MySQL技术内幕-InnoDB存储引擎
目录
一、深入理解InnoDB底层事务实现机制
1. 事务的四大特性
下面来简单介绍一下这四种隔离级别
2. 数据库的锁
3. MVCC机制
3.1 什么是COW机制
3.2 脏数据与旧数据
3.3 MVCC机制
4. redo log
5. 内部事务的优化
5.1 长事务的影响
6. 慢sql查询问题怎么优化
7. InnoDB引擎索引的实现
MyISAM存储引擎的实现
InnoDB存储引擎的实现
InnoDB存储引擎详解
编辑
8.最左前缀原则以及最左前缀原则的底层实现
8.1 什么是最左前缀原则?
8.2 为什么会形成最左前缀原则?
9. explain命令详解
一、深入理解InnoDB底层事务实现机制
1. 事务的四大特性
ACID:

mysql数据库中使用InnoDB这个存储引擎

mysql数据库默认使用RR,Oracle默认使用RC
下面来简单介绍一下这四种隔离级别
1. read uncommit(读未提交)
这种隔离级别下就是说一个事务可以读到另外一个事务没有提交的数据,但是如果事务使用roolback就可以返回了!
比如下面的代码
#事务1进行添加操作
set tx_isolation="read-UNCOMMITTED" #设置事务隔离级别
begin #开启事务
update account set balance=balance+500 where id=1;
#事务2进行读取操作
set tx_isolation="read-UNCOMMITTED" #设置事务隔离级别
begin #开启事务
select * from account where id=1;
#这个时候就可以读取到对应的数据
#但是如果这个时候事务1使用rollback的话就会取消事务的执行操作,因为当前没有提交,事务2再读取的时候将读取不到前面更新的数据2. read commit(读已提交) ---- 更适用于高并发
就是读取已经提交了的数据
需要使用commit真真正正的提交了!
存在一个不足的点:别的事务修改了数据之后,当前事务读取的数据会发生变化,也就是说不可以重复读取!就是当前事务读取的时候可能一直在变化,就会导致我们当前读取数据的时候会不一样,到底以那个为标准?一直飘忽不定,这个时候就需要更高的隔离级别repeatable read(可重复读)
3. repeatable read(可重复读) ----- 更适用于普通企业的管理
在一个事务里面只要读取过数据,后面再去读取数据都是以第一次读取的数据为准,并且第一次读取会保存所有的数据!
后面无论怎么读取都是读取到当前的第一次进行的时候的快照!
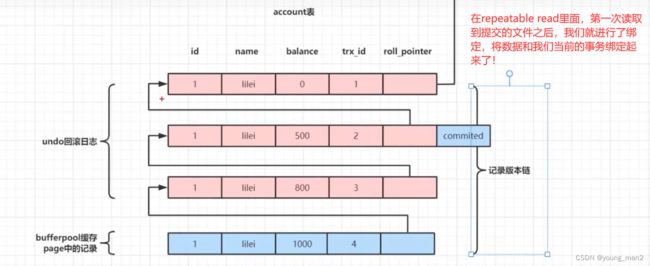
所以这就是为什么我们后面读取数据的时候都是读取原来的数据
我们知道在这个情况下会存在一些不足,那就是修改数据的时候可能会存在脏写的情况,那么怎么办?
解决方法一:
我们可以加乐观锁,比如我们可以在对应的数据上添加version,这个时候我们在更新的时候就需要添加上version,那么在执行语句的时候就首先会判断version对不对的上,比如我们当前没有事务对他操作过,那么一定可以对上,但是如果当前有事务操作了,就会修改对应的version,那么我们当前的verion下的操作就可能不能执行了!
解决方法二:
我们还可以直接使用对应的语句进行操作,比如我们可以修改为
update account set balance=balance-500 where id=; #这里的balance就是我们当前数据库的最新的数据,这样修改就不会出错【不可以使用java算出来的数据进行更新,因为那个数据是没有改变过的,还是原来的】
4. serializable(串行)
它可以实现,只要前面事务没有执行提交的前提下,后面的事务查询的时候是不会得到结果的,当前面的事务一旦提交,后面的事务就会立马得到结果了!
2. 数据库的锁

所有的更新操作、插入、删除操作在执行的时候都会添加行锁!行锁在提交的时候释放!
mysql中的锁如下所示:

3. MVCC机制
3.1 什么是COW机制
所谓COW就是copy on write,那么是怎么实现的?在对数据进行修改的时候首先复制出来一个新的数据表,然后对这个新复制的数据表进行操作,但是读取的时候是在原来的数据表进行读取,也就是说当前读取到的数据可能并不是最新的!类似于ConcurrentHashMap
当对复制的数据表操作完了之后再全部更新到原来的表中!
如果我们同时在一个表里面进行操作,这个时候可能写操作才执行一半的时候就有人来读取,这个时候就会读取脏数据!
那么怎么解决?
①加锁,只有更新完之后才释放锁,才可以读!这个时候就会形成读写串行化,这也就导致了性能不可能高!
②读写分离
3.2 脏数据与旧数据
脏数据:操作没有完成之前被读取
旧数据:原来的没有被修改的数据(没来得及更新的数据)
3.3 MVCC机制
所谓MVCC指的是多版本并发机制
使用读写分离进行操作
4. redo log
写redo日志采用的是顺序写,但是写入磁盘使用的却是随机写,这种情况下写redo日志比写磁盘的性能要高很多!
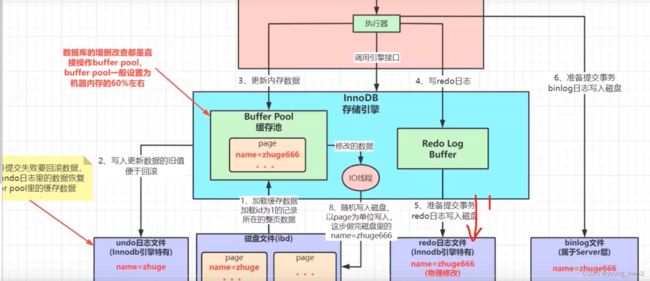
我们通过查看可以知道,我们数据库中含有很多的ibd文件,然后由于每次操作的时候都不会确定当前使用的是哪个idb文件,自然也就不可能实现顺序存储了
持久化的实现
MySQL引入了redo log, Buffer Pool内存写完了,然后会写份redo log,这份redo log记载着这次在某个页上做了什么修改。
即便MySQL在中途挂了,我们还可以根据redo log来对数据进行恢复。
redo log是顺序写的,写入速度很快。并且它记录的是物理修改(xxxx页做了xxx修改) ,文件的体积很小,恢复速度也很快。
5. 内部事务的优化
5.1 长事务的影响
- 并发情况下,数据库连接池容易被撑爆
- 锁定太多的数据,造成大量的阻塞和锁超时
- 执行时间长,容易造成主从延迟
- 回滚所需要的时间比较长
- undo log膨胀
- 容易导致死锁
6. 慢sql查询问题怎么优化
什么是慢SQL?所谓慢SQL指的是一条SQL语句平时可能只需要几毫秒就可以执行完但是在你这里需要几秒甚至几十秒。
如何优化?
可以使用索引,索引指的是帮助Mysql高效获取数据的排好序的数据结构
这里就涉及了mysql使用什么方式来建立索引-----二叉树、红黑树、B树、B+树
为什么mysql中使用B+树而不是其他的树?
①二叉树:
如果使用二叉树的话,我们知道二叉树存储都是大于根节点往右,小于往左,然后构建出一颗二叉树,但是这样可能存在一个不足,那就是如果当前加入的数据一直都是大于的,这个树构建出来就是单向的树了,这样的查找其实和直接在内存中查找没有区别
②红黑树
有了上面的想法后,我们可以想到另外一种结构----红黑树
红黑树有什么作用?---自适应平衡二叉树,也就是差距不会超过2
那么红黑树为什么也不行,因为我们会发现,即使是使用红黑树也会存在问题,每一层只可以存放两个节点,那么我们在寻找的时候查询的层高还是会很高,所以也不行!
③B树
有了上面的红黑树,也许会想,那我们就使用B树,B树每一层可以存放一定量的数据【16KB】,然后依次找肯定效率大于红黑树,没错,使用到B树的时候效率确实是提升了很多,但是我们会发现对比B树还存在一个更好的数据结构----B+树
④B+树
B+树相比于B树的区别在于,B+树每一层只存储节点,不会像B树一样还会存储数据,自然而然,B+树的高度肯定是低于B树的,所以B+树就是Mysql的最佳索引!
⑤hash表
这里作为拓展,我们知道hash存储的时候使用求hash然后链接的方式进行存储,最后得到我们想要的结果,它的效率也是高于B+树的,但是为什么我们不使用hash这个结构?
因为不支持范围查找,然后就是会存在hash冲突的情况

比如我们这里需要查找name>"Tom"的元素,就会发现定位不了,那就需要全表扫描,这就还不如不加索引!
7. InnoDB引擎索引的实现
存储引擎最终是形容我们的数据库表的
MyISAM存储引擎的实现
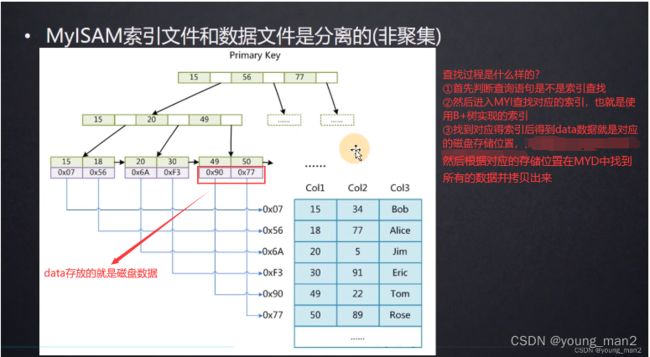
InnoDB存储引擎的实现
一般来说InnoDB的主键索引就是它的聚集索引,它的二级索引可以算得上是非聚集索引!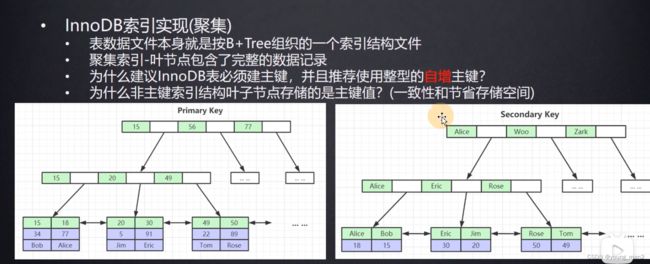
我们知道INNODB也是使用的B+树,那么他在最后叶子节点data的位置存放的就是当前索引所在行的列数据!

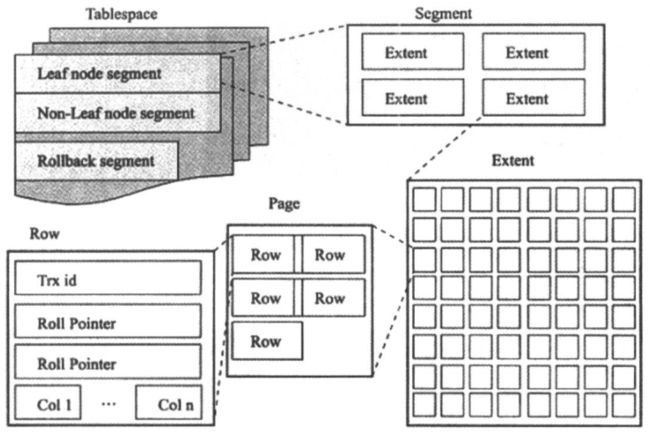
InnoDB存储引擎详解
InnoDB存储引擎主要包含表空间、段、区、页、层级关系
8.最左前缀原则以及最左前缀原则的底层实现
8.1 什么是最左前缀原则?
最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
8.2 为什么会形成最左前缀原则?
首先要知道,最左匹配原则都是针对联合索引来说的,所以我们有必要了解一下联合索引的原理。了解了联合索引,那么为什么会有最左匹配原则这种说法也就理解了。
我们都知道索引的底层是一颗B+树,那么联合索引当然还是一颗B+树,只不过联合索引的健值数量不是一个,而是多个。构建一颗B+树只能根据一个值来构建,因此数据库依据联合索引最左的字段来构建B+树。
例子:假如创建一个(a,b)的联合索引,那么它的索引树是这样的
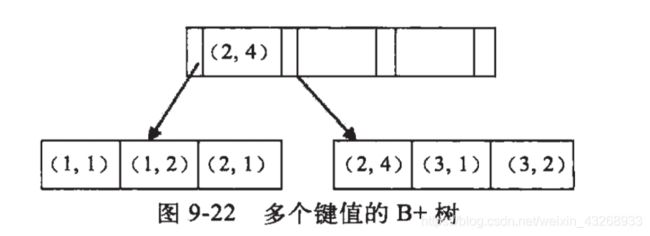
可以看到a的值是有顺序的,1,1,2,2,3,3,而b的值是没有顺序的1,2,1,4,1,2。所以b = 2这种查询条件没有办法利用索引,因为联合索引首先是按a排序的,b是无序的。
同时我们还可以发现在a值相等的情况下,b值又是按顺序排列的,但是这种顺序是相对的。所以最左匹配原则遇上范围查询就会停止,剩下的字段都无法使用索引。例如a = 1 and b = 2 a,b字段都可以使用索引,因为在a值确定的情况下b是相对有序的,而a>1and b=2,a字段可以匹配上索引,但b值不可以,因为a的值是一个范围,在这个范围中b是无序的。
9. explain命令详解
