// butex 对外提供的用户层接口
int bthread_mutex_init(bthread_mutex_t* __restrict m,
const bthread_mutexattr_t* __restrict)
int bthread_mutex_destroy(bthread_mutex_t* m);
int bthread_mutex_trylock(bthread_mutex_t* m)
int bthread_mutex_lock(bthread_mutex_t* m)
int bthread_mutex_lock_contended(bthread_mutex_t* m)
int bthread_mutex_timedlock(bthread_mutex_t* __restrict m,
const struct timespec* __restrict abstime)
int bthread_mutex_unlock(bthread_mutex_t* m)
// butex lock逻辑分析
int bthread_mutex_lock(bthread_mutex_t* m) {
bthread::MutexInternal * splite = (bthread::MutexInternal*)m->butex;
if (!split->locked.exchange(1, butil::memory_order_acquire)) { //获取锁成功,直接返回
return 0;
}
...
return bthread::mutex_lock_contended(m);
...
}
const MutexInternal MUTEX_CONTENDED_RAW = {{1},{1},0};
const MutexInternal MUTEX_LOCKED_RAW = {{1},{0},0};
#define BTHREAD_MUTEX_CONTENDED (*(const unsigned*)&bthread::MUTEX_CONTENDED_RAW)
#define BTHREAD_MUTEX_LOCKED (*(const unsigned*)&bthread::MUTEX_LOCKED_RAW)
inline int mutex_lock_contended(bthread_mutex_t* m) {
butil::atomic* whole = (butil::atomic*)m->butex;
// while 循环表示在butex_wait 唤醒之后,会重新尝试获取锁
while (whole->exchange(BTHREAD_MUTEX_CONTENDED) & BTHREAD_MUTEX_LOCKED) {
if (bthread::butex_wait(whole, BTHREAD_MUTEX_CONTENDED, NULL) < 0 &&
errno != EWOULDBLOCK && errno != EINTR/*note*/) {
// a mutex lock should ignore interrruptions in general since
// user code is unlikely to check the return value.
return errno;
}
}
// 如果在走到这一步,其实已经原子的设置值为{1,1,0},之前的lock位为0
// 相当于当前已经获取到锁
return 0;
}
int butex_wait(void* arg, int expected_value, const timespec* abstime) {
Butex* b = container_of(static_cast*>(arg), Butex, value);
// 发现值已经变化,即有可能锁已经被释放,则返回EWIULDBLOCK,返回如上while循环重试
if (b->value.load(butil::memory_order_relaxed) != expected_value) {
errno = EWOULDBLOCK;
// Sometimes we may take actions immediately after unmatched butex,
// this fence makes sure that we see changes before changing butex.
butil::atomic_thread_fence(butil::memory_order_acquire);
return -1;
}
// 当前为pthread 情况下的处理逻辑(butex同时也允许上层pthread)
TaskGroup* g = tls_task_group;
if (NULL == g || g->is_current_pthread_task()) {
return butex_wait_from_pthread(g, b, expected_value, abstime);
}
// 当前位bthread情况下的处理逻辑
ButexBthreadWaiter bbw;
bbw.tid = g->current_tid();
bbw.container.store(NULL, butil::memory_order_relaxed);
bbw.task_meta = g->current_task();
bbw.sleep_id = 0;
bbw.waiter_state = WAITER_STATE_READY;
bbw.expected_value = expected_value;
bbw.initial_butex = b;
bbw.control = g->control();
// 超时等待情况下相关机制
if (abstime != NULL) {
.....
}
// release fence matches with acquire fence in interrupt_and_consume_waiters
// in task_group.cpp to guarantee visibility of `interrupted'.
// 如下进行挂起,sched 出去
bbw.task_meta->current_waiter.store(&bbw, butil::memory_order_release);
g->set_remained(wait_for_butex, &bbw);
TaskGroup::sched(&g);
}
// 在执行另外的bthread之前需要执行的逻辑
static void wait_for_butex(void* arg) {
ButexBthreadWaiter* const bw = static_cast(arg);
Butex* const b = bw->initial_butex;
{
// 这里是重要的同步点(唤醒的时候同样要先lock这把锁,实现lock与unlock的同步)
// 此处使用futex竞争在产生竞争情况下需要陷入内核进行等待
BAIDU_SCOPED_LOCK(b->waiter_lock);
if (b->value.load(butil::memory_order_relaxed) != bw->expected_value) {
bw->waiter_state = WAITER_STATE_UNMATCHEDVALUE;
} else if (bw->waiter_state == WAITER_STATE_READY/*1*/ &&
!bw->task_meta->interrupted) {
b->waiters.Append(bw);
bw->container.store(b, butil::memory_order_relaxed);
return;
}
}
// b->container is NULL which makes erase_from_butex_and_wakeup() and
// TaskGroup::interrupt() no-op, there's no race between following code and
// the two functions. The on-stack ButexBthreadWaiter is safe to use and
// bw->waiter_state will not change again.
// 重新进行调度push到队列中等待下次调度
unsleep_if_necessary(bw, get_global_timer_thread());
tls_task_group->ready_to_run(bw->tid);
}
// butex unlock逻辑分析
int bthread_mutex_unlock(bthread_mutex_t* m) {
butil::atomic* whole = (butil::atomic*)m->butex;
....
const unsigned prev = whole->exchange(0, butil::memory_order_release);
// CAUTION: the mutex may be destroyed, check comments before butex_create
// 之前还只是自己上的锁,没有人等待,那么直接返回(也就是说在大多数无竞争情况下开销非常小)
if (prev == BTHREAD_MUTEX_LOCKED) {
return 0;
}
// Wakeup one waiter
// 否则尝试唤醒等待的bthread/pthread
// contention相关逻辑用语统计等待时间
if (!bthread::is_contention_site_valid(saved_csite)) {
bthread::butex_wake(whole);
return 0;
}
const int64_t unlock_start_ns = butil::cpuwide_time_ns();
bthread::butex_wake(whole);
const int64_t unlock_end_ns = butil::cpuwide_time_ns();
saved_csite.duration_ns += unlock_end_ns - unlock_start_ns;
bthread::submit_contention(saved_csite, unlock_end_ns);
return 0;
}
// butex 在唤醒情况下的逻辑,即lock住对应的,pop出等待任务队列的第一个任务
// 如果是bthread,如果当前执行的是TaskGroup的现场,直接刷入起run queue
// 如果是pthread,调用TaskControl 随机push到一个 TaskGroup的 remote queue
// 如果是Pthread,调用相逻辑
int butex_wake(void* arg) {
Butex* b = container_of(static_cast*>(arg), Butex, value);
ButexWaiter* front = NULL;
{
BAIDU_SCOPED_LOCK(b->waiter_lock);
if (b->waiters.empty()) {
return 0;
}
front = b->waiters.head()->value();
front->RemoveFromList();
front->container.store(NULL, butil::memory_order_relaxed);
}
if (front->tid == 0) {
wakeup_pthread(static_cast(front));
return 1;
}
ButexBthreadWaiter* bbw = static_cast(front);
unsleep_if_necessary(bbw, get_global_timer_thread());
TaskGroup* g = tls_task_group;
if (g) {
// 直接将当前的执行权限交给block的第一个bthread
TaskGroup::exchange(&g, bbw->tid);
} else {
bbw->control->choose_one_group()->ready_to_run_remote(bbw->tid);
}
return 1;
}
4 执行队列 ExecutionQueue
brpc当前采用类似grpc的单tcp连接多路复用的方式实现,也就是说可以在单条连接上处理上层并发的诸多的发送和接收请求。
ExecutionQueue为基于bthread的多生产者,单消费者无锁队列。可以在如上核心路径上实现无所化。
基本原理也是依赖操作系统提供CAS语义,主要使用原子的exchange语义-结合bthread的未完全连接情况下的yeild特性完成。
- 多生产者
- 使用原子的头插方法将要执行的任务发送插入到队列( _head.exchange(node, butil::memory_order_release);)
- 但是由于原子设置头节点和设置该节点的Next无法形成原子性
- 所以会发生头插入完了,但是完成指向前一个节点的操作还未完成(即处于UNCONNECT状态)
下图为未完全connect情况下示例图

- 消费者
- 插入第一个节点的情况下(发现前一个节点为nullptr)的情况下会启动bthread进行消费
- 但是在遍历过程中会发现由于多生产者的并发未连接完成的链表,这个时候会执行bthread_yeild方式切出一会儿(等到连接上的时候再进行便利)直到遍历完成
- 获取到的任务顺序为FILO,所以使用FIFO的方式执行请求
- 完成之后,使用原子的CAS接口判断是否当前的head还是之前取下来的head。如果是,说明没有更多的task,原子调用会将head设置为nullptr,该bthread退出。否则取下接下来的请求知道之前的head,继续进行处理(_head.compare_exchange_strong(old_head(expected), desired=NULL))
- PS:如果如上第4步的是发现没有更多待处理的请求下,当前bthread会退出,下一次插入请求的时候发现当前的head为nullptr会新生成一个bthread进行执行(也就是为了彻底避免生产者和消费者的等待,生产者其实是消费者进行创建的)
5. Buffer ManageMent
5.1 BRPC Buffer ManageMent
在一个程序的处理中,往往涉及使用Buffer进行不确定长度数据payload读取,很多的数据转换的拷贝等,对于一个典型的RPC框架来说,其需要处理的业务包括
- 从网络拷贝数据:网络数据包可能是一段段到达并拷贝出来的,append到buffer
- 将数据从内存拷贝到网络套接字fd,类似于一段段cut 到 网络
- 存储相关的业务:需要从文件中读取或者写入对应的文件(由于读取数据的非连续行,需要使用writev/readv等调用将数据一次性写入文件,避免多次陷入内存)。
BRPC 在这些环节通过其设计的 非连续的zerocopy buffer 称为IOBuf,并且结合ThreadLocal等特性做了高效实现和便捷的使用方式。
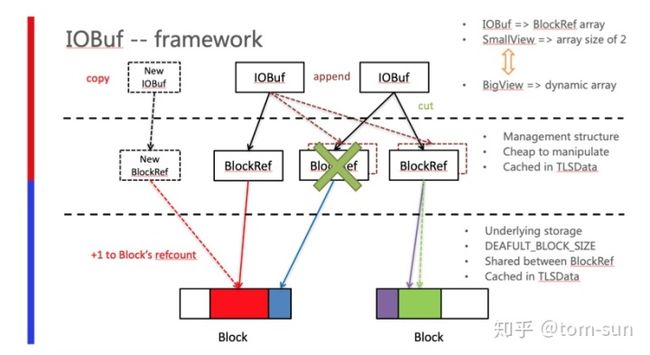
每个线程使用threadLocal的方式向底层内存分配器申请整块的内存,当前默认配置的大小为8KB(ps:本身依赖malloc进行内存分配,malloc底层内存分配器一般都做了threadLocal的实现,比如tcmalloc、jemalloc),然后这8KB的数据按照用户需要的方式分片大小(使用BlockRef结构)向上分配给对应的IOBuf。Block维护了引用计数,一个Block中所有的区段全部释放之后才能够将内存释放,所以IOBuf 适用于生命周期比较短的对象,不然空间浪费会比较严重,比较适合用于RPC场景下的Buffer 管理,IOBuf本身可以在多个线程之间进行传递和操作,所以一个IOBuf的数据有可能是指向很多Thread的ThreadLocal分配的内存Block,以下为核心数据结构的说明。PS:IOBuf是非线程安全结构。
// 核心数据结构说明
struct BlockRef{
uint32_t offset; // 对应占用数据在Block中的offset
uint32_t length; // 对应占用数据片段在Block中的长度
Block* block; // 对应的共享或者独占的block的指正
};
// block 的头部用于存放block元数据,剩余部分用于存储数据, 默认整个数据块的大小8KB。头部分用于存储元信息
struct Block {
buitl::atomic nshared; // 用于维护block的引用计数
uint16_t flags; // 用与说明对应的数据是内部malloc,或者是外部给定的数据
// 用于直接用于引用外部数据,避免数据拷贝
uint16_t abi_check; // 原始的cap,不能是0 (?)
uint32_t size; // 已经被占用的大小
uint32_t cap; // Block总空间大小
Block* portal_next; // 用于在线程退出情况下,进行便利释放应用计数?
char* data; // 用于指向对应的数据(在内部管理的数据的时候)
// data 指向内部block 8KB 数据库的数据部分
// 在flags 非0 情况下,data直接指向的就是外部的数据指针
// 8KB数据去的第一字节指向用于自定义的用于析构用户数据的函数指针
}
// 所谓IOBuf 就是通过BlockRef 实现对底层Block数据的管理/共享等等
struct IOBuf {
private:
union {
BigView _bv; // 超过2个BlockRef 情况下会通动态管理(初始数组大小 32)
SmallView _sv; // 不超过2个Block情况下
}
}
struct SmallView {
BlockRef refs[2];
}
struct BigView {
int32_t magic; // 表示这个union为为BigView(设置为-1)
uint32_t start; // 当前可用的BlockRef Array的的下一个index
BlockRef* refs; // BlockRef数组(采用类似vector的空间管理方式)
uint32_t nref; // 当前的BlockRef 的数量
uint32_t cap_mask; //
size_t nbytes; // 记录这个IOBuf 的长度
}
// IOBuf 核心对外接口
// 通过IOPortal封装了IOBuf与fd之间的双向操作
class IOPortal : public IOBuf {
/* @brief:从文件或者网络fd中获取数据到IOBuf
* param[in] fd: 对应操作的fd(网络/文件)
* param[in] offset:操作偏移(对于文件比较有用)
* param[in] max_size: 操作数据大小
*/
ssize_t append_from_file_descriptor(int fd, off_t offset, size_t max_count);
/* @brief:从文件或者网络fd中获取数据到IOBuf
* param[in] fd: 对应操作的fd(网络/文件)
* param[in] offset:操作偏移(对于文件比较有用)
* param[in] max_size: 操作数据大小
*/
ssize_t pappend_from_file_descriptor(int fd, off_t offset, size_t max_count);
}
// 另外除了从传统的指针指向内存地址块外,可以直接将用户复制给IOBuf,自定义删除回调等情况的避免拷贝的接口
/* @brief:append用户数据到IOBuf(不进行数据拷贝,只进行数据的拷贝)
* @param[in] data:用户内存地址
* @param[in] deleter: 删除函数
*/
int IOBuf::append_user_data(void *data, size_t size, void (*deleter)(void*));
5.2 About Memory Copy
然后回到问题本身,为什么需要避免内存拷贝?为什么内存拷贝对一个高性能的RPC框架来说至关重要? 这个可以从2个方面进行展开
- 内存拷贝的速度: 内存拷贝的速度,这个对于一般的业务场景来说往往不是太大的问题,内存拷贝的速度已经够快了。内存访问的速度在40ns 级别,而且往往现在CPU会使用SIMD机制来实现一定程度的并行。如下为在单线程内存拷贝的速度测试差不多可以到达14GB/s。纯从内存拷贝的速度来,一般上来说够不成瓶颈,1MB数据拷贝0.51us,也就是4KB数据158ns
// 测试内存&机器 (Intel(R) Xeon(R) CPU E5-2670 v3 @ 2.3GHz, DDR4)
// 为了避免虚拟地址页表TLB加载的影响,进行多轮次测试
// 为了避免最后最后沦为为CPU L1、L2、L3的测试,测试内存应该远大于L1+L2+L3
// 测试程序如下
#include
#include
#include
#include
void memcpy_speed(unsigned long buf_size, unsigned long iters){
struct timeval start, end;
void* pbuff_1;
void* pbuff_2;
pbuff_1 = malloc(buf_size);
pbuff_2 = malloc(buf_size);
gettimeofday(&start, NULL);
for(int i = 0; i < iters; ++i){
memcpy(pbuff_2, pbuff_1, buf_size);
}
gettimeofday(&end, NULL);
printf("%5.3f\n", ((buf_size*iters)/(1.024*1.024))/((end.tv_sec - \
start.tv_sec)*1000*1000+(end.tv_usec - start.tv_usec)));
free(pbuff_1);
free(pbuff_2);
}
int main(void) {
memcpy_speed(100*1024*1024, 1000);
}
- 内存拷贝的CPU开销:当前内存拷贝基本的流程就是先将内存数据一级一级拷贝到寄存器,然后存储到目的内存,基本就是使用CPU进行的操作,在一般的业务场景下使用CPU进行内存拷贝足够。但是当前在一些网络数据面等场景下,或者存储数据面的场景,随着SSD和网络性能的提高,都在避免进行过多通过syscall 进行内存拷贝,从而造成过多的CPU消耗,并且通过SPDK等方式通过轮训模式减少context switch来充分利用CPU 来驱动高性能设备的性能,当然内核也在适应这个趋势,比如类似io_uring的方案。
Notes
作者:网易存储团队工程师 TOM。限于作者水平,难免有理解和描述上有疏漏或者错误的地方,欢迎共同交流;部分参考已经在正文和参考文献中列表注明,但仍有可能有疏漏的地方,有任何侵权或者不明确的地方,欢迎指出,必定及时更正或者删除;文章供于学习交流,转载注明出处
参考文献
1https://www.cnblogs.com/ngnntds03/p/10700029.htmlNginx如何解决多进程acctept的惊群和连接处理的均衡问题
2https://zhuanlan.zhihu.com/p/57863097malloc 的实现原理 内存池 mmap sbrk 链表
3https://github.com/apache/incubator-brpc/blob/master/docs/cn/memory_management.md
4x86-64下函数调用及栈帧原理https://blog.csdn.net/lqt641/article/details/73002566
5http://www.cs.virginia.edu/~evans/cs216/guides/x86.htmlx86-Assembly-Guide
6https://zhuanlan.zhihu.com/p/31875174cache
7https://stackoverflow.com/questions/21038965/why-does-the-speed-of-memcpy-drop-dramatically-every-4kbspeed of memcpy() performance
8https://blog.tsunanet.net/2010/11/how-long-does-it-take-to-make-context.htmlhow-long-does-it-take-to-make-context
9https://akkadia.org/drepper/cpumemory.pdfWhat Every Programmer Should Know about Memory
10http://outofsync.net/wiki/index.php?title=File:Smp_numa.png
11ihttps://www.byteisland.com/io_uring%ef%bc%881%ef%bc%89-%e6%88%91%e4%bb%ac%e4%b8%ba%e4%bb%80%e4%b9%88%e4%bc%9a%e9%9c%80%e8%a6%81-io_uring/io_uring
12http://kms.netease.com/article/10556
13https://lwn.net/Articles/360699/a futex overview and update