yolov5训练出现错误解决方法
本人在训练时出现的错误如下
Traceback (most recent call last):
File "train.py", line 670, in
main(opt)
File "train.py", line 565, in main
train(opt.hyp, opt, device, callbacks)
File "train.py", line 352, in train
pred = model(imgs) # forward
File "/home/lly/anaconda3/envs/pytorch/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/lly/anaconda3/envs/pytorch/yolov5/models/yolo.py", line 135, in forward
return self._forward_once(x, profile, visualize) # single-scale inference, train
File "/home/lly/anaconda3/envs/pytorch/yolov5/models/yolo.py", line 158, in _forward_once
x = m(x) # run
File "/home/lly/anaconda3/envs/pytorch/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/lly/anaconda3/envs/pytorch/yolov5/models/common.py", line 128, in forward
y1 = self.cv3(self.m(self.cv1(x)))
File "/home/lly/anaconda3/envs/pytorch/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/lly/anaconda3/envs/pytorch/lib/python3.8/site-packages/torch/nn/modules/container.py", line 141, in forward
input = module(input)
File "/home/lly/anaconda3/envs/pytorch/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/lly/anaconda3/envs/pytorch/yolov5/models/common.py", line 111, in forward
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
File "/home/lly/anaconda3/envs/pytorch/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/lly/anaconda3/envs/pytorch/yolov5/models/common.py", line 47, in forward
return self.act(self.bn(self.conv(x)))
File "/home/lly/anaconda3/envs/pytorch/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/lly/anaconda3/envs/pytorch/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 446, in forward
return self._conv_forward(input, self.weight, self.bias)
File "/home/lly/anaconda3/envs/pytorch/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 442, in _conv_forward
return F.conv2d(input, weight, bias, self.stride,
RuntimeError: Unable to find a valid cuDNN algorithm to run convolution
wandb: Waiting for W&B process to finish... (failed 1). Press Control-C to abort syncing.
wandb:
wandb: Synced major-glitter-8: https://wandb.ai/llyue/YOLOv5/runs/1nah9k13
wandb: Synced 6 W&B file(s), 0 media file(s), 0 artifact file(s) and 0 other file(s)
wandb: Find logs at: ./wandb/run-20220617_165328-1nah9k13/logs 最后我发现是训练时batch参数设置过大导致训练出错
修改之前使用的训练代码
python train.py --img 640 --batch 8 --epochs 30 --data coco128.yaml --weights yolov5s.pt把batch参数改到8之后我发现我的训练可以正常进行了
这里最好修改的时候把batch参数修改成8的倍数,例如8,16,24
修改之后使用的代码
python train.py --img 640 --batch 8 --epochs 8 --data coco128.yaml --weights yolov5s.pt关于batch参数的理解:
一般训练主要需要调整的参数是这两个:
workers指数据装载时cpu所使用的线程数,默认为8。代码解释如下
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
一般默使用8的话,会报错~~。原因是爆系统内存,除了物理内存外,需要调整系统的虚拟内存。训练时主要看已提交哪里的实际值是否会超过最大值,超过了不是强退程序就是报错。

所以需要根据实际情况分配系统虚拟内存(python执行程序所在的盘)的最大值

第二个参数
batch-size就是一次往GPU哪里塞多少张图片了。决定了显存占用大小,默认是16
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
训练时显存占用越大当然效果越好,但如果爆显存,也是会无法训练的。
对于workers,并不是越大越好,太大时gpu其实处理不过来,训练速度一样,但虚拟内存(磁盘空间)会成倍占用。

workers为4时的内存占用
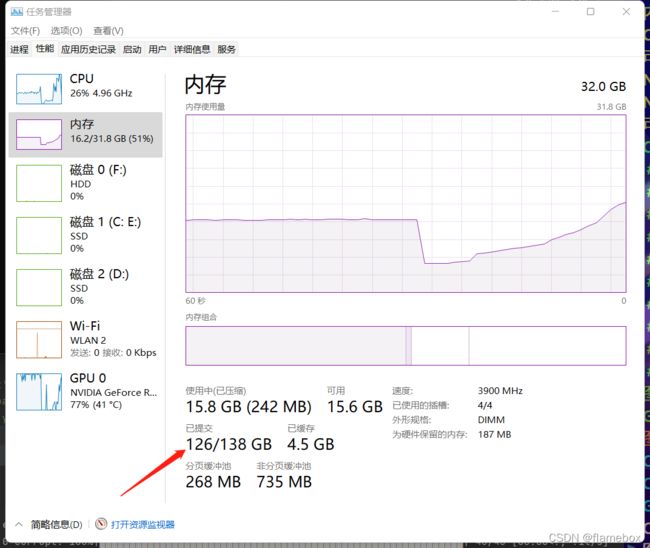
workers为8时的内存占用
我的显卡是rtx3050,实际使用中上到4以上就差别不大了,gpu完全吃满了。但是如果设置得太小,gpu会跑不满。比如当workers=1时,显卡功耗只得72W,速度慢了一半;workers=4时,显卡功耗能上到120+w,完全榨干了显卡的算力。所以需要根据你实际的算力调整这个参数。

2. 对于batch-size,有点玄学。理论是能尽量跑满显存为佳,但实际测试下来,发现当为8的倍数时效率更高一点。就是8时的训练效率会比10的高一点,这里就不太清楚原理是什么了,实际操作下来是这样。
总结以上参数的调整能最大化显卡的使用效率,其中的具体数值和电脑的实际配置还有模型大小、数据集大小有关,需要根据实际情况反复调整。当然,要实质提升训练速度,还是得有好显卡(钞能力)~~~~