Swin Transformer
一,原理介绍:
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows,绕不开的baseline,多模态
用有新意的方法有效的解决一个研究问题
(1)Swin Transformer 整体架构
Swin Transformer与VIT模型不同之处在于:1,金字塔形状,感受野是在不断变大的。Swin Transformer的feature map是有层次性的。2,注意力机制放在一个窗口内部(可以减少计算量 )。
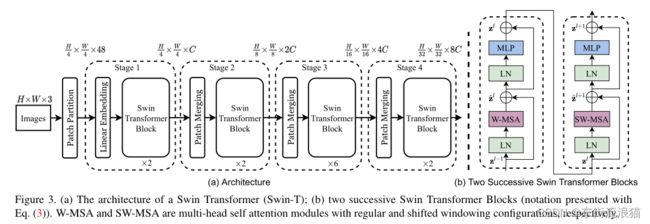
上图是Swin Transformer的整体架构图,输入是一个H*W*3的图像,假设图像长为224个像素点,宽是224个像素点,通道数为3,输入图片就是224*224*3。经过Patch Partition以后图像变成(224/4)*(224/4)*(4*4*3)的尺寸,Patch Partition这一层具体实现过程下面描述。然后经过Linear Embedding层,这一层作用就是将图像的通道数映射到规定的大小即将通道数48映射到C(C超参数是自己规定的)假设这里C为96,图像尺寸就变成(224/4)*(224/4)*(96)。经过Swin Transformer Block这一层并不会改变图像的尺寸大小还是(224/4)*(224/4)*(96)。具体架构如上图右边出现的,他是成双出现的,先经过W-MSA(窗口自注意力机制),后经过SW-MSA(移动窗口自注意力机制),具体下面介绍。后经过Patch Merging,将图像的大小改成(224/8)*(224/8)*(96*2)。Patch Merging(作用就是缩小分辨率,增大感受野)如何实现的也在下面详细介绍。

上图是论文中的模型公式。
(2)Patch Partition实现过程

假设Patch size=4,则通过一个4*4的小窗口对图像进行划分,如上图所示,然后将4*4小窗口内的像素点展平,使得通道数变成(4*4*3)图像长宽就变成H/4,W/4。
(3)Swin Transformer Block中的相对位置编码
原始的Transformer中的位置编码是在Input Emebeding后加入一个绝对的位置编码,并不是每一次都加入位置编码。在VIT中则是通过一维索引得到学习的位置编码。Swin Transformer的位置编码放在了attention矩阵中,并且Swin Transformer使用的相对位置编码。下图公式中B就是所加相对位置编码。
![]()
假设W-MSA的窗口大小是7*7,则窗口内一共有49个像素,则QKT的矩阵形状就应该是49*49,表示每个像素点对包括自身的每个像素点的相似性,则B的形状也应该是49*49。

在这里为了理解我们简化W-MSA的窗口大小是2*2,经过上面描述可以知道得到的QKT的矩阵形状就应该是4*4(上图右下角所示),因此B的大小也应该是4*4。左上角是一个二维的位置展开,第一行以第一个元素为中心([0,0],[0,1],[0,2],[0,3]表示2*2的矩阵相对于第一个元素的二维位置表示),第二行以第二个元素为中心,以此类推。由于我们需要得到索引从而得到位置信息,因此相对位置信息加上M-1,然后再在0纬度上*(2M-1),最后相对位置1纬度与0纬度相加得到值为索引(不直接0纬度与1纬度相加原因是一方面直接相加可能出现负数,另一方面可能不同位置相加后得到的索引值相同),最后通过索引值查找索引表中位置信息。索引表的大小是(2M-1)*(2M-1)相对位置索引的范围是(-M+1)到(M-1),行索引的范围是2M-1,同时列索引的范围是2M-1,一共(2M-1)*(2M-1)个索引。
(4)Swin Transformer Block中W-MSA(窗口自注意力机制)
对于普通的MSA模块,会对每一个patch求Q,K,V。会与其他每一个patch进行沟通,W-MSA会将feature map 划分为一个一个小窗口。优点就是可以减少计算量,但缺点就是窗口之间无法进行信息交互,导致感受野变小。
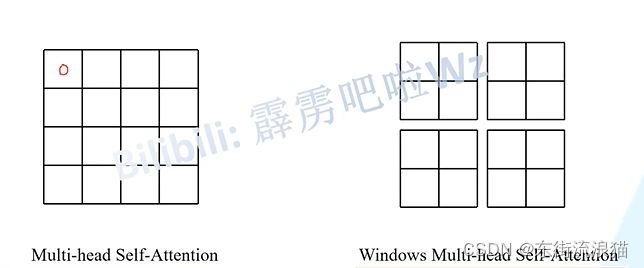
(5)Swin Transformer Block中SW-MSA(移动窗口自注意力机制)
使用窗口注意力机制存在问题就是,不同窗口之间不能交互,因此论文中提出SW-MSA(移动窗口自注意力机制)

为了方便理解移动窗口注意力机制,我们假设一张图片的大小为56*56,长宽的像素值都是56,我们将图像的上面三层像素移动到图像下方,同理将左面的3层像素点移动到最右边,如上图红色区域。红色区域与其余部分是不相邻的,所以在同一窗口进行MSA是不合理的。如上图的4,5,7,8是不相邻的。因此使用MASK 。

如何使用MASK,以4,5,7,8为例,我们将对应位置相减,得到矩阵,0的位置表示相邻位置的元素,非0表示不相邻位置的元素。 0位置置为0,非零职位负无穷,加到QKT。如下如所示。

(6)Patch Merging
通过降采样,在行方向与列方向,间隔取2,然后在深度上进行拼接(concat)通道维度变成原来的4倍,在channel方向进行layernorm,接一个linear channel转成两倍。经过Patch Merging,原图像的高和宽减半,channel变成两倍。

(7)Swin Transformer的复杂度

(1)代表的是原始Transformer的复杂度,(2)代表的是Swin Transformer的复杂度。图像X的维度是(HW,C),X经过一个Linear层得到Q,K,V矩阵(Q=X*Wq;K=X*Wk;V=X*Wv)W矩阵的维度是(C,C)因此这部分复杂度就是3hwc*c,然后计算QKT,复杂度就是hw*hw*c,softmax之后乘v得到z矩阵,复杂度为hw*hw*c,后z乘Wz得到最后输出,复杂度是hwc*c,这层是linear层的映射,将第一个公式中HW替换成MM,(窗口的高和宽)一共有H/M,W/M个window。
二,代码简介:
源码的实现是按照下图红框分别实现的。

第一个红框是通过PatchEmbed类进行实现。
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x
def flops(self):
Ho, Wo = self.patches_resolution
flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops下图代码块是窗口注意力机制的代码块
class WindowAttention(nn.Module):
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def extra_repr(self) -> str:
return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'
下面代码介绍attention 中mask矩阵的形成过程
if self.shift_size > 0:
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),#分片
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0 #对不同片加值
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) #窗口值相减
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask)论文地址:https://arxiv.org/pdf/2103.14030.pdf
源码地址:https://github.com/microsoft/Swin-Transformer