生成模型VAE、GAN和基于流的模型详细对比
在Ian Goodfellow和其他研究人员在一篇论文中介绍生成对抗网络两年后,Yann LeCun称对抗训练是“过去十年里ML最有趣的想法”。尽管GANs很有趣,也很有前途,但它只是生成模型家族的一部分,是从完全不同的角度解决传统AI问题,在本文中我们将对比常见的三种生成模型。

生成算法
当我们想到机器学习时,首先想到的可能是鉴别算法。判别模型是根据输入数据的特征对其标签或类别进行预测,是所有分类和预测解决方案的核心。与这些模型相比生成算法帮助我们讲述关于数据的故事并提供数据是如何生成的可能解释,与判别算法所做的将特征映射到标签不同,生成模型试图预测给定标签的特征。
区别模型定义的标签y和特征x之间的关系,生成模型回答“你如何得到y”的问题。而生成模型模型则是P(Observation/Cause),然后使用贝叶斯定理计算P(Cause/Observation)。通过这种方式,他们可以捕获p(x|y), x给定y的概率,或者给定标签或类别的特征的概率。所以实际上,生成算法也是可以用作分类器的,这可能是因为它们对各个类的分布进行了建模。
生成算法有很多,但属于深度生成模型类别的最流行的模型是变分自动编码器(VAE)、gan和基于流的模型。
VAE
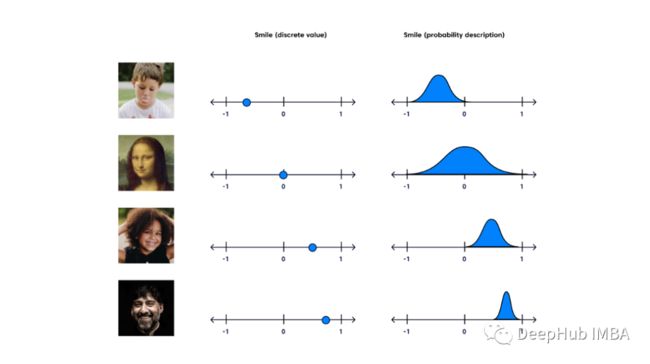
变分自编码器(VAE)是一种生成模型,它“提供潜在空间中观察结果的概率描述”。简单地说,这意味着vae将潜在属性存储为概率分布。
变分自编码器(Kingma & Welling, 2014)或VAE的思想深深植根于变分贝叶斯和图形模型方法。
标准的自动编码器包括2个相似的网络,一个编码器和一个解码器。编码器接受输入并将其转换为更小的表示形式,解码器可以使用该表示形式将其转换回原始输入。它们将输入转换到的潜在空间以及它们的编码向量所在的空间可能不是连续。这对于生成模型来说是一个问题,因为我们都希望从潜在空间中随机采样,或者从连续潜在空间中生成输入图像的变化。
而变分自编码器具有连续的潜在空间,这样可以使随机采样和插值更加方便。为了实现这一点,编码器的隐藏节点不输出编码向量,而是输出两个大小相同的向量:一个均值向量和一个标准差向量。每一个隐藏的节点都认为自己是高斯分布的。这里的均值和标准差向量的第i个元素对应第i个随机变量的均值和标准差值。我们从这个分布向量中采样,解码器从输入向量的概率分布中随机抽样。这个过程就是随机生成。这意味着即使对于相同的输入,当平均值和标准差保持不变时,实际的编码在每一次传递中都会有所不同。

自编码器的损失是最小化重构损失(输出与输入的相似程度)和潜在损失(隐藏节点与正态分布的接近程度)。潜在损失越小,可以编码的信息就越少,这样重构损失就会增加,所以在潜在损失和重建损失之间是需要进行进行权衡的。当潜在损耗较小时,生成的图像与训练的的图像会过于相似,效果较差。在重构损失小的情况下,训练时的重构图像效果较好,但生成的新图像与重构图像相差较大,所以需要找到一个好的平衡。
VAE可以处理各种类型的数据,序列的和非序列的,连续的或离散的,甚至有标签的或无标签的,这使它们成为非常强大的生成工具。
但是VAE的一个主要缺点是它们生成的输出模糊。正如Dosovitskiy和Brox所指出的,VAE模型往往产生不现实的、模糊的样本。这是由数据分布恢复和损失函数计算的方式造成的。Zhao等人在2017年的一篇论文中建议修改VAEs,不使用变分贝叶斯方法来提高输出质量。

生成对抗的网络
生成对抗网络(GANs)是一种基于深度学习的生成模型,能够生成新内容。GAN架构在2014年Ian Goodfellow等人题为“生成对抗网络”的论文中首次被描述。
GANs采用监督学习方法,使用两个子模型:生成新示例的生成器模型和试图将示例分类为真实或假(生成的)的鉴别器模型。
生成器:用于从问题域生成新的似是而非例子的模型。
鉴频器:用于将示例分类为真实的(来自领域)或假的(生成的)的模型。
这两个模型作为竞争对手进行训练。生成器直接产生样本数据。它的对手鉴别器,试图区分从训练数据中提取的样本和从生成器中提取的样本。这个竞争过程在训练中持续进行,直到鉴别器模型有一半以上的时间无法判断真假,这意味着生成器模型正在生成非常逼真的数据。

当鉴别器成功地鉴别出真假样本时,它会得到奖励它的参数保持不变。如果生成器判断错误则受到惩罚,更新其参数。在理想情况下,每当鉴别器不能分辨出差异并预测“不确定”(例如,50%的真假)时,生成器则能从输入域生成完美的副本。
但是这里每个模型都可以压倒另一个。如果鉴别器太好,它将返回非常接近0或1的值,生成器则难以获得更新的梯度。如果生成器太好,它就会利用鉴别器的弱点导致漏报。所以这两个神经网络必须具有通过各自的学习速率达到的相似的“技能水平”,这也是我们常说的GAN难以训练的原因之一。
生成器模型
生成器取一个固定长度的随机向量作为输入,在定义域内生成一个样本。这个向量是从高斯分布中随机抽取的。经过训练后,这个多维向量空间中的点将对应于问题域中的点,形成数据分布的压缩表示,这一步类似于VAE,这个向量空间被称为潜在空间,或由潜在变量组成的向量空间。GAN的生成器将平均选定的潜在空间中的点。从潜在空间中提取的新点可以作为输入提供给生成器模型,并用于生成新的和不同的输出示例。训练结束后,保留生成器模型,用于生成新的样本。
鉴别器模型
鉴别器模型将一个示例作为输入(来自训练数据集的真实样本或由生成器模型生成),并预测一个二进制类标签为real或fake(已生成)。鉴别器是一个正常的(并且很容易理解的)分类模型。
训练过程结束后,鉴别器被丢弃,因为我们感兴趣的是生成器。当然鉴别器也可用于其他目的使用
GANs可以产生可行的样本但最初版GAN也有缺点:
- 图像是由一些任意的噪声产生的。当生成具有特定特征的图片时,不能确定什么初始噪声值将生成该图片,而是需要搜索整个分布。
- GAN只区别于“真实”和“虚假”图像。但是没有约束说“猫”的照片必须看起来像“猫”。因此,它可能导致生成的图像中没有实际的对象,但样式看起来却很相似。
- GANs需要很长时间来训练。一个GAN在单个GPU上可能需要几个小时,而单个CPU可能需要一天以上的时间。
基于流的模型
基于流的生成模型是精确的对数似然模型,有易处理的采样和潜在变量推理。基于流的模型将一堆可逆变换应用于来自先验的样本,以便可以计算观察的精确对数似然。与前两种算法不同,该模型显式地学习数据分布,因此损失函数是负对数似然。

在非线性独立分量分析中,流模型f被构造为一个将高维随机变量x映射到标准高斯潜变量z=f(x)的可逆变换。流模型设计的关键思想是它可以是任意的双射函数,并且可以通过叠加各个简单的可逆变换来形成。总结来说:流模型f是由组成一系列的可逆流动作为f(x) =f1◦···◦fL(x),与每个fi有一个可处理的逆和可处理的雅可比矩阵行列式。
基于流的模型有两大类:带有标准化流模型和带有试图增强基本模型性能的自回归流的模型。
标准化流模型
对于许多机器学习问题来说,能够进行良好的密度估计是必不可少的。但是它在本质上是复杂的:当我们需要在深度学习模型中进行反向传播时,嵌入的概率分布需要足够简单,这样才可以有效地计算导数。传统的解决方案是在潜变量生成模型中使用高斯分布,尽管大多数现实世界的分布要复杂得多。标准化流(NF)模型,如RealNVP或Glow,提供了一个健壮的分布近似。他们通过应用一系列可逆变换函数将一个简单的分布转化为一个复杂的分布。通过一系列的变换,根据变量变换定理,可以反复地用新变量替换原变量,最后得到最终目标变量的概率分布。
自回归流的模型
当标准化流中的流动变换被框定为一个自回归模型,其中向量变量中的每个维度都处于先前维度的条件下,流模型的这种变化称为自回归流。与具有标准化流程的模型相比,它向前迈进了一步。
常用的自回归流模型是用于图像生成的PixelCNN和用于一维音频信号的WaveNet。它们都由一堆因果卷积组成——卷积运算考虑到顺序:在特定时间戳的预测只使用过去观察到的数据。在PixelCNN中,因果卷积由一个带掩码的积核执行。而WaveNet将输出通过几个时间戳转移到未来时间。

基于流的模型在概念上对复杂分布的建模是非常友好的,但与最先进的自回归模型相比,它受到密度估计性能问题的限制。尽管流模型最初可能会替代GANs产生良好的输出,但它们之间的训练计算成本存在显著差距,基于流的模型生成相同分辨率的图像所需时间是GANs的几倍。
总结
每一种算法在准确性和效率方面都有其优点和局限性。虽然GANs和基于流程的模型通常生成比VAE更好或更接近真实的图像,但后者比基于流程的模型更具有更快时间和更好的参数效率,下面就是三个模型的对比总结:

可以看到GAN因为并行所以它的效率很高,但它并不可逆。相反,流模型是可逆的但是效率却不高,而vae是可逆并且高效的,但不能并行计算。我们可以根据这些特性,在实际使用时根据产出、训练过程和效率之间进行权衡选择。
https://avoid.overfit.cn/post/a0d01a1c00184d559aeb426a77b163b3
作者:sciforce