动手学深度学习-pytorch版
Task 01
线性回归
线性回归的基本要素:模型、数据集、损失函数和优化函数
Softmax与分类模型
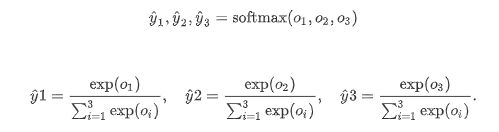
多层感知机
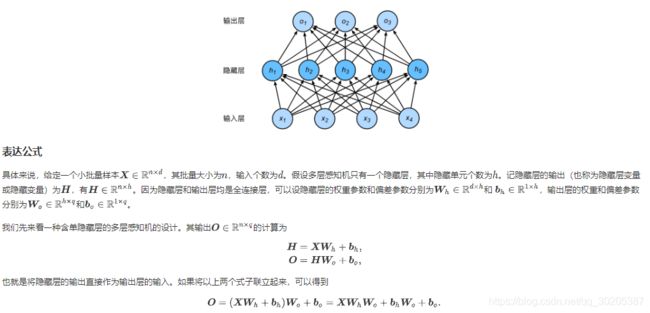
Task 02
文本预处理
文本是一类序列数据,一篇文章可以看作是字符或单词的序列,本节将介绍文本数据的常见预处理步骤,预处理通常包括四个步骤:
1. 读入文本
2. 分词
3. 建立字典,将每个词映射到一个唯一的索引(index)
4. 将文本从词的序列转换为索引的序列,方便输入模型
读入文本
lines = [re.sub(’[^a-z]+’, ’ ', line.strip().lower()) for line in f]
%将文本中的大写替换成小写,并将由非英文字母构成的子串替换成空格
分词

分别以单词或者字符为单位进行分词
建立字典:为每个词映射一个唯一的索引
for idx, token in enumerate(self.idx_to_token)
用现有工具进行分词:spaCy:和NLTK:


## 语言模型
基于统计的语言模型,主要是 n n n元语法
N元语法的缺陷: 参数空间过大(v+v2+v3+…),数据稀疏(齐夫定律:大多数的单词的词频低)
时序数据的采样:随机采样和相邻采样
相邻采样:
![]()
循环神经网络基础

## 过拟合欠拟合
训练误差和泛化误差(常用测试数据集上的误差来近似)
欠拟合:模型无法得到较小的训练误差
过拟合:
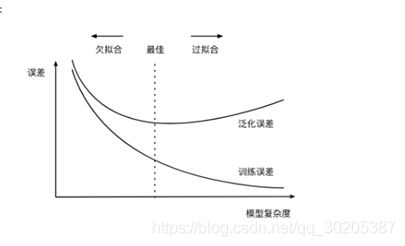
正常情况
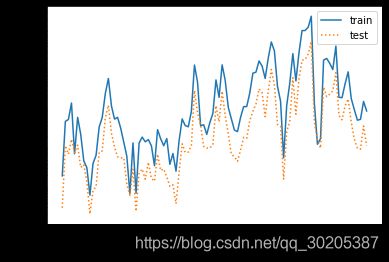
欠拟合情况
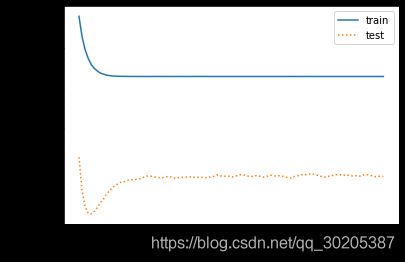
过拟合情况
降低过拟合的方法:
- 获得更多的训练样本。比如通过数据增强方式来扩充或者GAN来合成。
- 降低模型的复杂度。
- 正则化
- 集成学习方法
- dropout
降低欠拟合的方法:
6. 添加新的特征
7. 增加模型的复杂度,加强模型的拟合能力
8. 减小正则化系数
梯度消失、梯度爆炸
考虑环境因素:协变量偏移、标签偏移和概念偏移
循环神经网络进阶
裁剪梯度是一种应对梯度爆炸的方法
机器翻译及相关技术
问题:如何将输入序列映射为可能不等大小的输出序列(例如:I am Chinese -> 我是中国人)
在机器翻译模型的训练中,每个batch中的数据都要是相同长度的->pad
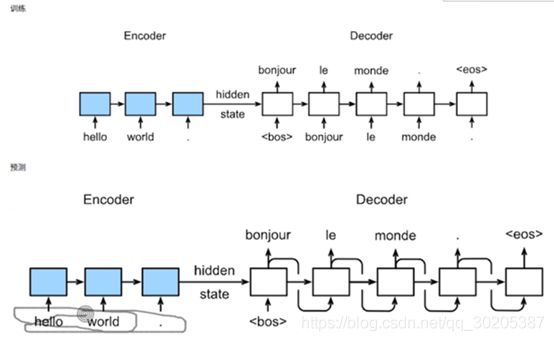
Encoder和decoder框架
Sequence to Sequence
维特比算法
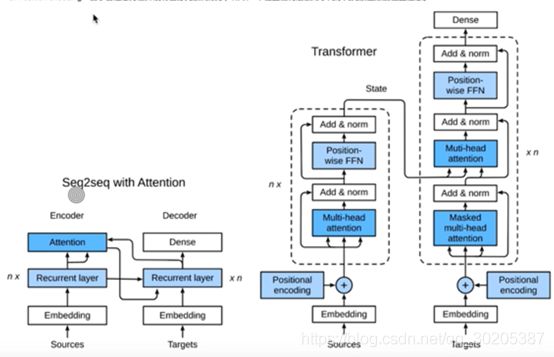
注意力机制与seq2seq模型
Transform模型
要点在于:并行化和长序列的依赖
卷积神经网络基础
卷积可以由互相关引入,但是具体来说还存在一个核中心翻转的过程(从频率域滤波的角度来看)但由于在卷积层中参数是可学习的,故可直接等价 。
卷积神经网络进阶
NiN
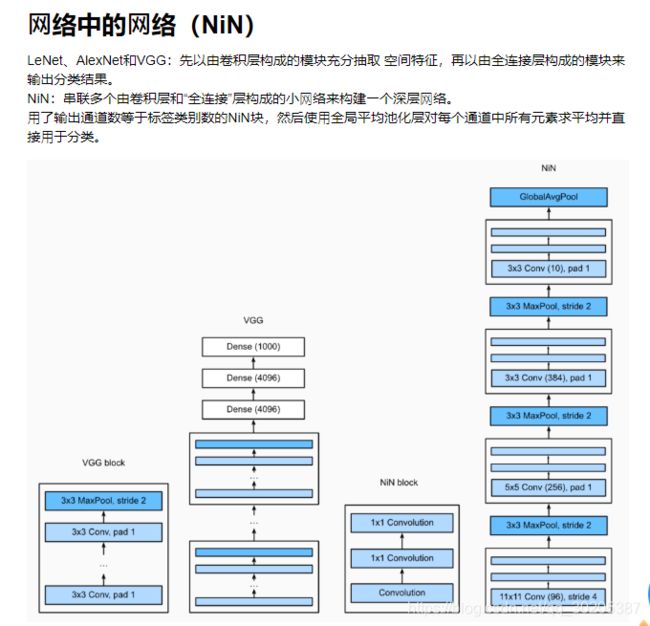

之前题目中提到relu函数是否存在梯度消失问题:
https://www.zhihu.com/question/49230360
批量归一化和残差网络
BN处理
训练:以batch为单位,对每个batch计算均值和方差。
预测:用移动平均估算整个训练数据集的样本均值和方差。(滑动求均值和方差),或者说,一般到模型训练后期稳定后,后续批次的均值和方差可以直接作为测试的均值和方差
残差网络:residual block(恒等映射)->解决梯度消失问题
稠密连接网络(densenet):与resnet的区别在于使用相加和使用联结(concat)
凸优化
• 优化方法目标:训练集损失函数值
• 深度学习目标:测试集损失函数值(泛化性)
在深度学习中的挑战:1. 局部最小值 2. 鞍点 3. 梯度消失
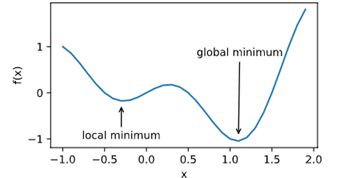
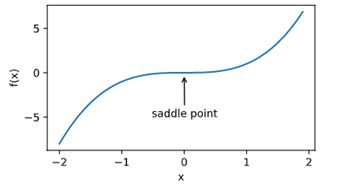

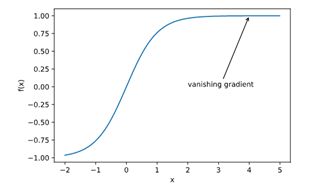
凸性证明
![]()



梯度下降
证明:

(在一定程度上依赖于学习率)梯度下降的自适应方法
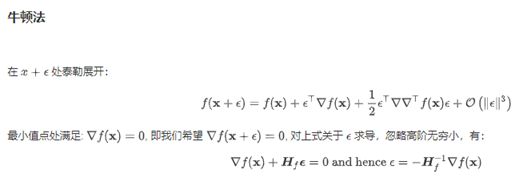
预处理 (Heissan阵辅助梯度下降)
梯度下降与线性搜索(共轭梯度法)
随机梯度下降
动态学习率
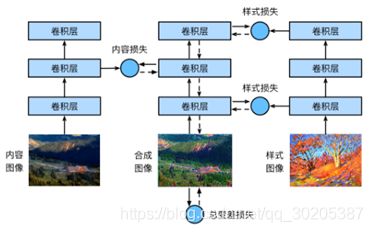
图像风格迁移
内容损失:平方误差
样式损失:格拉姆矩阵(Gram matrix)XX⊤∈Rc×c
总差分误差:抑制特别亮或者特别暗的像素
内容损失使合成图像与内容图像在内容特征上接近,样式损失令合成图像与样式图像在样式特征上接近,而总变差损失则有助于减少合成图像中的噪点。
图像分类案例1
目标检测基础
图像分类案例2
GAN
DCGAN
数据增强
Pytorch中的torchvision.transforms模块用于数据增强
RandomHorizontalFlip实例来实现一半概率的图像水平(左右)翻转
RandomVerticalFlip实例来实现一半概率的图像垂直(上下)翻转
RandomResizedCrop随机裁剪
ColorJitter变化颜色
多个增广方法的叠加 torchvision.transforms.Compose
模型微调
模型迁移
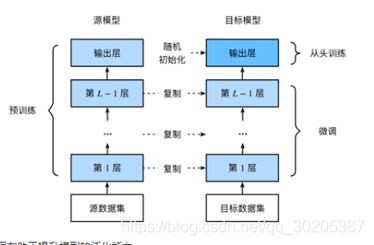
调参过程:先讲训练集划分为训练集和验证集,再放入模型训练调参过程,后续再讲完整训练集放入训练,最终在测试集上进行测试