python语音识别预处理_语音处理(python)
写在前面
本篇文章主要分以下三个部分讲述:wav语音的格式及其内容
语音的预处理
语音的特征及特征提取
语音的格式及其内容
首先了解以下wav文件的主要规范格式注释:RIFF全称为资源互换文件格式(Resources Interchange File Format),是Windows下大部分多媒体文件遵循的一种文件结构。RIFF文件所包含的数据类型由该文件的扩展名来标识,能以RIFF格式存储的数据有:wav、avi、RID等。
根据RIFF规范,对于一个wav格式的语音,一般含有以下的几个要素:ChunkID:块号
ChunkSize:块大小
Format:格式
AudioFormat:音频格式
NumChannels:通道数
SampleRate:采样率
ByteRate:速率
Chunk是RIFF文件的基本单元,其基本结构如下:
struct chunk
{
uint32_t id; // 块标志 uint32_t size; // 块大小 uint8_t data[size]; // 块数据};
具体介绍可看:RIFF和WAVE音频文件格式 - Brook_icv - 博客园www.cnblogs.com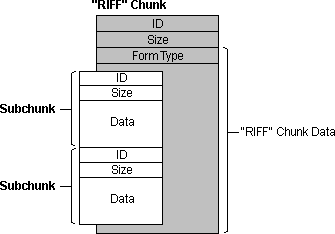
你也可以使用C语音对wav音频进行简单的测试:
#include #include #include
struct WAV_Format {
uint32_t ChunkID;/* "RIFF" */
uint32_t ChunkSize;/* 36 + Subchunk2Size */
uint32_t Format;/* "WAVE" */
/* sub-chunk "fmt" */
uint32_t Subchunk1ID;/* "fmt " */
uint32_t Subchunk1Size;/* 16 for PCM */
uint16_t AudioFormat;/* PCM = 1*/
uint16_t NumChannels;/* Mono = 1, Stereo = 2, etc. */
uint32_t SampleRate;/* 8000, 44100, etc. */
uint32_t ByteRate;/* = SampleRate * NumChannels * BitsPerSample/8 */
uint16_t BlockAlign;/* = NumChannels * BitsPerSample/8 */
uint16_t BitsPerSample;/* 8bits, 16bits, etc. */
/* sub-chunk "data" */
uint32_t Subchunk2ID;/* "data" */
uint32_t Subchunk2Size;/* data size */
};
int main(void)
{
FILE *fp = NULL;
struct WAV_Format wav;
fp = fopen("audio.wav", "rb");
if (!fp) {
printf("can't open audio file\n");
exit(1);
}
fread(&wav, 1, sizeof(struct WAV_Format), fp);
printf("ChunkID\t%x\n", wav.ChunkID);
printf("ChunkSize\t%d\n", wav.ChunkSize);
printf("Format\t\t%x\n", wav.Format);
printf("Subchunk1ID\t%x\n", wav.Subchunk1ID);
printf("Subchunk1Size\t%d\n", wav.Subchunk1Size);
printf("AudioFormat\t%d\n", wav.AudioFormat);
printf("NumChannels\t%d\n", wav.NumChannels);
printf("SampleRate\t%d\n", wav.SampleRate);
printf("ByteRate\t%d\n", wav.ByteRate);
printf("BlockAlign\t%d\n", wav.BlockAlign);
printf("BitsPerSample\t%d\n", wav.BitsPerSample);
printf("Subchunk2ID\t%x\n", wav.Subchunk2ID);
printf("Subchunk2Size\t%d\n", wav.Subchunk2Size);
fclose(fp);
return 0;
}
语音的预处理
在深度学习中,语音的输入都是根据需要经过以下处理:分帧和加窗
预加重
过零率
短时能量
下面通过问答形式简要讲述以上的几种语音处理,以及如何用python进行以上的语音处理。
分帧&加窗(hamming窗)
Q:什么是分帧和加窗?
A:
分帧:CHUNK短时分析将语音流分为一帧来处理,帧长:10~30ms,20ms常见;
帧移:STRIDE,0~1/2帧长,帧与帧之间的平滑长度;
加窗:与一个窗函数相乘,以此进行傅立叶展开。
窗函数:一般具有低通特性,分成以下几种类型矩形窗:主瓣宽度最小,旁瓣高度最高,会导致泄漏现象。
汉明窗:主瓣最宽,旁瓣高度最低,可以有效克服泄漏现象,具有更平滑的低通特性。
Q:为什么要对语音进行分帧和加窗?
A:分帧:
由于语音信号是一个非平稳态过程,不能用处理平稳信号的信号处理技术对其进行分析处理。但由于语音信号本身但特点,在10~30ms但短时间范围内,其特性可以看作是一个准稳态过程,即具有短时性。加窗:
对语音进行加窗主要有两个目的:使全局更加连续,避免出现吉布斯效应;
加窗时,原本没有周期性的语音信号呈现出周期函数的部分特征。PS:吉布斯效应:将具有不连续点的周期函数(如矩形脉冲)进行傅立叶级数展开后,选取有限项进行合成。当选取的项数越多,在所合成的波形中出现的峰起越靠近原信号的不连续点。当选取的项数很大时,该峰起值趋于一个常数,大约等于总跳变值的9%。这种现象称为吉布斯效应。
Q:怎样进行分帧和加窗?
A:
# 分帧处理函数
def enframe(wavData, frameSize, overlap):
coeff = 0.97#预加重系数
wlen = len(wavData)
step = frameSize - overlap
frameNum:int = math.ceil(wlen / step)
frameData = np.zeros((frameSize, frameNum))
#汉明窗
hamwin = np.hamming(frameSize)
for i in range(frameNum):
singleFrame = wavData[np.arange(i * step, min(i * step+frameSize,wlen))]
singleFrame = np.append(singleFrame[0], singleFrame[:-1] - coeff*singleFrame[1:])#预加重
frameData[:len(singleFrame),i] = singleFrame
frameData[:,i] = hamwin * frameData[:,i]#加窗
return frameData
预加重
Q:什么是预加重?
A:预加重即对语音的高频部分进行加重。
Q:为什么要对语音进行预加重处理?
A:为了去除口唇辐射的影响,增加语音的高频分辨率。
Q:怎样预加重?
A:一般采取一阶FIR高通数字滤波器来实现预加重,公式如下:
其中a为预加重系数,0.9
过零率
Q:什么是短时过零率?
A:短时过零率可以看作信号频率的简单度量过零就是指信号通过零值。过零率就是每秒内信号通过零值的次数。
对于离散时间序列,过零则是指序列取样值改变符号,过零率则是每个样本改变符号的次数。
Q:为什么要对过零短时语音进行处理?
A:由于短时过零率很容易受到低频的干扰,因此,在计算时,加上门限,来过滤掉低频带来的影响。一般来讲,浊音时能量集中于较低频率段内,具有较低的过零率,而清音时能量集中于较高频率段内,具有较高的过零率。
Q:如何计算过零率?
A:
# 计算每一帧的过零率
def ZCR(frameData):
frameNum = frameData.shape[1]
frameSize = frameData.shape[0]
zcr = np.zeros((frameNum,1))
for i in range(frameNum):
singleFrame = frameData[:,i]
temp = singleFrame[:frameSize-1]*singleFrame[1:frameSize]
temp = np.sign(temp)
zcr[i] = np.sum(temp<0)
return zcr
短时能量
Q:什么是短时能量?
A:语音的短时能量即每一帧语音包含的能量。
Q:为什么要计算短时能量?
A:可以通过短时能量分析去除高频环境噪声的干扰。语音和噪声的区别可以体现在他们的能量上,语音段的能量比噪声段的能量大,如果环境噪声和系统输入的噪声比较小,只要计算输入信号的短时能量就可以把语音段和噪声背景区分开来。同时,基于能量的算法还可以用来检测浊音,通常效果也是比较理想的。
Q:如何计算短时能量?
A:
# 计算每一帧能量
def energy(frameData):
frameNum = frameData.shape[1]
ener = np.zeros((frameNum,1))
for i in range(frameNum):
singleframe = frameData[:,i]
ener[i] = sum(singleframe * singleframe)
return ener
小结:短时能量可以和短时过零率近似为互补,短时能量大的地方过零率小,短时能量小的地方过零率较大。
语音的特征及其提取MFCC:Mel Frequency Cepstral Coefficents
Mel频率分析就是基于人类听觉感知实验的。实验观测发现人耳就像一个滤波器组一样,它只关注某些特定的频率分量(人的听觉对频率是有选择性的)。Fbank:FilterBank
人耳对声音频谱的响应是非线性的,Fbank就是一种前端处理算法,以类似于人耳的方式对音频进行处理,可以提高语音识别的性能。语谱图:Spectrogram
语谱图的x是时间,y轴是频率,z轴是幅度。幅度用亮色如红色表示高,用深色表示低。利用语谱图可以查看指定频率端的能量分布。
MFCC和Fbank特征
from python_speech_features import mfcc
from python_speech_features import logfbank
import scipy.io.wavfile as wav
import matplotlib.pyplot as plt
audio_name = "audio.wav"
samplimg_freq, audio = wav.read(audio_name)
mfcc_features = mfcc(audio,samplimg_freq)
fbank_features = logfbank(audio,samplimg_freq)
print('MFCC:number of win=',mfcc_features.shape[0])
print('MFCC:length of each feature=',mfcc_features.shape[1])
print('Fbank:number of win=',fbank_features.shape[0])
print('Fbank:length of each feature=',fbank_features.shape[1])
mfcc_features = mfcc_features.T
plt.matshow(mfcc_features)
plt.title('MFCC')
fbank_features = fbank_features.T
plt.matshow(fbank_features)
plt.title('Filter bank')
plt.show()MFCCFbank
结果:
MFCC:number of win= 291
MFCC:length of each feature= 13
Fbank:number of win= 291
Fbank:length of each feature= 26
语谱图
import math
import nump, wave
import matplotlib.pyplot as plt
import numpy as np
import os
filename = 'audio.wav'
= wave.open(filename,'rb')
params = f.getparams()
nchannels, sampwidth,framerate, nframes = params[:4]
strData = f.readframes(nframes)
waveData = np.fromstring(strData, dtype = np.int16) #将字符串转化为int
waveData = waveData * 1.0 / max(abs(waveData)) #幅值归一
waveData = np.reshape(waveData, [nframes, nchannels]).T
f.close()
plt.specgram(waveData[0], Fs = framerate, scale_by_freq=True, sides='default')
plt.ylabel('Frequency')
plt.xlabel('Time(s)')
plt.show()语谱图
比较几种特征MFCC特征提取是在FBank特征的基础上再进行离散余弦变换, 因此前面几步和FBank一样。
计算量:MFCC是在FBank的基础上进行的,所以MFCC的计算量更大。
特征区分度:FBank特征相关性较高,MFCC具有更好的判别度,这也是在大多数语音识别论文中用的是MFCC,而不是FBank的原因。
Reference