2--决策树(预剪枝、后剪枝部分)和 神经网络
本周学习内容:
- 继续学习预剪枝、后剪枝部分的处理以及结果可视化展示
- 学习神经网络算法相关内容
1 实现决策树结果的可视化以及预剪枝、后剪枝的处理
这里可视化是选择python 中的 graphviz 库来实现,graphviz模块提供了两个类:Graph和Digraph。他们都是使用DOT语言,一个是创建无向图,一个是创建有向图。
首先在所给出的数据集(仍使用上周的西瓜数据集)上基于基尼指数来进行划分选择得到的决策树,采用留出法,预留一部分数据用作测试集来对生成决策树的精度进行评估,这里将数据集随机化为两部分,编号{1,2,3,6,7,10,14,15,16,17}的数据作为训练集,其余数据作为测试集。
具体计算基尼指数函数如下:

最终构建的决策树结果如图1所示,

图1未剪枝的决策树
对图1的决策树进行预剪枝得到图2的决策树,可以看出来该方法剪掉了较多的分支,虽然降低了过拟合的风险,但存在较大的欠拟合风险。
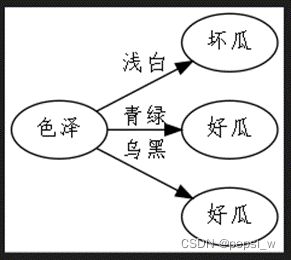
图2 预剪枝的决策树
对图1的决策树进行后剪枝得到图3的决策树,与图2相比,该决策树保留了较多的分支,欠拟合风险较小,但训练时间开销会大一些。
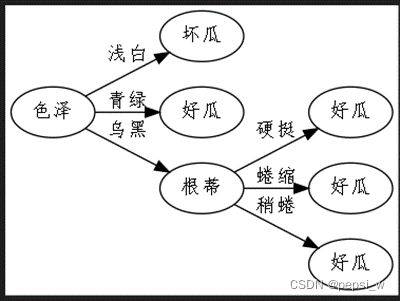
图3 后剪枝的决策树
这里对三种决策树分别进行测试得到各自在测试集上的精度,结果如图4所示:

图4 各决策树在测试集上表现的精度
2 神经网络
2.1神经元模型
神经元模型是神经网络中最基本的。如图5所示,在该模型中,神经元接受到来自n个其他神经元传递的输入信号,通过带权重的连接进行传递,神经元接收到的总输入值与神经元的阈值进行比较,最后通过激活函数处理后得到输出。
图5 MP神经元模型
2.2 感知机与多层网络
感知机由两层神经元组成,输入层接收输入信号后传递给输出层,易知其只有输出层神经元需要进行激活函数处理,即只拥有一层功能神经元。其学习规则比较简单,对训练数据(X,y),若当前感知机的输出为y1,则其权重将调整为:
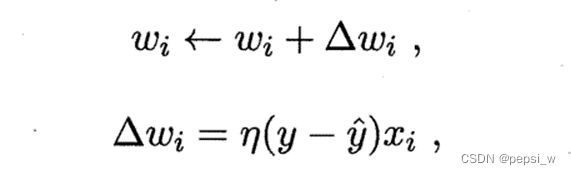
其中η为学习率,通常设置为一个较小的正数。如需解决非线性问题,就需要用到多层功能神经元,即神经网络进行学习的过程就是根据输入的训练数据来调整神经元之间的权重以及阈值,得到最好的一个效果。
2.3 误差逆传播(BP)算法
BP(back propagation)神经网络是是一种按照误差逆向传播算法训练的多层前馈神经网络。既无法直接得到隐层的权值,那就通过输出层得到输出结果和期望输出的误差来间接调整隐层的权值,该算法的基本思想:学习过程由信号的正向传播(求损失)与误差的反向传播(误差回传)两个过程组成。
正向传播,在这个过程中,根据输入的样本,给定的初始化权重值W和偏置项的值b, 计算最终输出值以及输出值与实际值之间的损失值。如果损失值不在给定的范围内则进行反向传播的过程,否则停止W,b的更新。
反向传播,将输出以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。
网络结构如图6所示,设初始权重值w和偏置项b为:
W = (0.1,0.15,0.2,0.25,0.3,0.35,0.4,0.45,0.5,0.55,0.6,0.65)
b = (0.35,0.65)
这里为了便于计算,假设从输入层到隐层之间, 隐层到输出层之间的偏置项b恒定。

图6 网络结构图
1) 正向传播计算过程
从输入层到隐层
h1 = w1*l1 +w2*l2 +b1*1 = 0.1*5+0.15*10+0.35*1
h2 = w3*l1 +w4*l2 +b1*1 = 0.2*5+0.25*10+0.35*1
h3 = w5*l1 +w6*l2 +b1*1 = 0.3*5+0.35*10+0.35*1
经过激活函数后:
Outh1 = 11+e-h1
Outh2= 1 1+e-h2
Outh3= 1 1+e-h3
隐层到输出层:
neto1 = outh1*w7 +outh2*w9 +outh3*w11+ b2*1= 2.35*0.4 + 3.85*0.5 +5.35 *0.6+0.65 = 2.10192
neto2 = outh1*w8 +outh2*w10 +outh3*w12 +b2*1= 2.35*0.45 + 3.85*0.55 +5.35 *0.65 +0.65= 2.24629
经过激活函数后:
Outo1 = 0.89(真实值为0.01) Outo2 = 0.90(真实值为0.99)
均方误差为:
易知其与真实值不符,则需要进行BP反馈计算。这里只对一个权重进行更新示例,运用梯度下降法求解W7的值。
则此时的损失函数为: 。
又有 neto1 = outh1*w7 +outh2*w9 +outh3*w11+ b2*1, outo1 = f(o1)
则对W7求偏导数得到:
根据参数更新公式得到W7* = 0.36 同理可对其他参数进行更新。
2.4 RBF网络
RBF全称Radial Basis Function,中文名称“径向基函数”,是一种单隐层前馈神经网络,使用径向基函数作为隐层神经元激活函数,输出层是对隐层神经元输出的线性组合。通常采用两部过程来训练RBF网络,第一步,确定神经元中心 Ci,常用的方式包括随机采样、聚类等;第二步,利用BP算法等来确定参数Wi和βi。
2.5 ART网络
ART(Adaptive Resonance Theory)网络属于竞争型学习类,即网络的输出神经元相互竞争,每一时刻仅有一个竞争获胜的神经元被激活,其他神经元的被抑制。该网络由比较层、识别层、识别阈值和重置模块构成。其中比较层负责接 输入样本,并将其传递给识别层神经元。识别层每个神经元对应一个模式类,神经元数目可在训练过程中动态增长以增加新的模式类。
竞争的最简单的方式是计算输入向量与每个识别层神经元所对应的模式类的代表向量之间的距离,距离最小者胜。获胜神经元将向其他识别层神经元发送信号,抑制其激活。若输入向量与获胜神经元所对应的代表向量之间的相似度大于识别阈值,则当前输入样本将被归为该代表向量所属类别。同时网络连接权将会更新使得以后在接收到相似输入样本时该模式类会计算出更大的相似度,从而使该获胜神经元有更大可能获胜。若相似度不大于识别阈值,则重置模块将在识别层增设一个新的神经元,其代表向量就设置为当前输入向量。
2.6 SOM网络
SOM(Self-Organizing Map ,自组织映射)网络是一种竞争学习型的无监督神经网络,能将高维输入数据映射到低维空间(通常为二维),同时保持输入数据在高维空间的拓扑结构,即将高维空间中相似的样本点映射到网络输出层中的邻近神经元。
下周计划:
- 学习支持向量机相关内容
- 对于python编程语言还是不能熟练使用,看能不能复现一些核心代码。