(五)联邦学习、FATE、DSL学习记录
一、联邦学习
背景:人工智能的危机
在大多数行业中,数据以孤岛的形式存在。
如何在满足用户隐私保护、数据安全和政府法规的前提下,进行跨组织的数据合作。
什么是联邦学习
举例来说,假设有两个不同的企业 A 和 B,它们拥有不同数据。比如,企业 A 有用户特征数据;企业 B 有产品特征数据和标注数据。这两个企业按照上述 GDPR准则是不能粗暴地把双方数据加以合并的,因为数据的原始提供者,即他们各自的用户并没有机会来同意这样做。假设双方各自建立一个任务模型,每个任务可以是分类或预测,而这些任务也已经在获得数据时有各自用户的认可。那现在的问题是如何在 A 和 B 各端建立高质量的模型。但是,由于数据不完整(例如企业 A 缺少标签数据,企业 B 缺少特征数据),或者数据不充分 (数据量不足以建立好的模型),那么,在各端的模型有可能无法建立或效果并不理想。
联邦学习是要解决这个问题:它希望做到各个企业的自有数据不出本地,而后联邦系统可以通过加密机制下的参数交换方式,即在不违反数据隐私法规情况下,建立一个虚拟的共有模型。这个虚拟模型就好像大家把数据聚合在一起建立的最优模型一样。但是在建立虚拟模型的时候,数据本身不移动,也不泄露隐私和影响数据合规。这样,建好的模型在各自的区域仅为本地的目标服务。在这样一个联邦机制下,各个参与者的身份和地位相同,而联邦系统帮助大家建立了“共同富裕”的策略。这就是为什么这个体系叫做“联邦学习”。
联邦学习定义
当多个数据拥有方(例如企业)F_i, i=1…N 想要联合他们各自的数据 D_i 训练机器学习模型时,传统做法是把数据整合到一方并利用数据 D={Di,i=1…N}进行训练并得到模型M_sum。然而,该方案由于其涉及到的隐私和数据安全等法律问题通常难以实施。
为解决这一问题,我们提出联邦学习。联邦学习是指使得这些数据拥有方 F_i 在不用给出己方数据D_i 的情况下也可进行模型训练并得到模型 M_FED 的计算过程,并能够保证模型 M_FED 的效果 V_FED 与模型 M_SUM 的效果 V_SUM 间的差距足够小,即:
|V_FED-V_SUM |<δ, 这里 δ 是任意小的一个正量值。称联邦学习算法有δ精度损失。
联邦学习特点
- 数据隔离:联邦学习的整套机制在合作过程中,数据不会传递到外部。
- 无损:通过联邦学习分散建模的效果和把数据合在一起建模的效果对比,几乎是无损的。
- 对等:合作过程中,合作双方是对等的,不存在一方主导另外一方。
- 共同获益:无论数据源方,还是数据应用方,都能获取相应的价值。
联邦学习分类
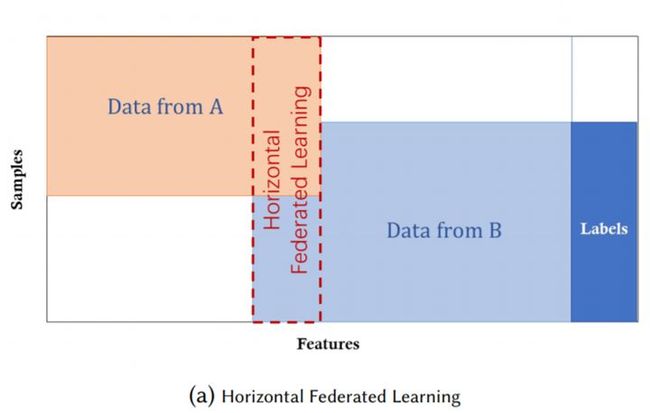
横向联邦学习
两个数据集的用户特征 ( X1, X2, … ) 重叠部分较大,而用户 ( U1, U2, … ) 重叠部分较小
又叫基于样本的联邦学习,用于有相同特征空间,不同样本空间的数据集场景。例如两个区域银行的用户样本可能差别很大,但是这两家银行的业务是相近的,所以用户样本的特征空间是相同的。
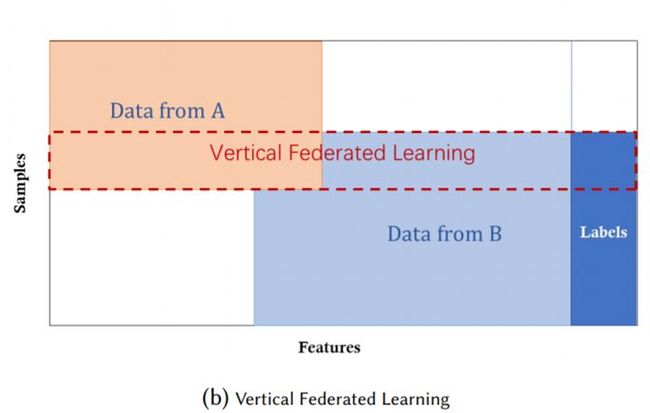
纵向联邦学习
两个数据集的用户 ( U1, U2, … ) 重叠部分较大,而用户特征 ( X1, X2, … ) 重叠部分较小
又叫做基于特征的联邦学习,被应用与不同数据集共享相同的样本空间,但特征空间不同的场景。例如在同一地区的两个不同领域的公司,他们拥有相同的数据样本,但由于领域不同,他们用户样本的特征数据是不同的。
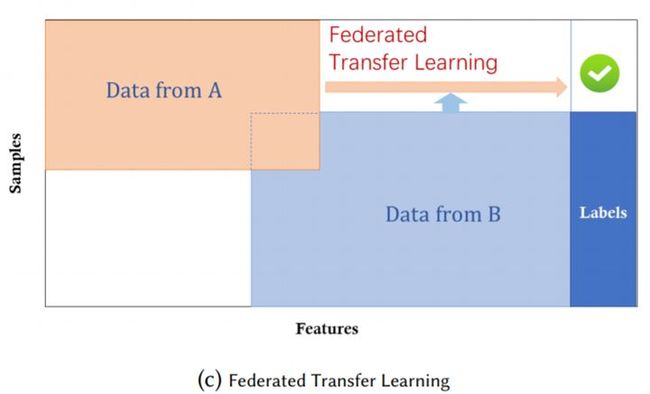
联邦迁移学习
两个数据集的用户 ( U1, U2, … ) 与用户特征重叠 ( X1, X2, … ) 部分都比较小
应用于不同数据集的样本空间和用户空间的交集都很少的场景下。例如在两个不同区域的两家不同领域的公司,它们的用户和用户的数据都极为不同,或者只有极小一部分交集。
二、FATE:
FATE官方网站:
https://fate.fedai.org/
FATE概念:
FATE (Federated AI Technology Enabler) 是微众银行AI部门发起的开源项目,为联邦学习生态系统提供了可靠的安全计算框架。
FATE项目使用多方安全计算 (MPC) 以及同态加密 (HE) 技术构建底层安全计算协议,以此支持不同种类的机器学习的安全计算,包括逻辑回归、基于树的算法、深度学习和迁移学习等。
FATE中的联邦学习算法:
FATE目前支持三种类型联邦学习算法:横向联邦学习、纵向联邦学习以及迁移联邦学习。
FATE的三种角色:
在Fate的概念中分成3种角色,Guest、Host、Arbiter:
**Guest:**数据应用方。在纵向算法中,Guest往往是有标签y的一方。一般由Guest发起建模流程。
**Host:**数据提供方
**arbiter:**用来辅助多方完成联合建模。主要的作用是用来聚合梯度或者模型,比如纵向lr里面,各方将自己一半的梯度发送给arbiter,然后arbiter再联合优化等等,arbiter还参与以及分发公私钥,进行加解密服务等等。
FATE技术框架:
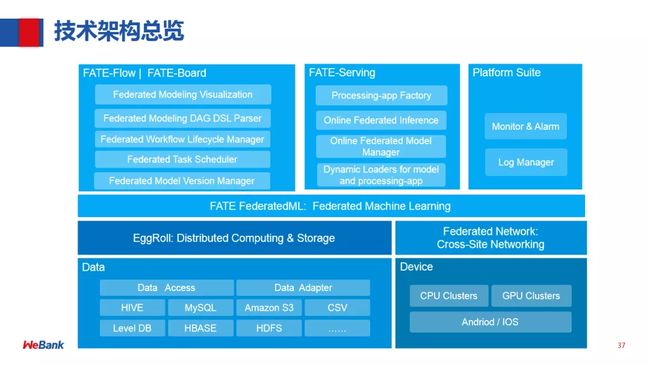
FATE主要包括:
- EggRoll:分布式计算和存储的抽象;
- Federated Network:跨域跨站点通信的抽象;
- FATE FederatedML:联邦学习算法模块,包含了目前联邦学习所有的算法功能;
- FATE-Flow | FATE-Board:完成一站式联邦建模的管理和调度以及整个过程的可视化;
- FATE-Serving:联邦学习在线推理模块。
三、dsl、conf
为了让任务模型的构建更加灵活,目前 FATE 使用了一套自定的域特定语言 (DSL:domain-specific language) 来描述任务。
在 DSL 中,各种模块(例如数据读写 data_io,特征工程 feature-engineering, 回归 regression,分类 classification)可以通向一个有向无环图 (DAG) 组织起来。通过各种方式,用户可以根据自身的需要,灵活地组合各种算法模块。
借助FATE,我们可以使用组件的方式来构建联邦学习,而不需要用户从新开始编码。
FATE构建联邦学习Pipeline是通过自定义dsl和conf两个配置文件来实现的:
dsl文件:用来描述任务模块,将任务模块以有向无环图(DAG)的形式组合在一起。
conf文件:设置各个组件的参数,比如输入模块的数据表名;算法模块的学习率、batch大小、迭代次数等。
每个模块都有不同的参数需要配置,不同的 party 对于同一个模块的参数也可能有所区别。为了简化这种情况,对于每一个模块,FATE 会将所有 party 的不同参数保存到同一个运行配置文件(Submit Runtime Conf)中,并且所有的 party 都将共用这个配置文件。