(CVPR 2020) RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
Abstract
我们研究了大规模3D点云的有效语义分割问题。通过依赖昂贵的采样技术或计算量大的预处理/后处理步骤,大多数现有方法只能在小规模点云上进行训练和操作。在本文中,我们介绍了RandLA-Net,这是一种高效且轻量级的神经架构,可直接推断大规模点云的每点语义。我们方法的关键是使用随机点采样而不是更复杂的点选择方法。尽管计算和内存效率非常高,但随机抽样可能会偶然丢弃关键特征。为了克服这个问题,我们引入了一种新的局部特征聚合模块来逐步增加每个3D点的感受野,从而有效地保留几何细节。大量实验表明,我们的RandLA-Net可以一次处理100万个点,速度比现有方法快200倍。此外,我们的RandLA-Net在两个大型基准Semantic3D和SemanticKITTI上明显超越了最先进的语义分割方法。
1. Introduction
大规模3D点云的有效语义分割是实时智能系统(如自动驾驶和增强现实)的基本和必不可少的能力。一个关键挑战是深度传感器获取的原始点云通常是不规则采样、非结构化和无序的。尽管深度卷积网络在结构化2D计算机视觉任务中表现出出色的性能,但它们不能直接应用于此类非结构化数据。
最近,开创性的工作PointNet[43]已成为一种有前途的直接处理3D点云的方法。它使用共享的多层感知器(MLP)学习每点特征。这在计算上是有效的,但无法为每个点捕获更广泛的上下文信息。为了学习更丰富的局部结构,随后迅速引入了许多专用的神经模块。这些模块通常可以分类为:1)相邻特征池[44, 32, 21, 70, 69], 2)图消息传递[57, 48, 55, 56, 5, 22, 34], 3)kernel-based convolution[49, 20, 60, 29, 23, 24, 54, 38]和4)基于注意力的聚合[61, 68, 66, 42]。尽管这些方法在对象识别和语义分割方面取得了令人印象深刻的结果,但几乎所有这些方法都仅限于极小的3D点云(例如,4k点或1×1米块),不能直接扩展到更大的点云(例如,数百万点和最大200×200米),无需块划分等预处理步骤。造成这种限制的原因有三个。 1)这些网络常用的点采样方法要么计算量大,要么内存效率低。例如,广泛使用的最远点采样[44]需要200多秒才能对100万个点中的10%进行采样。2)大多数现有的局部特征学习器通常依赖计算昂贵的内核化或图构建,因此无法处理大量点。3)对于通常由数百个目标规模点云,现有的局部特征学习器要么无法捕获复杂的结构,要么效率低下,因为它们的感受野大小有限。
最近的一些工作已经开始解决直接处理大规模点云的任务。SPG[26]在应用神经网络学习每个超点语义之前将大点云预处理为超图。FCPN[45]和PCT[7]都结合体素化和点级网络来处理海量点云。尽管它们实现了不错的分割精度,但预处理和体素化步骤的计算量太大,无法部署在实时应用程序中。
在本文中,我们的目标是设计一种内存和计算效率高的神经架构,它能够在单次通过中直接处理大规模3D点云,而不需要任何预处理/后处理步骤,例如体素化、块分割或图形构造。然而,这项任务极具挑战性,因为它需要:1)一种内存和计算效率高的采样方法,以逐步对大规模点云进行下采样以适应当前GPU的限制,以及2)一种有效的局部特征学习器,以逐步增加接受能力字段大小以保留复杂的几何结构。为此,我们首先系统地证明了随机抽样是深度神经网络有效处理大规模点云的关键推动力。但是,随机采样会丢弃关键信息,尤其是对于点稀疏的目标。为了应对随机抽样的潜在不利影响,我们提出了一种新的高效局部特征聚合模块,以在逐渐变小的点集上捕获复杂的局部结构。
在现有的采样方法中,最远点采样和逆密度采样最常用于小尺度点云[44,60,33,70,15]。由于点采样是这些网络中的一个基本步骤,我们在第3.2节中研究了不同方法的相对优点,其中我们看到常用的采样方法限制了对大点云的缩放,并成为实时处理的重要瓶颈。然而,我们认为随机采样是迄今为止最适合大规模点云处理的组件,因为它速度快且可有效扩展。随机抽样并非没有成本,因为突出的点特征可能会被偶然丢弃,并且不能直接在现有网络中使用而不会导致性能损失。为了克服这个问题,我们在3.3节设计了一个新的局部特征聚合模块,它能够通过逐步增加每个神经层的感受野大小来有效地学习复杂的局部结构。特别是,对于每个3D点,我们首先引入一个局部空间编码(LocSE)单元来显式地保留局部几何结构。其次,我们利用注意力池来自动保留有用的局部特征。第三,我们将多个LocSE单元和注意力池堆叠为一个扩张的残差块,大大增加了每个点的有效感受野。请注意,所有这些神经组件都是作为共享MLP实现的,因此具有显着的内存和计算效率。
总体而言,基于简单随机抽样和有效的局部特征聚合器的原则,我们的高效神经架构RandLA-Net不仅比现有的大规模点云方法快200倍,而且超过Semantic3D[17]和SemanticKITTI[3]基准上最先进的语义分割方法。图1显示了我们方法的定性结果。我们的主要贡献是:
-
我们分析和比较现有的采样方法,将随机采样确定为最适合在大规模点云上进行有效学习的组件。
-
我们提出了一个有效的局部特征聚合模块,通过逐步增加每个点的感受野来保留复杂的局部结构。
-
我们在基线上展示了显着的内存和计算增益,并在多个大规模基准上超越了最先进的语义分割方法。
图1.PointNet++[44]、SPG[26]和我们在SemanticKITTI[3]上的方法的语义分割结果。我们的RandLA-Net在3D空间中直接处理 150 × 130 × 10 150 \times 130 \times 10 150×130×10米的 1 0 5 10^{5} 105个点的大型点云仅需0.04秒,比SPG快200倍。红色圆圈突出了我们方法的卓越分割精度。
2. Related Work
为了从3D点云中提取特征,传统方法通常依赖于手工制作的特征[11、47、25、18]。最近基于学习的方法[16, 43, 37]主要包括此处概述的基于投影、基于体素和基于点的方案。
(1) Projection and Voxel Based Networks. 为了利用2D CNN的成功,许多工作[30、8、63、27]将3D点云投影/展平到2D图像上以解决目标检测任务。但是,在投影过程中可能会丢失几何细节。或者,可以将点云体素化为3D网格,然后在[14、28、10、39、9]中应用强大的3D CNN。尽管它们在语义分割和目标检测方面取得了领先的成果,但它们的主要限制是计算成本高,尤其是在处理大规模点云时。
(2) Point Based Networks. 受PointNet/PointNet++[43, 44]的启发,许多最近的作品引入了复杂的神经模块来学习每点的局部特征。这些模块通常可以分类为1)相邻特征池[32, 21, 70, 69], 2)图消息传递[57, 48, 55, 56, 5, 22, 34, 31], 3)基于内核卷积 [49, 20, 60, 29, 23, 24, 54, 38]和4)基于注意力的聚合[61, 68, 66, 42]。尽管这些网络在小点云上显示出有希望的结果,但由于其高计算和内存成本,它们中的大多数无法直接扩展到大型场景。与它们相比,我们提出的RandLA-Net在三个方面有区别:1)它只依赖于网络内的随机采样,因此需要更少的内存和计算量; 2)所提出的局部特征聚合器可以通过明确考虑局部空间关系和点特征来获得连续更大的感受野,从而对于学习复杂的局部模式更加有效和鲁棒;3)整个网络仅由共享的MLP组成,不依赖于任何昂贵的操作,例如图构建和内核化,因此对于大规模点云非常有效。
(3) Learning for Large-scale Point Clouds. SPG[26]将大点云预处理为超点图,以学习每个超点语义。最近的FCPN[45]和PCT[7]应用基于体素和基于点的网络来处理海量点云。然而,图分割和体素化在计算上都是昂贵的。相比之下,我们的RandLA-Net是端到端可训练的,无需额外的预处理/后处理步骤。
3. RandLA-Net
3.1. Overview
如图2所示,给定一个具有数百万点跨越数百米的大规模点云,要使用深度神经网络对其进行处理,不可避免地需要在每个神经层中对这些点进行渐进有效的下采样,而不会丢失有用的点特征。在我们的RandLA-Net中,我们建议使用简单快速的随机采样方法来大大降低点密度,同时应用精心设计的局部特征聚合器来保留突出的特征。这使得整个网络在效率和有效性之间实现了极好的权衡。
图2. 在RandLA-Net的每一层中,大规模点云被显着下采样,但能够保留准确分割所需的特征。

3.2. The quest for efficient sampling
现有的点采样方法[44, 33, 15, 12, 1, 60]可以大致分为启发式和基于学习的方法。但是,仍然没有适合大规模点云的标准采样策略。因此,我们分析和比较它们的相对优点和复杂性如下。
(1) Heuristic Sampling
-
最远点采样(FPS):为了从具有 N N N个点的大规模点云 P \boldsymbol{P} P中采样 K K K个点,FPS返回度量空间 { p 1 ⋯ ⋅ p k ⋯ p K } \left\{p_{1} \cdots \cdot p_{k} \cdots p_{K}\right\} {p1⋯⋅pk⋯pK}的重新排序,使得每个 p k p_{k} pk是距离前 k − 1 k - 1 k−1个点最远的点。FPS在[44, 33, 60]中广泛用于小点集的语义分割。虽然它对整个点集有很好的覆盖,但它的计算复杂度是 O ( N 2 ) \mathcal{O}\left(N^{2}\right) O(N2)。对于大规模点云 ( N ∼ 1 0 6 ) \left(N \sim 10^{6}\right) (N∼106),FPS在单个GPU上处理最多需要200秒。这说明FPS不适用于大规模点云。
-
逆密度重要性采样(IDIS):为了从 N N N个点中采样 K K K个点,IDIS根据每个点的密度对所有 N N N个点进行重新排序,然后选择前 K K K个点[15]。其计算复杂度约为 O ( N ) \mathcal{O}(N) O(N)。根据经验,处理 1 0 6 10^{6} 106个点需要10秒。与FPS相比,IDIS效率更高,但对异常值也更敏感。但是,在实时系统中使用它仍然太慢。
-
随机抽样(RS):随机抽样从原来的 N N N个点中均匀选择 K K K个点。它的计算复杂度为 O ( 1 ) \mathcal{O}(1) O(1),与输入点的总数无关,即它是恒定时间的,因此具有固有的可扩展性。与FPS和IDIS相比,随机采样具有最高的计算效率,无论输入点云的规模如何。处理 1 0 6 10^{6} 106个点仅需0.004s。
(2) Learning-based Sampling
-
基于生成器的采样 (GS):GS[12]学习生成一小组点来近似表示原始的大点集。然而,FPS通常用于在推理阶段将生成的子集与原始集进行匹配,从而产生额外的计算。在我们的实验中,对 1 0 6 10^{6} 106个点的10%进行采样最多需要1200秒。
-
基于连续松弛的采样(CRS):CRS方法[1, 66]使用重新参数化技巧将采样操作松弛到连续域以进行端到端训练。特别是,每个采样点都是基于整个点云上的加权和来学习的。当通过一次矩阵乘法同时对所有新点进行采样时,它会导致很大的权重矩阵,从而导致无法承受的内存成本。例如,估计需要超过300 GB的内存占用来采样 1 0 6 10^{6} 106个点的10%。
图3. 提出的局部特征聚合模块。顶部面板显示了提取特征的位置空间编码块,以及基于局部上下文和几何形状对最重要的相邻特征进行加权的注意池化机制。底部面板显示了如何将这些组件中的两个链接在一起,以增加残差块内的感受野大小。

- 基于策略梯度的采样 (PGS):PGS将采样操作制定为马尔可夫决策过程[62]。它顺序学习概率分布以对点进行采样。然而,当点云很大时,由于极大的探索空间,学习概率具有很高的方差。例如,要对 1 0 6 10^{6} 106个点的10%进行采样,探索空间是 C 1 0 6 1 0 5 \mathrm{C}_{10^{6}}^{10^{5}} C106105,不太可能学习到有效的采样策略。我们凭经验发现,如果PGS 用于大型点云,网络很难收敛。
总体而言,FPS、IDIS和GS的计算成本太高,无法应用于大规模点云。 CRS方法具有过多的内存占用,而PGS很难学习。相比之下,随机采样具有以下两个优点:1)它具有显着的计算效率,因为它与输入点的总数无关,2)它不需要额外的计算内存。因此,我们有把握地得出结论,与所有现有的替代方案相比,随机抽样是迄今为止处理大规模点云的最合适的方法。然而,随机抽样可能会导致许多有用的点特征被丢弃。为了克服它,我们提出了一个强大的局部特征聚合模块,如下一节所述。
3.3. Local Feature Aggregation
如图3所示,我们的局部特征聚合模块并行应用于每个3D点,它由三个神经单元组成:1)局部空间编码(LocSE)、2)注意力池化和 3) 扩张残差块。
(1) Local Spatial Encoding
给定一个点云 P \boldsymbol{P} P和每个点的特征(例如,原始RGB或中间学习特征),这个局部空间编码单元显式嵌入所有相邻点的x-y-z坐标,使得对应的点特征总是知道它们的相对空间位置。这允许LocSE单元显式地观察局部几何图案,从而最终使整个网络受益于有效地学习复杂的局部结构。特别是,本单元包括以下步骤:
寻找相邻点。对于第i个点,为了提高效率,首先通过简单的最近邻(KNN)算法收集其相邻点。KNN基于逐点欧几里得距离。
相对点位置编码。对于中心点 p i p_{i} pi的每个最近的 K K K点 { p i 1 ⋯ p i k ⋯ p i K } \left\{p_{i}^{1} \cdots p_{i}^{k} \cdots p_{i}^{K}\right\} {pi1⋯pik⋯piK},我们将相对点位置显式编码如下:
r i k = M L P ( p i ⊕ p i k ⊕ ( p i − p i k ) ⊕ ∥ p i − p i k ∥ ) ( 1 ) \mathbf{r}_{i}^{k}=M L P\left(p_{i} \oplus p_{i}^{k} \oplus\left(p_{i}-p_{i}^{k}\right) \oplus\left\|p_{i}-p_{i}^{k}\right\|\right) \quad\quad\quad\quad(1) rik=MLP(pi⊕pik⊕(pi−pik)⊕∥ ∥pi−pik∥ ∥)(1)
其中 p i p_{i} pi和 p i k p_{i}^{k} pik是点的x-y-z位置, ⊕ \oplus ⊕是连接操作, ∥ ⋅ ∥ \|\cdot\| ∥⋅∥计算相邻点和中心点之间的欧几里得距离。似乎 r i k \mathbf{r}_{i}^{k} rik是从冗余点位置编码的。有趣的是,这往往有助于网络学习局部特征并在实践中获得良好的性能。
点特征增强。对于每个相邻点 p i k p_{i}^{k} pik,将编码后的相对点位置 r i k \mathbf{r}_{i}^{k} rik与其对应的点特征 f i k \mathbf{f}_{i}^{k} fik连接起来,得到一个增强的特征向量 f ^ i k \hat{\mathbf{f}}_{i}^{k} f^ik。
最终,LocSE单元的输出是一组新的相邻特征 F ^ i = { f ^ i 1 ⋯ f ^ i k ⋯ f ^ i K } \hat{\mathbf{F}}_{i}=\left\{\hat{\mathbf{f}}_{i}^{1} \cdots \hat{\mathbf{f}}_{i}^{k} \cdots \hat{\mathbf{f}}_{i}^{K}\right\} F^i={f^i1⋯f^ik⋯f^iK},它显式地编码了中心点 p i p_{i} pi的局部几何结构。我们注意到最近的工作[36]也使用点位置来改进语义分割。然而,这些位置用于学习[36]中的点分数,而我们的LocSE显式编码相对位置以增强相邻点特征。
(2) Attentive Pooling
该神经单元用于聚合一组相邻点特征 F ^ i \hat{\mathbf{F}}_{i} F^i。现有的工作[44, 33]通常使用最大/均值池化来硬集成相邻特征,导致大部分信息丢失。相比之下,我们转向强大的注意力机制来自动学习重要的局部特征。特别是,受[65]的启发,我们的注意力池单元由以下步骤组成。
计算注意力分数。给定一组局部特征 F ^ i = { f ^ i 1 ⋯ f ^ i k ⋯ f ^ i K } \hat{\mathbf{F}}_{i}=\left\{\hat{\mathbf{f}}_{i}^{1} \cdots \hat{\mathbf{f}}_{i}^{k} \cdots \hat{\mathbf{f}}_{i}^{K}\right\} F^i={f^i1⋯f^ik⋯f^iK}我们设计一个共享函数 g ( ) g() g()来学习每个特征的唯一注意力分数。基本上,函数 g ( ) g() g()由一个共享MLP和其后的softmax组成。其正式定义如下:
s i k = g ( f ^ i k , W ) ( 2 ) \mathbf{s}_{i}^{k}=g\left(\hat{\mathbf{f}}_{i}^{k}, \boldsymbol{W}\right) \quad\quad\quad\quad(2) sik=g(f^ik,W)(2)
其中 W W W是共享MLP的可学习权重。
加权求和。学习的注意力分数可以被视为自动选择重要特征的soft mask。从形式上看,这些特征的加权总和如下:
f ~ i = ∑ k = 1 K ( f ^ i k ⋅ s i k ) ( 3 ) \tilde{\mathbf{f}}_{i}=\sum_{k=1}^{K}\left(\hat{\mathbf{f}}_{i}^{k} \cdot \mathbf{s}_{i}^{k}\right) \quad\quad\quad\quad(3) f~i=k=1∑K(f^ik⋅sik)(3)
总的来说,给定输入点云 P \boldsymbol{P} P,对于第 i i i个点 p i p_{i} pi,我们的位置和注意池单元学习聚集其 K K K个最近点的几何图案和特征,并最终生成信息特征向量 f ~ i \tilde{\mathbf{f}}_{i} f~i。
(3) Dilated Residual Block
由于大点云将被大幅下采样,因此希望显着增加每个点的感受野,这样即使删除了一些点,输入点云的几何细节也更有可能被保留。如图3所示,受成功的ResNet[19]和有效的扩张网络[13]的启发,我们将多个LocSE和Attentive Pooling单元与跳跃连接堆叠为扩张残差块。
为了进一步说明我们的扩张残差块的能力,图4显示红色3D点在第一次LocSE/Attentive Pooling操作后观察到 K K K 个相邻点,然后能够接收来自多达 K 2 K^{2} K2个相邻点的信息,即它的两跳第二次之后的邻域。这是一种通过特征传播扩大感受野并扩大有效邻域的廉价方法。理论上,我们堆叠的单位越多,这个方块就越强大,因为它的影响范围变得越来越大。但是,更多的单元将不可避免地牺牲整体计算效率。此外,整个网络很可能会过拟合。在我们的RandLA-Net中,我们简单地将两组LocSE和Attentive Pooling堆叠为标准残差块,在效率和有效性之间取得了令人满意的平衡。
总体而言,我们的局部特征聚合模块旨在通过明确考虑相邻几何形状和显着增加感受野来有效地保留复杂的局部结构。此外,该模块仅由前馈(feed-forward)MLP组成,因此计算效率高。
图4.显着增加每个点的感受野(虚线圆圈)的扩张残差块的图示,彩色点代表聚合特征。 L:局部空间编码,A:注意力池化。

3.4. Implementation
我们通过堆叠多个局部特征聚合模块和随机采样层来实现RandLA-Net。详细的架构在附录中给出。我们使用带有默认参数的Adam优化器。初始学习率设置为0.01,每个epoch后降低5%。最近点的数量 K K K设置为16。为了并行训练我们的RandLA-Net,我们从每个点云中采样固定数量的点 ( ∼ 1 0 5 ) \left(\sim 10^{5}\right) (∼105)作为输入。在测试过程中,整个原始点云被输入到我们的网络中以推断每个点的语义,而无需进行几何或块分区等预/后处理。所有实验均在NVIDIA RTX2080Ti GPU上进行。
4. Experiments
4.1. Efficiency of Random Sampling
在本节中,我们根据经验评估现有采样方法的效率,包括第3.2节中讨论的FPS、IDIS、RS、GS、CRS和PGS。特别地,我们进行了以下4组实验。
- 第1组。给定一个小规模点云( ∼ 1 0 3 \sim 10^{3} ∼103个点),我们使用每种采样方法逐步对其进行下采样。具体来说,点云通过五个步骤进行下采样,在单个GPU上的每个步骤中仅保留25%的点,即四倍抽取率。这意味着最后只剩下 ∼ ( 1 / 4 ) 5 × 1 0 3 \sim(1 / 4)^{5} \times 10^{3} ∼(1/4)5×103个点。这种下采样策略模拟了PointNet++[44]中使用的过程。对于每种采样方法,我们总结了它的时间和内存消耗以进行比较。
图5. 不同采样方法的时间和内存消耗。由于有限的GPU内存,虚线表示估计值。

- 第2/3/4组。总点数向着大范围增加,即分别在 1 0 5 10^{5} 105、 1 0 5 10^{5} 105和 1 0 6 10^{6} 106点左右。我们使用与第1组相同的五个采样步骤。
分析。 图5比较了每种采样方法处理不同尺度点云的总时间和内存消耗。可以看出:1)对于小规模点云( ∼ 1 0 3 \sim 10^{3} ∼103),所有采样方法往往具有相似的时间和内存消耗,并且不太可能产生沉重或有限的计算负担。 2)对于大规模点云( ∼ 1 0 6 \sim 10^{6} ∼106),FPS/IDIS/GS/CRS/PGS要么非常耗时,要么耗费内存。相比之下,随机采样总体上具有出色的时间和内存效率。这一结果清楚地表明,大多数现有网络[44、33、60、36、70、66]只能在小块点云上进行优化,主要是因为它们依赖于昂贵的采样方法。受此启发,我们在RandLA-Net中使用了有效的随机抽样策略。
4.2. Efficiency of RandLA-Net
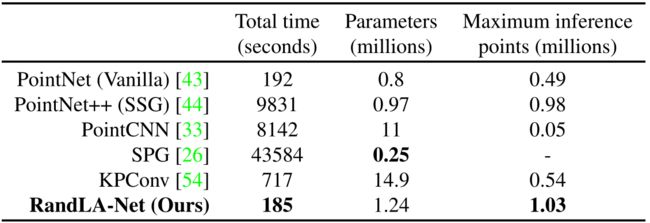
在本节中,我们系统地评估了我们的RandLA-Net在现实世界大规模点云上用于语义分割的整体效率。特别是,我们在 SemanticKITTI[3]数据集上评估RandLA-Net,获得了我们网络在序列08上的总时间消耗,总共有4071次点云扫描。我们还评估了同一数据集上最近的代表性作品[43、44、33、26、54]的时间消耗。为了公平比较,我们将每次扫描的相同数量的点(即81920)输入每个神经网络。
此外,我们还评估了RandLA-Net和基线的内存消耗。特别是,我们不仅报告了每个网络的参数总数,还测量了每个网络在单次传递中可以作为输入的最大3D点数,以推断每个点的语义。请注意,所有实验均在具有AMD 3700X @3.6GHz CPU和NVIDIA RTX2080Ti GPU的同一台机器上进行。
分析。 表1定量地显示了不同方法的总时间和内存消耗。可以看出,1)SPG[26]的网络参数数量最少,但由于昂贵的几何划分和超图构建步骤,处理点云的时间最长; 2)PointNet++[44]和PointCNN[33]的计算成本也很高,主要是因为FPS采样操作;3)PointNet[43]和KPConv[54]由于内存效率低下的操作,无法在一次通过中获取超大规模点云(例如 1 0 6 10^{6} 106个点)。4)由于简单的随机抽样和高效的基于MLP的局部特征聚合器,我们的RandLA-Net用最短的时间(4071帧平均185秒→大约22FPS)来推断每个大规模点的语义标签云(最多 1 0 6 10^{6} 106点)。
表1.SemanticKITTI[3]数据集序列08上不同语义分割方法的计算时间、网络参数和最大输入点数。
4.3. Semantic Segmentation on Benchmarks
在本节中,我们在三个大型公共数据集上评估RandLA-Net的语义分割:室外Semantic3D[17]和SemanticKITTI[3]以及室内S3DIS[2]。
(1)对Semantic3D的评估。 Semantic3D数据集[17]由15个用于训练的点云和15个用于在线测试的点云组成。每个点云最多有 1 0 8 10^{8} 108个点,在真实世界3D空间中覆盖最大160×240×30米。原始3D点属于8个类别,包含3D坐标、RGB信息和强度。我们只使用3D坐标和颜色信息来训练和测试我们的RandLANet。所有类别的平均交并比(mIoU)和总体准确度(OA)用作标准指标。为了公平比较,我们只包括最近发布的强基线(strong baselines)[4, 52, 53, 46, 69, 56, 26]和当前最先进的方法KPConv[54]的结果。
表2展示了不同方法的定量结果。 RandLA-Net在mIoU和OA方面明显优于所有现有方法。值得注意的是,除了低植被和扫描艺术外,RandLANet在八个类别中的六个上也取得了卓越的表现。
表2. Semantic3D(reduced-8)[17]上不同方法的定量结果。仅比较最近发布的方法。于2020年3月31日访问。

表3. SemanticKITTI[3]上不同方法的定量结果。仅比较最近发表的方法,所有分数均来自在线单次扫描评估轨道。于2020年3月31日访问。

图6. RandLA-Net在SemanticKITTI[3]验证集上的定性结果。红色圆圈表示失败案例。
(2)对SemanticKITTI的评估。 SemanticKITTI[3]由43552个密集注释的LIDAR扫描组成,属于21个序列。每次扫描都是一个大规模的点云,大约有 1 0 5 10^{5} 105个点,在3D空间中跨越160×160×20米。官方将序列00∼07和09∼10(19130次扫描)用于训练,序列08(4071次扫描)用于验证,序列11∼21(20351 次扫描)用于在线测试。原始3D点只有3D坐标,没有颜色信息。超过19个类别的mIoU得分用作标准指标。
表3显示了我们的RandLANet与最近的两个方法系列的定量比较,即1)基于点的方法[43、26、49、44、51]和2)基于投影的方法[58、59、3、40],以及图6显示了RandLA-Net在验证拆分上的一些定性结果。可以看出,我们的RandLA-Net大大超过了所有基于点的方法[43、26、49、44、51]。我们也优于所有基于投影的方法[58, 59, 3, 40],但并不显着,主要是因为RangeNet++[40]在交通标志等小目标类别上取得了更好的结果。然而,我们的RandLA-Net的网络参数比RangeNet++[40]少40倍,并且计算效率更高,因为它不需要昂贵的前/后投影步骤。
(3)对S3DIS的评价。 S3DIS数据集[2]由271个房间组成,属于6个大区域。每个点云都是一个中等大小的单人房间( ∼ 20 × 15 × 5 \sim 20 \times 15 \times 5 ∼20×15×5米),带有密集的3D点。为了评估我们的RandLA-Net的语义分割,我们在实验中使用了标准的6重交叉验证。比较了总共13个类的平均IoU (mIoU)、平均类准确度(mAcc)和总体准确度(OA)。
如表4所示,我们的RandLA-Net实现了与最先进的方法相当或更好的性能。请注意,这些基线[44, 33, 70, 69, 57, 6]中的大多数倾向于使用复杂但昂贵的操作或采样来优化点云小块(例如, 1 × 1 1 \times 1 1×1米)上的网络,并且相对较小的房间有利于他们被分成小块。相比之下,RandLA-Net将整个房间作为输入,并且能够在单次传递中有效地推断每个点的语义。
表4.S3DIS数据集[2]上不同方法的定量结果(6重交叉验证)。仅包括最近发布的方法。

4.4. Ablation Study
由于在第4.1节中充分研究了随机抽样的影响,我们对我们的局部特征聚合模块进行了以下消融研究。所有消融网络都在序列00∼07和09∼10上进行训练,并在SemanticKITTI数据集[3]的序列08上进行测试。
(1)去除局部空间编码(LocSE)。 该单元使每个3D点能够明确地观察其局部几何形状。去除locSE后,我们直接将局部点特征输入到后续的注意力池中。
(2∼4)用max/mean/sum pooling代替attentive pooling。 注意力池单元学习自动组合所有局部点特征。相比之下,广泛使用的max/mean/sum pooling倾向于硬选择或组合特征,因此它们的性能可能不是最优的。
(5)简化扩张残差块。 扩张的残差块堆叠了多个LocSE单元和注意力池,大大扩张了每个3D点的感受野。通过简化这个块,我们每层只使用一个LocSE单元和注意力池化,也就是说,我们不像原来的RandLA-Net那样链接多个块。
表5比较了所有消融网络的mIoU分数。由此,我们可以看出:1)最大的影响是由链式空间嵌入和注意力池化块的移除造成的。这在图4中突出显示,它显示了如何使用两个链式块允许信息从更广泛的邻域传播,即大约 K 2 K^{2} K2个点而不是仅 K K K。这对于随机采样尤其重要,随机采样不能保证保留特定的点集。2)局部空间编码单元的去除显示了对性能的第二大影响,表明该模块对于有效学习局部和相对几何上下文是必要的。3)移除注意力模块会因为无法有效保留有用的特征而降低性能。从这项消融研究中,我们可以看到所提出的神经单元如何相互补充以达到我们最先进的性能。
表5. 基于我们完整的RandLA-Net的所有消融网络的平均IoU分数。

5. Conclusion
在本文中,我们证明了使用轻量级网络架构可以有效地分割大规模点云。与依赖昂贵采样策略的大多数当前方法相比,我们在我们的框架中使用随机采样来显着减少内存占用和计算成本。还引入了一个局部特征聚合模块,以有效地保留来自广泛邻域的有用特征。在多个基准上进行的大量实验证明了我们方法的高效率和最先进的性能。通过借鉴最近的工作[64]以及实时动态点云处理[35],扩展我们在大规模点云上端到端3D实例分割的框架将会很有趣。
References
[1] Abubakar Abid, Muhammad Fatih Balin, and James Zou. Concrete autoencoders for differentiable feature selection and reconstruction. In ICML, 2019.
[2] Iro Armeni, Sasha Sax, Amir R Zamir, and Silvio Savarese. Joint 2D-3D-semantic data for indoor scene understanding. In CVPR, 2017.
[3] Jens Behley, Martin Garbade, Andres Milioto, Jan Quenzel, Sven Behnke, Cyrill Stachniss, and Juergen Gall. SemanticKITTI: A dataset for semantic scene understanding of lidar sequences. In ICCV, 2019.
[4] Alexandre Boulch, Bertrand Le Saux, and Nicolas Audebert. Unstructured point cloud semantic labeling using deep segmentation networks. In 3DOR, 2017.
[5] Chao Chen, Guanbin Li, Ruijia Xu, Tianshui Chen, Meng Wang, and Liang Lin. ClusterNet: Deep hierarchical cluster network with rigorously rotation-invariant representation for point cloud analysis. In CVPR, 2019.
[6] Lin-Zhuo Chen, Xuan-Yi Li, Deng-Ping Fan, Ming-Ming Cheng, Kai Wang, and Shao-Ping Lu. LSANet: Feature learning on point sets by local spatial attention. arXiv preprint arXiv:1905.05442, 2019.
[7] Siheng Chen, Sufeng Niu, Tian Lan, and Baoan Liu. PCT: Large-scale 3D point cloud representations via graph inception networks with applications to autonomous driving. In ICIP, 2019.
[8] Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, and Tian Xia. Multi-view 3D object detection network for autonomous driving. In CVPR, 2017.
[9] Yilun Chen, Shu Liu, Xiaoyong Shen, and Jiaya Jia. Fast point R-CNN. In ICCV, 2019.
[10] Christopher Choy, JunY oung Gwak, and Silvio Savarese. 4D spatio-temporal convnets: Minkowski convolutional neural networks. In CVPR, 2019.
[11] Chin Seng Chua and Ray Jarvis. Point signatures: A new representation for 3D object recognition. IJCV, 1997.
[12] Oren Dovrat, Itai Lang, and Shai Avidan. Learning to sample. In CVPR, 2019.
[13] Francis Engelmann, Theodora Kontogianni, and Bastian Leibe. Dilated point convolutions: On the receptive field of point convolutions. In BMVC, 2019.
[14] Benjamin Graham, Martin Engelcke, and Laurens van der Maaten. 3D semantic segmentation with submanifold sparse convolutional networks. In CVPR, 2018.
[15] Fabian Groh, Patrick Wieschollek, and Hendrik P . A. Lensch. Flex-convolution (million-scale point-cloud learning beyond grid-worlds). In ACCV, 2018.
[16] Y ulan Guo, Hanyun Wang, Qingyong Hu, Hao Liu, Li Liu, and Mohammed Bennamoun. Deep learning for 3d point clouds: A survey. arXiv preprint arXiv:1912.12033, 2019.
[17] Timo Hackel, Nikolay Savinov, Lubor Ladicky, Jan D Wegner, Konrad Schindler, and Marc Pollefeys. Semantic3d. net: A new large-scale point cloud classification benchmark. ISPRS, 2017.
[18] Timo Hackel, Jan D Wegner, and Konrad Schindler. Fast semantic segmentation of 3d point clouds with strongly varying density. ISPRS, 2016.
[19] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016.
[20] Binh-Son Hua, Minh-Khoi Tran, and Sai-Kit Yeung. Pointwise convolutional neural networks. In CVPR, 2018.
[21] Qiangui Huang, Weiyue Wang, and Ulrich Neumann. Recurrent slice networks for 3D segmentation of point clouds. In CVPR, 2018.
[22] Li Jiang, Hengshuang Zhao, Shu Liu, Xiaoyong Shen, ChiWing Fu, and Jiaya Jia. Hierarchical point-edge interaction network for point cloud semantic segmentation. In ICCV, 2019.
[23] Artem Komarichev, Zichun Zhong, and Jing Hua. A-CNN: Annularly convolutional neural networks on point clouds. In CVPR, 2019.
[24] Shiyi Lan, Ruichi Y u, Gang Y u, and Larry S Davis. Modeling local geometric structure of 3D point clouds using GeoCNN. In CVPR, 2019.
[25] Loic Landrieu, Hugo Raguet, Bruno V allet, Clément Mallet, and Martin Weinmann. A structured regularization framework for spatially smoothing semantic labelings of 3d point clouds. ISPRS, 2017.
[26] Loic Landrieu and Martin Simonovsky. Large-scale point cloud semantic segmentation with superpoint graphs. In CVPR, 2018.
[27] Alex H Lang, Sourabh V ora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. PointPillars: Fast encoders for object detection from point clouds. In CVPR, 2019.
[28] Truc Le and Ye Duan. PointGrid: A deep network for 3D shape understanding. In CVPR, 2018.
[29] Huan Lei, Naveed Akhtar, and Ajmal Mian. Octree guided cnn with spherical kernels for 3D point clouds. In CVPR, 2019.
[30] Bo Li, Tianlei Zhang, and Tian Xia. V ehicle detection from 3D lidar using fully convolutional network. In RSS, 2016.
[31] Guohao Li, Matthias Muller, Ali Thabet, and Bernard Ghanem. Deepgcns: Can gcns go as deep as cnns? In ICCV, October 2019.
[32] Jiaxin Li, Ben M Chen, and Gim Hee Lee. SO-Net: Selforganizing network for point cloud analysis. In CVPR, 2018.
[33] Yangyan Li, Rui Bu, Mingchao Sun, Wei Wu, Xinhan Di, and Baoquan Chen. PointCNN: Convolution on Xtransformed points. In NeurIPS, 2018.
[34] Jinxian Liu, Bingbing Ni, Caiyuan Li, Jiancheng Yang, and Qi Tian. Dynamic points agglomeration for hierarchical point sets learning. In ICCV, 2019.
[35] Xingyu Liu, Mengyuan Yan, and Jeannette Bohg. MeteorNet: Deep learning on dynamic 3D point cloud sequences. In ICCV, 2019.
[36] Y ongcheng Liu, Bin Fan, Shiming Xiang, and Chunhong Pan. Relation-shape convolutional neural network for point cloud analysis. In CVPR, 2019.
[37] Zhijian Liu, Haotian Tang, Y ujun Lin, and Song Han. Pointvoxel cnn for efficient 3d deep learning. In NeurIPS, 2019.
[38] Jiageng Mao, Xiaogang Wang, and Hongsheng Li. Interpolated convolutional networks for 3D point cloud understanding. In ICCV, 2019.
[39] Hsien-Y u Meng, Lin Gao, Y u-Kun Lai, and Dinesh Manocha. VV-net: V oxel vae net with group convolutions for point cloud segmentation. In ICCV, 2019.
[40] Andres Milioto, Ignacio Vizzo, Jens Behley, and Cyrill Stachniss. RangeNet++: Fast and accurate lidar semantic segmentation. In IROS, 2019.
[41] Andriy Mnih and Karol Gregor. Neural variational inference and learning in belief networks. arXiv preprint arXiv:1402.0030, 2014.
[42] Anshul Paigwar, Ozgur Erkent, Christian Wolf, and Christian Laugier. Attentional pointnet for 3d-object detection in point clouds. In CVPRW, 2019.
[43] Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. PointNet: Deep learning on point sets for 3D classification and segmentation. In CVPR, 2017.
[44] Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In NeurIPS, 2017.
[45] Dario Rethage, Johanna Wald, Jurgen Sturm, Nassir Navab, and Federico Tombari. Fully-convolutional point networks for large-scale point clouds. In ECCV, 2018.
[46] Xavier Roynard, Jean-Emmanuel Deschaud, and Franc ¸ois Goulette. Classification of point cloud scenes with multiscale voxel deep network. arXiv preprint arXiv:1804.03583, 2018.
[47] Radu Bogdan Rusu, Nico Blodow, and Michael Beetz. Fast point feature histograms (fpfh) for 3D registration. In ICRA, 2009.
[48] Yiru Shen, Chen Feng, Yaoqing Yang, and Dong Tian. Mining point cloud local structures by kernel correlation and graph pooling. In CVPR, 2018.
[49] Hang Su, V arun Jampani, Deqing Sun, Subhransu Maji, Evangelos Kalogerakis, Ming-Hsuan Yang, and Jan Kautz. SPLA TNet: sparse lattice networks for point cloud processing. In CVPR, 2018.
[50] Richard S Sutton, David A McAllester, Satinder P Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation. In NeurIPS, 2000.
[51] Maxim Tatarchenko, Jaesik Park, Vladlen Koltun, and QianYi Zhou. Tangent convolutions for dense prediction in 3D. In CVPR, 2018.
[52] Lyne Tchapmi, Christopher Choy, Iro Armeni, JunY oung Gwak, and Silvio Savarese. Segcloud: Semantic segmentation of 3D point clouds. In 3DV, 2017.
[53] Hugues Thomas, Franc ¸ois Goulette, Jean-Emmanuel Deschaud, and Beatriz Marcotegui. Semantic classification of 3D point clouds with multiscale spherical neighborhoods. In 3DV, 2018.
[54] Hugues Thomas, Charles R Qi, Jean-Emmanuel Deschaud, Beatriz Marcotegui, Franc ¸ois Goulette, and Leonidas J Guibas. KPConv: Flexible and deformable convolution for point clouds. In ICCV, 2019.
[55] Chu Wang, Babak Samari, and Kaleem Siddiqi. Local spectral graph convolution for point set feature learning. In ECCV, 2018.
[56] Lei Wang, Y uchun Huang, Yaolin Hou, Shenman Zhang, and Jie Shan. Graph attention convolution for point cloud semantic segmentation. In CVPR, 2019.
[57] Y ue Wang, Y ongbin Sun, Ziwei Liu, Sanjay E. Sarma, Michael M. Bronstein, and Justin M. Solomon. Dynamic graph cnn for learning on point clouds. ACM Transactions on Graphics (TOG), 2019.
[58] Bichen Wu, Alvin Wan, Xiangyu Y ue, and Kurt Keutzer. Squeezeseg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3D lidar point cloud. In ICRA, 2018.
[59] Bichen Wu, Xuanyu Zhou, Sicheng Zhao, Xiangyu Y ue, and Kurt Keutzer. Squeezesegv2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a lidar point cloud. In ICRA, 2019.
[60] Wenxuan Wu, Zhongang Qi, and Li Fuxin. PointConv: Deep convolutional networks on 3D point clouds. In CVPR, 2018.
[61] Saining Xie, Sainan Liu, Zeyu Chen, and Zhuowen Tu. Attentional shapecontextnet for point cloud recognition. In CVPR, 2018.
[62] Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Y oshua Bengio. Show, attend and tell: Neural image caption generation with visual attention. In ICML, 2015.
[63] Bin Yang, Wenjie Luo, and Raquel Urtasun. Pixor: Realtime 3D object detection from point clouds. In CVPR, 2018.
[64] Bo Yang, Jianan Wang, Ronald Clark, Qingyong Hu, Sen Wang, Andrew Markham, and Niki Trigoni. Learning object bounding boxes for 3D instance segmentation on point clouds. In NeurIPS, 2019.
[65] Bo Yang, Sen Wang, Andrew Markham, and Niki Trigoni. Robust attentional aggregation of deep feature sets for multiview 3D reconstruction. IJCV, 2019.
[66] Jiancheng Yang, Qiang Zhang, Bingbing Ni, Linguo Li, Jinxian Liu, Mengdie Zhou, and Qi Tian. Modeling point clouds with self-attention and gumbel subset sampling. In CVPR, 2019.
[67] Xiaoqing Ye, Jiamao Li, Hexiao Huang, Liang Du, and Xiaolin Zhang. 3D recurrent neural networks with context fusion for point cloud semantic segmentation. In ECCV, 2018.
[68] Wenxiao Zhang and Chunxia Xiao. PCAN: 3D attention map learning using contextual information for point cloud based retrieval. In CVPR, 2019.
[69] Zhiyuan Zhang, Binh-Son Hua, and Sai-Kit Yeung. Shellnet: Efficient point cloud convolutional neural networks using concentric shells statistics. In ICCV, 2019.
[70] Hengshuang Zhao, Li Jiang, Chi-Wing Fu, and Jiaya Jia. Pointweb: Enhancing local neighborhood features for point cloud processing. In CVPR, 2019.