机器学习算法
机器学习算法
-
- 介绍
- Logistics Regression
- SVM
- Softmax回归
- K-Means
- KNN
- Decision Tree
- GBDT
- XGBoost
- 集成学习
-
- Boosting
- Bagging
- 多分类、多标签的分类
-
- 单标签二分类
- 单标签多分类
- 多标签多分类
- 机器学习误区
-
- 数据问题
- 数据泄露
- 建模问题
介绍
本篇博客主要介绍基础的机器学习的算法以及误区。如果有什么错误之处,欢迎大家批评指正。
Logistics Regression
在介绍逻辑回归之前,先看看极大似然估计,详情可参考这一篇文章:一文搞懂极大似然估计。我对极大似然估计的理解是通过样本去反推拟合函数的参数。换句话来说,极大似然提供了一种给定观察数据来评估模型参数的方法。极大似然中采样需要满意一个重要假设,就是所有的采样都独立同分布的。
参数估计有两种方式,一种是最大似然估计(Maximum likelihood estimation,简称MLE)和最大后验概率估计(Maximum a posteriori estimation,简称MAP)。概率是已知模型和参数,推理数据。统计是已知数据,推断模型和参数。详情参考:详解最大似然估计(MLE)、最大后验概率估计(MAP),以及贝叶斯公式的理解。
通过学习上述两个参考链接,我对深度学习的理解是:如果已知数据,求参数的函数就是似然函数;如果已知参数,求数据的过程就是概率函数。在模型训练阶段,其实是一个统计的过程,通过批量的数据去统计模型的参数。在推理阶段其实是一个概率的过程,通过模型去预测该事件发生的概率。
逻辑回归 logistics regression 公式推导
sklearn: Logistic-Regression
from sklearn.linear_model import LogisticRegression as LR
from sklearn.datasets import load_breast_cancer
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = load_breast_cancer()
X = data.data
y = data.target
# 实例化LR模型
lr1 = LR(penalty='l1', solver='liblinear', C=0.5, max_iter=1000)
lr2 = LR(penalty='l2', solver='liblinear', C=0.5, max_iter=1000)
# 逻辑回归的重要属性
lr1 = lr1.fit(X, y)
lr2=lr2.fit(X,y)
SVM
SVM算法的话这里就不多做介绍,可以参考支持向量机原理篇,机器学习支持向量机但是最好的是参考下李航的《统计学习方法》。另外我在油管上看一位博士讲的SVM原理推导过程也是挺不错的。
import numpy as np
from sklearn import datasets
from sklearn.datasets import load_iris
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
# 加载iris数据集
iris = datasets.load_iris()
X = iris['data']
y = iris["target"]
svm_clf = Pipeline(( ("scaler", StandardScaler()),
("linear_svc", LinearSVC(C=1, loss="hinge")) ,))
svm_clf.fit( X, y )
res = svm_clf.predict([[4.9, 3. , 1.4, 0.3], [5.9, 3. , 5.1, 1.8], [6.9, 3.2, 5.7, 2.3]])
print(res)
Softmax回归
softmac+交叉熵
首先看一下softmax函数的定义:

softmax有以下的特点:函数值在0到1的区间;所有值的和为1。softmax主要计算每个类别出现的概率。
然后再看看一些关于信息论里面的东西。信息熵表示的是一个信息混乱程度,也可以表示一个事件的信息量的多少。信息熵公式的定义:

从信息熵我们可以引出一个KL散度。KL散度是衡量两个分布p和q之间的差异,但是p相对q的差异与q相对p的差异并不一样,换言之不是一个对称量。p往往表示样本的真实分布,q表示模型所预测的分布。我的论文里面也引用过KL散度作为模型的误差分析。KL散度的公式如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-137GGOfV-1631969558984)(https://www.zhihu.com/equation?tex=%5Cbegin%7Baligned%7D+KL+%28p+%7C%7C+q%29+%26%3D±+%5Cint+p%28x%29+%5Cln+q%28x%29+d+x±+%28-%5Cint+p%28x%29+%5Cln+p%28x%29+dx%29+%5C%5C+%26%3D±+%5Cint+p%28x%29+%5Cln+%5B%5Cfrac%7Bq%28x%29%7D%7Bp%28x%29%7D%5D+dx+%5Cend%7Baligned%7D)]
相对熵公式前半部分是信息熵公式,对相对熵公式进行变形得出交叉熵公式:
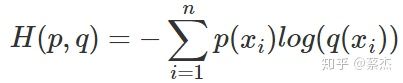
最后我们再来看看softmax加交叉熵的求导:softmax+交叉熵求导过程
K-Means
Kmeans算法在这篇专栏中讲的很详细:【机器学习】K-means。
首先Kmeans是一个聚类算法,可以用于统计数据的分布情况,降维等。在yolov3的anchor box选择中,可以使用kmeans对样本的标记框进行聚类,从而得到较好的anchor box。YOLOv3使用笔记——Kmeans聚类计算anchor boxes。然后kemans中的K是一个超参数,因此对于K值得选取非常重要。Kmeans算法在处理大数据的时候能够保证较好的伸缩性,对样本的异常值较为敏感。最后Kmeans算法的大致流程是:1. 选择初始化K个样本作为聚类中心;2. 计算其他样本对每个聚类中心的距离,选择最小聚类距离作为分类。3. 对于每个类别,重新计算它的聚类中心。4. 重复操作,直到达到某个中止条件。
from numpy import *
import time
import matplotlib.pyplot as plt
# calculate Euclidean distance
def euclDistance(vector1, vector2):
return sqrt(sum(power(vector2 - vector1, 2)))
# init centroids with random samples
def initCentroids(dataSet, k):
numSamples, dim = dataSet.shape
centroids = zeros((k, dim))
for i in range(k):
index = int(random.uniform(0, numSamples))
centroids[i, :] = dataSet[index, :]
return centroids
# k-means cluster
def kmeans(dataSet, k):
numSamples = dataSet.shape[0]
# first column stores which cluster this sample belongs to,
# second column stores the error between this sample and its centroid
clusterAssment = mat(zeros((numSamples, 2)))
clusterChanged = True
## step 1: init centroids
centroids = initCentroids(dataSet, k)
while clusterChanged:
clusterChanged = False
## for each sample
for i in xrange(numSamples):
minDist = 100000.0
minIndex = 0
## for each centroid
## step 2: find the centroid who is closest
for j in range(k):
distance = euclDistance(centroids[j, :], dataSet[i, :])
if distance < minDist:
minDist = distance
minIndex = j
## step 3: update its cluster
if clusterAssment[i, 0] != minIndex:
clusterChanged = True
clusterAssment[i, :] = minIndex, minDist**2
## step 4: update centroids
for j in range(k):
pointsInCluster = dataSet[nonzero(clusterAssment[:, 0].A == j)[0]]
centroids[j, :] = mean(pointsInCluster, axis = 0)
print 'Congratulations, cluster complete!'
return centroids, clusterAssment
# show your cluster only available with 2-D data
def showCluster(dataSet, k, centroids, clusterAssment):
numSamples, dim = dataSet.shape
if dim != 2:
print "Sorry! I can not draw because the dimension of your data is not 2!"
return 1
mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', ', 'pr']
if k > len(mark):
print "Sorry! Your k is too large! please contact Zouxy"
return 1
# draw all samples
for i in xrange(numSamples):
markIndex = int(clusterAssment[i, 0])
plt.plot(dataSet[i, 0], dataSet[i, 1], mark[markIndex])
mark = ['Dr', 'Db', 'Dg', 'Dk', '^b', '+b', 'sb', 'db', ', 'pb']
# draw the centroids
for i in range(k):
plt.plot(centroids[i, 0], centroids[i, 1], mark[i], markersize = 12)
plt.show()
KNN
K近邻算法的原理是以所有已知样本作为参照,计算未知样本与所有已知样本的距离,从中选取与未知样本距离最近的K个已知样本,根据少数服从多数的原则,将未知样本与K个最邻近样本中所属类别占比较多的归为一类。KNN算法并不需要进行训练,然后预测,直接进行硬算,然后得出结果。超参数只有一个那就是K,一般都是不选择类别的整数倍。K值选择太大会引起欠拟合,太小会过拟合,需要进行交叉验证确定K的值。
# K近邻算法:https://blog.csdn.net/pengjunlee/article/details/82713047
import numpy as np
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressor
from sklearn.model_selection import train_test_split
from sklearn.datasets._samples_generator import make_regression
# 生成数据集
data = make_blobs(n_samples=200, n_features=2, centers=2, cluster_std=1.0, random_state=8)
X,Y =data
clf = KNeighborsClassifier()
clf.fit(X, Y)
x_min, x_max = X[:,0].min()-1, X[:, 0].max()+1
y_min, y_max = X[:,1].min()-1, X[:, 1].max()+1
xx,yy=np.meshgrid(np.arange(x_min,x_max,.02),np.arange(y_min,y_max,.02))
z=clf.predict(np.c_[xx.ravel(),yy.ravel()])
z=z.reshape(xx.shape)
plt.pcolormesh(xx,yy,z,cmap=plt.cm.Pastel1)
plt.scatter(X[:,0], X[:,1],s=80, c=Y, cmap=plt.cm.spring, edgecolors='k')
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("Classifier:KNN")
# 把待分类的数据点用五星表示出来
plt.scatter(6.75,4.82,marker='*',c='red',s=200)
# 对待分类的数据点的分类进行判断
res = clf.predict([[6.75,4.82]])
plt.text(6.9,4.5,'Classification flag: '+str(res))
plt.show()
# 回归分析
X,Y=make_regression(n_samples=100,n_features=1,n_informative=1,noise=50,random_state=8)
reg = KNeighborsRegressor(n_neighbors=5)
reg.fit(X,Y)
# 将预测结果用图像进行可视化
z = np.linspace(-3,3,200).reshape(-1,1)
plt.scatter(X,Y,c='orange',edgecolor='k')
plt.plot(z,reg.predict(z),c='k',Linewidth=3)
plt.title("KNN Regressor")
plt.show()
Decision Tree
决策树算法中,ID3和C4.5算法就不说了,在本科的时候毕业设计就做了一个C4.5的算法实现。然后在答辩的时候院长问了一个问题,我回他说:“不是,你先听我说”当时觉得有点不尊重。ID3算法的节点分裂标准是信息熵,信息熵描述的是内容的的不确定性。对于一些确定性的信息,它的信息熵很低。例如“一年有12个月”,对于这条信息已经是确定了,因此它的信息量很低,对应的信息熵很低。对于“明天可能会下雨”,这个信息的不确定较前一个信息较大,因此这个信息量较前面的高。当时做C4.5的时候有个地方还没做好的是没有进行模型的剪枝。
除了ID3和C4.5算法之外还有CART算法,现在打算简单的聊聊CART算法。先放上博客参考:CART分类树算法。由于ID3和C4.5在特征选择过程中涉及到信息熵的计算,大量的信息熵计算意味着大量的对数计算。于是为了简化模型运算的同时,不完全丢失熵模型的有点,CART算法使用基尼系数来替代信息增益比。基尼系数代表了模型的不纯度,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。
决策树算法的缺点是容易过拟合,换言之就是泛化能力较弱,可以通过设置节点最小样本数量和树的深度进行推进。很多一些集成算法都用树模型进行集成。寻找最优决策树是一个NP难的问题,一般通过启发式方法容易陷入局部最优,可通过集成学习之类的方法来改善。
sklearn上面也有一些决策树的算法,这边暂时就先不放这个代码了。
GBDT
GBDT称为梯度提升树,使用的决策树是CART,因为主要解决的是连续值的问题。GBDT主要是通过加法模型(即基函数的线性组合),通过训练不断减少训练残差。贴上GBDT的原理参考:机器学习-一文理解GBDT的原理,偏差方差的讲解,GBDT算法原理以及实例理解,机器学习算法GBDT(主要参考),GBDT算法。
GBDT通过多轮迭代,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。对弱分类器的要求一般是足够简单,并且是低方差和高偏差。弱分类器一般会选择CART,通过加法模型,最终的预测结果是每轮训练的到的弱分类器加权求和得到的。GBDT的弱分类器默认选择的是CART TREE,但是也可以选择其他弱分类器,选择的前提是低方差和高偏差,服从boosting框架即可。

XGBoost
XGBoost原理
通俗理解Kaggle比赛大杀器XGBoost
集成学习
集成学习指的是构建多个分类器(弱分类器)对数据集进行预测,然后用某种策略将多个分类器预测的结果集成起来,作为最终的预测结果。
Boosting
各个分类器之间有依赖关系,必须串行,比如Adaboost、GBDT、XGBoost。以Adaboost为例,首先初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N。然后训练弱分类器。如果某个样本点已经被准确分类了,那么在构造下一个训练集中,它的权值就会被降低;相反样本点的权值会提高。权值更新后训练下一个分类器,以此类推。最后将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器权重,使得该分类器在最终分类器中起到较大的作用。相反亦然。GBDT的话是拟合上一个残差。
Bagging
各分类器之间没有依赖关系,可各自并行,比如随机森林。
多分类、多标签的分类
上图是截图python深度学习一书里面的内容。关于一些多标签多分类的内容,本人也混淆相关的概念,没能好好理解多标签,多分类各自代表什么意思。现在根据一些理解做出相关的笔记。(以图像为例)多分类即multiclass,多标签即multilabel。关于binary_crossentropy和categorical_crossentropy的相关知识可以参考:binary_crossentropy和categorical_crossentropy的相关知识,keras中两种交叉熵损失函数的探讨
单标签二分类
很简单的分类问题,例如图像中只包含猫和狗,只需要预测一个标签,并且这个标签取值只有两类。
单标签多分类
单标签多分类任务重需要预测一个标签,但是这个标签的取值有多类。
多标签多分类
多标签多分类任务需要图像里面多个标签并且每个标签取值有多类。multi-label由于假设每个标签的输出是相互独立的,因此常用配置是sigmoid+BCE,其中每个类别输出对应一个sigmoid。这种任务场景下CE将难以收敛。关于多标签多分类的tricks,可以参考:Bags of Tricks for Multi-Label Classification,对应的翻译版:https://mp.weixin.qq.com/s/bKcTp1b8bzAnvvHsOp_5IQ。不过我觉得写得也不是特别好。
- categorical_crossentropy

- binary_crossentropy

机器学习误区
数据问题
如果不仔细验证数据,你可能会错过有用的特征。英国统计学家弗朗西斯·安斯科姆因《安斯科姆四重奏》而闻名,该四重奏是四个数据集的一个例子,它们具有几乎相同的描述性统计均值、方差、相关性、回归线、R平方,但有非常不同的分布如果你以不恰当的方式选择数据,也很容易欺骗自己。例如,如果你选择因变量的值,你可能会得到一个关于自变量和因变量之间真实关系的误导性估计。
对应解决方案:
- 使用探索性数据分析(EDA)技术,包括非图形(如均值、方差、最小值、最大值和相关矩阵)和图形(如散点图、直方图、热图和降维)。
- 仔细检查数据错误、丢失的数据、总是相同值的字段、重复的实例、不平衡的数据、抽样偏差、因变量的选择以及容易博弈的数据。
- 验证字段是否包含您希望它们包含的数据。检查数据是否代表模型将在生产中看到的数据。对于分类问题,确保在每个分割中有足够的类实例。
- 与数据创建者和所有者交谈,以更好地理解数据。
数据泄露
当训练数据集包含在预测时无法得到的信息或线索时就会发生数据泄漏,数据泄漏会导致模型性能变差。
解决方案:
-
作为一个一般的经验法则,如果你的结果非常好即各种指标超过90%,你可以怀疑是否数据泄漏。
-
在最开始的时候,将您的数据分成项目中需要的数据集:训练、验证、开发、测试、盲法、折叠等等。在数据准备之前分解数据,包括值的归一化、缺失值的归一化、移除异常值、降维和特征选择,留出几个测试数据集用于最终评估。
-
当使用k折交叉验证时,在每个折中分别进行数据准备。
-
通过特征重要性的度量来识别可能泄漏的特征,例如特征与因变量的相关性(信息性)、回归特征权重、R平方和排列特征重要性(变换特征值后性能下降)。
-
查找数据中的重复,并查找在多个分割中出现的相同实例。
-
仔细查看每个数据元素的属性。
-
确定数据元素可用的顺序,只使用过去的信息进行预测。
-
从自变量集中删除泄漏特性。与数据提供者合作改进数据文档,减少数据泄漏。
建模问题
- 如何验证模型:
- 考虑使用可视化技术,如热图、高亮显示、聚类、t分布随机邻居嵌入(t-SNE)、均匀流形近似和投影(UMAP)以及嵌入投影仪。
- 对于回归模型,看权重。
- 对于决策树,看分割。
- 对于神经网络,使用神经网络可视化技术,如激活图集、特征可视化。
- 使用可解释的人工智能工具,例如,深色对应注意力权重的线条可以帮助理解Transformer模型。
- 执行debug分析,看模型失败的原因。
- 以交互方式运行模型,尝试新的输入并查看输出,试着不寻常的输入打破这种模式。
- 使用各种指标评估您的模型,查看数据子集的指标(例如,在意图级别)。
- 研究为什么某些功能有用或没用,这会让你发现更多的问题。