初入神经网络剪枝量化5(大白话)
最近看了很多篇关于剪枝的文章,今天在这里简单介绍一下每一篇的思想。
①PRUNING FILTERS FOR EFFICIENT CONVNETS: https://arxiv.org/pdf/1608.08710.pdf 这篇论文之前也说过,在我看来就是非常经典的,非常传统的一篇剪枝的论文。
核心思想就是首先计算卷积核的绝对值和即 ∑|Fi,j| , (L1范数),选择前m个最小的绝对值删除, 认为权重的绝对值越小,则权重的作用也就越小。
②Pruning Convolutional Neural Networks for Resource Efficient Inference: https://arxiv.org/abs/1611.06440
这篇论文,数学好的感兴趣的可以看看。
核心思想是利用一阶泰勒公式展开,来逼近由于修剪网络参数引起的损失函数的变化。也就是用泰勒公式来逼近这个∆C(hi)
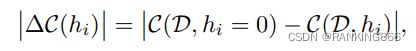
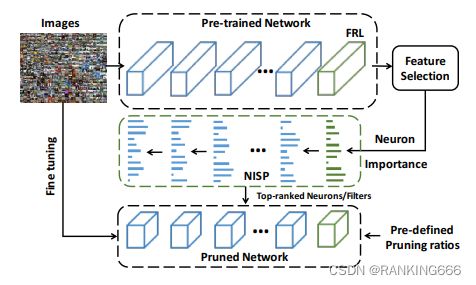
③NISP: Pruning Networks using Neuron Importance Score Propagation:https://arxiv.org/abs/1711.05908
这篇论文首先提出,现有的方法只考虑单个层或两个连续层的统计量(比如说,剪枝一层以最小化下一层的重建误差),而忽略了深层网络中误差传播的影响,这种剪枝的方法只看局部,不看整体。所以作者认为,必须根据一个统一的目标,联合修剪整个神经元网络中的神经元。
本文的核心思想就是重要性分数传播(NISP)算法,将最终响应的重要分数传播到网络中的每个神经元指导剪枝。也就是在分类器的前一层(模型的倒数第二层),Inf-FS的滤波方法有效地计算了一个特征相对于所有其他特征的重要性,从而得到了最终响应层的神经元重要性。
再利用作者提出的传播算法,将重要性分数逐层反推回去,得到整个网络所有层的重要性分数,再根据所得到的分数以及预先设定的每一层的剪枝率对原有的模型进行剪枝,得到剪枝后的模型,再送入数据对于模型进行微调。
④ Neuron-level Structured Pruning using Polarization Regularizer:
作者自己介绍论文的视频: Neuron-level Structured Pruning using Polarization Regularizer - AI学习 - 阿里云天池 (aliyun.com) 本论文的核心思想就在于,在以往的工作中,对神经元的尺度因子施加L1正则化,对尺度因子低于一定阈值的神经元进行剪枝来实现的。但是L1正则化是对所有的神经元施加惩罚项,对于所有的神经元均推向0,然后通过人为设定一定的阈值来裁剪。
但这是有问题的,作者认为我们不应该将所有的神经元推向0,而是将重要的推向1,将不重要的神经元推向0,为了实现这一目标,作者提出了一种新的比例因子正则化,即极化正则化,极化正则化将一些比例因子推至0,将其他比例因子推至a > 0。实验表明,使用极化正则化的结构化剪枝比使用L1正则化的剪枝获得更好的结果。

⑤Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures :http://cn.arxiv.org/abs/1607.03250
本文的核心思想就是介绍了一种新的评价参数是否需要被裁剪的标准:AP0Z
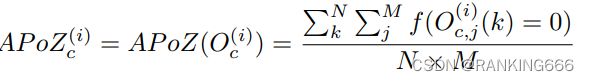
也就是统计每一个核中像素点为0的比例,通过这个比例还判断哪些核不重要,哪些层的冗余比较多。
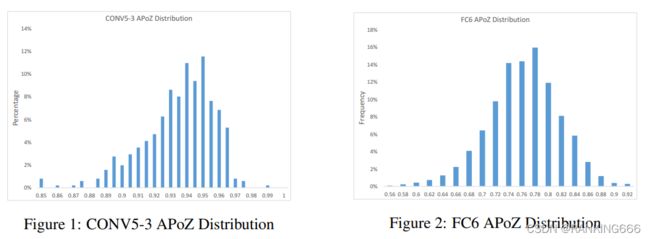
可以看到,通道越多,冗余越大。
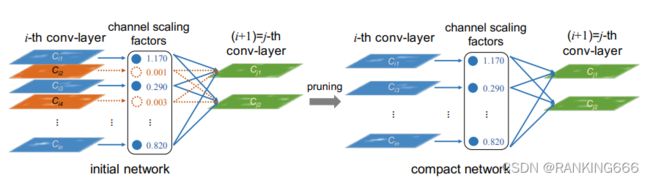
⑥Learning Efficient Convolutional Networks through Network Slimming:[1708.06519] Learning Efficient Convolutional Networks through Network Slimming (arxiv.org)
经典中的经典,我之前也说过,就是对BN层中的γ缩放因子添加L1正则化惩罚项,来稀疏训练,再按值的大小排序,然后按照裁剪比例裁剪。
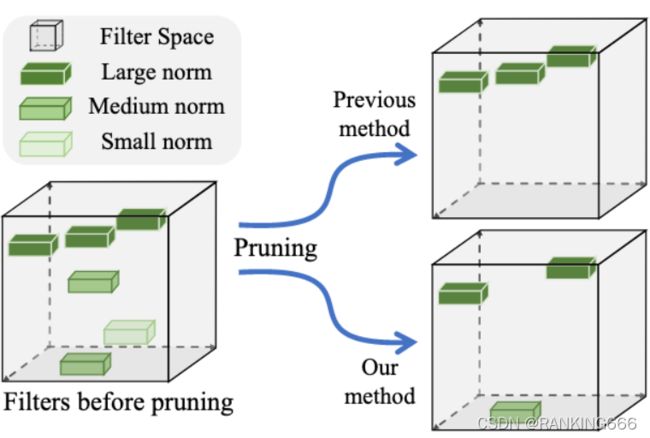
⑦ Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration:https://arxiv.org/pdf/1811.00250.pdf
这篇论文指出了基于范数裁剪方式的弊端,他必须有两个先决条件:1)权重的标准差足够大 2)权重的最小的范数应该趋近于0。然而这两个条件并不能保证总是满足,为了解决这个问题文章提出了一种基于几何中心的裁剪方式,认为靠近几何中心的卷积核在划水,因此可以裁减掉这些冗余的卷积核。
⑧Soft Filter Pruning for Accelerating Deep Convolutional Neural Networks:https://arxiv.org/pdf/1808.06866.pdf
这篇论文与上一篇的作者是同一个,因此整体思路都差不多。
首先就是提出了软剪枝的思想,相对于硬剪枝直接裁剪掉认为不重要的通道来说,软剪枝是在训练的过程中对要裁剪的通道乘以一个mask,但是在下一个epoch仍然参与运算,仍然可以反向更新梯度。
算法整体流程为,每次训完一个epoch就要开始执行剪枝操作。在每次剪枝操作时,遍历网络的每一层,计算每一层的每个滤波器的L2-norm(L2范数),剪枝概率Pi和第i层的滤波器数量Ni+1相乘表示一个网络层中被剪枝的滤波器个数,将滤波器的L2范数最低的Ni+1*Pi个滤波器剪枝,剪枝是通过将该滤波器的值置为0来实现,从而完成第i层滤波器的剪枝操作。

⑨Asymptotic Soft Filter Pruning for Deep Convolutional Neural Networks:1808.07471v4.pdf (arxiv.org)
与上篇论文也为同一作者,思想基本相同,就是在上文的方法中增加了,渐进的对滤波器进行修剪,以进行后续的训练,使得剪枝变得更加稳定。

⑩EagleEye: Fast Sub-net Evaluation for Efficient Neural Network Pruning :[2007.02491] EagleEye: Fast Sub-net Evaluation for Efficient Neural Network Pruning (arxiv.org)
这篇论文之前也讲过,就是说最好的剪枝方法,还是将每一种剪枝后的结果都计算出来,逐一对比效果,但这样的时间代价太大,根本无法实施。
本文通过观察剪枝后与微调后的参数,微调过后的权重也就是相当于做一个简单的移动。因此本文认为只需微调bn层的参数即可对比出不同剪枝后的模型效果。
这就是论文的创新之处。论文提出的思路是将网络中的其他参数冻住,然后利用训练集的样本进行前向计算,修正“继承”来的BN层参数。最终实现将微调后的模型与剪枝后的模型形成正相关。
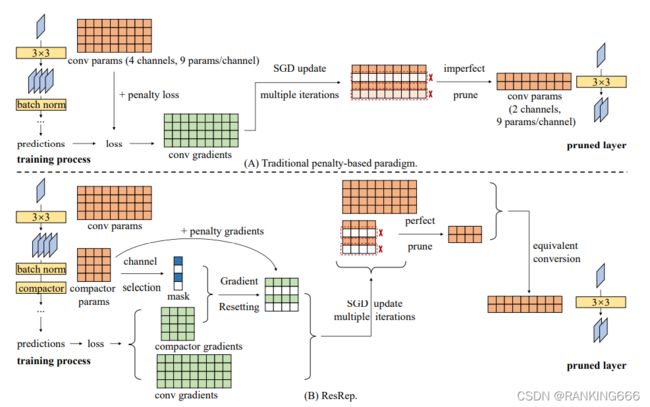
11、ResRep: Lossless CNN Pruning via Decoupling Remembering and Forgetting:2007.03260.pdf (arxiv.org)
推荐看一下作者本人在知乎上的介绍:ResRep:剪枝SOTA!用结构重参数化实现CNN无损压缩(ICCV) - 知乎 (zhihu.com)
这篇文章提出将记忆与遗忘解耦,也就是说一部分的神经元负责记忆,而专门的一部分的神经元负责遗忘。主要的思路就是,在每一个通道后添加一个compactor模块,负责遗忘。
主要的点有两个,一个是res一个是rep,res的话就是一种魔改SGD更新规则, rep就是重参化的技巧。主要就是添加compactor模块负责遗忘的模块,通过在损失函数中添加对于compactor的惩罚项使得不改动原有模型参数的情况下,来达到遗忘的效果。最后再使用重参化的技巧将compactor融进卷积的操作中去,来不减少推理过程中的计算负担。
12、MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning:https://arxiv.org/pdf/1903.10258.pdf
本篇论文之前也讲过,将元学习引入到了剪枝当中,本文的核心思想就是建立一个 PruningNet的meta network来为特定结构的网络产生权重。然后通过进化算法得出最优的剪枝结构,再送到PruningNet中生成模型权重。

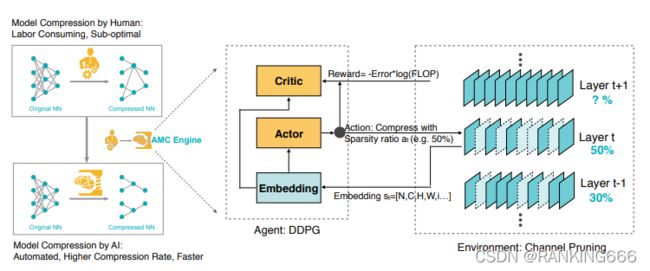
13、AMC: AutoML for Model Compression and Acceleration on Mobile Devices:
本篇论文的核心思想就是使用强化学习技术来实现自动化压缩模型,来解决人工压缩模型的弊端。采用强化学习中的DDPG(深度确定性策略梯度法)来产生连续空间上的具体压缩比率,通过约束FLOPs和准确率设定奖励值,因此得到的压缩策略是适应当前硬件环境的。agent的动作就是剪枝率,剪枝的结果,比如精度,FLOPs 等作为奖励,来训练。
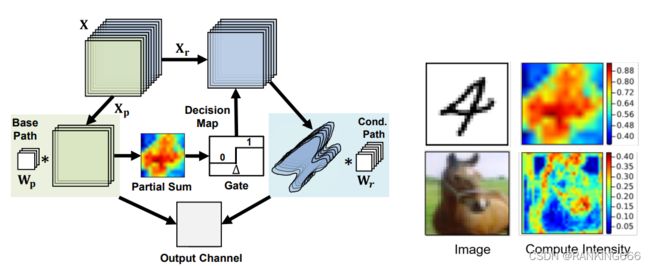
14、 Channel Gating Neural Networks:[1805.12549] Channel Gating Neural Networks (arxiv.org)
本文主要是从动态神经网络中获得启发,实现的动态剪枝的方法。
核心思想 就是将输入分为base path 和 conditional path,base path实现正常的卷积操作。作者这里证明了部分通道的激活输出与整体通道的激活输出是正相关的,因此可以通过部分通道的激活输出判断,是否剩下的conditional path还有计算的必要,计算流程如下图。
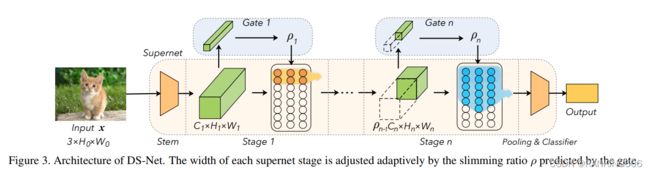
15、Dynamic Slimmable Network:https://arxiv.org/pdf/2103.13258.pdf
这篇论文的核心在于,传统的动态剪枝算法,由于构造了稀疏矩阵,以及权重的复制等,并不能在硬件上达到良好的加速效果,本文设计了动态可切分(slice-able )卷积。同样是通过过滤通道来实现瘦身,但它训练后形成的是密集通道而不是离散的,因此可直接使用切片操作。
如有错误,欢迎各位批评指正!!