KnowPrompt:Knowledge-aware Prompt-tuning with Synergistic Optimization for Relation Extraction
Abstract
Prompt-tuning 的核心思想就是将文本块(text pieces)插入到输入中并且将一个分类问题转换成一个掩码语言模型问题。在关系抽取任务中,决定一个合适的prompt模板需要大量的领域知识,并且很难有一个合适的label word。此外,在实体和关系之间存在着大量的语义知识。为此作者提出了一个基于协同优化的知识感知的即时优化方法,这种方法着重将知识插入到prompt-tuning。具体而言就是把实体知识和关系知识注入到具有可学习虚拟模板和回答词的Prompt 构造中,并在知识约束下协同优化它们的表示。
Introduction
关系抽取因其能够提取文本信息,有利于诸如信息检索、对话生成和问题问答等自然语言处理任务。先前的预训练模型有以下缺点:1、fune-tuning时需要在顶部添加额外的分类器;2、进一步在分类对目标训练模型;3、费事、费人力(标注数据);4、1,2步导致了模型的泛化性较差。因此prompt-tuning逐渐流行,其将预训练语言模型直接作为一个预测器去完成完形填空任务,这弥补了预训练和微调之间的差距。Prompt-tuning将原始输入和prompt模板融合起来预测[MASK].然后将预测的标签词映射到相应的类集,这使得PLM在few-shots任务上具有更好的性能。

由上图可以看出,在原本的基础上,prompt-tuning以人名(Hamilton)、国家(British)知识作为约束从而将去掉预测的另一个类别。简而言之,带有Prompt-tuning的关系抽取任务涉及到模板工程和回答工程,后者的目标是寻找最佳模板和一个回答空间。
然而,仍然由以下几个问题:1、确定适当的模板需要领域专业知识,而自动构造具有输入实体的高性能提示仍然需要额外的计算成本来生成和验证。2、搜索label word过程的计算复杂度是比较高的(复杂度通常依赖标签的种类),并且当词汇表中关系标签的长度变化时,很难获得一个合适的目标标签。For example, the relation labels of per:country_of_birthand ,org:city_of_headquarters cannot specify a suitable single label word in the vocabulary。3、此外,实体类型之间存在着丰富的语义知识,关系标签之间存在着丰富的关系三元组之间的结构知识含义,这些都是不容忽视的。
为了解决上面的问题,我们第一步将知识注入到可学习的常量prompts并且提出了一个新的Knowledge-aware Prompt-tuning with synergistic optimization (KnowPrompt) 方法用于关系抽取。我们通过可学习的虚拟模板词和虚拟的回答词来构造Prompt以此来减轻人力标注prompt。具体来说,我们利用实体周围的有类型的标记用聚合的实体类型嵌入初始化来作为可学习的虚拟模板词以此去注入实体类型知识。我们进一步利用关系标签中每个token的平均嵌入作为虚拟回答词来注入关系知识。由于实体和关系之间存在隐性的结构约束,虚拟词应与周围语境保持一致,我们引入协同优化,以获得优化后的虚拟模板和答案词。具体来说,我们提出了一种具有隐式结构约束的上下文感知提示校准方法,在关系三元组之间注入结构知识含义,并将提示嵌入相互关联。我们总结我们的贡献如下:
1、本文提出了一种新的知识感知提示优化方法(KnowPrompt),该方法将知识注入到提示模板设计和答案构造中,从而对实体类型和关系之间丰富的语义知识进行编码。
2、我们建议联合优化虚拟提示模板的表示,并在知识约束下回答单词。据我们所知,这是第一个在连续空间中联合优化提示模板和回答词的方法。
3、在5个RE基准数据集(一般和对话领域)上的广泛实验说明了KnowPrompt在标准和低资源设置中的有效性。
Background
关系抽取得分数据集可以被表示为![]() ,其中
,其中 表示样例的集合,
表示样例的集合, 表示关系标签的集合。对于每个样例
表示关系标签的集合。对于每个样例![]() ,关系抽取的目标就是预测实体
,关系抽取的目标就是预测实体![]() 和实体
和实体![]() 之间的关系
之间的关系![]() (一个实体可能有多个token,这里使用实体
(一个实体可能有多个token,这里使用实体![]() 和实体
和实体![]() 简洁的代表所有实体)。
简洁的代表所有实体)。
Fine-tuning of PLMs
对于一个预训练模型,之间fine-tuning方法是把实例![]() 转化成一个预训练模型的输入,例如
转化成一个预训练模型的输入,例如![]() 。预训练模型将输入序列编码成对应的输出隐向量,例如
。预训练模型将输入序列编码成对应的输出隐向量,例如![]() 。通常,
。通常,![]() 被用于
被用于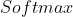 函数计算类集上的概率分布,
函数计算类集上的概率分布,![]() 。
。
Prompt-Tuning of PLMs
Prompt被用于弥补预训练和下游任务的差距。困难的构建一个合适的模板![]() 和标签词
和标签词 ,这些统一被称为提示符
,这些统一被称为提示符 。对于每个实例
。对于每个实例 ,利用模板将映射到提示输入
,利用模板将映射到提示输入![]() 。具体的是,模板
。具体的是,模板![]() 包含添加的额外的单词位置个数量(包括实际的和可学习的连续单词)。指的是语言模型词汇表中的标签单词的集合,并且
包含添加的额外的单词位置个数量(包括实际的和可学习的连续单词)。指的是语言模型词汇表中的标签单词的集合,并且![]() 表示连接任务标签到标签词的单射映射。
表示连接任务标签到标签词的单射映射。
除了保留中原始的单词,在 中防止一个或多个
中防止一个或多个![]() 去填充标签单词。模型可以正确的预测被masked位置的token,我们可以将上被遮掩位置的条件分布
去填充标签单词。模型可以正确的预测被masked位置的token,我们可以将上被遮掩位置的条件分布![]() 做如下形式化。
做如下形式化。
![]()
我们将映射为![]() “ Apple
“ Apple ![]() Steve Jobs
Steve Jobs![]() ”,我们可以编码并且产生一个概率分布
”,我们可以编码并且产生一个概率分布![]() 以此获得一个
以此获得一个![]() 的隐向量,从而决定中的哪个词可以代替
的隐向量,从而决定中的哪个词可以代替![]() 的位置。最后,分别设置集合
的位置。最后,分别设置集合![]() 和
和![]() 等等。然后根据模型预测是“birth”还是“founder”,以此确定实例的关系标签。重要的是构建一个预测词和关系标签的一个对应关系。
等等。然后根据模型预测是“birth”还是“founder”,以此确定实例的关系标签。重要的是构建一个预测词和关系标签的一个对应关系。
Methodology
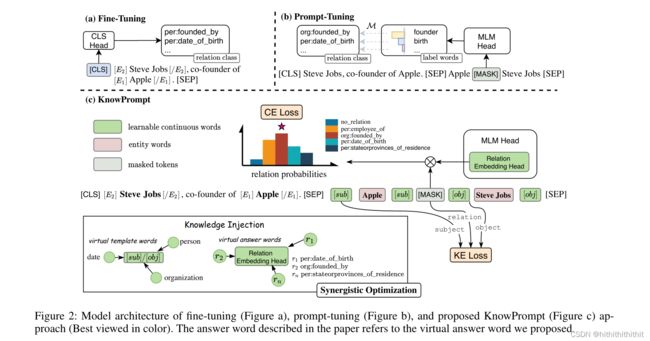
Prompt Construction with Knowledge Injection
典型的Prompt包含两部分,分别是模板和一系列的标签词,我们针对关系抽取任务提出了有知识注入的虚拟模板词和虚拟回答词构造。
Entity Knowledge Injection.我们遵循之前的方法,使用Entity/Type MARKER 在原始输入序列实体周围注入特殊的符号,例如[E]和[/E]以便在关系抽取任务中索引实体的位置。虽然TYPE MARKER方法可以额外的引入实体的类型信息来提高性能,但需要额外的类型信息注释。然而,在给定特定关系的前提下,我们可以得到具有先验知识的两个被标记实体的实体类型的范围。例如,对于给出的关系:“per:country_of_birth”,很明显就能看出主体属于person,客体属于country。对此,我们首先根据关系类别评测![]() 实体类型的概率分布。其中,概率分布由可能实体类型的频率统计完成。在图2中,我们利用可学习的连续词去感知实体类型信息。具体而言,虚拟模板词的可学习嵌入用聚合的实体类型嵌入初始化如下:
实体类型的概率分布。其中,概率分布由可能实体类型的频率统计完成。在图2中,我们利用可学习的连续词去感知实体类型信息。具体而言,虚拟模板词的可学习嵌入用聚合的实体类型嵌入初始化如下:
![]()
![]()
![]() 代表主体和客体周围的虚拟模板词嵌入,e是模型的词嵌入层。基于实体类型知识设计可学习虚拟模板,这种方法类似于Entity MARKER方法没有额外的类型信息标注的效果。事实上,ENTITY MARKER和TYPED MARKER方法可以被视为prompts模板的一种类型,prompts提供了丰富的实体位置和实体类型的知识信息。
代表主体和客体周围的虚拟模板词嵌入,e是模型的词嵌入层。基于实体类型知识设计可学习虚拟模板,这种方法类似于Entity MARKER方法没有额外的类型信息标注的效果。事实上,ENTITY MARKER和TYPED MARKER方法可以被视为prompts模板的一种类型,prompts提供了丰富的实体位置和实体类型的知识信息。
Relation Knowledge Injection.先前的prompt-tuning研究通常形式化一个在标签词和任务标签之间的单射关系,这通常会导致无法利用关系标签之间去丰富的语义知识。为此,我们假定PLMs词汇表空间中有一个![]() 作为虚拟的答案词。从这个角度,我们用可学习的关系嵌入来扩展模型的MLM头部层作为虚拟回答词集合
作为虚拟的答案词。从这个角度,我们用可学习的关系嵌入来扩展模型的MLM头部层作为虚拟回答词集合![]() 来完全表示对应的关系标签集。因此,我们可以用
来完全表示对应的关系标签集。因此,我们可以用![]() 在掩码位置的概率分布重新化为
在掩码位置的概率分布重新化为![]() 。也可以通过分解关系类型来设置关系语义词的候选集
。也可以通过分解关系类型来设置关系语义词的候选集![]() 上的概率分布
上的概率分布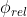 。具体来说,我们对关系标签的标记化中每个标记的平均嵌入采用加权平均函数来初始化这些关系嵌入,关系嵌入可以注入关系的语义知识。例如,我们将关系
。具体来说,我们对关系标签的标记化中每个标记的平均嵌入采用加权平均函数来初始化这些关系嵌入,关系嵌入可以注入关系的语义知识。例如,我们将关系![]() 分解为
分解为![]() ;然后虚拟回答词的可学习关系嵌入被初始化为如下形式:
;然后虚拟回答词的可学习关系嵌入被初始化为如下形式:![]()
Synergistic Optimization with Knowledge Constraints
由于实体类型和关系标签之间存在着丰富的交互和联系,并且虚拟模板词和答案词都需要与周围上下文关联,因此我们进一步引入了一种具有隐式结构约束的协同优化方法。其中,进一步协同优化虚拟模板词与虚拟回答词的参数集![]() 。
。
Context-aware Prompt Calibration(上下文感知Prompt校准).虽然我们的虚拟模板和答案词是基于语义知识进行初始化的,但它们在潜变量空间中可能不是最优的,应该与周围的上下文相关联。因此,通过感知上下文来校准它们的表示,进一步优化是必要的。给定掩码位置的概率分布![]() ,我们通过
,我们通过 和
和![]() 之间的交叉熵计算的损失函数对虚拟模板词和答案词进行优化,如下所示:
之间的交叉熵计算的损失函数对虚拟模板词和答案词进行优化,如下所示:
![]()
![]() 表示训练数据集的数量,可学习连续词可通过协同模板和答案优化自适应获得最优表示形式进行即时调优。
表示训练数据集的数量,可学习连续词可通过协同模板和答案优化自适应获得最优表示形式进行即时调优。
Implicit Structural Constraints.为了将结构化知识整合到KnowPrompt中,我们将KnowPrompt中的知识嵌入(Knowledge Embedding,KE)对象作为一个额外的限制用于优化prompts。具体而言,我们用了一个三元组![]() 去描述一个关系对象。其中,
去描述一个关系对象。其中,![]() 分别代表主体和客体实体,
分别代表主体和客体实体, 代表一个预定义回答词集合
代表一个预定义回答词集合![]() 内的关系标签。在KnowPrompt中,我们没有使用预先训练好的知识图谱嵌入,直接使用了虚拟模板词和虚拟答案词输出嵌入,通过语言模型参与计算。使用如下的Loss作为KE目标:
内的关系标签。在KnowPrompt中,我们没有使用预先训练好的知识图谱嵌入,直接使用了虚拟模板词和虚拟答案词输出嵌入,通过语言模型参与计算。使用如下的Loss作为KE目标:
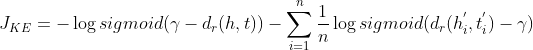
![]()
![]() 是负例,
是负例, 是margin,
是margin, 是分数函数。对于负例,我们指定正确的虚拟词在
是分数函数。对于负例,我们指定正确的虚拟词在![]() 位置,随机抽样主体或客体词并且将其和一个不相关的词放在一个一起构造一个损坏(corrupt)的三元组,其中实体对当前关系具有不可能的类型。
位置,随机抽样主体或客体词并且将其和一个不相关的词放在一个一起构造一个损坏(corrupt)的三元组,其中实体对当前关系具有不可能的类型。
Training Details
我们的方法有一个两个阶段的优化过程。首先,我们用一个较大的学习率![]() 去协同优化虚拟模板词和虚拟回答词的参数集合
去协同优化虚拟模板词和虚拟回答词的参数集合![]() 以此去获得一个如下优化的prompt:
以此去获得一个如下优化的prompt:
![]()
其中, 是超参数,
是超参数,![]() 是
是![]() 和
和![]() 预测的损失.
预测的损失.
然后,在优化后的虚拟模板词和答案词的基础上,利用对象函数![]() 以较小的学习速率
以较小的学习速率![]() 对PLM参数进行提示(整体参数优化)优化。
对PLM参数进行提示(整体参数优化)优化。
Conclusions
In this paper, we present KnowPrompt, which mainly includes knowledge-injected prompt construction and synergistic optimization with structure constraints. Experimental results on five datasets show that our approach achieves improvement in both standard and low-resource scenarios compared with various baselines. In the future, we plan to explore three directions, including: (i) extending to semi-supervised setting to further leverage unlabelled data; (ii)extending to lifelong learning, whereas prompt should be optimized with adaptive tasks. (iii) applying our approaches to more prompt-tuning tasks.