hadoop+Springboot+Echarts网站访问量数据分析及可视化
网站访问量静态日志文件分析系统
- 目录大纲
-
- 获取静态日志
- 数据预处理
-
-
- 新建Maven
- 打包jar包运行
-
- 数据仓库开发
-
-
- 下载安装hive
- 修改配置文件
- 配置MySQL元数据库
-
- 实现数据仓库
- 数据分析
-
-
- 流量分析
- 人均浏览量分析
-
- sqoop数据导出
-
-
- 安装Sqoop并配置
- 将数据导入MySQL
-
- 日志分析系统报表展示
目录大纲
获取静态日志
找到自己的日志文件所在的位置
我的在这里

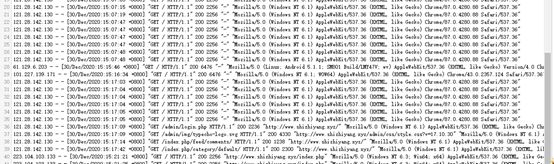
日志文件里的内容大致这样
数据预处理
新建Maven
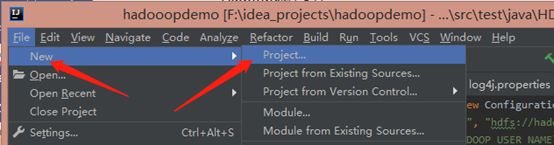

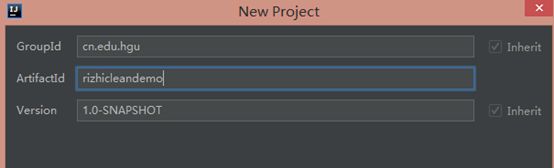
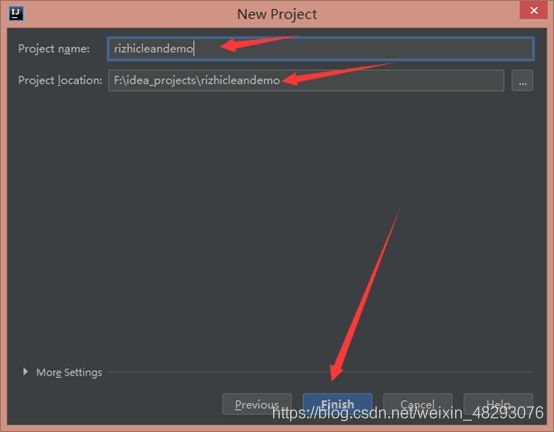
目录结构大致如下

WebLogBean下
package weblog;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 对接外部数据的层,表结构定义最好跟外部数据源保持一致
* 术语: 贴源表
* @author itcast
*
*/
public class WebLogBean implements Writable {
private boolean valid = true;// 判断数据是否合法
private String remote_addr;// 记录客户端的ip地址
private String remote_user;// 记录客户端用户名称,忽略属性"-"
private String time_local;// 记录访问时间与时区
private String request;// 记录请求的url与http协议
private String status;// 记录请求状态;成功是200
private String body_bytes_sent;// 记录发送给客户端文件主体内容大小
private String http_referer;// 用来记录从那个页面链接访问过来的
private String http_user_agent;// 记录客户浏览器的相关信息
//设置属性值
public void set(boolean valid,String remote_addr, String remote_user, String time_local, String request, String status, String body_bytes_sent, String http_referer, String http_user_agent) {
this.valid = valid;
this.remote_addr = remote_addr;
this.remote_user = remote_user;
this.time_local = time_local;
this.request = request;
this.status = status;
this.body_bytes_sent = body_bytes_sent;
this.http_referer = http_referer;
this.http_user_agent = http_user_agent;
}
public String getRemote_addr() {
return remote_addr;
}
public void setRemote_addr(String remote_addr) {
this.remote_addr = remote_addr;
}
public String getRemote_user() {
return remote_user;
}
public void setRemote_user(String remote_user) {
this.remote_user = remote_user;
}
public String getTime_local() {
return this.time_local;
}
public void setTime_local(String time_local) {
this.time_local = time_local;
}
public String getRequest() {
return request;
}
public void setRequest(String request) {
this.request = request;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public String getBody_bytes_sent() {
return body_bytes_sent;
}
public void setBody_bytes_sent(String body_bytes_sent) {
this.body_bytes_sent = body_bytes_sent;
}
public String getHttp_referer() {
return http_referer;
}
public void setHttp_referer(String http_referer) {
this.http_referer = http_referer;
}
public String getHttp_user_agent() {
return http_user_agent;
}
public void setHttp_user_agent(String http_user_agent) {
this.http_user_agent = http_user_agent;
}
public boolean isValid() {
return valid;
}
public void setValid(boolean valid) {
this.valid = valid;
}
/**
* 重写toString()方法,使用Hive默认分隔符进行分隔,为后期导入Hive表提供便利
* @return
*/
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(this.valid);
sb.append("\001").append(this.getRemote_addr());
sb.append("\001").append(this.getRemote_user());
sb.append("\001").append(this.getTime_local());
sb.append("\001").append(this.getRequest());
sb.append("\001").append(this.getStatus());
sb.append("\001").append(this.getBody_bytes_sent());
sb.append("\001").append(this.getHttp_referer());
sb.append("\001").append(this.getHttp_user_agent());
return sb.toString();
}
/**
* 序列化方法
* @param in
* @throws IOException
*/
@Override
public void readFields(DataInput in) throws IOException {
this.valid = in.readBoolean();
this.remote_addr = in.readUTF();
this.remote_user = in.readUTF();
this.time_local = in.readUTF();
this.request = in.readUTF();
this.status = in.readUTF();
this.body_bytes_sent = in.readUTF();
this.http_referer = in.readUTF();
this.http_user_agent = in.readUTF();
}
/**
* 反序列化方法
* @param out
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeBoolean(this.valid);
out.writeUTF(null==remote_addr?"":remote_addr);
out.writeUTF(null==remote_user?"":remote_user);
out.writeUTF(null==time_local?"":time_local);
out.writeUTF(null==request?"":request);
out.writeUTF(null==status?"":status);
out.writeUTF(null==body_bytes_sent?"":body_bytes_sent);
out.writeUTF(null==http_referer?"":http_referer);
out.writeUTF(null==http_user_agent?"":http_user_agent);
}
}
WebLogParser下
package weblog;
import weblog.WebLogBean;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
/**
* 处理原始日志,过滤出真实请求数据,转换时间格式,对缺失字段填充默认值,对记录标记valid和invalid
*/
public class WeblogPreProcess {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WeblogPreProcess.class);
job.setMapperClass(WeblogPreProcessMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//这里的是HDFS下的文件路径
FileInputFormat.setInputPaths(job, new Path("/weblog/input"));
FileOutputFormat.setOutputPath(job, new Path("/weblog/output"));
job.setNumReduceTasks(0);
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
public static class WeblogPreProcessMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
// 用来存储网站url分类数据
Set<String> pages = new HashSet<String>();
Text k = new Text();
NullWritable v = NullWritable.get();
/**
* 设置初始化方法,加载网站需要分析的url分类数据,存储到MapTask的内存中,用来对日志数据进行过滤
* 如果用户请求的资源是以下列形式,就表示用户请求的是合法资源。
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
pages.add("/about");
pages.add("/black-ip-list/");
pages.add("/cassandra-clustor/");
pages.add("/finance-rhive-repurchase/");
pages.add("/hadoop-family-roadmap/");
pages.add("/hadoop-hive-intro/");
pages.add("/hadoop-zookeeper-intro/");
pages.add("/hadoop-mahout-roadmap/");
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行数据
String line = value.toString();
//调用解析类WebLogParser解析日志数据,最后封装为WebLogBean对象
WebLogBean webLogBean = WebLogParser.parser(line);
if (webLogBean != null) {
// 过滤js/图片/css等静态资源
WebLogParser.filtStaticResource(webLogBean, pages);
k.set(webLogBean.toString());
context.write(k, v);
}
}
}
}
打包jar包运行


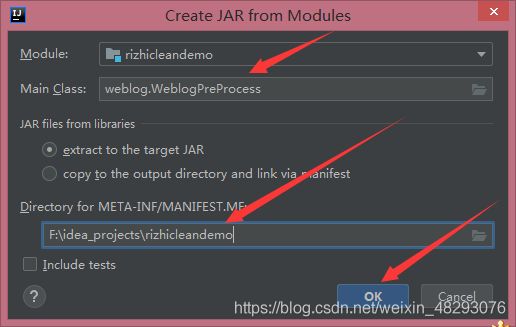

打包ok之后一定要点击Bulid


Bulid之后你将会看见新生成的文件

Jar包打包完成
Jar包运行
Hdfs上新建输入路径
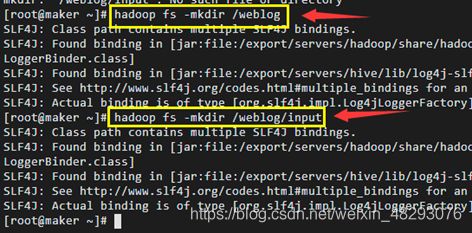
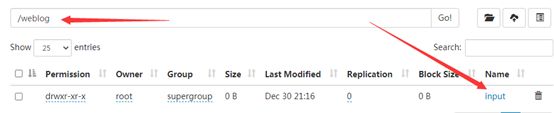
上传日志文件

上传jar包,在本地上找到打包好的jar包


![]()

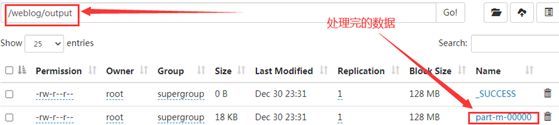
处理完的数据长这样

数据仓库开发
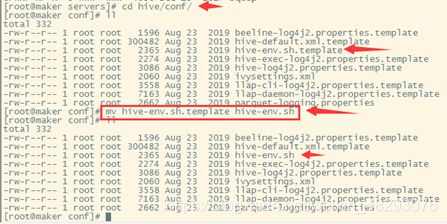
下载安装hive
嵌入模式


更换guava jar包

复制hadoop下的高版本
![]()
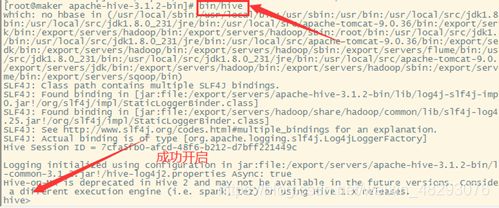
修改配置文件
由于hive包的名称过于冗长,因此首先对于Apache hive进行重命名


配置环境变量
![]()

配置MySQL元数据库
上传mysql驱动到hive/lib
自己事先在mysql官网上下载好

在hive/conf路径创建配置文件hive-site.xml:
注意写入mysql的用户名密码


重启hadoop集群初始化
格式化hive,在hive下输入命令
schematool -dbType mysql -initSchema

开启mysql权限



实现数据仓库
创建数据仓库

创建表

导入数据
由于原始的日志文件已经经过MapReduce处理后,直接上传到了HDFS,所以这里,我不需要再一次单独上传。直接载入数据

创建明细表ods_weblog_detail

创建临时中间表t_ods_tmp_referurl,解析客户端来源地址字段

创建临时中间表t_ods_tmp_detail,解析时间字段

修改默认动态分区参数
![]()
向ods_weblog_detail表中加载数据
将两张临时表的相关字段数据查询并保存到明细表中

在HDFS上查看
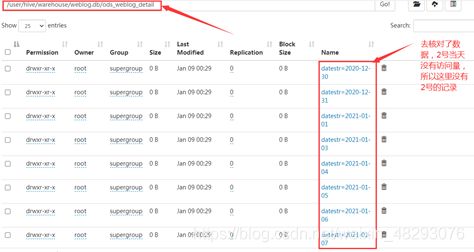
数据分析
流量分析
首先创建表结构

提取‘day’字段
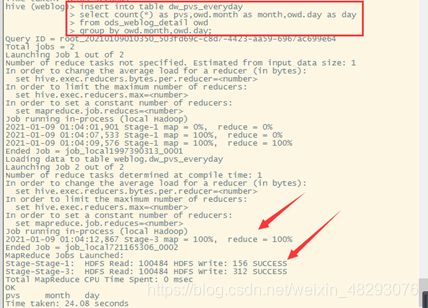
查看表数据
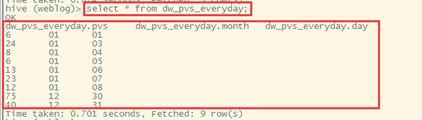
人均浏览量分析
人均浏览量指标反映了网站对用户的黏性程度,方法是通过总页面请求数量除以去重人数得出。
创建维度表dw_avgpv_user_everyday

从ods_weblog_detail表获取相关数据插入dw_avgpv_user_everyday表中

更换日期分别计算,查看结果

sqoop数据导出
主要运用Sqoop将Hive表中的数据导入到MySQL数据库中
安装Sqoop并配置
下载好sqoop的压缩包,导入

配置环境变量
![]()

修改配置文件


打开dfs和yarn集群之后测试:
bin/sqoop list-databases -connect jdbc:mysql://localhost:3306 --username root --password 123456

说明Sqoop操作是成功的,前期准备完成
将数据导入MySQL
在MySQL下建库建表
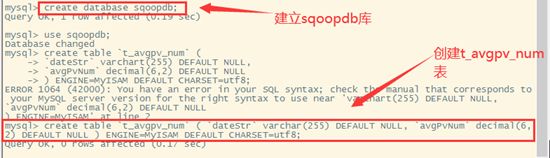
导出数据,在sqoop下输入导出命令
bin/sqoop export --connect jdbc:mysql://maker:3306/sqoopdb --username root --password Root123! --table t_avgpv_num --export-dir /user/hive/warehouse/weblog.db/dw_avgpv_user_everyday --input-fields-terminated-by '\001' --columns "dateStr,avgPvNum" --bindir ./

日志分析系统报表展示
如果你用的是idea的企业版,恭喜你,你会省去很多步骤
参考教程https://blog.csdn.net/shaock2018/article/details/86706101
本人使用是idea的社区版,很多方面受限制,比较麻烦,参考教程
https://blog.csdn.net/qq_42881421/article/details/108240531?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-2&spm=1001.2101.3001.4242
这个真的很好,至少本人受益很多,教程很详细,关于这一部分,本人也是参照这个教程写的所以,在这里不再描述
最终结果展示

保持热爱 奔赴山海