2022秋中国海洋大学《软件工程》第14小组第四次作业
2022秋中国海洋大学《软件工程》第14小组第四次作业
本博客为OUC2022秋季软件工程第三次作业
文章目录
-
-
- 2022秋中国海洋大学《软件工程》第14小组第四次作业
-
- 李昊
- 陈子琪
-
- 前言
- 第一部分 在谷歌 Colab 上完成猫狗大战VGG模型的迁移学习
- 第二部分 用比赛测试集进行测试并生成CSV文件提交
- 第三部分 进行优化
- 第四部分 总结
- 兰宇瑞
- 文顺
- 吴鑫磊
- 秦奥翔
-
李昊
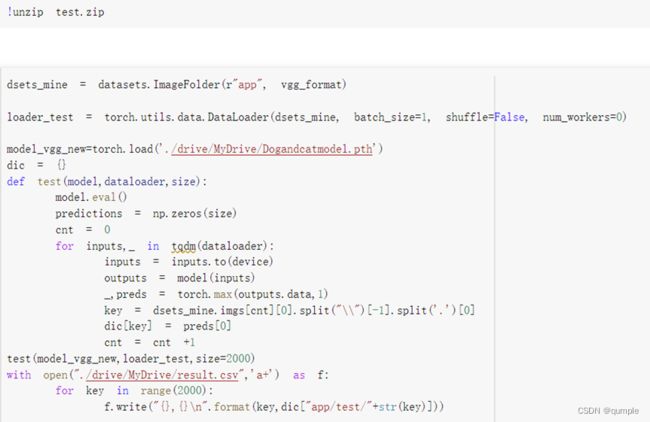
1.下载数据:
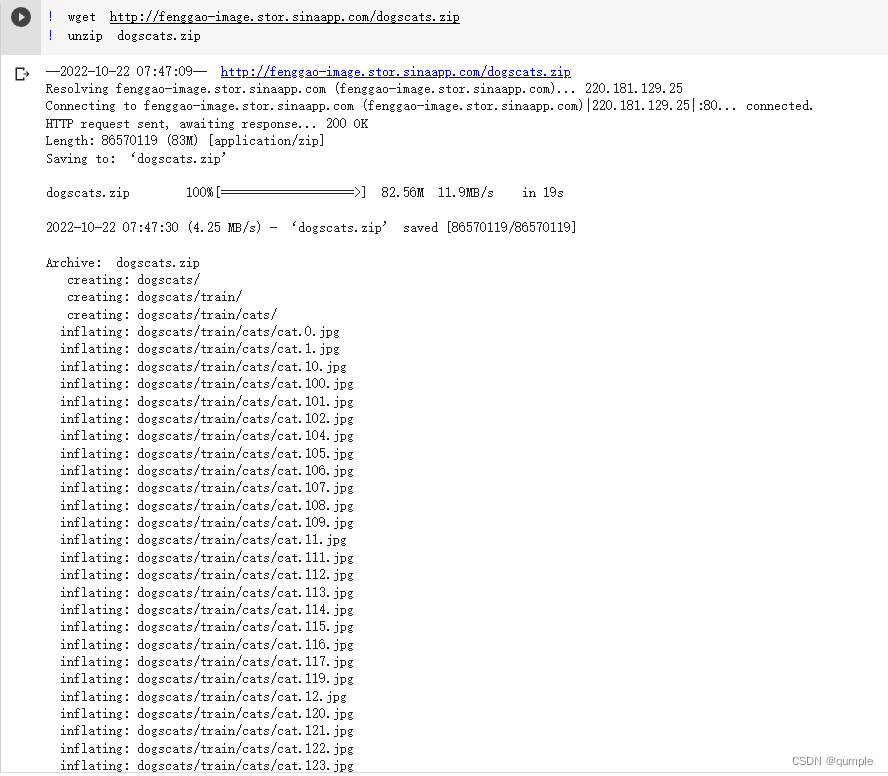
2.数据处理:
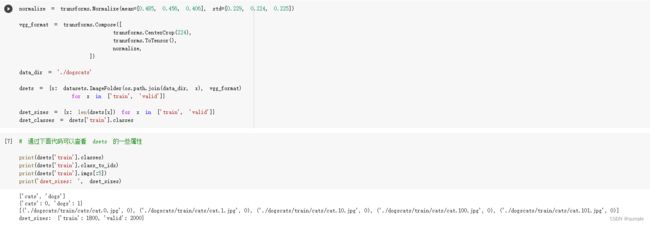

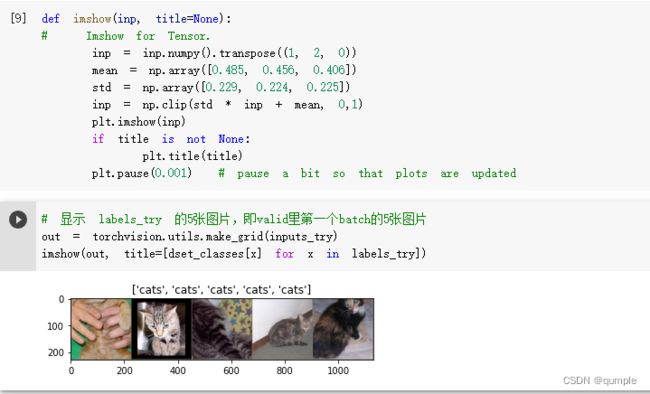
3.创建 VGG Model

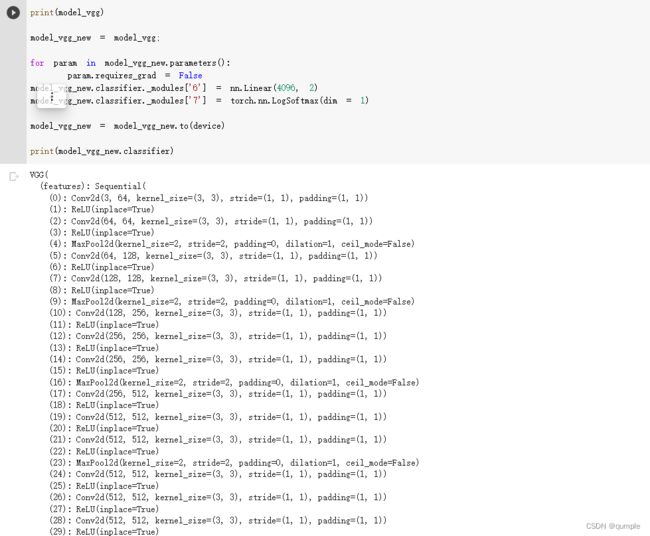
4. 修改最后一层,冻结前面层的参数
5. 训练并测试全连接层

陈子琪
前言
我们将建一个模型来完成 Kaggle 中的猫狗大战竞赛题目。在这个比赛中,有25000张标记好的猫和狗的图片用做训练,有12500张图片用做测试。首先在谷歌 Colab 上完成猫狗大战VGG模型的迁移学习,关键步骤截图,并附一些自己想法和解读。
在该代码的基础上,下载AI研习社“猫狗大战”比赛的测试集,利用fine-tune的VGG模型进行测试,按照比赛规定的格式输出,上传结果在线评测。将在线评测结果截图,将代码实现的解读发在博客。同时,分析使用哪些技术可以进一步提高分类准确率。
第一部分 在谷歌 Colab 上完成猫狗大战VGG模型的迁移学习
- 检查是否有GPU
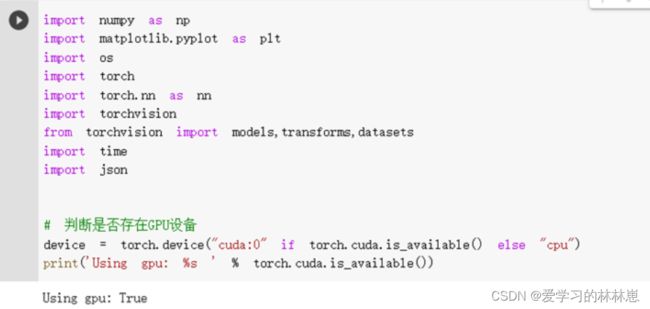
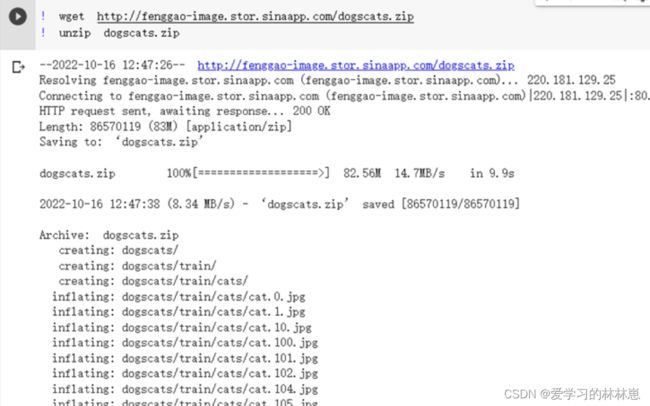
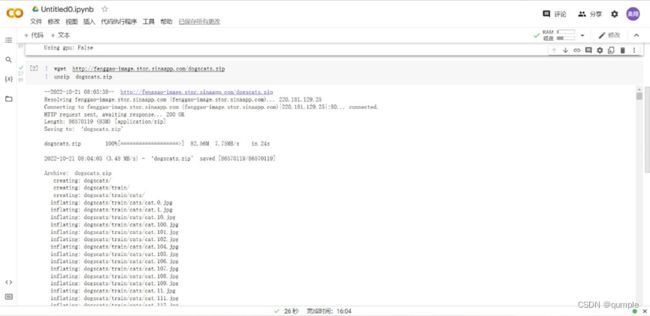
- 下载数据
下载数据并解压到工作目录
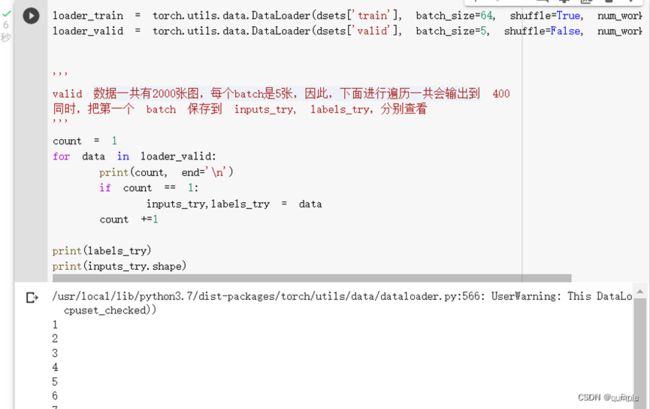
- 数据处理

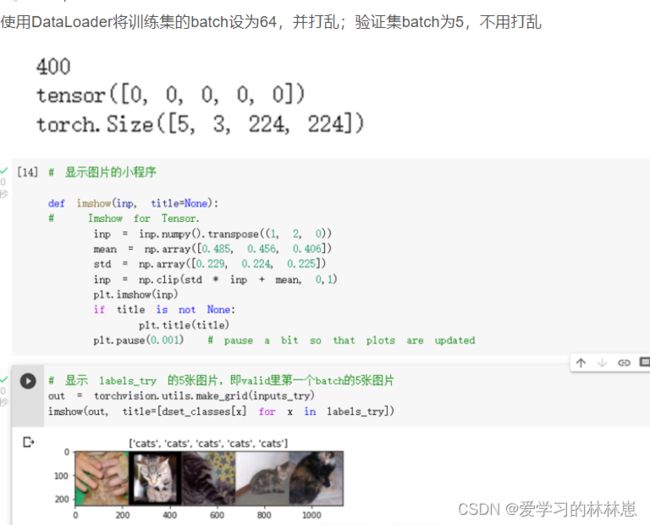
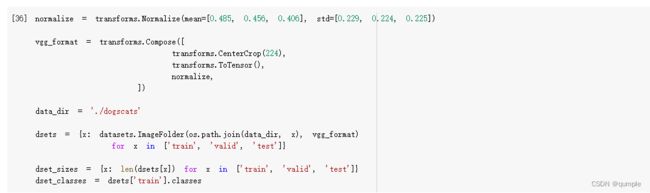
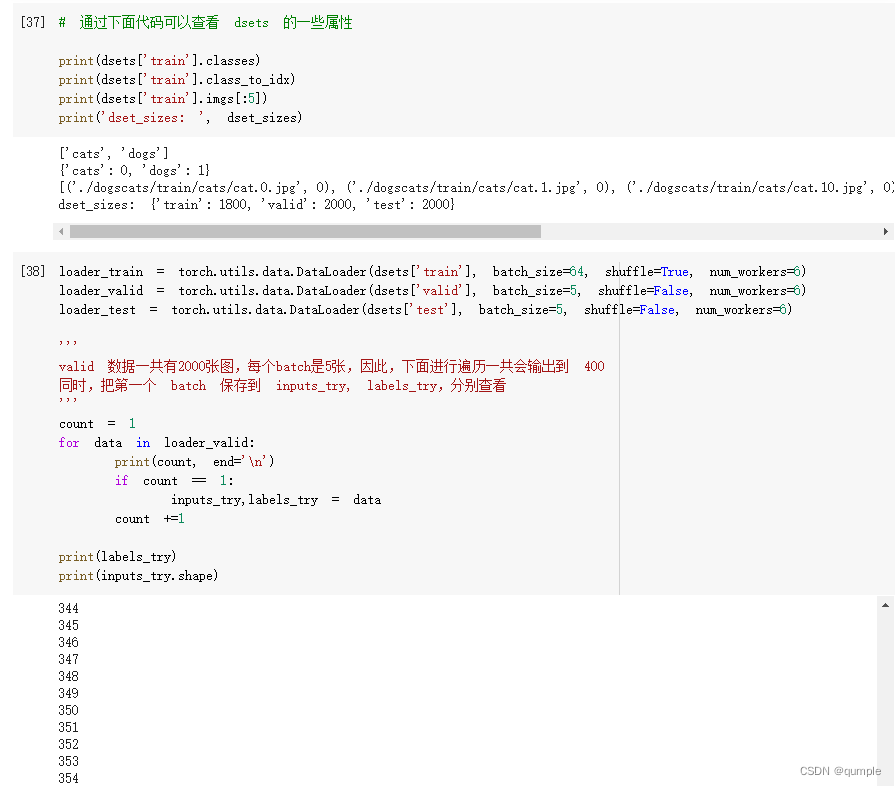
然后使用datasets.ImageFolder加载数据,把训练集和验证集分别加载并使用transforms进行处理,最后放到一个字典里。并且获取数据集大小和训练集的类别


- 创建 VGG Model
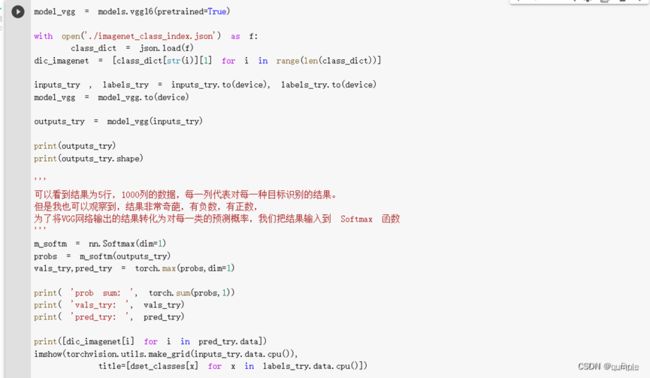
torchvision中集成了很多在 ImageNet (120万张训练数据) 上预训练好的通用的CNN模型,可以直接下载使用。
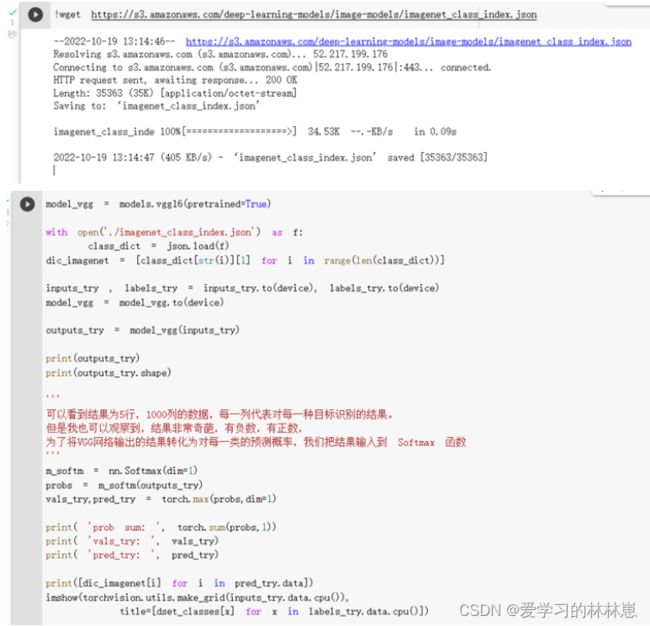
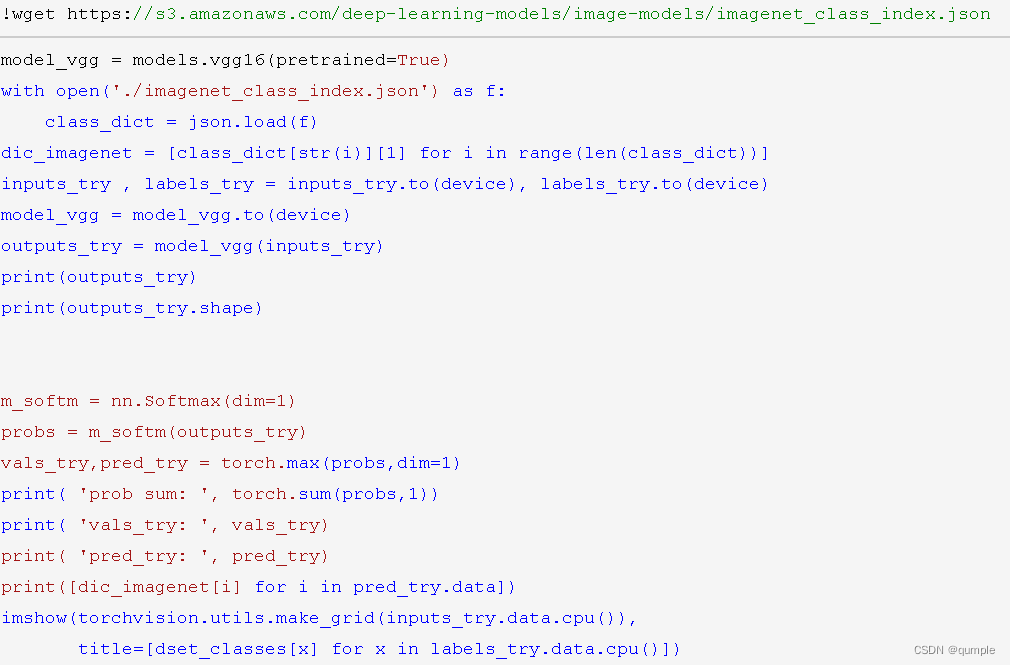
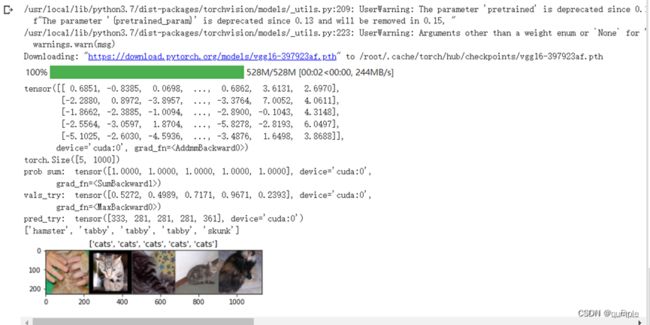
在本课程中,我们直接使用预训练好的 VGG 模型。同时,为了展示 VGG 模型对本数据的预测结果,还下载了 ImageNet 1000 个类的 JSON 文件。
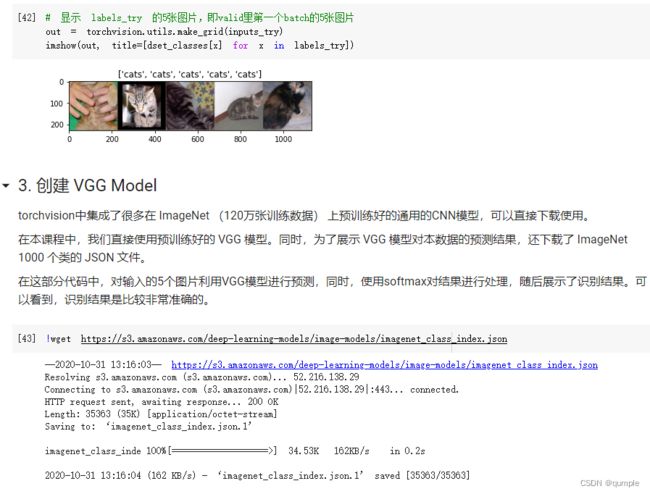
在这部分代码中,对输入的5个图片利用VGG模型进行预测,同时,使用softmax对结果进行处理,随后展示了识别结果。可以看到,识别结果是比较非常准确的。
- 修改最后一层,冻结前面层的参数
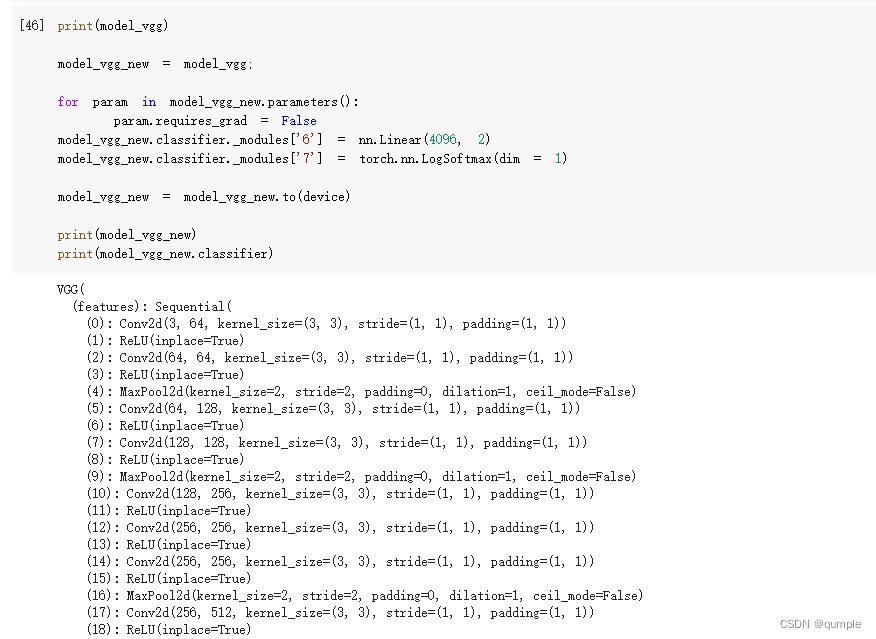
我们的目标是使用预训练好的模型,因此,需要把最后的 nn.Linear 层由1000类,替换为2类。为了在训练中冻结前面层的参数,需要设置 required_grad=False。这样,反向传播训练梯度时,前面层的权重就不会自动更新了。训练中,只会更新最后一层的参数。
把原网络的分类器的第六层改为nn.Linear(4096, 2)

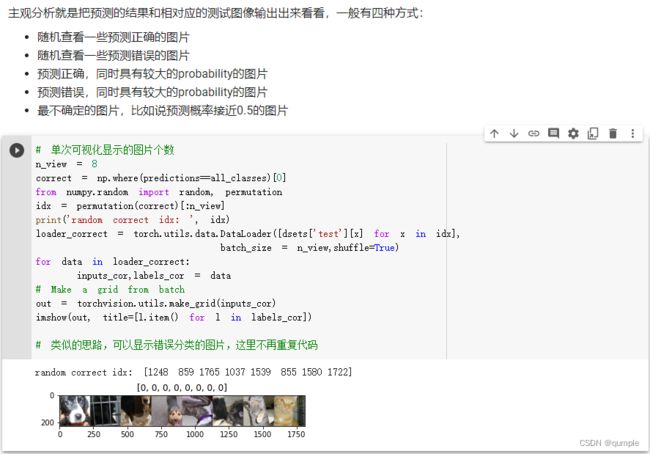
- 可视化模型预测结果(主观分析)
主观分析就是把预测的结果和相对应的测试图像输出出来看看,一般有五种方式:
随机查看一些预测正确的图片
随机查看一些预测错误的图片
预测正确,同时具有较大的probability的图片
预测错误,同时具有较大的probability的图片
最不确定的图片,比如说预测概率接近0.5的图片
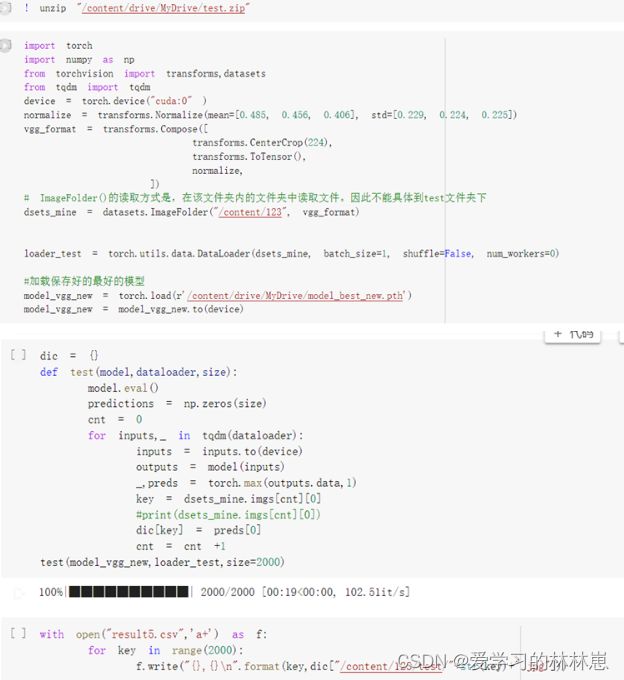
第二部分 用比赛测试集进行测试并生成CSV文件提交
第三部分 进行优化
- 进行优化(小训练集)
// An highlighted block
for param in model_vgg_new.parameters():
param.requires_grad = False
model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 4096)
model_vgg_new.classifier._modules['7'] = nn.LeakyReLU(0.2, inplace=True)
model_vgg_new.classifier._modules['8'] = nn.Dropout(p=0.5,inplace=False)
model_vgg_new.classifier._modules['9'] = nn.Linear(4096, 2)
model_vgg_new.classifier._modules['10'] = torch.nn.LogSoftmax(dim = 1)
import shutil
def classify_pics(dir_name):
path = "./cat_dog/" + dir_name + "/"
cat = path + "cat"
dog = path + "dog"
if not os.path.exists(cat):
os.makedirs(cat)
if not os.path.exists(dog):
os.makedirs(dog)
files = os.listdir(path)
for file in files:
if not os.path.isdir(file):
name = os.path.splitext(file)[0].split('_')[0]
if name == 'cat':
shutil.move(path+file, cat)
elif name == 'dog':
shutil.move(path+file, dog)
classify_pics("train")
classify_pics("valid")
// A code block
var foo = 'bar';
path = "./cat_dog/test/"
raw = path + "raw"
if not os.path.exists(raw):
os.makedirs(raw)
files = os.listdir(path)
for file in files:
if not os.path.isdir(file):
shutil.move(path+file, raw)

第四部分 总结
通过对视频学习 总结 并且通过我在谷歌 Colab 上完成猫狗大战VGG模型的迁移学习,在网络的学习 用比赛测试集进行测试并进行了优化。本次是通过训练好的VGG模型对其进行优化,对pytorch的使用更加熟悉,学习并使用了很多优化策略。对以后的学习和项目打下坚实的基础。可以更好地进步学习
习 总结 并且通过我在谷歌 Colab 上完成猫狗大战VGG模型的迁移学习,在网络的学习 用比赛测试集进行测试并进行了优化。本次是通过训练好的VGG模型对其进行优化,对pytorch的使用更加熟悉,学习并使用了很多优化策略。对以后的学习和项目打下坚实的基础。可以更好地进步学习
兰宇瑞
1.下载数据

2.数据处理
datasets 以多线程的形式从硬盘中读取数据,使用 mini-batch 的形式,在网络训练中向 GPU 输送。在使用CNN处理图像时,需要进行预处理。图片将被整理成 224 × 224 × 3 224\times 224 \times 3 224×224×3 的大小,同时还将进行归一化处理。

3.创建VGG Model
直接下载使用 ImageNet (120万张训练数据) 上预训练好的通用的CNN模型。同时,为了展示 VGG 模型对本数据的预测结果,还下载了 ImageNet 1000 个类的 JSON 文件。在这部分代码中,对输入的5个图片利用VGG模型进行预测,同时,使用softmax对结果进行处理,随后展示了识别结果。可以看到,识别结果是比较非常准确的。
4.冻结前层的参数
VGG 模型由三种元素组成:
卷积层(CONV)是发现图像中局部的pattern
全连接层(FC)是在全局上建立特征的关联
池化(Pool)是给图像将为以提高特征的invariance

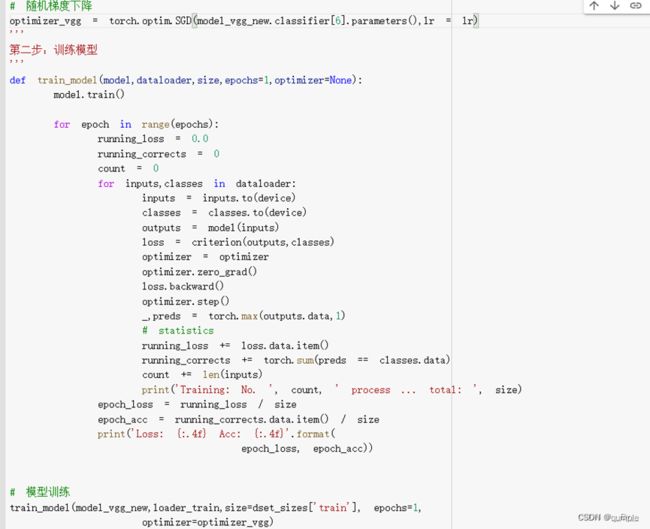
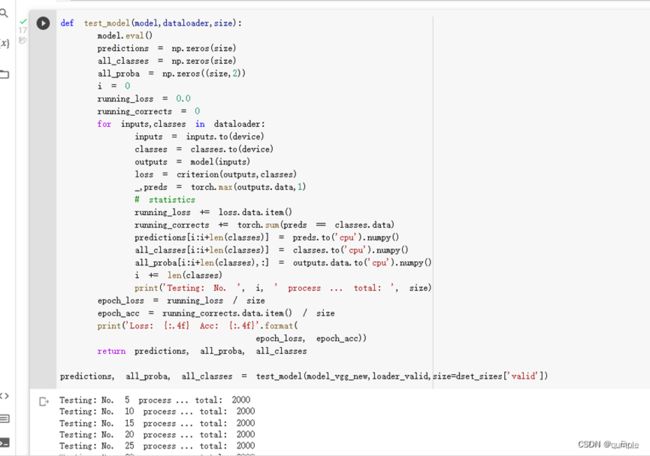
5.训练并测试全连接层
第一步,创建损失函数和优化器
第二步,训练模型
第三步,测试模型



文顺
一、在Colab上完成迁移学习
- 关键步骤截图
下载并加载数据集,数据文件夹包括train,valid,训练集含有dogs,cats文件,图片分别被放在这两个文件夹下表示对图片正确结果的标注

从网上下载预训练好的VGG16model,设置 required_grad=False冻结前面层的参数,使得在训练时只训练最后一层。同时在深度学习中,冻结其他层,只训练某一层可以避免梯度消失


二、 想法
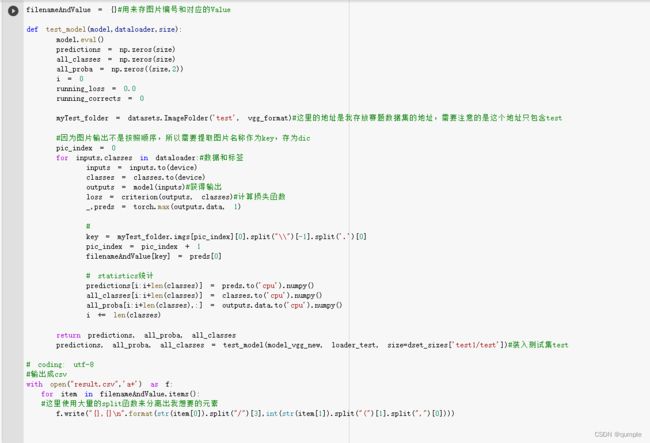
在进行写入数据的时候,要注意图片在colab的排序方式,并按照对应的格式输出数据
def test_model(model,dataloader,size):
model.eval()
#初始化变量
predictions = np.zeros(size)
all_classes = np.zeros(size)
all_proba = np.zeros((size,2))
i = 0
running_loss = 0.0
running_corrects = 0
meici_shuzu=[0,1,2,3,4]
total_cishu=0
for inputs,classes in dataloader:
print("num:",inputs)#获得inputs格式,进行分解
#将数据放入GPU
inputs = inputs.to(device)
classes = classes.to(device)
#放入模型,获取结果
outputs = model(inputs)
#计算损失值
loss = criterion(outputs,classes)
_,preds = torch.max(outputs.data,1)
#以下是修改的代码
print("\npreds:",preds)#输出观察preds结构,发现是张量
for shushu2 in range(0,5):#构造编号,后期发现其
#实只需要调用test的图片名就好了
meici_shuzu[shushu2]=shushu2+total_cishu
#将preds用numpy转换成数组类型,便于储存
dataframe=pd.DataFrame({'num':meici_shuzu,'result':preds.numpy()})
#循环写入
dataframe.to_csv("test.csv",index=False,mode='a',sep=",")
total_cishu=total_cishu+5
吴鑫磊



数据处理
使用transfrom函数把图片整理为2242243的大小,同时进行归一化处理,查看datasets的一些属性。将数据拆分为训练集和有效集,设置VGG的格式。
创建 VGG Model
使用torchvision中预训练好的VGG模型进行训练。可以看出预测比较准确,对第一个batch中的5张图片都得到了正确的结果。但结果有负数和正数。
直接下载使用 ImageNet (120万张训练数据) 上预训练好的通用的CNN模型,只需要改动最后全连接层输出部分的参数需要把最后的 nn.Linear 层由1000类,替换为2类。为了在训练中冻结前面层的参数,需要设置 required_grad=False
秦奥翔
一、 首先判断是否存在CPU设备
二、 下载数据
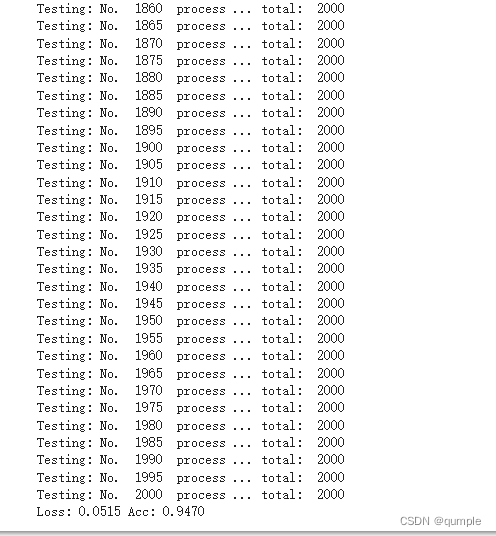
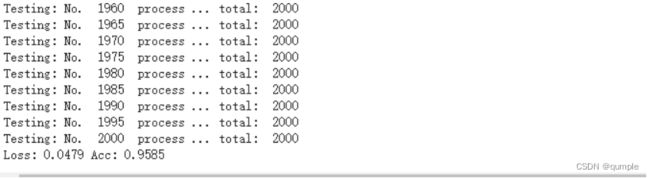
重新整理数据,制作新的数据集,训练集包含1800张图(猫的图片900张,狗的图片900张),测试集包含2000张图。
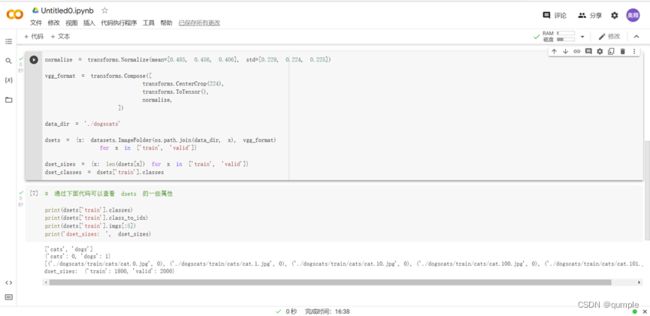
三、 数据处理
datasets 是 torchvision 中的一个包,可以用做加载图像数据。它可以以多线程(multi-thread)的形式从硬盘中读取数据,使用 mini-batch 的形式,在网络训练中向 GPU 输送。在使用CNN处理图像时,需要进行预处理。图片将被整理成224×224×3的大小,同时还将进行归一化处理。torchvision 支持对输入数据进行一些复杂的预处理/变换 (normalization, cropping, flipping,jittering 等)。
四、 创建VGG Model
torchvision中集成了很多在 ImageNet (120万张训练数据) 上预训练好的通用的CNN模型,可以直接下载使用。在本课程中,我们直接使用预训练好的 VGG 模型。同时,为了展示 VGG 模型对本数据的预测结果,还下载了 ImageNet 1000 个类的 JSON 文件。在这部分代码中,对输入的5个图片利用VGG模型进行预测,同时,使用softmax对结果进行处理,随后展示了识别结果。
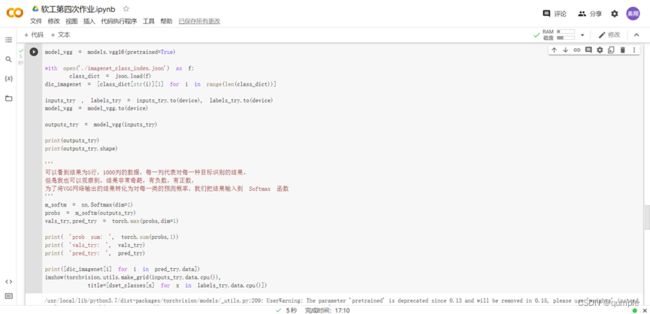

五、 修改最后一层,冻结前面层的参数
我们的目标是使用预训练好的模型,因此,需要把最后的 nn.Linear 层由1000类,替换为2类。为了在训练中冻结前面层的参数,需要设置 required_grad=False。这样,反向传播训练梯度时,前面层的权重就不会自动更新了。训练中,只会更新最后一层的参数。

在本次实验中,增加了一次ReLU函数激活以及一次线性连接层。线性连接层的参数为多次试验后的较优取值
六、 训练并测试全连接层
包括三个步骤:第1步,创建损失函数和优化器;第2步,训练模型;第3步,测试模型

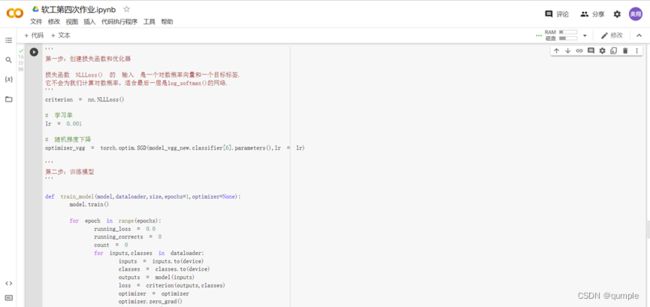
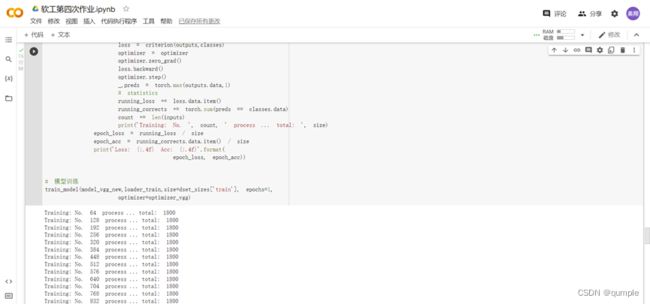

如上述代码可见,在训练代码中做出三个变化:
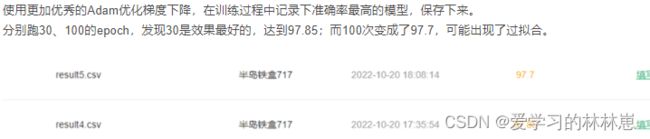
通过查阅资料及试验可得,Adam在训练模型时效果要略优于SDG,故将代码中得SDG换成Adam
增加epoch的数值为100,由于选用训练样本数为1800,故选择增加训练次数来提高所训练的模型的准确性
由于每次训练的模型准确率的不相同,故需选择准确率最高训练模型进行测试,增加了几行提取最大值并存入云盘的程序
max_acc = 0
if epoch_acc > max_acc:
max_acc = epoch
path = ‘./drive/MyDrive/Dogandcatmodel.pth’
torch.save(model,path)
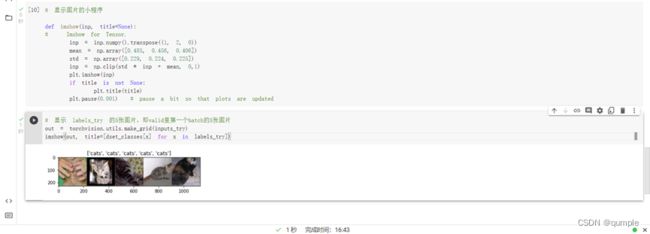
七、可视化模型预测结果(主观分析)
主观分析就是把预测的结果和相对应的测试图像输出出来看看,一般有四种方式:
随机查看一些预测正确的图片
随机查看一些预测错误的图片
预测正确,同时具有较大的probability的图片
预测错误,同时具有较大的probability的图片
最不确定的图片,比如说预测概率接近0.5的图片
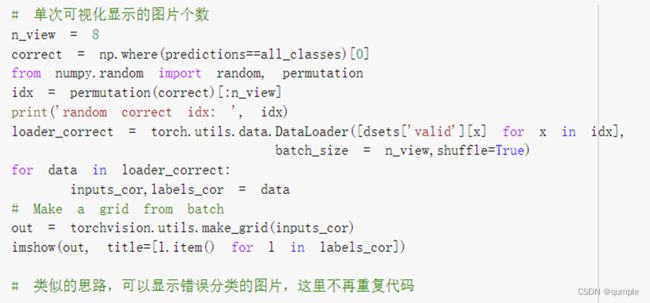
对AI研习社中猫狗大战中给出的测试模型进行测试
该结果与未改进前结果相比较提高了2%左右,但仍有较大进步空间,未能达到好的检测效果原因有如下:
选用的训练模型为1800张,相对而言较少,若采用20000张图片进行训练或许会得到更好的训练模型
对于修改的几层函数的选择不是最优,导致即使在训练阶段将准确率达到100%,但依然不能在实际测试时获得更好的结果