ElasticSearch个人学习笔记 狂神说
ES安装
介绍:ELK是Elasticsearch、Logstash、Kibana的合体,市面上也成为Elastic Stack,是一个日志分析架构技术栈总称
声明:JDK版本1.8+才可以
安装:ElasticSearch客户端、可视化界面,整合的时候版本要对应
1.下载es
官网:https://www.elastic.co/cn/
华为云镜像:
ElasticSearch: https://mirrors.huaweicloud.com/elasticsearch/?C=N&O=D
logstash: https://mirrors.huaweicloud.com/logstash/?C=N&O=D
kibana: https://mirrors.huaweicloud.com/kibana/?C=N&O=D
暂时先下载了7.6.2版本
修改配置文件
修改jvm的内存为256m 初始是1g
运行elasticsearch.bat
访问localhost:9200

2. 安装可视化界面es head
网址:https://github.com/mobz/elasticsearch-head
# Running with built in server
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head`
npm install
npm run start
`open` http://localhost:9100/
This will start a local webserver running on port 9100 serving elasticsearch-head
# Running with docker
for Elasticsearch 5.x: `docker run -p 9100:9100 mobz/elasticsearch-head:5`
for Elasticsearch 2.x: `docker run -p 9100:9100 mobz/elasticsearch-head:2`
for Elasticsearch 1.x: `docker run -p 9100:9100 mobz/elasticsearch-head:1`
for fans of alpine there is `mobz/elasticsearch-head:5-alpine`
`open` http://localhost:9100/
此时打开控制台,发现报跨域错误
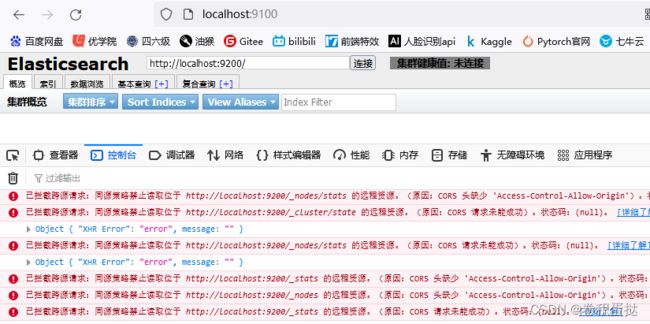
配置跨域
打开elasticsearch.yml,输入
http.cors.enabled: true
http.cors.allow-origin: "*"
配置完成后将显示es节点
新建索引
索引当成一个数据库, 文档当成库里的数据,这个head当成一个数据展示工具,后面所有的查询操作都在Kibana中进行

3. 安装Kibana
网址:kibana: https://mirrors.huaweicloud.com/kibana/?C=N&O=D
版本要和ES版本一致
-
启动比较耗时,访问localhost:5601
-
打开Dev tools页面,可以测试连接
-
汉化:打开kibana.yml,添加i18n.locale: “zh-CN”
ES核心概念
1. 总体概述
Elasticsearch是面向文档的,ES中的一切都是JSON。关系型数据库 和 Elasticsearch对比:

Mysql存数据:建库 – 建表 – 建行(对应具体数据) – 写入字段
ES存数据:建索引 – 建立types(慢慢被弃用) – 创建文档(对应具体数据)
物理设计:
ES在后台把每个索引划分成多个分片,每个分片可在集群中不同的服务器之间迁移,他一个人就是一个集群,不存在单个的ES
逻辑设计:
一个索引类型包含多个文档:文档1、文档2.当索引一篇文档时,可通过这样的顺序找到他:索引 – 类型 – 文档ID,通过这个组合我们就能所引导某个具体的文档。
2. 文档
文档就是一条条数据,类似行:
user:
1 zhangsan 18
2 wangwu 19
3 zhaoliu 20
ES是面向文档的,所以索引搜索数据的最小单位就是文档。文档重要属性:
- 自我包含,一篇文章同时包含字段和对应的值,即包含key:value
- 可以使层次型的,一个文档中包含文档,复杂的逻辑实体就是这么来的
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
3. 类型
类型是文档的逻辑容器,类似表,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如name映射为字符串类型。我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?
- elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整形。但是elasticsearch也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用。
4. 索引
索引是映射类型的容器,类似数据库, elasticsearch中的索引是一个非常大的文档集合。 索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的。
5. 物理设计:节点和分片 如何工作
创建新索引

一个集群至少有一个节点,而一个节点就是一个elasricsearch进程,节点可以有多个索引默认的,如果你创建索引,那么索引将会有个5个分片(primary shard ,又称主分片)构成的,每一个主分片会有一个副本(replica shard,又称复制分片)

上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于失。实际上,一个分片是一个Lucene索引(一个ElasticSearch索引包含多个Lucene索引) ,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。不过,等等,倒排索引是什么鬼?
6. 倒排索引
搜索的核心需求是全文检索,全文检索简单来说就是要在大量文档中找到包含某个单词出现的位置,在传统关系型数据库中,数据检索只能通过 like 来实现,例如需要在酒店数据中查询名称包含公寓的酒店,需要通过如下 sql 实现:
select * from hotel_table where hotel_name like '%公寓%';
这种实现方式实际会存在很多问题:
- 无法使用数据库索引,需要全表扫描,性能差
- 搜索效果差,只能首尾位模糊匹配,无法实现复杂的搜索需求
- 无法得到文档与搜索条件的相关性
正排索引:是以文档对象的唯一 ID 作为索引,以文档内容作为记录的结构。
倒排索引:Inverted index,指的是将文档内容中的单词作为索引,将包含该词的文档 ID 作为记录的结构。

例子
有两个文档
| 文档 id | content |
|---|---|
| 1 | 苏州街维亚大厦 |
| 2 | 桔子酒店苏州街店 |
生成倒排索引:
- 首先进行分词,这里两个文档包含的关键词有:苏州街、维亚大厦…
- 然后按照单词来作为索引,对应的文档 id 建立一个链表,就能构成上述的倒排索引结构。
| Word | 文档 id |
|---|---|
| 苏州街 | 1,2 |
| 维亚大厦 | 1 |
| 维亚 | 1 |
| 桔子 | 2 |
| 酒店 | 2 |
| 大赛 | 1 |
有了倒排索引,能快速、灵活地实现各类搜索需求。整个搜索过程中我们不需要做任何文本的模糊匹配。
例如,如果需要在上述两个文档中查询 苏州街桔子 ,可以通过分词后 苏州街 查到 1、2,通过 桔子 查到 2,然后再进行取交取并等操作得到最终结果。
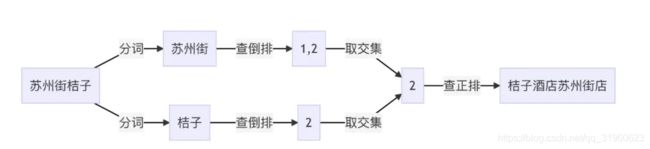
在ES中,索引(库)被分为多个分片,每个分片是一个Lucene的索引。所以一个ES索引是由多个Lucene索引组成的
IK分词器
1. 配置
-
下载网址:https://github.com/medcl/elasticsearch-analysis-ik/releases
-
新建文件夹“ik”,放到es的plugin文件夹中,将文件解压到ik里
-
重启es
-
可以通过elasticsearch-plugin list命令查看加载的插件
2. 测试
有两种模式:ik_smart(最少切分) 和 ik_max_word(最细粒度划分)
GET _analyze
{
"analyzer": "ik_smart",
"text": "中国共产党"
}
//结果
{
"tokens" : [
{
"token" : "中国共产党",
"start_offset" : 0,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 0
}
]
}
GET _analyze
{
"analyzer": "ik_max_word",
"text": "中国共产党"
}
//结果
{
"tokens" : [
{
"token" : "中国共产党",
"position" : 0
},
{
"token" : "中国",
"position" : 1
},
{
"token" : "国共",
"position" : 2
},
{
"token" : "共产党",
"position" : 3
},
{
"token" : "共产",
"position" : 4
},
{
"token" : "党",
"position" : 5
}
]
}
3. 添加自定义词汇到词典中
elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
<properties>
<comment>IK Analyzer 扩展配置comment>
<entry key="ext_dict">herb_names.dicentry>
<entry key="ext_stopwords">entry>
properties>
elasticsearch/plugins/ik/config/herb_names.dic
麻黄
桂枝
荆芥
...
REST风格操作
基本Rest命令说明
| method | url地址 | 描述 |
|---|---|---|
| PUT(创建,修改) | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST(创建) | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST(修改) | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE(删除) | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET(查询) | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档ID |
| POST(查询) | localhost:9200/索引名称/类型名称/文档id/_search | 查询所有数据 |
测试
1. 创建索引
Deprecation: [types removal] Specifying types in document index requests is deprecated, use the typeless endpoints instead (/{index}/doc/{id}, /{index}/doc, or /{index}/_create/{id}).
//已弃用方式:
PUT /test1/type1/1
{
"name" : "流柚",
"age" : 18
}
//替换:
PUT /test1/_doc/1
{
"name": "流油",
"age": 18
}
结果:

2. 字段数据类型
- 字符串类型
- text、keyword
- text:支持分词,全文检索,支持模糊、精确查询,不支持聚合,排序操作;text类型的最大支持的字符长度无限制,适合大字段存储;
- keyword:不进行分词,直接索引、支持模糊、支持精确匹配,支持聚合、排序操作。keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
- text、keyword
- 数值型
- long、Integer、short、byte、double、float、half float、scaled float
- 日期类型
- date
- te布尔类型
- boolean
- 二进制类型
- binary
- 等等…
3. 指定字段的类型
设置规则
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
},
"birthday": {
"type": "date"
}
}
}
}
通过GET获取建立的规则
GET /test2
添加数据
PUT /test2/_doc/1
{
"name": "这里就叫卢本伟广场好了",
"age": 19,
"birthday": "2022-12-19"
}
如果自己的文档字段没有被指定,那么ElasticSearch就会给我们默认配置字段类型
扩展:通过GET _cat/xx 可以获取ElasticSearch的当前的很多信息!
GET _cat/indices
GET _cat/aliases
GET _cat/allocation
GET _cat/count
GET _cat/fielddata
GET _cat/health
GET _cat/indices
GET _cat/master
GET _cat/nodeattrs
GET _cat/nodes
GET _cat/pending_tasks
GET _cat/plugins
GET _cat/recovery
GET _cat/repositories
GET _cat/segments
GET _cat/shards
GET _cat/snapshots
GET _cat/tasks
GET _cat/templates
GET _cat/thread_pool
4. 修改
- 旧的方法(使用put覆盖原来的值)
- 版本+1(_version)
- 但是如果漏掉某个字段没有写,那么更新是没有写的字段 ,会消失
PUT /test2/_doc/1
{
"name": "这里就叫卢本伟广场",
"birthday": "2022-12-19"
}
es-head中对应记录的age字段消失
- 新的方法(使用post的update)
- version不会改变
- 需要注意doc
- 不会丢失字段
POST /test2/_doc/2/_update
{
"doc": {
"age": 122,
"birthday": "1919-10-10"
}
}
没有指定"name"并不会导致他的“name”丢失

5. 删除
删除索引
DELETE /test1
删除文档
DELETE /test2/_doc/1
6. 查询
- 简单查询
GET /test2/_doc/_search?q=birthday:2022-12-19
- 匹配查询
match:匹配(会使用分词器解析(先分析文档,然后进行查询))_source:过滤字段,即要获取的字段sort:排序form、size分页
GET /test2/_doc/_search (现在不用写_doc,直接GET /test2/_serach 就行)
{
"query": {
"match": {
"name": "中国饭"
}
},
"_source": [ //获取name 和 age
"name",
"age"
],
"sort": [
{
"age": {
"order": "asc"
}
}
],
"from": 0, //from是第几个开始 不是第几页
"size": 15 //一页多少个
}
匹配的方法与sql的like不同

- 多条件查询(bool)
must相当于andshould相当于ormust_not相当于not (... and ...)filter过滤
GET /test2/_search
{
"query":{
"bool": {
"must": [
{
"match": { "birthday": "2022-12-19" }
}
],
"should": [
{
"match": { "name": "这里就叫卢本伟广场" }
},
{
"match": { "name": "吃" }
}
],
"filter": {
"range": {
"age": { "gte": 0, "lte": 120 }
}
}
}
}
}
- 匹配数组
- 可以多关键字查(空格隔开)— 匹配字段也是符合的
match会使用分词器解析(先分析文档,然后进行查询)- 搜词
先创建这样的文档
PUT /test1/_doc/1
{
"id": "10001",
"name": "麻黄散",
"ingredient": [
"当归", "吴茱萸", "大黄"
]
}
再进行查询
GET /test1/_search
{
"query":{
"match":{
"ingredient":"白术 当归 大黄 仓鼠" //默认将所有结果or起来
}
}
}
结果
"hits" : [
{
"_id" : "6",
"_score" : 4.2601705,
"_source" : { "id" : "10006", "name" : "药方6", "ingredient" : ["当归","白术","大黄"] }
},
{
"_id" : "1",
"_score" : 3.0661612,
"_source" : { "id" : "10001", "name" : "麻黄散", "ingredient" : ["当归","吴茱萸","大黄"] }
},
{
"_id" : "5",
"_score" : 1.7683537,
"_source" : { "id" : "10005", "name" : "药方5", "ingredient" : ["大黄","龙胆草","木香"] }
},
{
"_id" : "2",
"_score" : 1.2978076,
"_source" : { "id" : "10002", "name" : "药方2", "ingredient" : ["百合","当归","浙贝母"] }
},
{
"_id" : "3",
"_score" : 1.1404719,
"_source" : { "id" : "10003", "name" : "药方3", "ingredient" : ["白术","百合"] }
}
]
- 精确查询
term直接通过 倒排索引 指定词条查询- 适合查询 number、date、keyword ,不适合text
// 精确查询(必须全部都有,而且不可分,即按一个完整的词查询)
// term 直接通过 倒排索引 指定的词条 进行精确查找的
GET /test1/_search
{
"query":{
"term":{
"ingredient": "白" //这里用白能搜出来,但是白术就搜不出来了,是中文分词的问题
//用match_phrase代替term 或 修改索引中ingredient的analyzer为ik
}
}
}
text在查询时会被分词器分析,keyword整体进行查询不分词
手动指定类型为keyword
PUT /test3
{
"mappings": {
"properties": {
"name": { "type": "text" },
"id": { "type": "long" },
"ingredient": { "type": "keyword" }
}
}
}
插入数据
PUT /test3/_doc/1
{
"name": "中药1",
"id": 121,
"ingredient": [ "白术", "当归", "浙贝母" ]
}
查询数据
//单独查询一个关键词
GET /test3/_search
{
"query": {
"term": {
"ingredient": "白术" //白术能查出来,白、白术1查不出来
}
}
}
//查询多个关键词
// 1.只要包含里面的其中一个都会被查出来,所有记录score都为1
GET /test3/_search
{
"query": {
"terms": {
"ingredient": ["白术", "麻药", "的使劲地发"]
}
}
}
// 2.需要包含所有指定的词
GET /test3/_search
{
"query": {
"bool": {
"must": [
{ "term": { "ingredient": "白术" } },
{ "term": { "ingredient": "麻药" } }
]
}
}
}
// 3.包含其中一个就可以,包含的越多score越高
GET /test3/_search
{
"query": {
"bool": {
"should": [
{ "term": { "ingredient": "白术" } },
{ "term": { "ingredient": "麻药" } },
{ "term": { "ingredient": "吴恩达" } }
]
}
}
}
设置为keyword后,不管查询方式是match还是term,如果不完全相等都不会被查出来,查询”白术“时,“白术1”就查不出来,这是由keyword的性质决定的,不取决于查询的方式。而在之前未指定keyword的例子中,查询 “白术1”、“白魔术” 都是可以查出来的。
- 模糊查询
wildcard查询条件分词模糊查询regexp正则查询prefix前缀查询
GET /test3/_search
{
"query": {
"wildcard": {
"ingredient": "白*" //查出白 白术 白术1 白芷
}
}
}
GET /test3/_search
{
"query": {
"wildcard": {
"ingredient": "白??" //查出白术1
}
}
}
不要在搜索字段的前面加通配符,不然会像数据库一样扫描一遍整个表去匹配数据
7. 高亮
可以设置高亮,让查询到的字词凸显出来
GET /test1/_search
{
"query":{
"match":{
"ingredient":"白术 当归"
}
},
"highlight": {
"pre_tags": "", //指定前缀 默认
"post_tags": "", //指定后缀 默认
"fields": {
"ingredient": {} //指定高亮字段
}
}
}
结果
{
"_id" : "6",
"_score" : 2.3712473,
"_source" : {
"id" : "10006",
"name" : "药方6",
"ingredient" : [ "当归", "白术", "大黄" ]
},
"highlight" : {
"ingredient" : [
"当归",
"白术"
]
}
}
8. 最小匹配度
当输入一串很长的文本,使用match对其进行搜索时,会搜出来一大堆不相关的东西。
比如输入 “福曦堂 四川白芍 生白芍 白芍片 芍药 中药材 可磨白芍粉也可搭配川芎 当归使用 精选货 白芍250克*1罐 福曦堂 四川白芍 生白芍 白芍片 芍药 中药材 可磨白芍粉也可搭配川芎 当归使用 精选货 白芍”,搜索结果:
"hits" : {
"total" : {
"value" : 263, // 搜到了好多没用的
"relation" : "eq"
},
"max_score" : 229.36502,
"hits" : [
...
]
}
highlight一下看一下那些不相关的他怎么匹配的

所以我们使用minimum_should_match来过滤一些无关内容。
当搜索“Sip on La Croix”时,分词器会将其解析成:
{
"bool": {
"should": [
{ "term": { "body": "Sip"}},
{ "term": { "body": "on"}},
{ "term": { "body": "La"}},
{ "term": { "body": "Croix"}},
]
}
}
当我们指定minimum_should_match后,他会根据你指定的值来进行结果的筛选。具体如下图
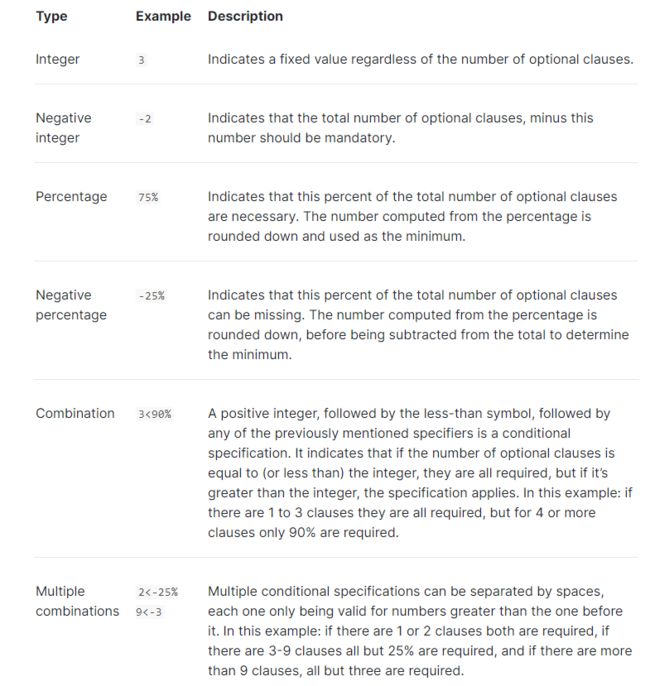
使用
GET /goods-temp/_search
{
"query": {
"match": {
"title": {
"query": "福曦堂 四川白芍 生白芍 白芍片 芍药 中药材 可磨白芍粉也可搭配川芎 当归使用 精选货 白芍250克*1罐 福曦堂 四川白芍 生白芍 白芍片 芍药 中药材 可磨白芍粉也可搭配川芎 当归使用 精选货 白芍",
"minimum_should_match": "4<40%"
}
}
}
}
//结果
"hits" : {
"total" : {
"value" : 7,
"relation" : "eq"
},
"max_score" : 229.36502,
"hits" : [
{
"_score" : 229.36502,
"_source" : { "title" : "福曦堂 四川白芍 生白芍 白芍片 芍药 中药材 可磨白芍粉也可搭配川芎 当归使用 精选货 白芍250克*1罐 福曦堂 四川白芍 生白芍 白芍片 芍药 中药材 可磨白芍粉也可搭配川芎 当归使用 精选货 白芍250克*1罐" }
},
{
"_score" : 67.59854,
"_source" : { "title" : "京东超市 福东海 川芎片250克/袋 中药材当归白芍川芎粉熟地四物汤原料川穹 川芎茶 【五一秒杀特惠,2件9折】宁夏原产红枸杞500克2件到手均件价35.9元!上浮率92%以上,大颗足干,新鲜无硫,活动时间:5月2日20点-3日20点点击" }
},
{
"_score" : 67.06959,
"_source" : { "title" : "福曦堂土茯苓 四川土茯苓 中药材 土茯苓干货 精选货 土茯苓500克*1袋 福曦堂土茯苓 四川土茯苓 中药材 土茯苓干货 精选货 土茯苓500克*1袋" }
},
{
"_score" : 62.90972,
"_source" : { "title" : "北京同仁堂四物汤膏搭四物汤中药材颗粒汤包四君子汤搭当归白芍川芎熟地黄八珍膏补f气血不足月经不调怡福寿 1支装 北京同仁堂四物汤膏搭四物汤中药材颗粒汤包四君子汤搭当归白芍川芎熟地黄八珍膏补f气血不足月经不调怡福寿 1支装" }
},
{
"_score" : 58.995457,
"_source" : { "title" : "福曦堂沙苑子 沙苑蒺藜 沙菀子潼蒺藜可代磨沙苑子粉 中药材 沙苑子250克*1罐 福曦堂沙苑子 沙苑蒺藜 沙菀子潼蒺藜可代磨沙苑子粉 中药材 沙苑子250克*1罐" }
},
{
"_score" : 55.16248,
"_source" : { "title" : "福东海四物汤中药材当归熟地黄川穹白芍四物汤原料 4袋*10包(共400g) 超值特惠全店所有商品2件9折,活动时间4月26日-5月5日。热销产品买二送一···" }
},
{
"_score" : 49.526695,
"_source" : { "title" : "世斛堂 生何首乌片 四川何首乌中药材切片何首乌干片精选可泡水煮粥煲汤 何首乌-1000克 精选正品原料,保证质量售后,让购买放心无忧。" }
}
]
}
不过没有达到我想要的效果,以后再研究。
集成SpringBoot
SpringBoot: 2.2.1.RELEASE
ElasticSearch: 7.6.2
1. 创建空Maven项目,指定es的version
<properties>
<java.version>8java.version>
<elasticsearch.version>7.6.2elasticsearch.version>
properties>
2. 依赖
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.79version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
dependency>
dependencies>
3. 配置ElasticSearchClientConfig配置类,添加Bean
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")
)
);
return client;
}
}
4. 创建实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Prescription implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;
private String name;
private List<String> ingredient;
}
5. 测试
注入RestHighLevelClient
@Autowired
private RestHighLevelClient client;
1. 测试索引
创建索引
@Test
public void createIndex() throws IOException {
//配置索引
CreateIndexRequest request = new CreateIndexRequest("test4");
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println("是否创建成功:" + response.isAcknowledged());
System.out.println("返回对象:" + response);
client.close();
}
获取索引
@Test
public void queryIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("test4");
//是否存在:client.indices().exists(request, RequestOptions.DEFAULT);
GetIndexResponse response = client.indices().get(request, RequestOptions.DEFAULT);
System.out.println(response);
client.close();
}
删除索引
@Test
public void deleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("test4");
AcknowledgedResponse response = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(response);
client.close();
}
2. 文档操作
添加文档
- 添加单条记录
@Test
public void addDocument() throws IOException {
Prescription prescription = new Prescription();
prescription.setId(10009L);
prescription.setName("麻黄散他爹");
List<String> list = new ArrayList<>();
list.add("当归");
list.add("人参");
list.add("阿胶");
prescription.setIngredient(list);
IndexRequest request = new IndexRequest("test3"); //Index
request.id("9");
request.timeout(TimeValue.timeValueMillis(2000));
request.source(JSON.toJSONString(prescription), XContentType.JSON);
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
System.out.println(response.status());
client.close();
}
- 添加多条记录
@Test
public void addDocumentBatch() throws IOException {
BulkRequest request = new BulkRequest("test3"); //Global Index
List<Prescription> list = new ArrayList<>();
list.add(new Prescription(10L, "10", null));
list.add(new Prescription(11L, "11", null));
list.add(new Prescription(12L, "12", null));
list.add(new Prescription(13L, "13", null));
list.forEach(item -> {
request.add(new IndexRequest()
.id(item.getId().toString())
.source(JSON.toJSONString(item), XContentType.JSON));
});
BulkResponse response = client.bulk(request, RequestOptions.DEFAULT);
System.out.println(response.status());
client.close();
}
查找文档
@Test
public void getDocument() throws IOException {
GetRequest request = new GetRequest("test3", "9");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
System.out.println(response.getSourceAsString());
client.close();
}
更新文档
@Test
public void updateDocument() throws IOException {
UpdateRequest request = new UpdateRequest("test3", "9");
Prescription prescription = new Prescription();
//只对name进行更新,其他字段不会变
prescription.setName("卢本伟");
request.doc(JSON.toJSONString(prescription), XContentType.JSON);
UpdateResponse response = client.update(request, RequestOptions.DEFAULT);
System.out.println(response);
System.out.println(response.status());
client.close();
}
删除文档
@Test
public void deleteDocument() throws IOException {
DeleteRequest request = new DeleteRequest("test3", "9");
DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);
System.out.println(response);
client.close();
}
查询文档
@Test
public void searchDocument() throws IOException {
SearchRequest request = new SearchRequest("test3");
//查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//Term
TermQueryBuilder termQueryBuilder = new TermQueryBuilder("ingredient", "当归");
//Match
MatchQueryBuilder matchQueryBuilder = new MatchQueryBuilder("ingredient", "当归");
//HighLight
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("ingredient");
searchSourceBuilder.highlighter(highlightBuilder);
//Page
searchSourceBuilder.from(0);
searchSourceBuilder.size(10);
searchSourceBuilder.query(termQueryBuilder);
request.source(searchSourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
System.out.println(response.getHits().getTotalHits());
response.getHits().forEach(System.out::println);
client.close();
}
仿京东搜索
1. 解析京东网页获取数据放入ES
引入依赖
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.10.2version>
dependency>
创建HtmlContent类
@Data
@NoArgsConstructor
@AllArgsConstructor
public class HtmlContent implements Serializable {
private String title;
private String price;
private String img;
}
解析京东网页
public class HtmlParseUtil {
public static List<HtmlContent> parseJD(String keyword, int pageNum) {
List<HtmlContent> list = new ArrayList<>();
for (int i = 1; i <= pageNum; i++) {
String url = "https://search.jd.com/Search?keyword=#1&enc=utf-8&wq=#1&page=#2"
.replaceAll("#1", keyword)
.replaceAll("#2", String.valueOf(i));
Document doc = null;
try {
doc = Jsoup.parse(new URL(url), 3000);
} catch (IOException e) {
e.printStackTrace();
}
Element goodsList = doc.getElementById("J_goodsList");
Elements lis = goodsList.getElementsByTag("li");
for (Element li : lis) {
String img = li.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = li.getElementsByClass("p-price").eq(0).text();
String title = li.getElementsByClass("p-name").eq(0).text();
list.add(new HtmlContent(title, price, img));
}
}
return list;
}
}
配置ElasticSearchClientConfig
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
new HttpHost("localhost", 9200, "http")));
return client;
}
}
创建ContentService
@Service
public class ContentService {
@Autowired
RestHighLevelClient client;
/**
* 分析页面,将商品添加到ES中
* @param keyword 搜索关键词
* @param pageNum 搜索京东上几页的内容
* @return
*/
public Boolean addContent(String keyword, int pageNum) {
List<HtmlContent> list = HtmlParseUtil.parseJD(keyword, pageNum);
BulkRequest bulkRequest = new BulkRequest("goods");
list.forEach(content -> {
bulkRequest.add(new IndexRequest()
.source(JSON.toJSONString(content), XContentType.JSON));
});
try {
BulkResponse response = client.bulk(bulkRequest, RequestOptions.DEFAULT);
return !response.hasFailures();
} catch (IOException e) {
e.printStackTrace();
return false;
}
}
}
创建ContentController
@RestController
public class ContentController {
@Autowired
ContentService contentService;
@GetMapping("/add/{keyword}/{pageNum}")
public R addContent(@PathVariable String keyword, @PathVariable Integer pageNum) {
System.out.println("keyword: " + keyword + ", pageNum:" + pageNum);
Boolean flag = contentService.addContent(keyword, pageNum);
return flag ? R.ok() : R.error();
}
}
2. 搜索功能实现
Service
/**
* 检索功能
* @param keyword 搜索的关键词
* @param pageNo 第几页 最小为0
* @param pageSize 一页几个
* @param searchForContent 用于搜索框提示输入还是用于在页面上展示商品
* @return
*/
public Map<String, Object> search(String keyword, Integer pageNo, Integer pageSize, Boolean searchForContent) {
SearchRequest request = new SearchRequest("goods");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
if (!searchForContent) { //搜索框提示输入
//只需要获取title
searchSourceBuilder.fetchSource("title", null);
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
String[] keywords = keyword.split(" ");
for (String word : keywords) {
boolQueryBuilder.must(new MatchPhraseQueryBuilder("title", word));
}
searchSourceBuilder.query(boolQueryBuilder);
} else {
MatchQueryBuilder matchQueryBuilder = new MatchQueryBuilder("title", keyword);
matchQueryBuilder.minimumShouldMatch("2<50%");
searchSourceBuilder.query(matchQueryBuilder);
}
searchSourceBuilder.from(pageNo * pageSize);
searchSourceBuilder.size(pageSize);
searchSourceBuilder.highlighter(new HighlightBuilder()
.field("title")
.preTags(""
)
.postTags(""));
request.source(searchSourceBuilder);
try {
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
Map<String, Object> result = new HashMap<>();
List<Map<String, Object>> list = new ArrayList<>();
response.getHits().forEach(item -> {
Map<String, Object> map = item.getSourceAsMap();
// 返回文本设置高亮
Map<String, HighlightField> highlight = item.getHighlightFields();
HighlightField name = highlight.get("title");
if (name != null){
Text[] fragments = name.fragments();
StringBuilder new_name = new StringBuilder();
for (Text text : fragments) {
new_name.append(text);
}
map.put("title", new_name.toString());
}
list.add(map);
});
result.put("total", response.getHits().getTotalHits().value);
result.put("list", list);
return result;
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
Controller
@GetMapping("search/{keyword}/{pageNo}/{pageSize}")
public R search(@PathVariable String keyword, @PathVariable Integer pageNo,
@PathVariable Integer pageSize) {
return R.ok().data(contentService.search(keyword, pageNo, pageSize, true));
}
@GetMapping("searchList/{keyword}/{pageSize}")
public R searchList(@PathVariable String keyword, @PathVariable Integer pageSize) {
return R.ok().data(contentService.search(keyword, 0, pageSize, false));
}
3. 前端页面
引入js文件
写Html
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<script src="/js/vue.js">script>
<script src="/js/axios.js">script>
<script src="/js/jquery.js">script>
<style>
body {
margin: 0;
padding: 0;
}
.nav {
width: 700px;
margin: 20px auto;
position: relative;
}
.nav input {
outline: none;
margin: 0;
box-sizing: border-box;
width: 70%;
height: 50px;
font-size: 22px;
display: inline-block;
vertical-align: bottom;
border: 4px solid rgb(255, 0, 0)
}
.nav button {
margin-left: -5px;
width: 15%;
height: 50px;
box-sizing: border-box;
display: inline-block;
vertical-align: bottom;
font-size: 18px;
background: rgb(255, 0, 0);
color: white;
}
.nav ul {
position: absolute;
top: 50px;
left: 0;
width: 595px;
background: white;
box-sizing: border-box;
border: 1px solid black;
padding: 0;
margin: 0;
}
.nav li {
list-style: none;
border-bottom: 1px solid grey;
text-overflow: ellipsis;
word-break: break-all;
white-space: nowrap;
overflow: hidden;
margin: 0 5px;
height: 40px;
line-height: 40px;
font-size: 18px;
transition: .2s;
cursor: pointer;
}
.nav li:hover {
background: rgb(230, 230, 230);
}
.nav li .highlight {
color: red;
display: inline;
}
.nav li p {
margin: 0;
}
.main {
width: 90%;
margin: 20px auto;
display: flex;
justify-content: left;
flex-wrap: wrap;
}
.box {
border: 1px solid white;
width: 230px;
height: 300px;
margin: 5px;
box-sizing: border-box;
transition: .3s;
}
.box:hover {
box-shadow: 0px 0px 8px gray;
}
.box img {
width: 220px;
margin-left: 5px;
}
.price {
color: rgb(255, 31, 38);
font-size: 20px;
font-weight: 550;
margin: 0 10px;
}
.title {
margin: 0 5px;
display: -webkit-box;
-webkit-box-orient: vertical;
-webkit-line-clamp: 2;
overflow: hidden;
}
.title p {
display: inline;
}
.title .highlight {
color: red;
}
.footer {
width: 50%;
margin: 20px auto;
display: flex;
justify-content: center;
}
style>
head>
<body>
<div id="app">
<div class="nav">
<input type="text" id="search" v-model="keyword"
@focusin="showSearchList"
@focusout="() => {if(!this.focus)this.searchListVisible=false}"
@keyup="handleKeyUp"
>
<button @click="search(1)">搜索button>
<ul v-show="searchListVisible&&this.keyword" @mouseenter="()=>{this.focus=true}" @mouseleave="()=>{this.focus=false}">
<li v-for="item in searchList" v-html="item.title" @click="setKeyword(item.title)">li>
ul>
div>
<h1 style="text-align:center;margin-top:150px" v-if="!list[0]">暂无数据h1>
<div class="main">
<div class="box" v-for="goods in list">
<img v-bind:src="goods.img">
<p class="price" v-text="goods.price">¥122p>
<p class="title" v-bind:title="goods.title.replaceAll(/<.*?>/ig,'')" v-html="goods.title">标题p>
div>
div>
<div class="footer" v-if="list[0]">
<button @click="lastPage">上一页button>
<button v-for="i in pageNum" @click="search(i)" :disabled="i==pageNo">{{i}}button>
<button @click="nextPage">下一页button>
div>
div>
<script>
new Vue({
el: '#app',
data: {
keyword: '',
pageNo: 0,
pageSize: 30,
total: 0,
pageNum: 0,
list: [],
searchList: [],
searchListVisible: false,
focus: false,
compositionStart: false
},
created() {
},
mounted() {
$('#search').on('compositionstart', e => {
this.compositionStart = true
}).on('compositionend', e => {
this.compositionStart = false
this.updateSearchList()
})
},
methods: {
search(pageNo = 1) {
if (!this.keyword) {
return
}
this.pageNo = pageNo
axios.get(`search/${this.keyword}/${pageNo-1}/${this.pageSize}`).then(resp => {
this.list = resp.data.data.list
this.total = resp.data.data.total
this.pageNum = Math.max(Math.floor(this.total / this.pageSize), 1)
this.searchListVisible = false
}).catch(err => {
console.log(err)
})
},
showSearchList() {
if (this.keyword) {
this.searchListVisible = true
}
},
updateSearchList() {
if (this.keyword) { //有内容 去搜索
let pageSize = 10
axios.get(`searchList/${this.keyword}/${pageSize}`).then(resp => {
this.searchList = resp.data.data.list
this.searchListVisible = true
}).catch(err => {
console.log(err)
})
} else {
this.searchList = []
this.searchListVisible = false
}
},
handleKeyUp(e) {
if (e.keyCode == 13) { // 回车
this.search(1)
} else if (e.keyCode == 8) { // 删除
this.updateSearchList()
} else {
if (!this.compositionStart) {
this.updateSearchList()
}
}
},
setKeyword(keyword) {
this.keyword = keyword.replaceAll(/<.*?>/ig, '')
this.search()
},
lastPage() {
if (this.pageNo > 1) {
this.search(this.pageNo - 1)
}
},
nextPage() {
if (this.pageNo < this.pageNum) {
this.search(this.pageNo + 1)
}
}
}
})
script>
body>
html>
4. 最终效果
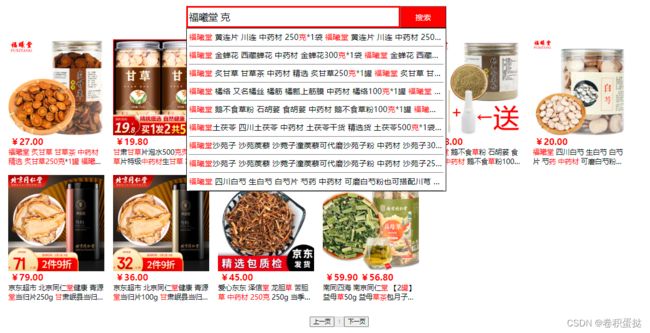
学到了 感谢狂神